-
-
Protocol Ready -> An oncology trial PDF loaded and ready to be parsed by AI.
-
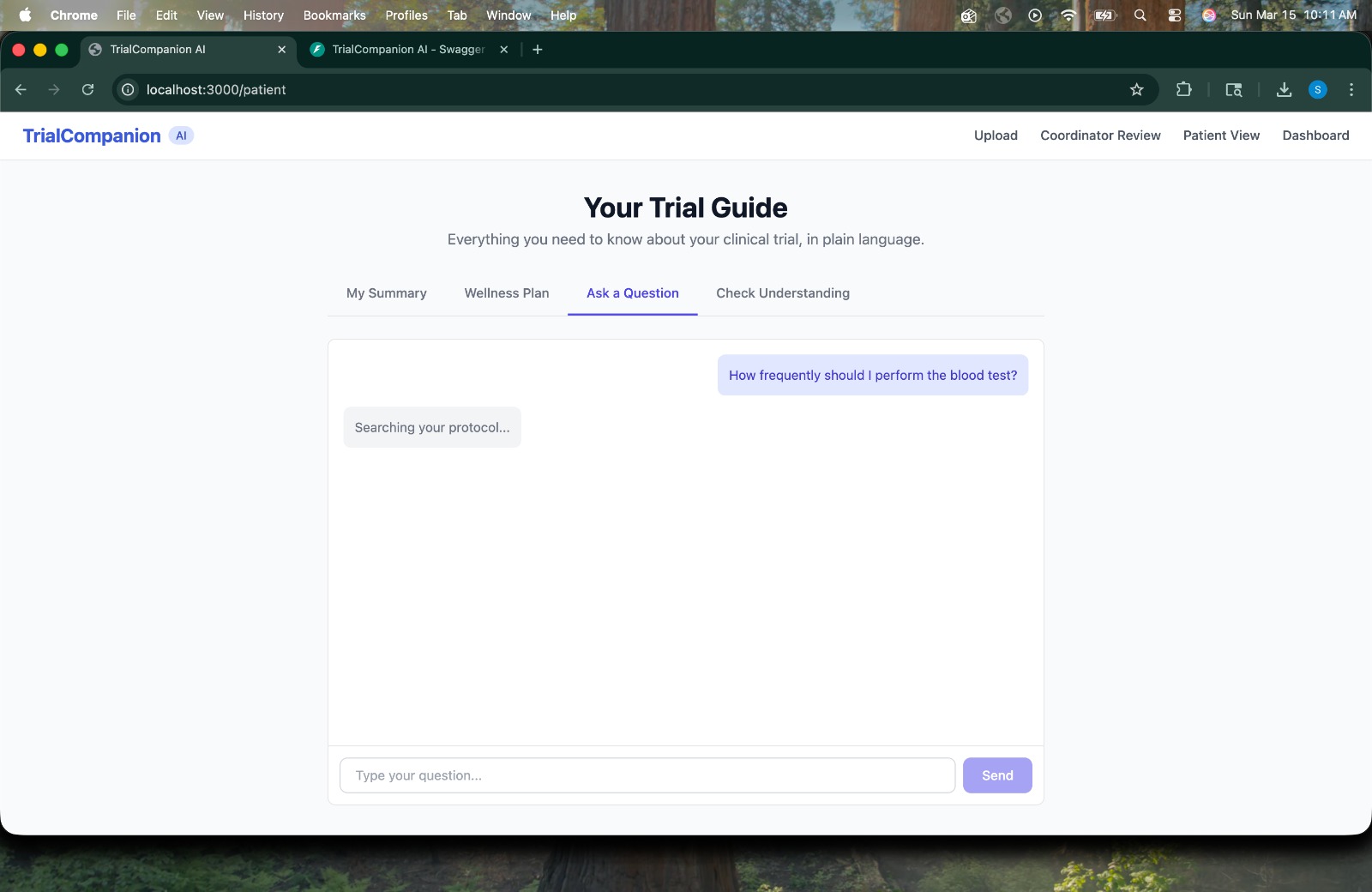
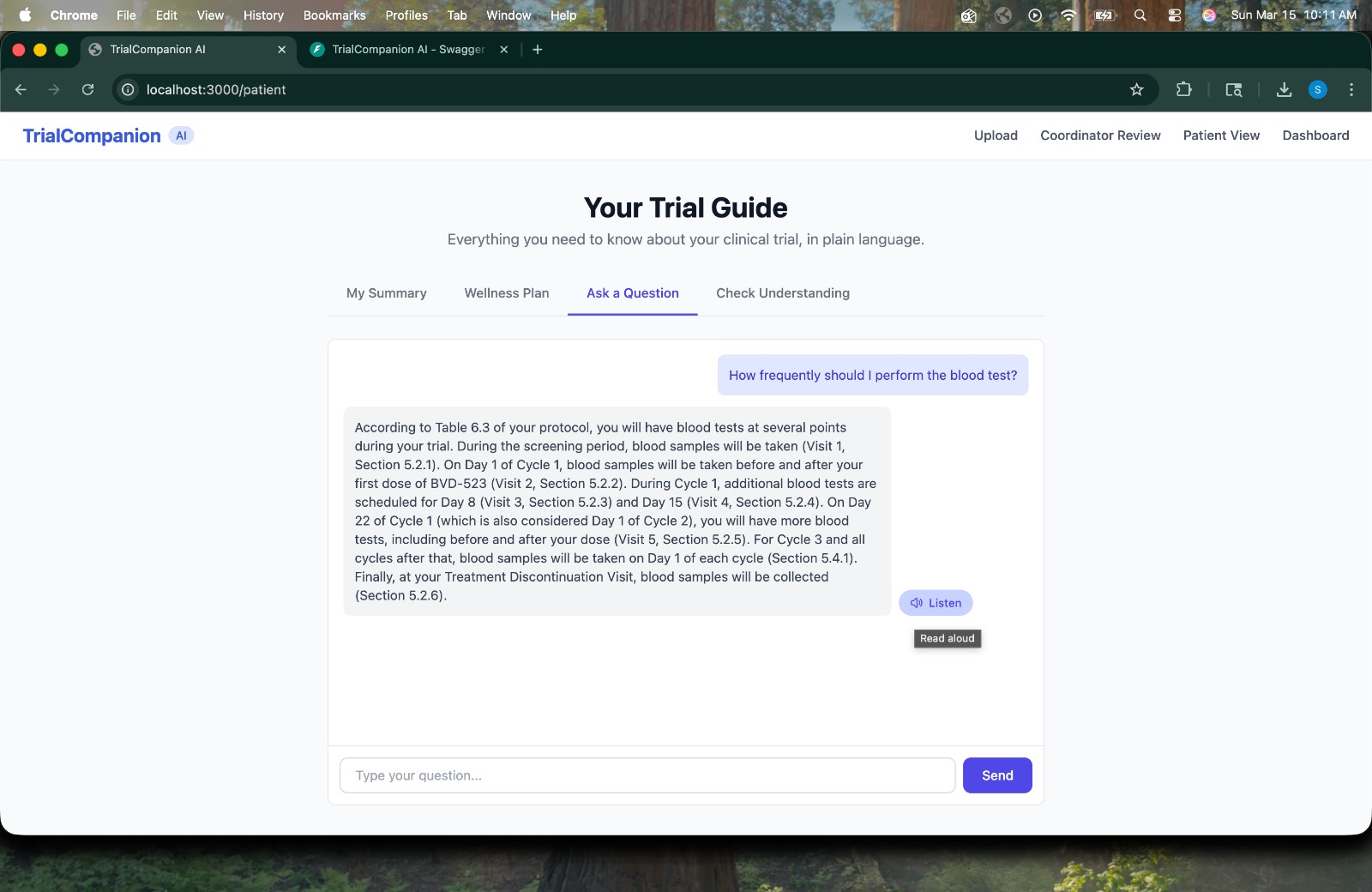
Patient Q&A -> Patient asks "How frequently should I perform the blood test?" -> AI searches the protocol in real time.
-
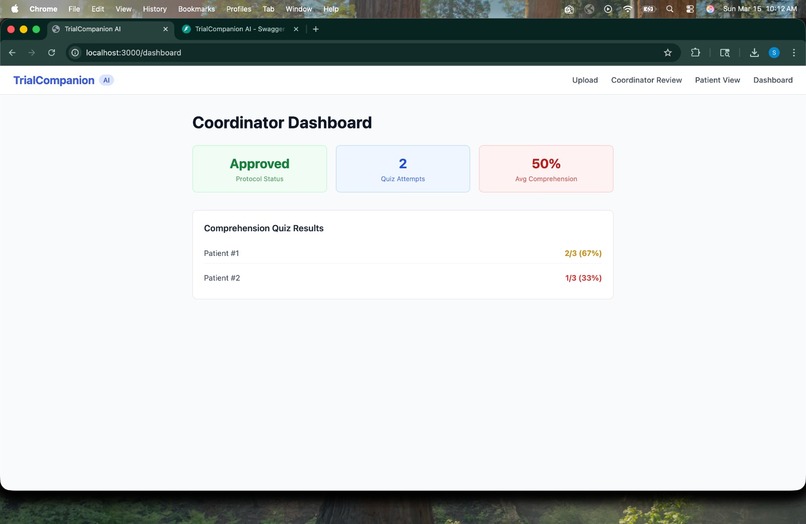
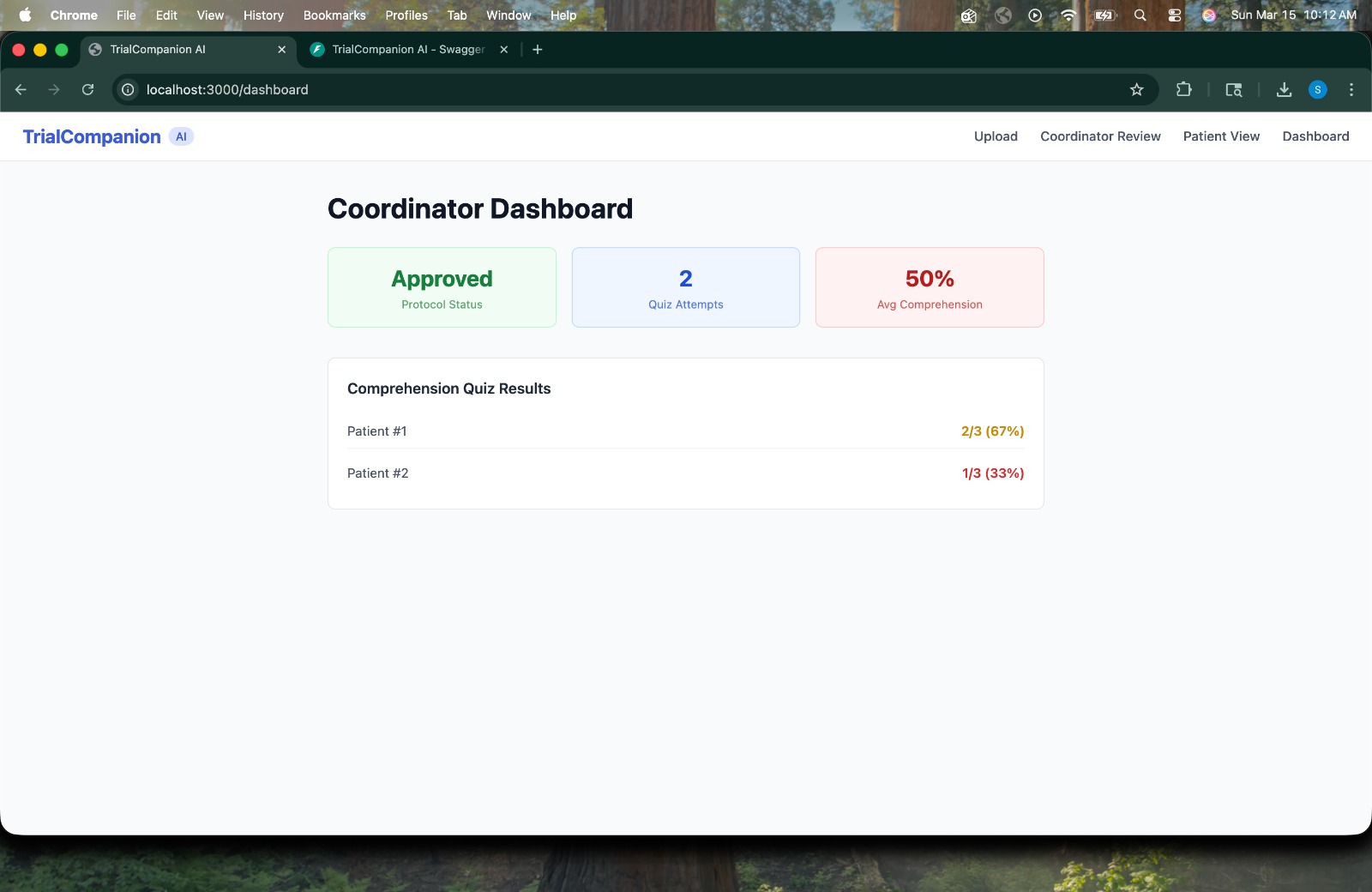
Coordinator Dashboard -> Real-time view of protocol approval status, quiz attempt count, and per-patient comprehension scores.
-
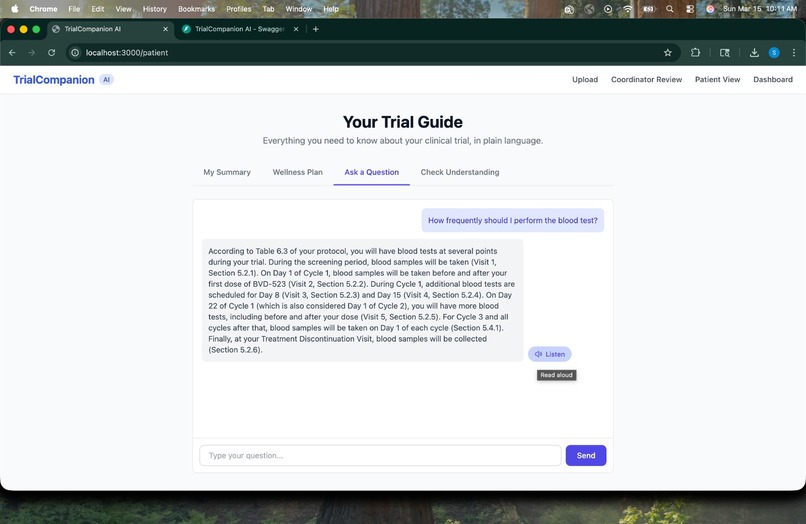
Protocol-Grounded Answer -> AI responds with a detailed, cited answer pulled strictly from the patient's specific trial.
-
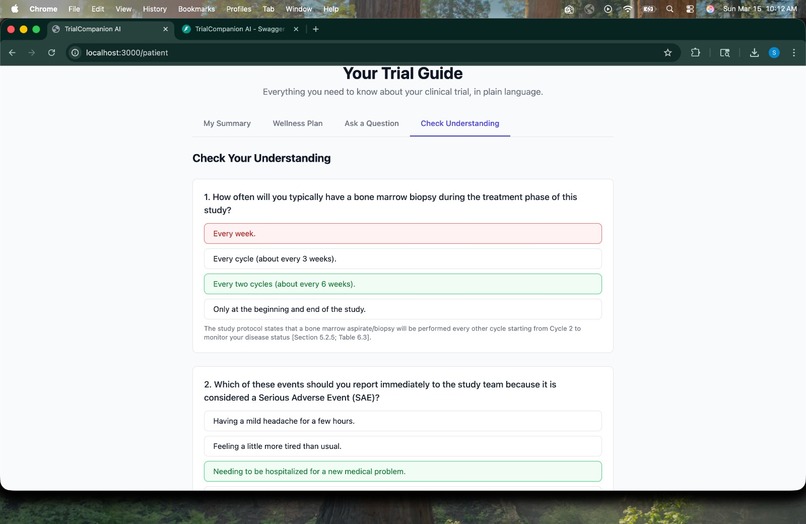
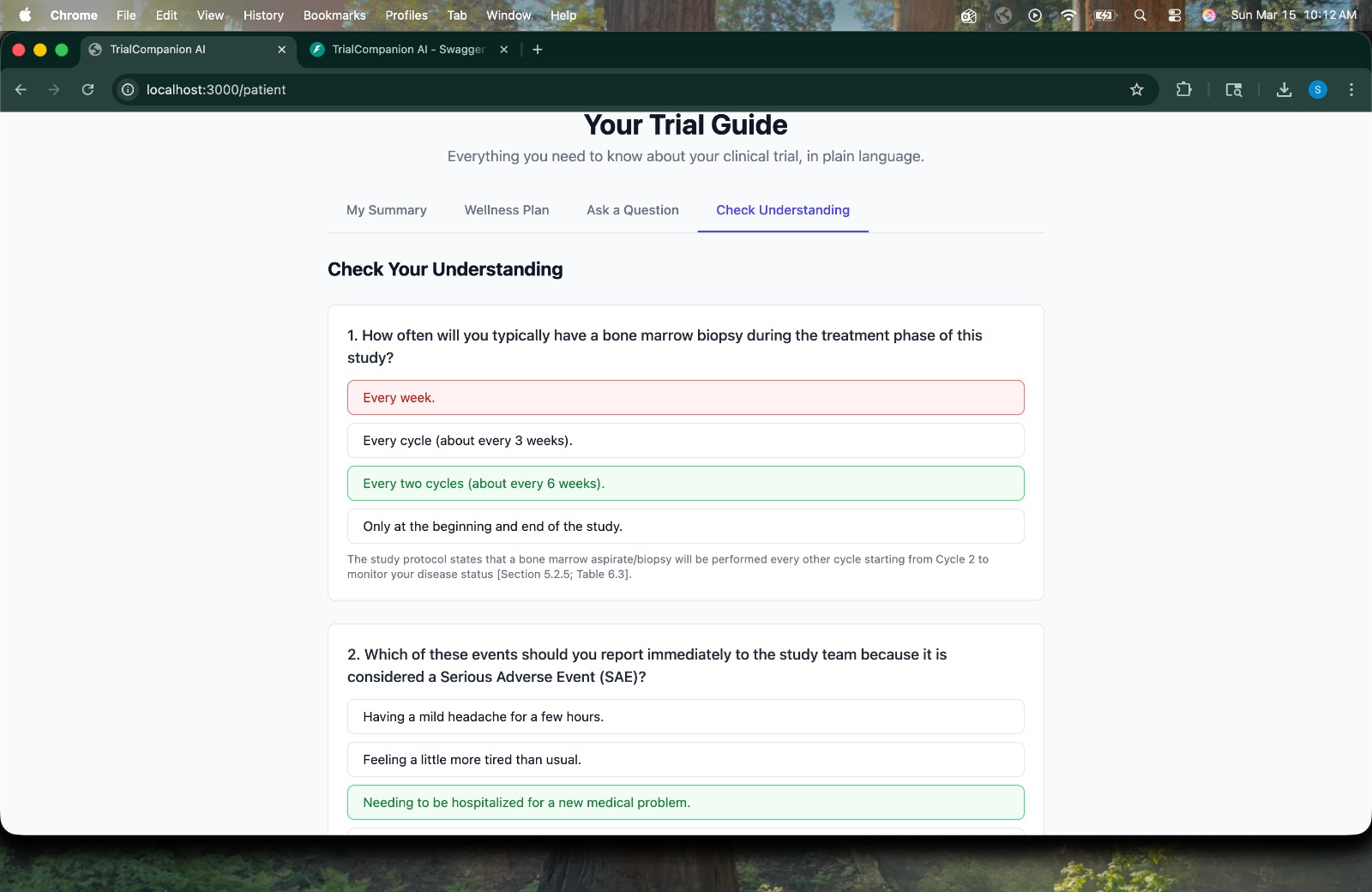
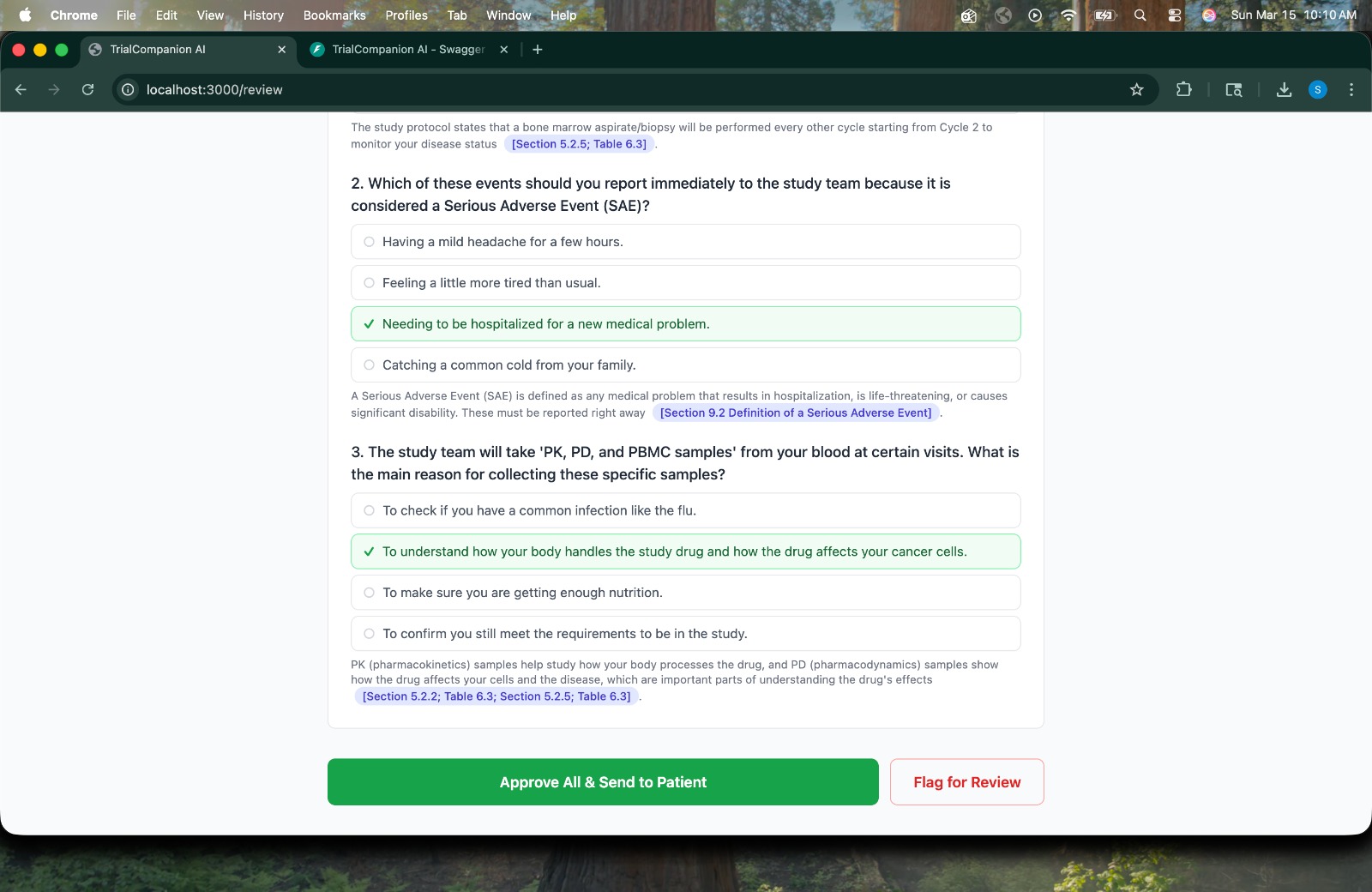
Comprehension Quiz -> Patient takes an auto-generated quiz testing understanding of key trial procedures, with immediate feedback.
-
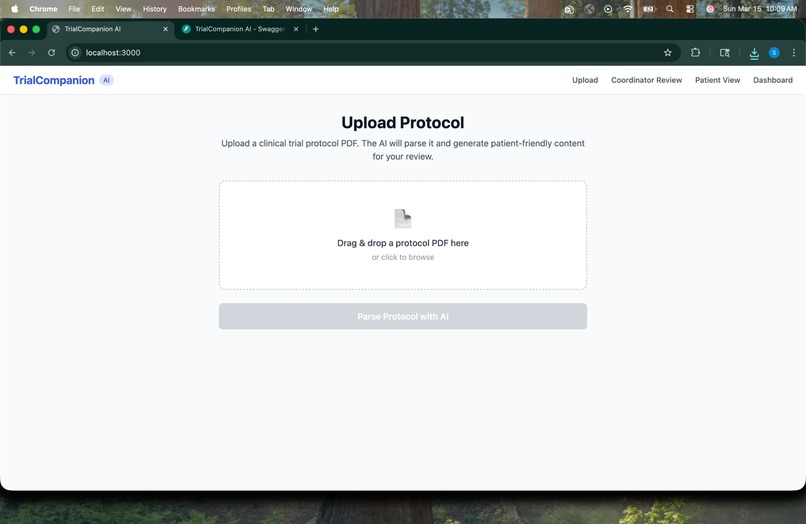
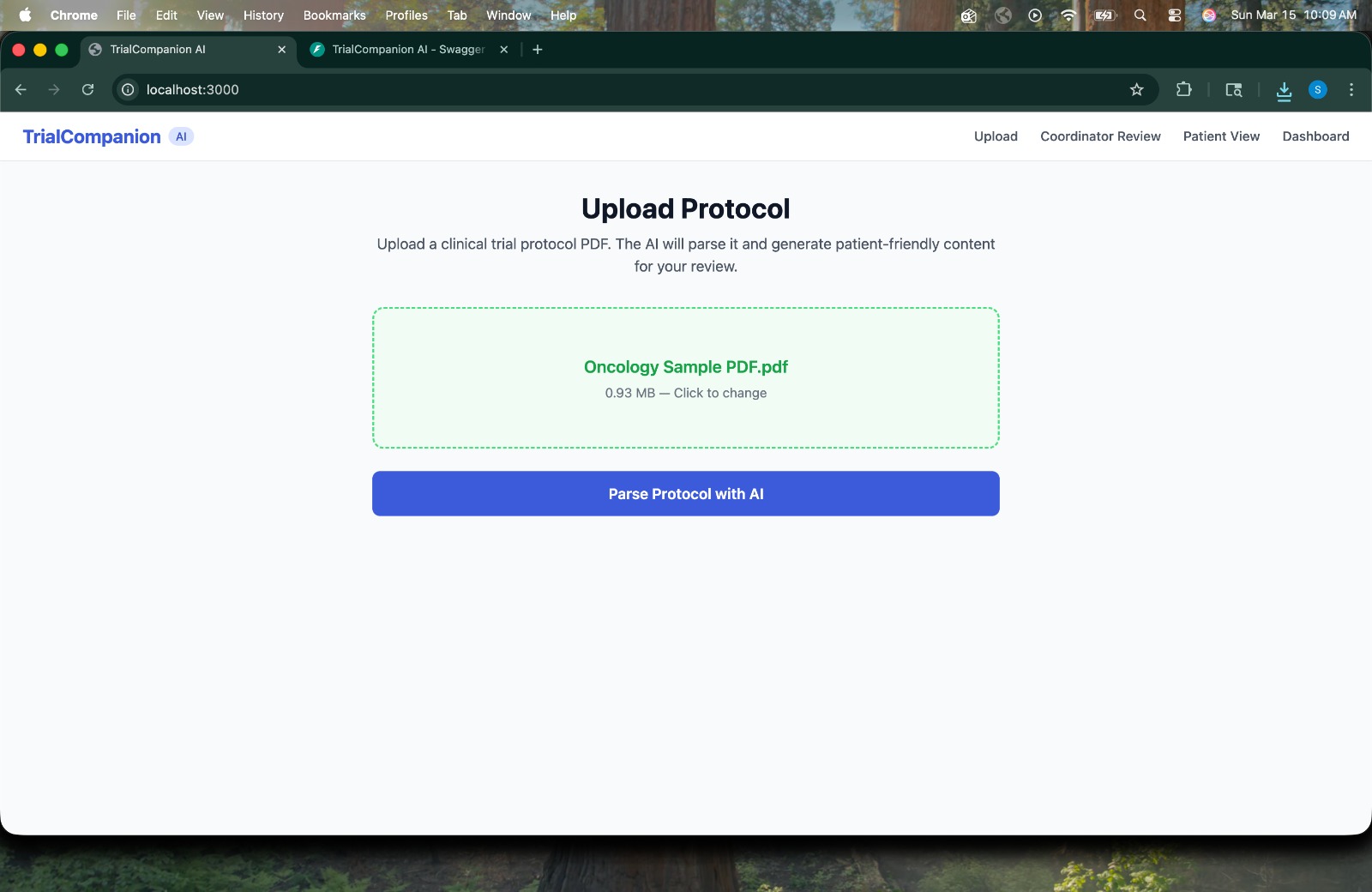
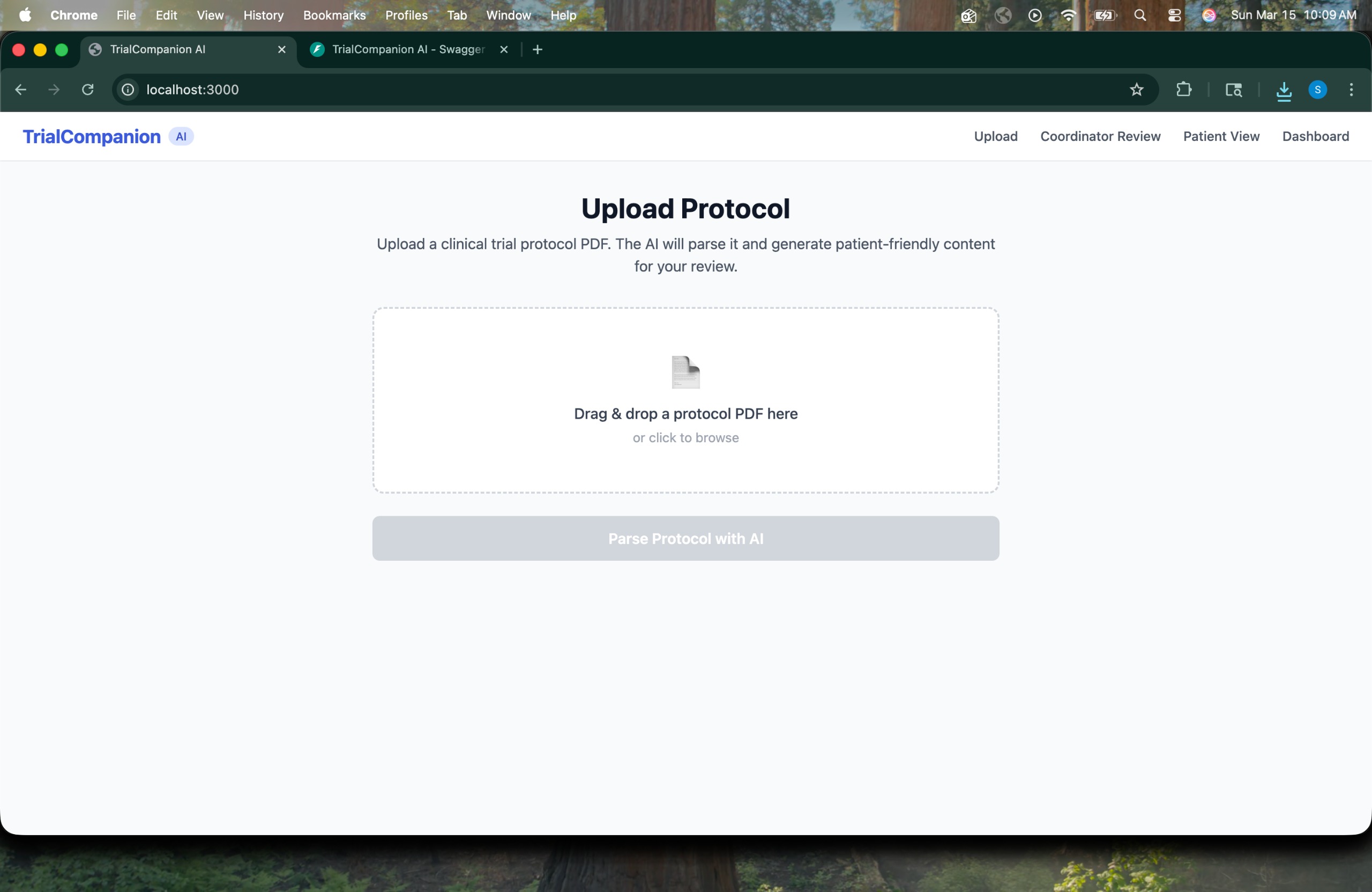
Upload Protocol -> Coordinator drag-and-drops a clinical trial protocol PDF to begin the pipeline.
-
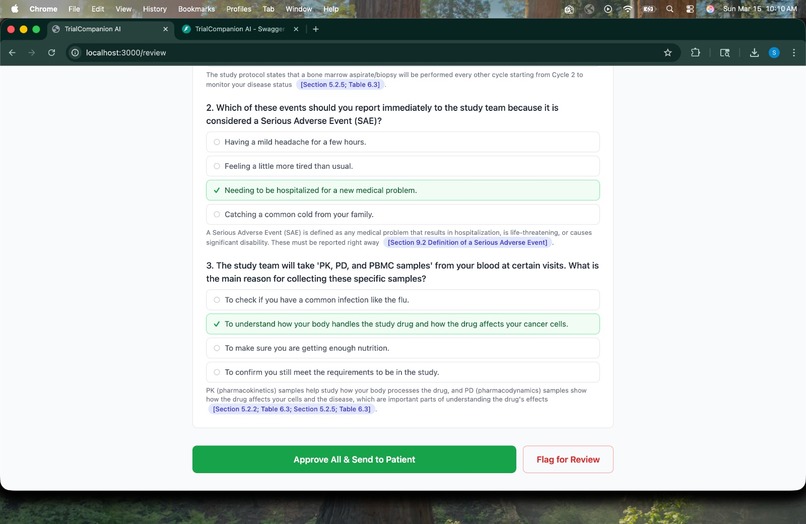
Human Approval Gate -> Coordinator reviews AI-generated comprehension quiz questions with cited answers, then approves or flags for review.
-
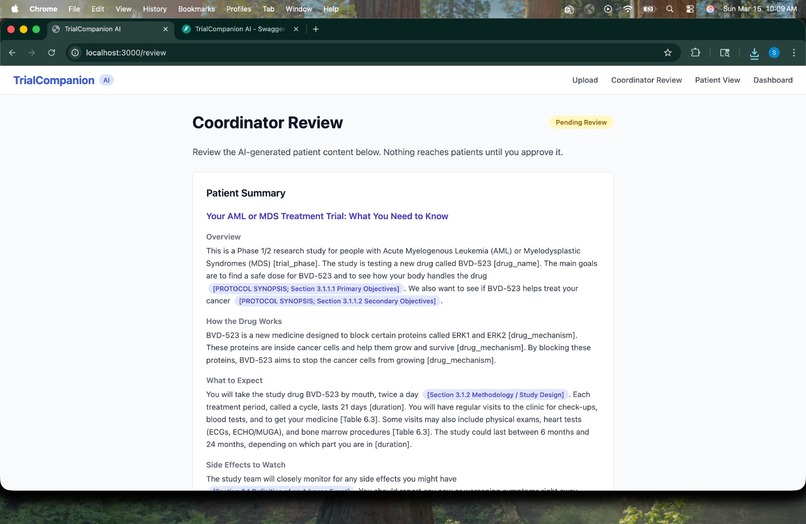
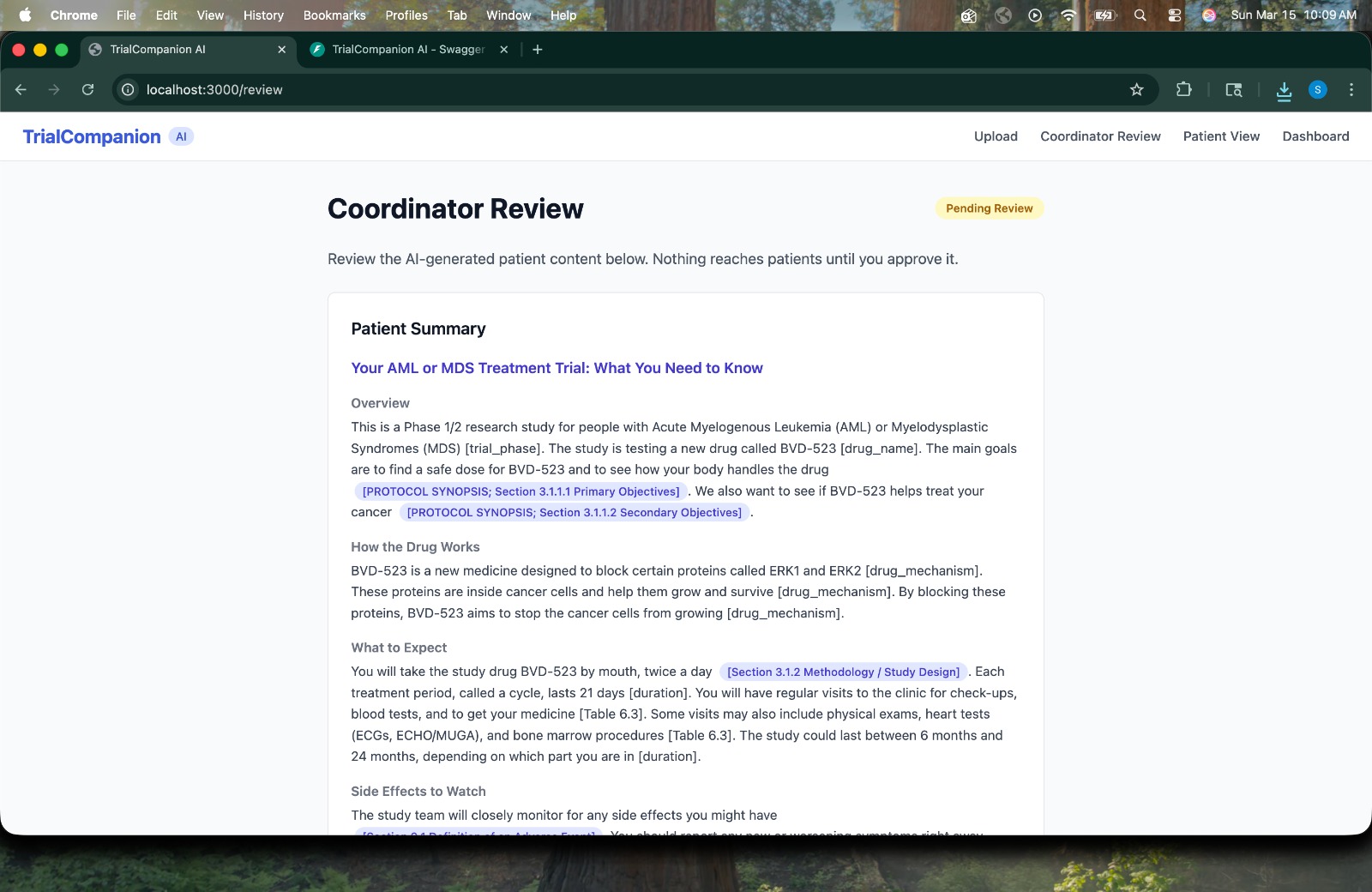
Coordinator Review -> AI-generated plain-language patient summary with protocol section citations, pending coordinator approval
-
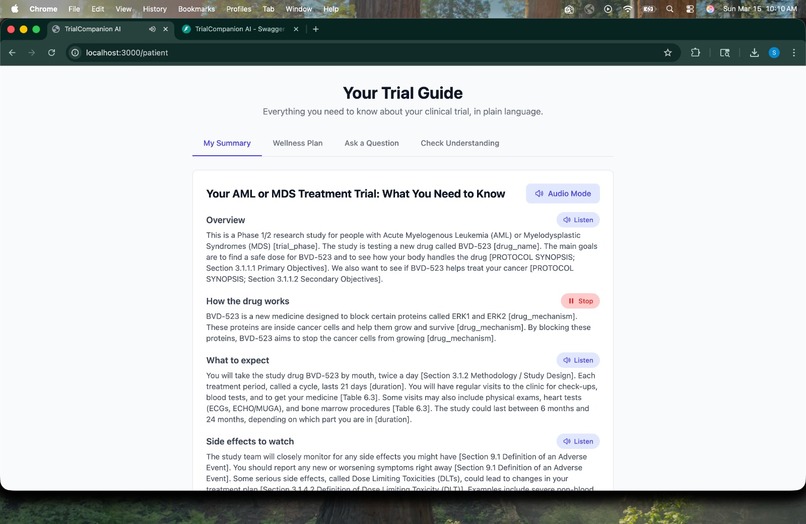
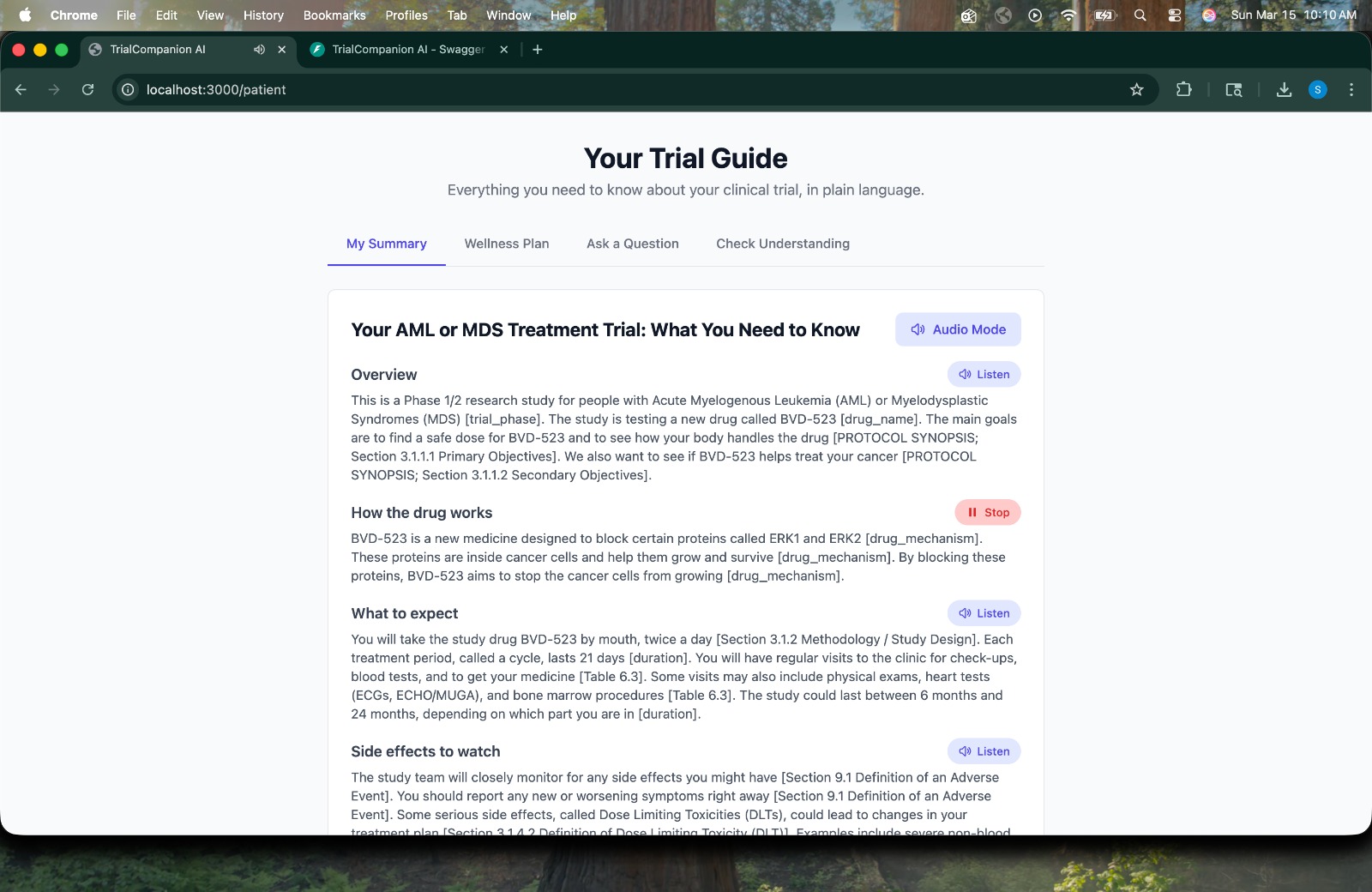
Patient Summary -> Plain-language trial guide with audio mode, breaking down the AML/MDS treatment trial for with section citations.
-
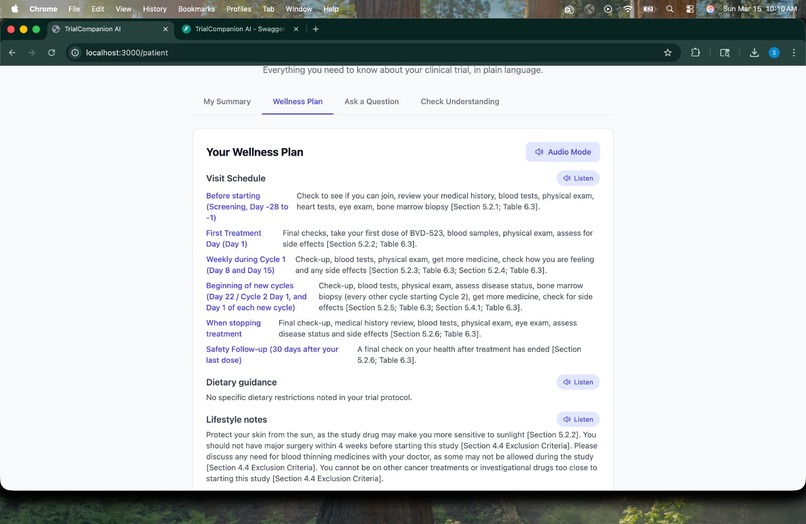
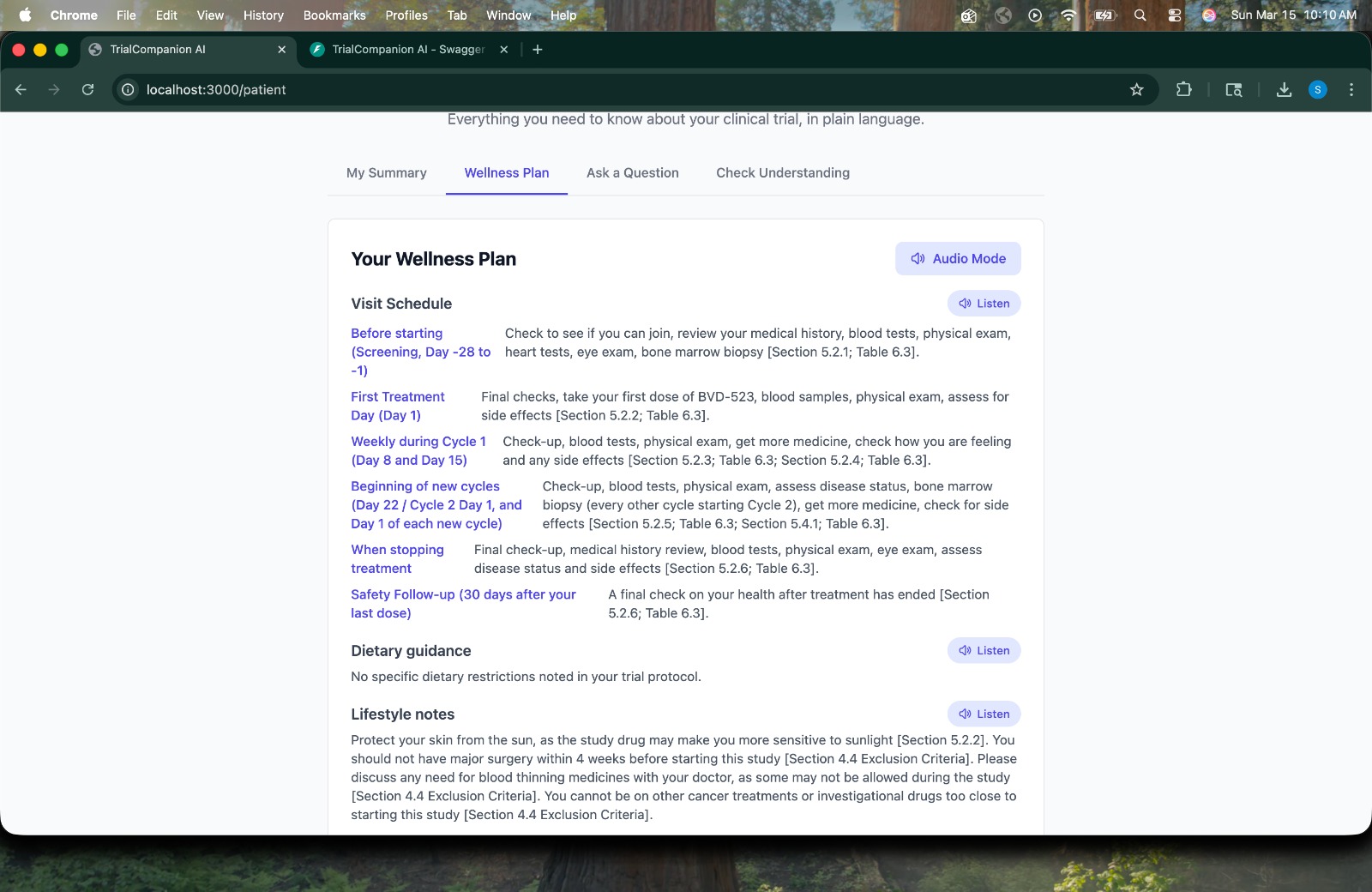
Wellness Plan -> Derived directly from the protocol with section citations.
TrialCompanion AI
Inspiration
Clinical trials are the backbone of modern medicine yet the patients who make them possible are often the least informed people in the room. The average clinical trial protocol runs 50+ pages of dense regulatory language, filled with medical jargon, latin terminology, and legal disclaimers that even educated non-clinicians struggle to parse.
We asked ourselves a simple question: what if a patient could just ask their trial protocol a question and get a plain, honest answer?
That question became TrialCompanion AI.
What We Built
TrialCompanion AI is an end-to-end platform that transforms clinical trial protocols into patient-friendly content. A research coordinator uploads a protocol PDF and our system handles the rest:
- Smart Protocol Parser -> extracts structured data including endpoints, visit schedules, adverse events, and eligibility criteria.
- Plain-Language Summary -> rewrites the protocol in plain language with citations to specific protocol sections.
- Patient Q&A Chatbot -> answers patient questions strictly from the approved protocol, never from external knowledge.
- Trial Wellness Plan -> can generate personalized visit schedules, dietary guidance, and symptom tracking checklists.
- Comprehension Quiz -> auto-generated questions to measure patient understanding, with scores surfaced on the coordinator dashboard.
- Patient Matching Engine -> converts eligibility criteria into structured rules and matches patients from the database automatically.
Every AI output is gated behind a human approval step -> nothing reaches patients without coordinator sign-off.
How We Built It
Tech Stack
| Layer | Technology |
|---|---|
| AI Model | Gemini 2.5 Flash |
| Backend | Python, FastAPI, SQLAlchemy |
| PDF Parsing | pdfplumber |
| Auth | JWT (python-jose), passlib |
| Database | PostgreSQL (Supabase) |
| Frontend | React, Tailwind CSS, shadcn/ui |
Architecture
The core pipeline follows a simple flow:
$$ \text{PDF} \rightarrow \text{Raw Text} \rightarrow \text{Structured JSON} \rightarrow \text{Approval Gate} \rightarrow \text{Patient Content} $$
Protocol text is extracted page by page, sent to Gemini with carefully engineered system prompts, and returned as structured JSON with section citations.
The patient eligibility engine converts free-text criteria into machine-readable rules. A match ratio is computed for each patient:
$$ \text{match_ratio} = \frac{\text{rules matched}}{\text{applicable rules}} $$
Patients with a match ratio ( > 0.6 ) are shortlisted. Those above ( > 0.8 ) are automatically invited to the trial.
Challenges We Faced
1. Rate Limits at the Worst Time
Gemini's API rate limits had to be dealt with constantly throughout the duration of live testing with multiple endpoints, each making separate AI calls, we burned through quotas quickly.
2. Local LLM Integration
We explored running the AI fully on-device using locally hosted open-source models (Ollama + Meditron, LLaMA 3) to eliminate rate limits and keep sensitive clinical data off third-party servers entirely. We ran into a fundamental challenge; most medical LLMs like Meditron are base models, not instruction-tuned, meaning they excel at medical knowledge but struggle to follow strict output format instructions like returning valid JSON consistently. This is a known tradeoff in the open-source medical LLM space and remains an active area of our development.
4. Preserving Blinding Integrity
Clinical trials often involve randomized, blinded treatment assignments. We had to ensure our system never surfaces blinding information to patients, even if it appears in the uploaded protocol. This required explicit guardrails in every prompt and careful review of AI outputs during testing.
What We Learned
- Human-in-the-loop isn't just an ethical choice, it's a product feature. Coordinators trusted the system more once they understood nothing reached patients without their explicit approval.
- Base models vs instruction-tuned models is a critical distinction when building production AI systems that need to follow strict output contracts.
- The gap between what AI can do and what patients actually receive in clinical trials is a real, solvable problem and the solution doesn't require reinventing medicine, just better communication.
What's Next
- Local LLM deployment -> replacing Gemini with a fine-tuned instruction-tuned medical LLM running fully on-premise for HIPAA compliance.
- Fine-tuning on coordinator-approved data -> using the approval gate as a data flywheel to continuously improve output quality.
- Multi-language support -> translating summaries for non-English speaking patients.
- EHR integration -> pulling patient data directly from electronic health records for automated eligibility matching.
Built With
- fastapi
- gemini-2.5-flash
- gemini-api
- llama3
- passlib
- pdfplumber
- python
- python-jose
- react
- sqlalchemy
- supabase

Log in or sign up for Devpost to join the conversation.