-
-
TrialMatchAI
-


The Last Mile in Clinical Trials
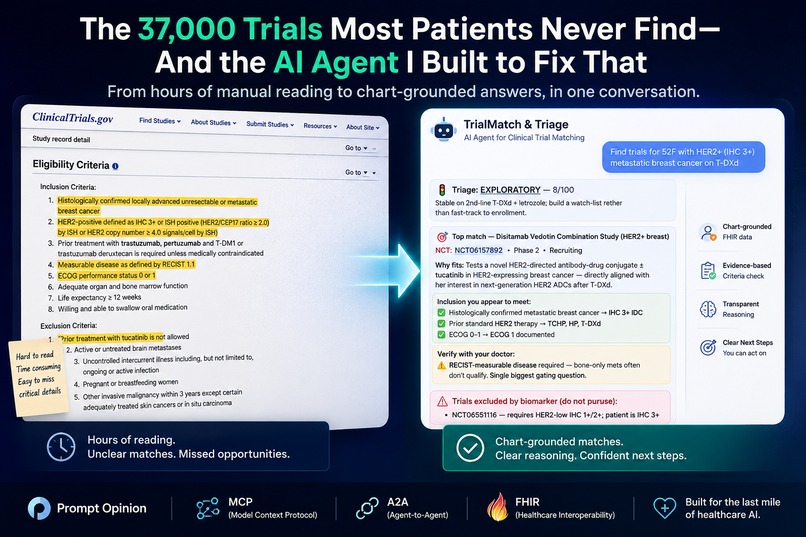
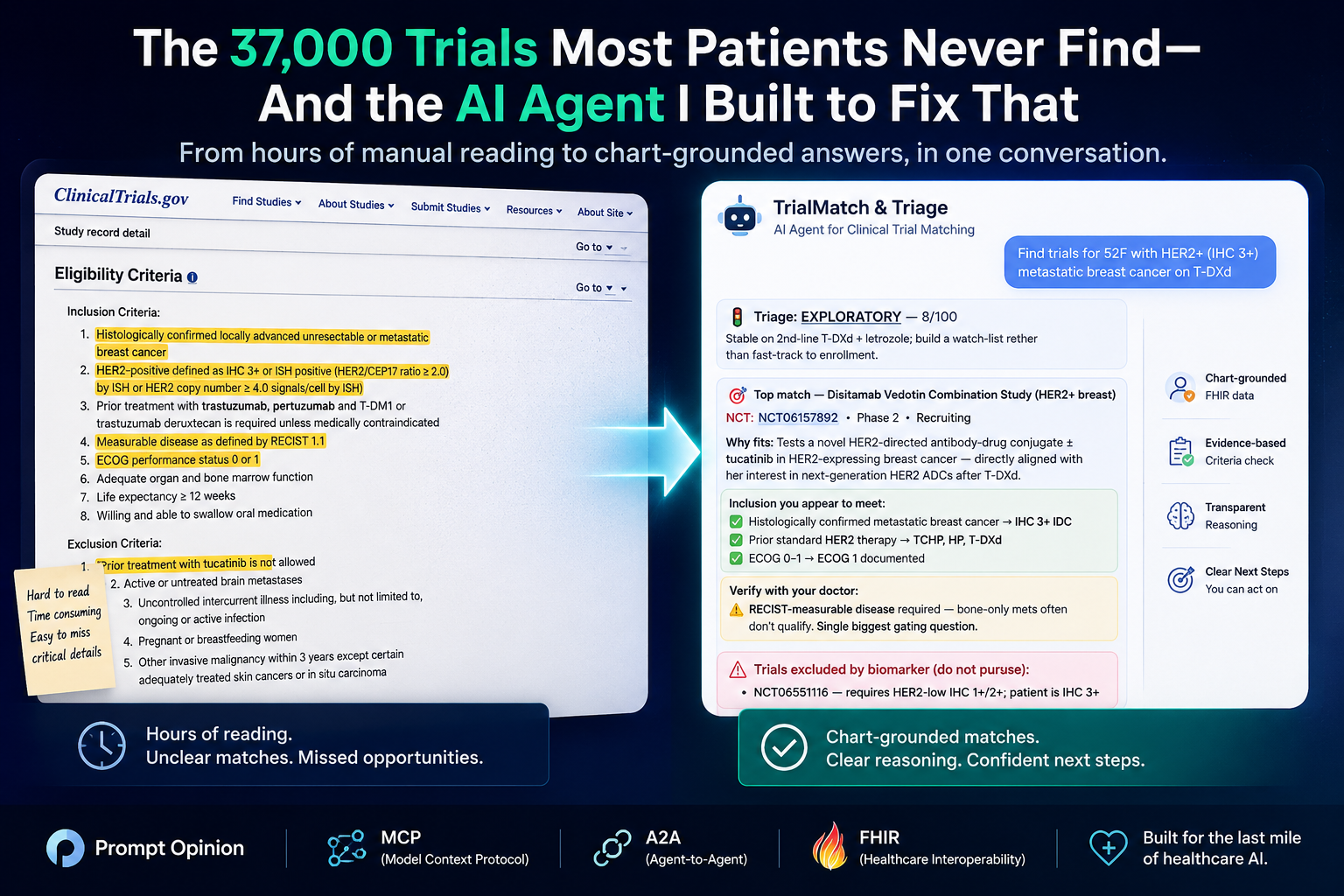
There are roughly 37,000 actively recruiting clinical trials on ClinicalTrials.gov right now. Most patients who would qualify for one will never find out it exists. Not because the trials are hidden — they're sitting in plain sight — but because matching a real patient to a real trial means reading pages of dense eligibility criteria, cross-referencing each one against an unstructured medical chart, and accounting for things the chart may not document at all.
A clinical research nurse can do this well. They are also one of the most expensive, scarcest professionals in oncology and cardiology, and they are not the people answering patients' 3 a.m. Google searches.
TrialMatch & Triage is a healthcare AI agent that does that work. Built inside the Prompt Opinion workspace on MCP, A2A, and SHARP FHIR-context standards, it reads a patient's live FHIR record, classifies how urgently they should be considered for trial enrollment, searches ClinicalTrials.gov, and returns a ranked list of trials with chart-grounded ✓ / ⚠️ checklists explaining exactly why each fits — citing the specific datapoint from the chart that proves it.
What it does
Given a patient in context, the agent runs a six-step workflow in a single conversation:
- Pulls the patient's FHIR record (demographics, conditions, observations, medications, allergies) using Prompt Opinion's SHARP context propagation
- Triages enrollment urgency —
URGENT,MODERATE, orEXPLORATORY— based on disease activity, prior lines of therapy, and remaining standard-of-care options - Searches ClinicalTrials.gov with the patient's primary condition and location
- Ranks candidate trials by hard-filtering age, sex, and condition compatibility
- Pulls full inclusion/exclusion criteria for the top three matches
- Returns a ranked list with chart-grounded ✓ inclusions, ⚠️ items to verify with the treating physician, and named exclusions
Real example: Robert Anderson, 69M with HFpEF
We tested with a synthetic patient designed to mirror a real cardiology clinic referral:
- 69-year-old male, San Francisco
- HFpEF, LVEF 62%, NYHA Class III, NT-proBNP 1,840 pg/mL
- Recent HF hospitalization 6 months ago
- 6-minute walk distance: 285m despite optimized 4-drug GDMT (empagliflozin, spironolactone, lisinopril, metoprolol)
- BMI 34.2, T2DM with A1C 6.8%
The agent's top match was NCT07037459 — MARITIME-HF, a Phase 3 trial of maridebart cafraglutide (a GLP-1/GIP-class agent) in HFpEF patients with obesity. Here's what the response looked like — every checkmark is anchored to the actual chart: 🎯 Top match — Maridebart Cafraglutide in HFpEF + Obesity (MARITIME-HF) NCT: NCT07037459 (Phase 3, Recruiting) Why fits: GLP-1/GIP-class agent for HFpEF patients with obesity. Robert has confirmed HFpEF (LVEF 62%), BMI 34.2, NYHA III, elevated NT-proBNP, and a recent HF hospitalization. Hits every primary inclusion bucket. Strength: Strong Inclusion you appear to meet: ✓ Age ≥18 → 69 years ✓ BMI ≥30 → BMI 34.2 ✓ NYHA II–IV, HF ≥30 days → NYHA III, dx 2022 ✓ On HF standard of care → empagliflozin + MRA + ACE-i + beta-blocker ✓ LVEF >40% within 12 mo → LVEF 62% (echo 2 mo ago) ✓ Elevated NT-proBNP → 1,840 pg/mL ✓ HF hospitalization >30d & <12mo prior → hospitalization 6 months ago with IV diuretics Verify with your doctor: ⚠️ T2DM controls: A1C must be ≤10% (yours is 6.8% ✓) and no proliferative/severe diabetic retinopathy — confirm a recent eye exam is on file. ⚠️ Bay Area site availability — trial is multi-site Phase 3 but the public listing's first sites are out of state. Have your physician query the sponsor for the nearest activated CA site (UCSF / Stanford).
That's seven inclusion criteria, each traced to a specific chart datapoint. Two honest verification flags — one clinical (retinopathy screening), one logistical (which CA site is recruiting). No invented facts. No hallucinated NCT IDs. No overconfident "you qualify" verdict.
Why this matters
Most healthcare AI demos hit a wall at this step. They retrieve trials by keyword and present them. A patient acting on that output wastes time on trials they don't qualify for, raises hopes that get crushed at screening, and lose trust in clinical research altogether.
The bar to clear is no longer "can my agent retrieve relevant information." It's "would a clinician trust the answer enough to act on it."
Every ✓ in TrialMatch & Triage's output cites the chart datapoint that proves it. Every ⚠️ flags something the chart genuinely cannot answer. The agent is allowed to be wrong, but it is not allowed to be confidently wrong without flagging the uncertainty. That's the difference between a search engine and a research nurse.
How we built it
Architecture
User (clinician or patient) │ ▼ TrialMatch & Triage Agent (BYO agent in Prompt Opinion) │ MCP (Streamable HTTP) + SHARP FHIR context ▼ TrialMatch & Triage MCP Server (Python, Starlette) │ ├── ClinicalTrials.gov API v2 ├── PubMed E-utilities └── Workspace FHIR server (live patient data)
The agent is invoked directly in the Prompt Opinion launchpad. A2A is enabled on the agent, so any other compliant agent in the ecosystem can compose with it without writing custom glue code.
MCP server with full Prompt Opinion FHIR extension support
We wrote a custom MCP server in Python (Starlette + Uvicorn) that:
- Speaks MCP over Streamable HTTP at
POST /mcp - Declares the
ai.promptopinion/fhir-contextextension in theinitializeresponse, with SMART scopes (patient/Patient.rs,Condition.rs,Observation.rs,MedicationRequest.rs,AllergyIntolerance.rs) - Reads
X-FHIR-Server-URL,X-FHIR-Access-Token, andX-Patient-IDheaders per request and makes authenticated calls back to the workspace FHIR server
Once the extension was declared correctly, Prompt Opinion immediately surfaced the FHIR trust toggle and scope checkboxes the docs describe — proving end-to-end SHARP integration.
Six tools, one focused workflow
| Tool | Purpose |
|---|---|
read_patient_fhir |
Live patient profile from workspace FHIR |
triage_patient_urgency |
Decision rule for enrollment urgency tier |
search_clinical_trials |
ClinicalTrials.gov v2 API search |
match_trials_to_patient |
Hard-filter + score top N candidates |
extract_eligibility_signals |
Parse one trial's inclusion/exclusion bullets |
search_pubmed_research |
Optional supporting research enrichment |
A2A-ready BYO agent in Prompt Opinion
The agent is configured with patient context, A2A enabled, FHIR context propagation on, and our six tools attached. The system prompt enforces a strict workflow with critical reasoning rules — most importantly: a high keyword-match score is not eligibility; always verify against the actual eligibility text before recommending. This is what produces the chart-grounded inclusion checklists and the honest verification flags.
Challenges we ran into
Declaring the FHIR extension in MCP. The standard mcp Python SDK (FastMCP) doesn't support custom capability declarations in the initialize response. We dropped to writing the JSON-RPC handler from scratch on Starlette, giving us full control over the capabilities payload. Worth it — once the extension was declared correctly, Prompt Opinion immediately surfaced the FHIR trust toggle and the integration "just worked."
Distinguishing keyword-match from real eligibility. Our first matcher returned high scores for trials whose conditions field contained the patient's primary condition — even when the actual inclusion text disqualified them. We added explicit reasoning rules in the system prompt forcing the agent to verify candidates against full eligibility text before recommending them, and to ground each ✓ in a specific chart datapoint. This turned a failure mode into the demo highlight.
Output token budgets. With multiple tool calls feeding ~30K tokens of context back to the model, responses occasionally hit pagination limits. We tightened tool payloads (shorter summaries, top-N filtering, fewer redundant fields), enforced a strict word budget in the prompt, and added a "next match" pagination flow as a fallback. The compression also made the responses more readable.
Sparse FHIR records vs. rich uploaded notes. Some patients in the workspace have rich clinical notes uploaded as documents but minimal FHIR resources. We instructed the agent to fall back to reading uploaded clinical notes when FHIR is sparse — combining structured and unstructured data into a coherent profile.
What we learned
- MCP extensions are powerful but require dropping below the SDK abstractions. The Prompt Opinion SHARP integration is well-designed, but using it required custom server code rather than just decorating tools.
- Keyword search is not eligibility matching. A trial whose
conditionsfield contains "heart failure" tells you almost nothing about whether your patient qualifies. Real matching requires reading the full inclusion/exclusion text against a structured patient profile, criterion by criterion. - Honest uncertainty beats confident hallucination. The agent's most valuable single behavior is saying "yes on these 7 criteria, with the chart facts that prove each one, plus 2 items only your doctor can verify." That kind of grounding is what makes this a tool a clinician would trust.
- Chart-grounded ✓ marks change the trust equation. A bare recommendation says "trust me." A recommendation where every ✓ cites the exact chart datapoint it relies on says "verify me." Clinicians want the second one.
What's next
- Multi-site routing — route patients to the closest enrolling site (e.g., automatically resolve the "Bay Area site availability" verification flag from above)
- Recurring monitoring — re-run matching on a schedule and alert when new trials open that fit the patient's profile
- Co-pilot mode — flip the workflow so a clinician can paste a draft trial-summary note and the agent fills in the chart-grounded checklist
- Multi-condition matching — handle patients with overlapping diseases (e.g., HFpEF + diabetes + obesity) by querying multiple condition-specific searches in parallel and ranking trials that address overlap
Built with
Python, Starlette, Uvicorn, httpx, MCP (Model Context Protocol over Streamable HTTP), Anthropic Claude Opus 4.7, Prompt Opinion (BYO Agent + A2A + SHARP FHIR context), ClinicalTrials.gov API v2, PubMed E-utilities, ngrok, FHIR R4


Log in or sign up for Devpost to join the conversation.