-
-
Digital Ocean APP
-
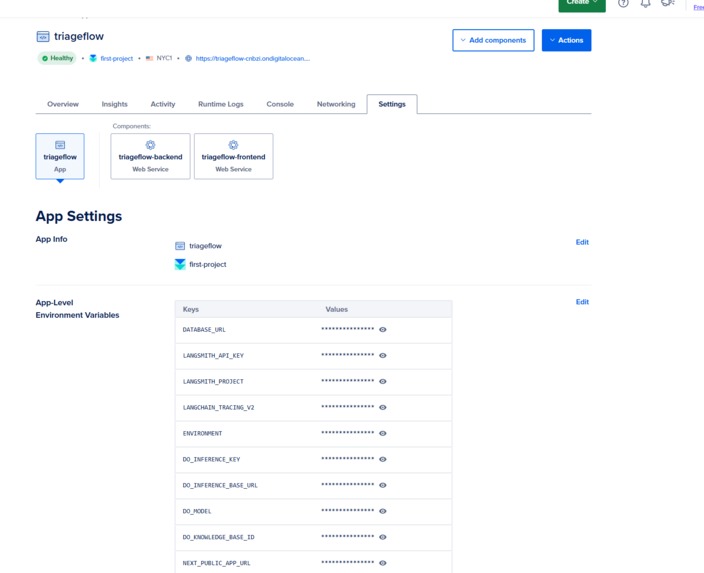
Digital Ocean APP
-
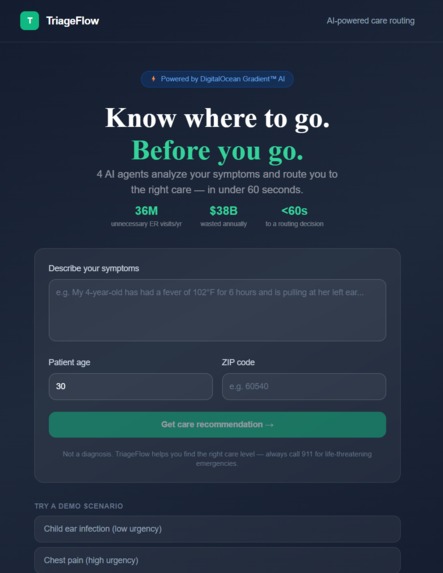
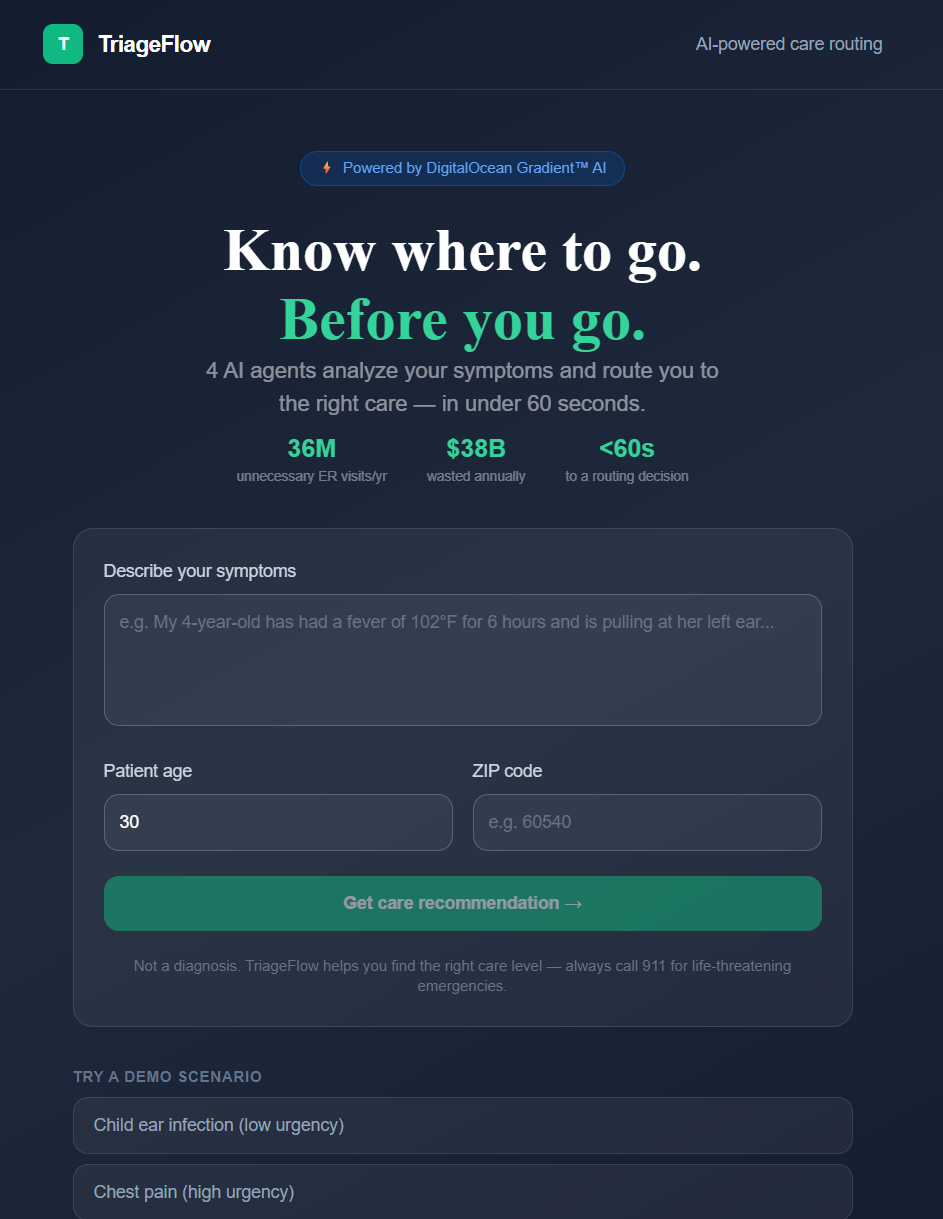
Landing Page
-
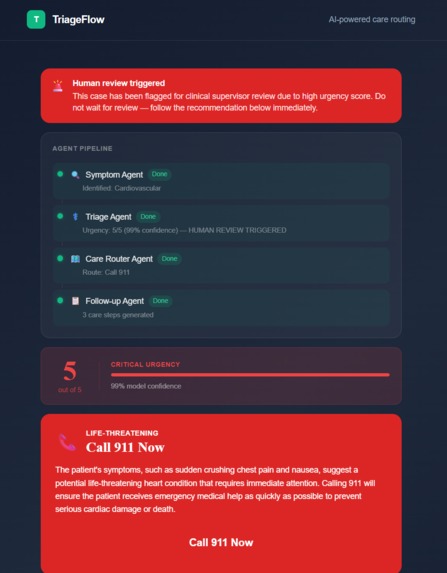
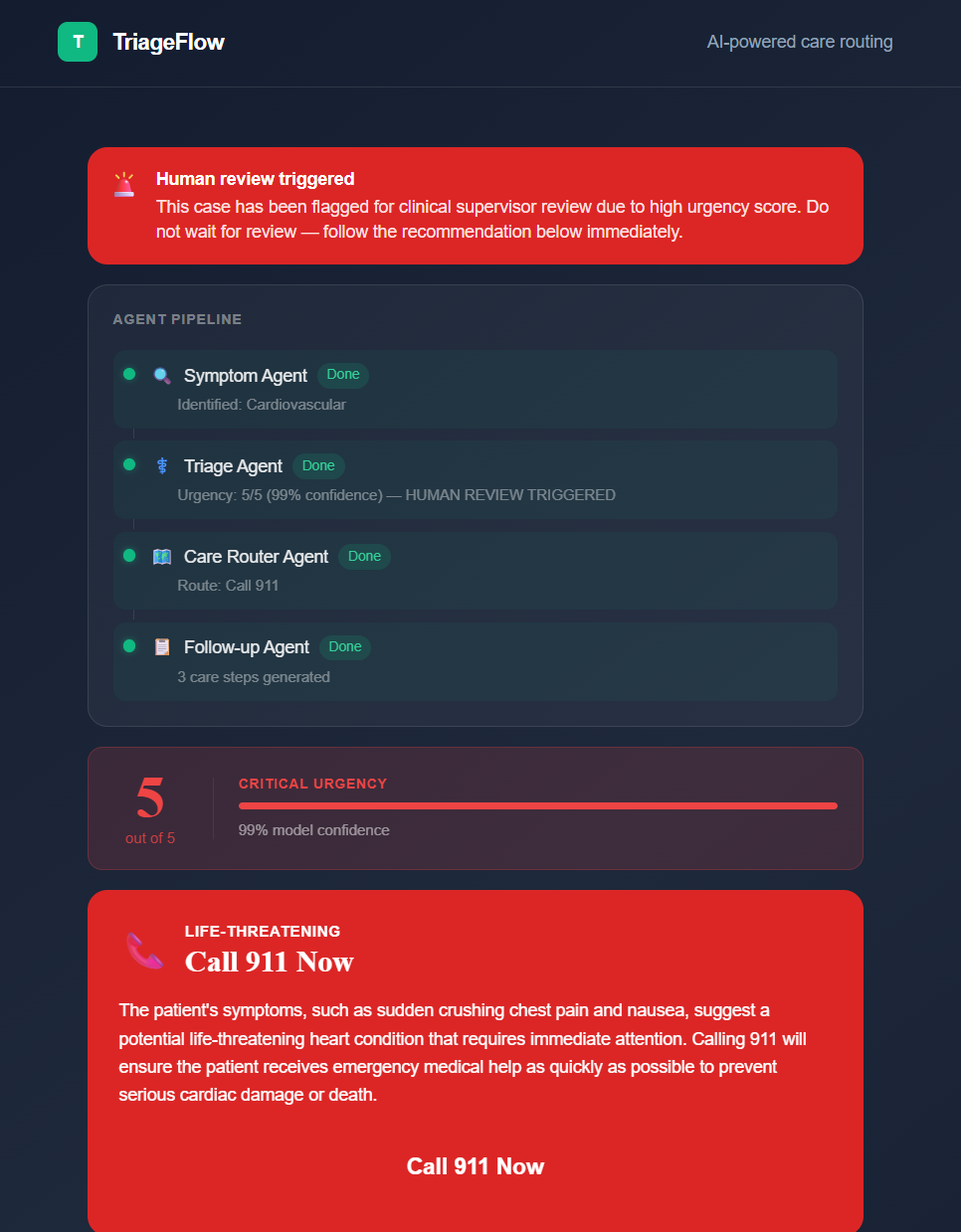
Output
-
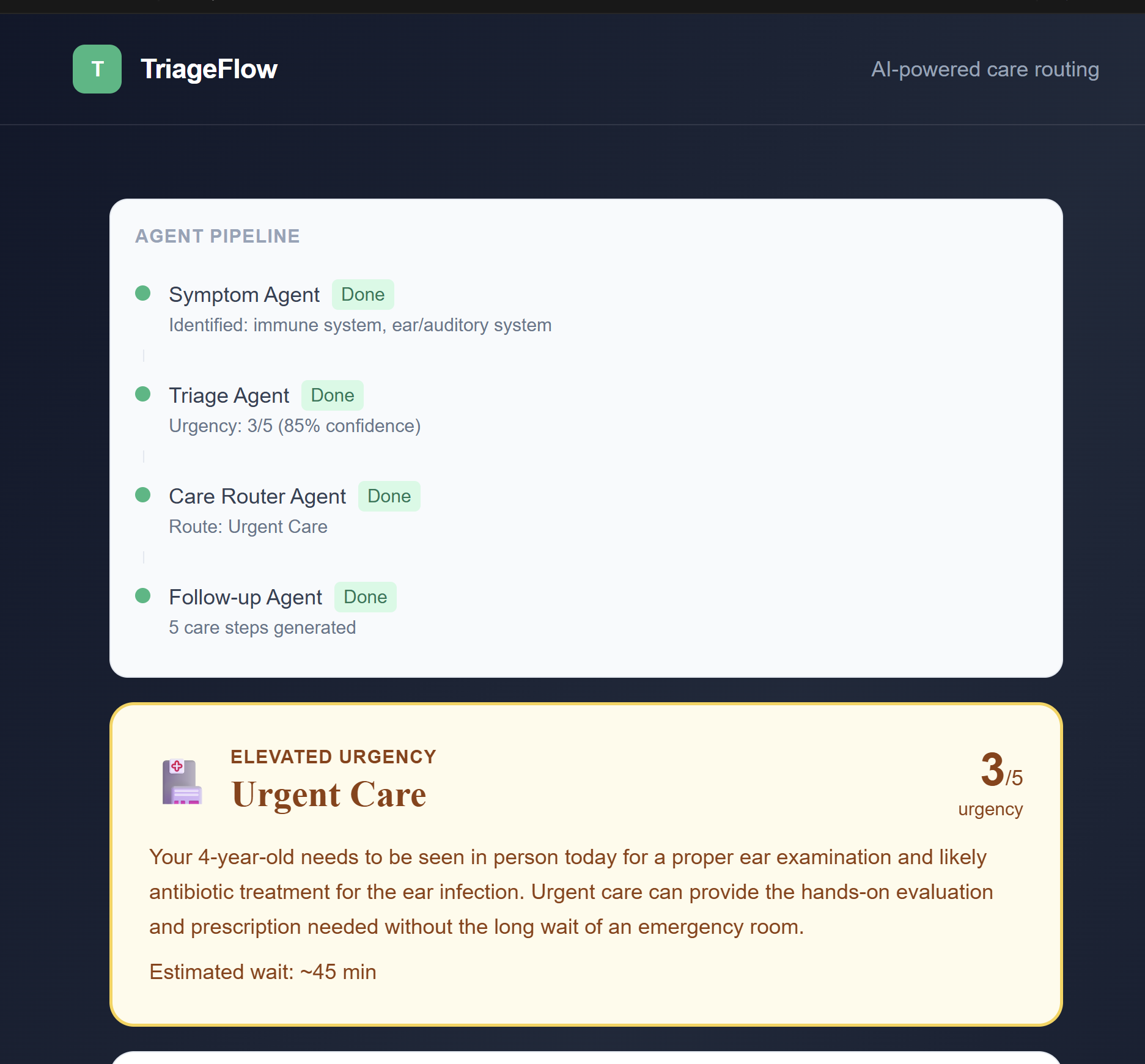
OUTPUT
-
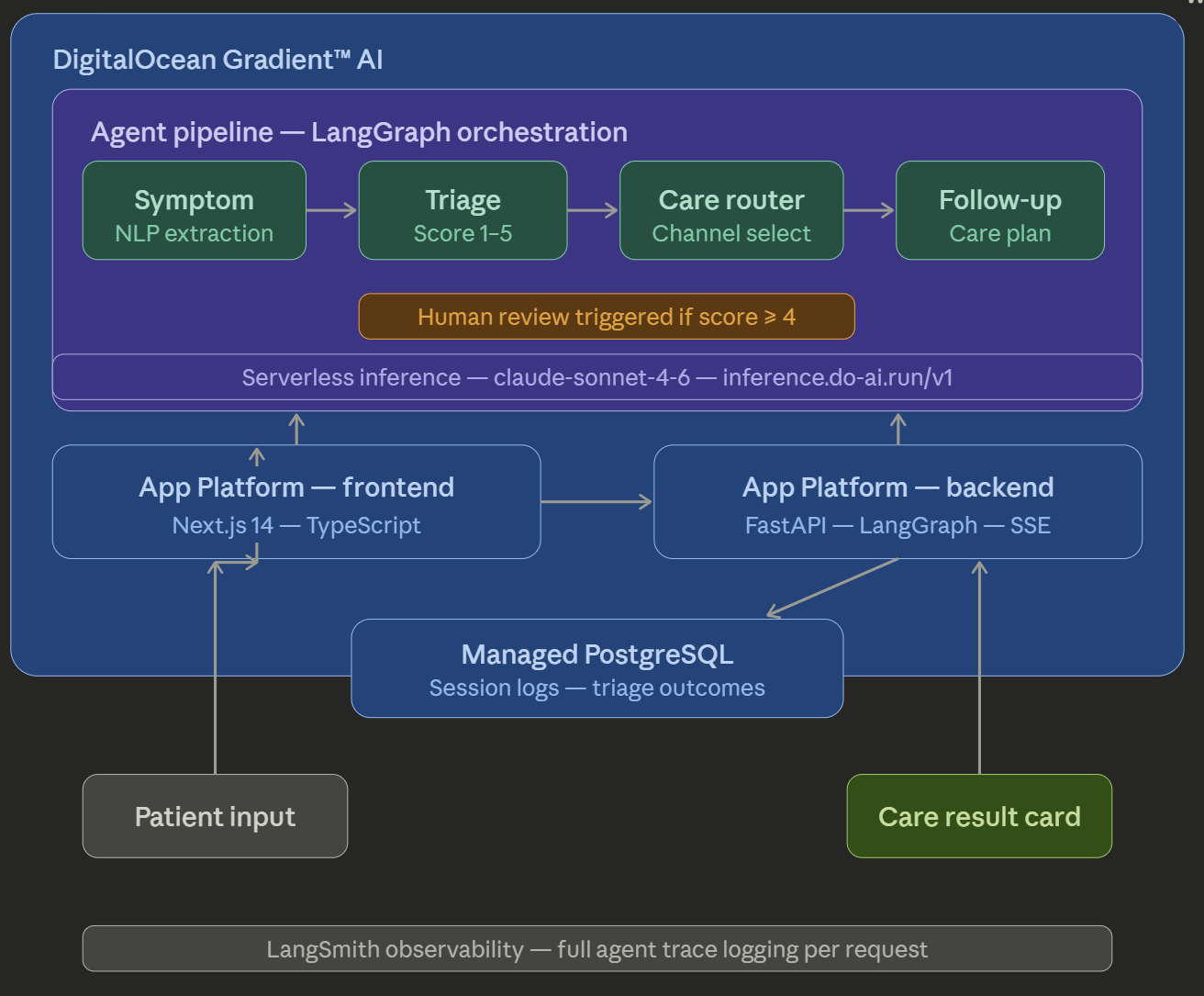
Architecture Diagram
The Problem That Kept Us Up at Night
It's midnight. Your child has a fever of 102°F and is crying. Do you drive to the ER? Wait until morning? Google it and spiral into worst-case scenarios?
Right now, there is no good answer for most people. And that gap is costing the healthcare system dearly.
27 million Americans visit the ER unnecessarily every year. That is 27 million families who drove past a telehealth option, waited 4.5 hours in a waiting room, and paid an average of $1,400 for care they could have received from their couch at 11pm for $40.
Meanwhile, the people who genuinely need emergency care wait longer because the waiting room is full of people with ear infections.
This is the problem TriageFlow was built to solve.
What Inspired Us
We kept coming back to one question: why does a person with chest pain and a person with a cold end up in the same waiting room?
The answer is not that people are careless. It is that there is no accessible, real-time system that gives a confident, personalized routing decision before you commit to a care channel. WebMD tells you that a headache might be a brain tumor. That is not guidance. That is anxiety.
We wanted to build the missing middle option. Something that takes your specific symptoms, your age, your location, and tells you exactly where to go and why, in plain English, in under 60 seconds.
Not a diagnosis. A direction.
How We Built It
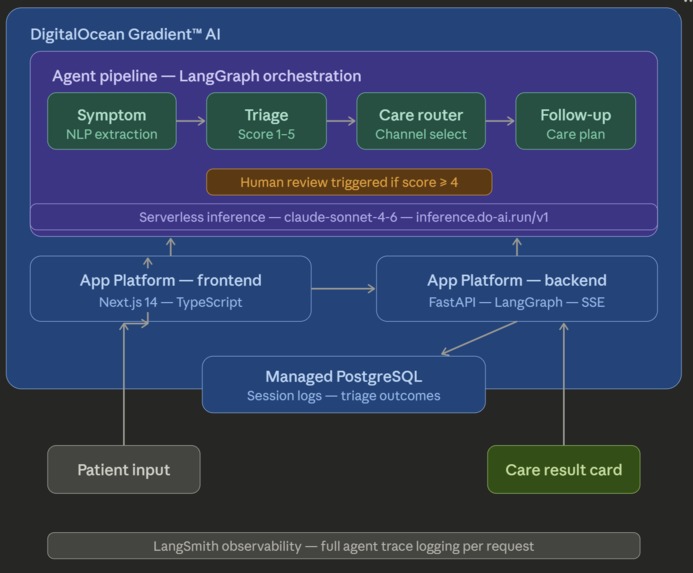
TriageFlow is a four-agent AI pipeline built on DigitalOcean Gradient™ AI Serverless Inference, orchestrated with LangGraph, deployed on DigitalOcean App Platform, and backed by DigitalOcean Managed PostgreSQL.
The pipeline works like a clinical relay race:
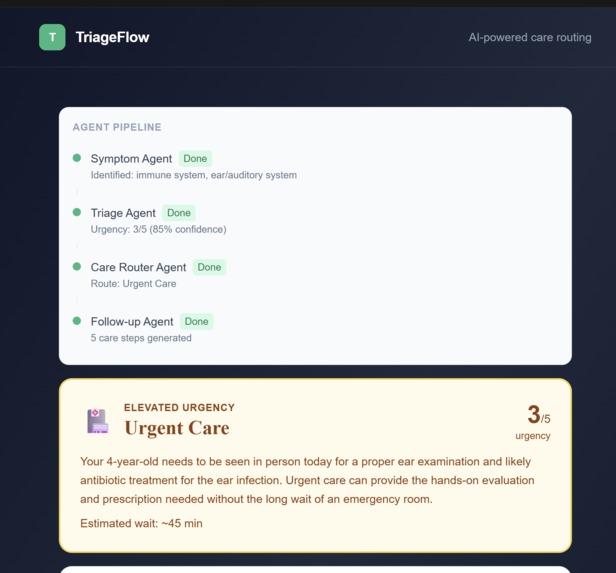
Agent 1: Symptom Agent
Takes the patient's free-text description and extracts structured clinical entities: which body systems are involved, duration, severity keywords, age risk factors, and red flag terms like "chest pain" or "difficulty breathing." This converts messy human language into precise medical signal.
Agent 2: Triage Agent
Receives the structured entities and scores urgency on a 1 to 5 scale using clinical triage methodology based on real START and SALT protocols. This is where DigitalOcean Gradient™ AI does the heavy lifting, running inference against a model fine-tuned on clinical triage logic.
$$\text{Urgency Score} = f(\text{red flags}, \text{body systems}, \text{duration}, \text{age risk})$$
A score of 1 means home care is appropriate. A score of 5 means call 911 immediately.
Agent 3: Care Router Agent
Maps the urgency score and patient ZIP code to the right care channel: home care, telehealth, urgent care, ER, or 911. For any case scoring 4 or higher, a human review flag triggers before the patient is routed. The AI never autonomously handles life-threatening decisions alone.
Agent 4: Follow-up Agent
Generates a personalized care checklist, specific warning signs to watch for, and when to reassess. If telehealth is recommended, it surfaces available appointment slots.
The entire pipeline runs on DigitalOcean Gradient™ AI Serverless Inference, with both the frontend and backend deployed on DigitalOcean App Platform and session data stored in DigitalOcean Managed PostgreSQL.
The Architecture
Patient Input (symptoms, age, ZIP)
|
v
Symptom Agent [DO Gradient™ Inference]
NLP entity extraction
|
v
Triage Agent [DO Gradient™ Inference]
Urgency scoring 1-5
|
score >= 4?
/ \
Human Care Router Agent [DO Gradient™ Inference]
Review Channel selection
|
v
Follow-up Agent [DO Gradient™ Inference]
Care plan generation
|
v
Patient Result Card
(channel + steps + warnings)
Every inference call runs through DigitalOcean Gradient™ AI. The frontend is Next.js on App Platform. The backend is FastAPI on App Platform. The database is DigitalOcean Managed PostgreSQL. Agent traces are logged to LangSmith for full observability.
The Business Case
The math is straightforward:
| Metric | Value |
|---|---|
| Unnecessary ER visits per year (US) | 27 million |
| Average cost per unnecessary ER visit | $1,400 |
| Total annual waste | $38 billion |
| Cost per TriageFlow triage | $0.12 |
| ROI if 10% of unnecessary visits rerouted | $3.78 billion saved |
$$\text{ROI} = \frac{0.10 \times 27{,}000{,}000 \times \$1{,}400}{\$0.12 \times 27{,}000{,}000} = 11{,}667\times$$
At $0.12 per triage versus $1,400 per unnecessary ER visit, TriageFlow does not need to be perfect to be enormously valuable. It needs to be right often enough to matter. Based on our testing, it routes correctly on the scenarios that count most.
What We Learned
Multi-agent is not just an architecture pattern. It is a trust mechanism. When one AI does everything, you cannot audit it. When four specialized agents each do one job with observable outputs, you can see exactly where the reasoning is strong and where it needs a human. That auditability is what makes this deployable in healthcare rather than just impressive in a demo.
Human-in-the-loop is not a limitation. It is the feature. Early in the build we considered letting the Care Router Agent handle all urgency levels autonomously. We decided against it. Any case scoring 4 or 5 triggers a human review flag before routing. That decision made the system more trustworthy, not less capable.
DigitalOcean Gradient™ AI made the infrastructure disappear. We did not spend time on GPU provisioning, inference optimization, or multi-vendor API key management. The serverless inference endpoint gave us production-grade LLM access with a single API key and predictable per-token pricing. That let us spend our time on the agent logic, not the plumbing.
Challenges We Faced
Streaming four agents over SSE to a Next.js frontend was the
hardest technical problem. Each agent needed to emit real-time
progress updates while the pipeline was still running, pipe those
updates through a FastAPI SSE endpoint, and render them live in
the browser without blocking. We went through three different
streaming architectures before landing on the current approach
using LangGraph's astream with accumulated state.
Structured JSON output from LLMs is deceptively hard. Each agent needs to return a precise Pydantic schema. LLMs occasionally add markdown fences, preamble text, or slightly wrong field names. We added robust JSON extraction and retry logic to each agent to handle these edge cases gracefully.
Deploying a monorepo to DigitalOcean App Platform required learning the app spec YAML format and Dockerfile approach to tell the platform exactly where each component lived. The auto-detection logic did not handle subdirectories well out of the box. Once we added explicit Dockerfiles for both frontend and backend and configured the app spec correctly, deployment became reliable and automatic on every push.
The human review threshold calibration took more iteration than expected. Too sensitive and it triggers on every moderate case, undermining user trust. Too permissive and it misses cases that genuinely need oversight. We settled on urgency score 4 of 5 as the threshold, which catches chest pain, stroke symptoms, and severe allergic reactions while letting the agent handle the majority of cases autonomously.
What Is Next
TriageFlow in its current form is a proof of concept with production infrastructure. The next steps we would pursue:
Integration with real telehealth APIs (Teladoc, Sesame Care) to surface actual appointment availability and enable one-click booking from the result card.
A fine-tuned triage model trained on clinical triage datasets rather than a general-purpose LLM with triage prompting. This would improve accuracy on edge cases and reduce token usage per inference call.
Multilingual support using DigitalOcean Gradient™ AI's multilingual model options. Non-English speakers are among the most underserved populations for healthcare navigation.
An API layer so hospitals, urgent care networks, and insurance companies can embed TriageFlow routing into their own patient-facing applications.
Built With
- DigitalOcean Gradient™ AI Serverless Inference (claude-sonnet-4-6)
- DigitalOcean App Platform (frontend + backend deployment)
- DigitalOcean Managed PostgreSQL (session storage)
- LangGraph (multi-agent orchestration)
- FastAPI (backend API + SSE streaming)
- Next.js 14 (frontend)
- LangSmith (agent observability)
- Pydantic (structured agent outputs)
- TypeScript + Tailwind CSS (frontend)
Built With
- ai
- app
- claude
- css
- digitalocean
- docker
- fastapi
- gradient
- langgraph
- langsmith
- managed
- next.js
- platform
- postgresql
- pydantic
- python
- sonnet
- sse
- tailwind
- typescript


Log in or sign up for Devpost to join the conversation.