💡 Inspiration
Healthcare has a communication problem. After a consultation, patients leave confused — half-remembering what the doctor said, unsure what their lab results mean, and anxious about next steps. On the other side, doctors drown in documentation: transcribing notes, filing EMRs, and cross-referencing records when they should be focused on healing.
We asked a simple question: what if AI could sit in the room and handle all of that?
EarlyAxxess was born from the intersection of three pain points we kept hearing about: patients who don't understand their own health, doctors who spend more time on paperwork than patients, and hospitals burdened with manual administrative workflows. We wanted to build something that was genuinely useful at all three layers simultaneously.
⚙️ What it does
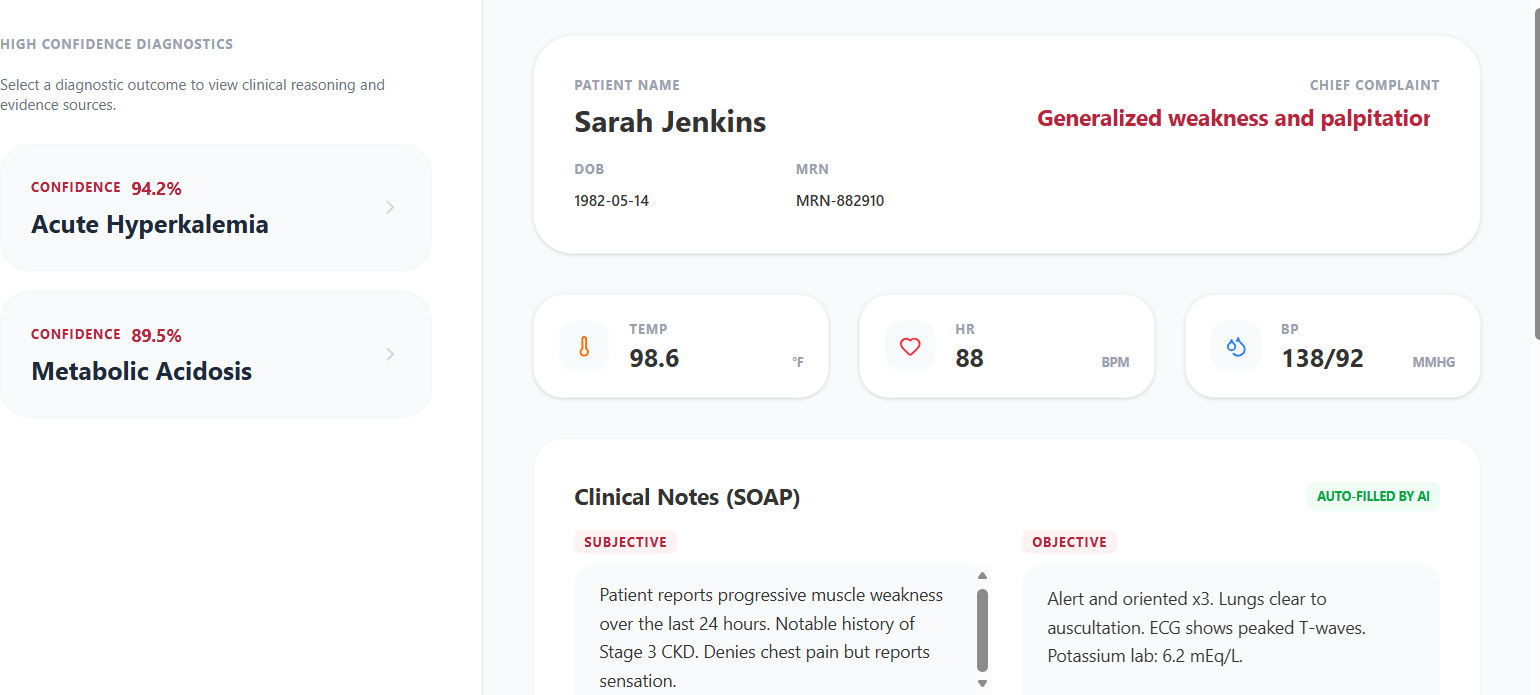
- Digestible Patient Summaries: Plain-language consultation recaps generated after every appointment, covering diagnoses, next steps, and what the lab results actually mean.
- GraphRAG Diagnostic Assist for Doctors: Weighted causal path reasoning over a merged PrimeKG + Hetionet knowledge graph, ranked by Bayesian confidence, with full citations back to source documents.
- What-If Simulator: Remove a hypothesized cause from the graph and watch the reasoning re-run in real time, showing which alternative explanations gain weight.
- Unexplained Symptom Gap Detection: Surfaces symptoms with no current causal explanation and generates targeted follow-up questions or lab suggestions.
- EMR Auto-Filing: Structured entity extraction (symptoms, medications, labs, vitals with page numbers) packaged for automated hospital record entry.
- Hallucination Guard: Every LLM response is validated against the actual subgraph before it reaches the user.
🛠️ How we built it
- Frontend Interface: We built a sleek, responsive Single Page Application (SPA) using React and Vite, styled with Tailwind CSS. We utilized
react-router-domto manage distinct views for different user personas (e.g., the Doctor Dashboard, Patient Dashboard, and Live Recording view) and used Lucide React for clean, medical-appropriate iconography. - AI & Natural Language Processing: We heavily leveraged the new Gemini API (
google-genai) across several Python micro-scripts to handle the core logic:diarize.py: Analyzes conversation transcripts and uses Gemini to accurately label speaking turns (Doctor vs. Patient), with a built-in alternating fallback.generate_emr.py: Uses few-shot prompting to force Gemini to extract clinical data from transcripts and output strict, perfectly formatted JSON containing SOAP notes, vitals, and ICD-10 codes.summarize.py: Transforms complex medical jargon into 5th-grade reading-level summaries so patients can easily digest their visit.chat.py: Utilizes Gemini's chat session functionality, pre-loaded with a strict system instruction and the patient's transcript, to act as a contextual medical assistant.
- Speech-to-Text: We implemented dual transcription methods—a browser-based version using the Web Speech API for frictionless demos, and a Python-based script (
transcribe.py) utilizing thespeech_recognitionlibrary for local microphone and WAV file processing.
🚧 Challenges we ran into
- Making it actually viable: The hardest problem wasn't building any individual component — it was making the whole system coherent. Merging PrimeKG and Hetionet via UMLS CUI, preventing Firebase/Neo4j divergence, and ensuring LLM outputs stay grounded in the graph required architectural decisions we had to revisit multiple times.
- Zero Tolerance for Hallucinations: Hallucination in a medical context is unacceptable. LLMs confidently invent medical relationships. We iterated through several prompting strategies before landing on our constraint-based approach combined with the Graph Validator fallback. The goal: if the model mentions anything not in the user's subgraph, we catch it and surface a safe template instead.
- Seamless integration across personas: A patient wants a plain-English summary they can share with family. A doctor wants ranked differential hypotheses with citations. A hospital administrator wants structured EMR data filed automatically. Building one pipeline that serves all three without becoming bloated required careful API design and modular frontend components.
- Scaling the NLP Model: Scale with an 8GB-per-worker NLP model was tough. MedCAT is accurate but memory-hungry. We isolated NLP workers into a dedicated pool to avoid starving sync and reasoning workers — a small architectural decision that made load testing with 10 concurrent PDF uploads actually pass.
🏆 Accomplishments that we're proud of
- Multi-Persona UI Design: We successfully designed and implemented a beautiful, intuitive frontend that caters to completely different user needs—giving doctors a dense, data-rich EMR interface and patients a warm, accessible summary dashboard.
- Robust Prompt Engineering: We successfully engineered strict prompts that force the LLM to return complex medical data as pure, parseable JSON for the EMR auto-filing, preventing the system from breaking due to markdown formatting or hallucinations.
- Fail-Safe Architecture: We built resilient Python backend scripts that gracefully handle API failures. For example, if the Gemini API times out during speaker diarization, the system automatically falls back to an alternating "Doctor/Patient" logic rather than crashing the pipeline.
🧠 What we learned
- SDK Migration & API Handling: We learned the intricacies of migrating to the modern
google-genaiSDK, specifically how to properly format configuration types for system instructions and handle asynchronous API limits. - Context Window Management: By building the Patient Chatbot, we learned how to effectively inject a full transcript file into an LLM's context window as a hidden first message, allowing the bot to instantly act as an expert on that specific patient's visit.
- The Gap Between Demo and Production: We learned that while getting an LLM to generate text is easy, forcing it to generate structured, predictable data (like our EMR JSON generator) requires meticulous instructions, fallback templates, and rigorous error catching.
🚀 What's next for EarlyAxxess
- SMART on FHIR Integration: Now that we are successfully generating highly structured, graph-validated EMR data, the next logical step is to move beyond JSON exports. We plan to implement the SMART on FHIR standard to allow EarlyAxxess to securely push documentation directly into live hospital systems like Epic or Cerner without friction.
- Real-Time Multilingual Triage: Language barriers are a massive bottleneck in emergency rooms. We want to upgrade our audio pipeline to not only diarize and transcribe, but to actively translate non-English speakers in real-time. This would allow a patient to explain their symptoms in Spanish or Japanese, while the GraphRAG and EMR generation processes the data and outputs the medical insights in English for the doctor.
- Longitudinal Patient Graphs: Currently, our Knowledge Graph runs localized predictions based on a single triage conversation. We want to expand the graph's capability to link a patient's historical visits over time, allowing the AI to detect slow-moving chronic conditions that a doctor might miss in a fast-paced ER environment.
- Voice Biomarker Analysis: While our current system extracts profound insights from the text of the conversation, we want to train additional machine learning models on the raw audio data itself. By analyzing acoustic features like speech rate, pitch variability, and breathlessness, EarlyAxxess could objectively score a patient's pain level or respiratory distress before the doctor even enters the room.
Built With
- firebase
- flask
- gemini
- graphdb
- html5
- javascript
- natural-language-processing
- python
- react
- tailwindcss

Log in or sign up for Devpost to join the conversation.