-
-

TrialMatch.AI logo
-

-

-
-
-

-






Inspiration
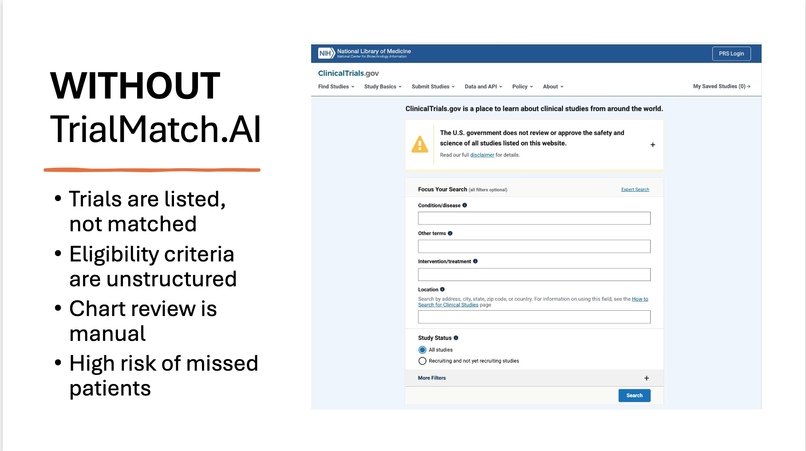
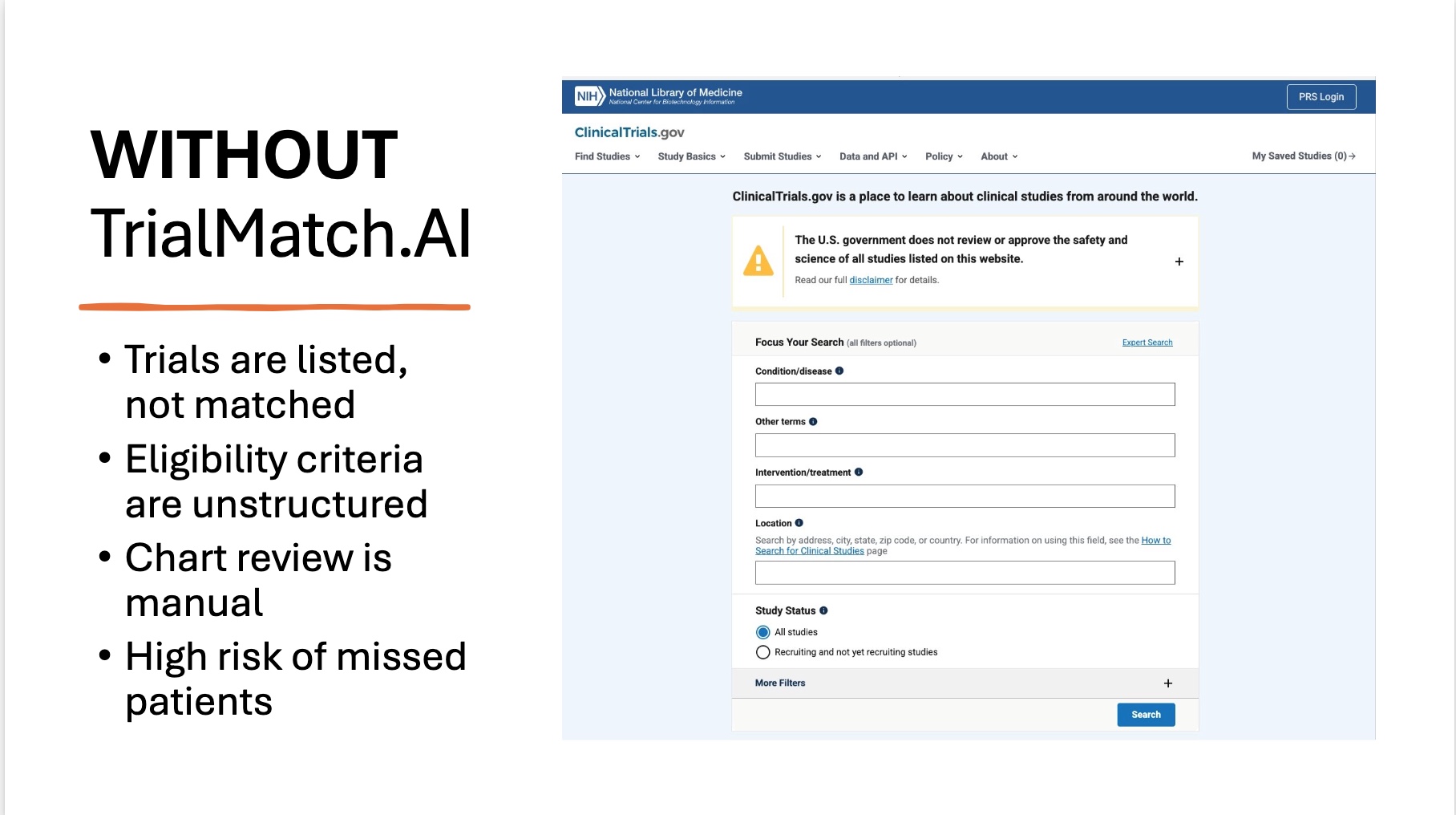
Clinical trials do not fail because science fails. They fail because we cannot match the right patients to the right studies fast enough. Research shows that 80% of clinical trials fail to meet their recruitment timelines, 30% of trial sites enroll zero patients, and 11% of trials shut down permanently due to low enrollment. Every day of delay costs sponsors between $600,000 and $8,000,000, and yet only 3–5% of eligible cancer patients ever make it into a clinical trial. The real bottleneck is not science, but screening. Clinical research coordinators often spend 30–90 minutes manually reviewing eligibility criteria and comparing them against patient charts. That process does not scale, and every missed match is a missed chance to save a life. TrialMatch.AI was built to eliminate that delay.
What it does
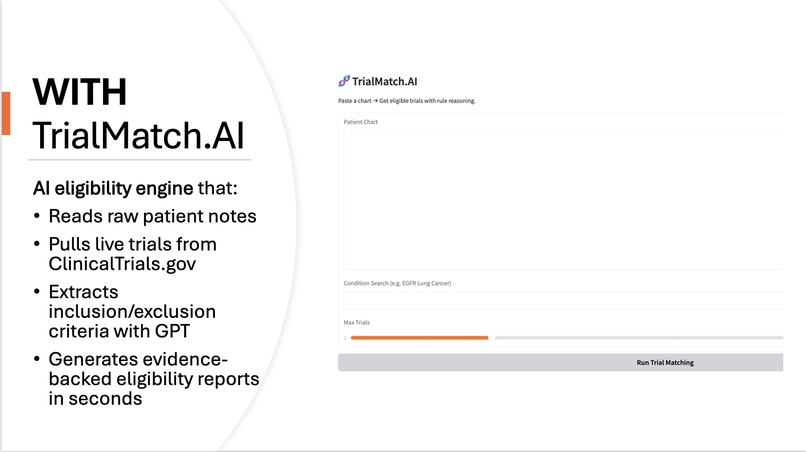
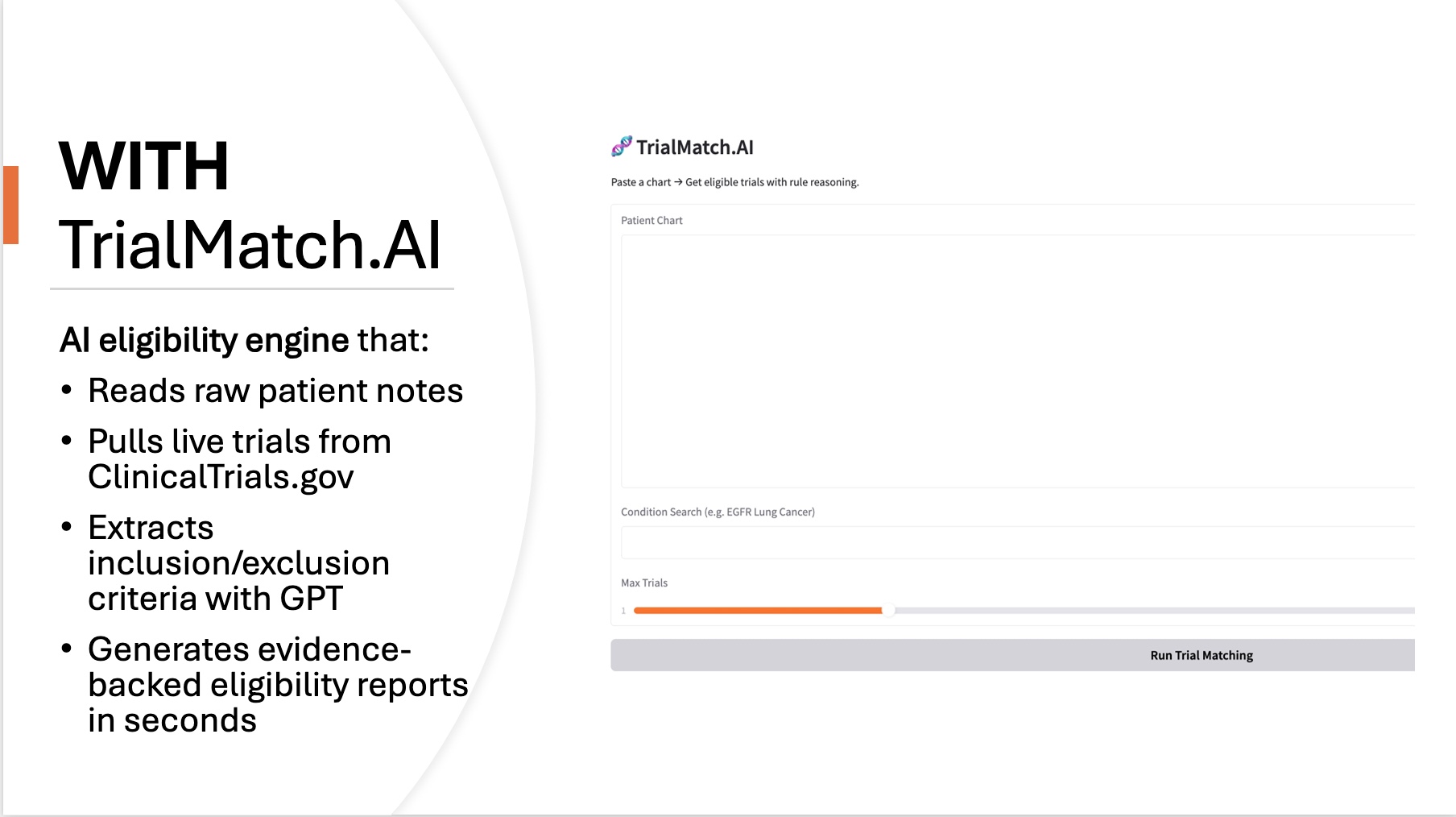
The idea behind the project is intentionally simple: a clinician should be able to paste a real patient chart into a tool and instantly see which clinical trials the patient may qualify for. TrialMatch.AI turns raw, unstructured Electronic Health Records (EHR)-style clinical notes into evidence-grounded trial eligibility assessments. The system automatically pulls live trials from ClinicalTrials.gov, extracts eligibility criteria using GPT, evaluates each rule against evidence inside the patient chart, and produces a readable match report showing which inclusion criteria are satisfied, which exclusion criteria are triggered, and where more information is needed. Importantly, every eligibility decision includes supporting evidence quoted or summarized from the patient chart, so a clinician can see exactly why the model reached its conclusion.
How I built it
To build TrialMatch.AI, I first created a live data pipeline that retrieves actively recruiting studies directly from the ClinicalTrials.gov API based on a condition keyword provided by the user. Once the trial information is retrieved, the raw eligibility section, which is normally written as a long block of unstructured text, is passed through a GPT-based extraction prompt that forces the model to convert it into a clean JSON structure containing two explicit lists: inclusion criteria and exclusion criteria. Because GPT sometimes produces partial or noisy responses, I implemented a parsing layer that first attempts a direct JSON load, and if it fails, automatically extracts the valid portion between the first and last curly braces. After each trial is converted into structured rule lists, the platform performs a second reasoning step in which each individual eligibility rule is evaluated against the unstructured patient chart text. Instead of using keyword matching, every rule is sent through a second GPT prompt that must decide whether the chart provides evidence that the rule is met, violated, or not assessable, and must also return a short evidence quote if applicable. After all inclusion and exclusion rules are evaluated, the system determines final eligibility logically: a trial is considered eligible if all checkable inclusion criteria are met and no exclusion criteria are triggered, ineligible if any exclusion rule is supported by evidence or any required inclusion rule is contradicted, and indeterminate if no rules could be confirmed. The final output is a structured match report that lists each trial with its eligibility status, rule-level reasoning, evidence citations, and a direct link back to the trial page. All of this logic is wrapped in a Gradio interface running in Google Colab, allowing real-time input of patient notes and instant generation of a match report without requiring any backend infrastructure. The result is a system that behaves like a human research coordinator: it reads trial protocols, reads patient charts, and makes evidence-based decisions rather than relying on keyword approximation or rigid rule coding.
Challenges I ran into
Building TrialMatch.AI required solving real challenges. Clinical trial eligibility text is messy, inconsistently formatted, and often ambiguous, so the first challenge was designing prompts and parsing logic that reliably extracts structured criteria. The second challenge was preventing hallucinated assumptions. Many rule-based systems assume that missing information means exclusion. To prevent this, the model explicitly assigns “not applicable” when a rule cannot be verified from the chart. Another challenge was transparency. Research coordinators do not trust black-box matching. To address this, the tool produces evidence citations for each rule outcome. Performance and API cost forced additional engineering decisions, such as dynamically limiting the number of trials evaluated and enforcing deterministic inference with temperature zero.
Accomplishments that I'm proud of
I am proud that TrialMatch.AI is not just a concept, but a fully functioning clinical reasoning engine that can screen real patient charts against live trials in seconds. In a single weekend, I built a system that retrieves active studies from ClinicalTrials.gov, extracts eligibility criteria using GPT, evaluates each rule against unstructured medical notes, and generates a transparent, evidence-backed eligibility report—something that normally takes clinical research staff 30–90 minutes per patient. What I am most proud of is that the system behaves like a real research coordinator rather than a keyword script: it only flags exclusion criteria when there is explicit evidence in the chart, and it never rejects a patient simply because a data field is missing. During testing, I successfully identified scenarios where traditional matching tools would falsely screen out eligible patients, including cases where male patients were incorrectly excluded for pregnancy criteria. I also proved that even without structured EHR data, pure reasoning over free-text clinical notes can still produce accurate, explainable screening results. For a hackathon project, achieving automated trial retrieval, rule extraction, evidence-based rule evaluation, and a working user interface, while preserving clinical transparency, is something I am genuinely proud of.
What I learned
Throughout the project, I learned that the biggest value of language models in healthcare is not generating text but interpreting it. GPT is capable of reading medical notes and applying rule logic with surprising clinical fidelity, as long as the prompts force justification and do not allow silent assumptions. I also learned that trial matching does not require a full EHR integration to be valuable. Even a pasted unstructured note can support meaningful automated screening, proving that large language models are finally able to take over 70% of the pre-screening workload that consumes clinicians’ time.
What's next for TrialMatch.AI
Next, I plan to support PDF uploads, batch-screening hundreds of patients at once, ranking trials by match strength, and eventually deploying inside a HIPAA-compatible environment where this can plug directly into EHRs via Fast Healthcare Interoperability Resources (FHIR). My long-term goal is to eliminate trial-matching delays entirely by replacing manual screening with an automated safety net that ensures no qualified patient ever slips through the cracks again.

Log in or sign up for Devpost to join the conversation.