Inspiration
Every production incident starts the same way: someone gets paged at 2am, opens their laptop, and spends the first ten minutes doing the same mechanical work — reading the alert, pulling traces, checking recent deploys, and forming a hypothesis. That work is high-stakes but low-creativity. It is exactly what an agent should do.
The hackathon prompt — "AI that doesn't just provide answers, it helps you take action" — described on-call response perfectly. So I am building an agent that does the boring first ten minutes of every incident, and lets the human stay in control of every action that touches production.
What it does
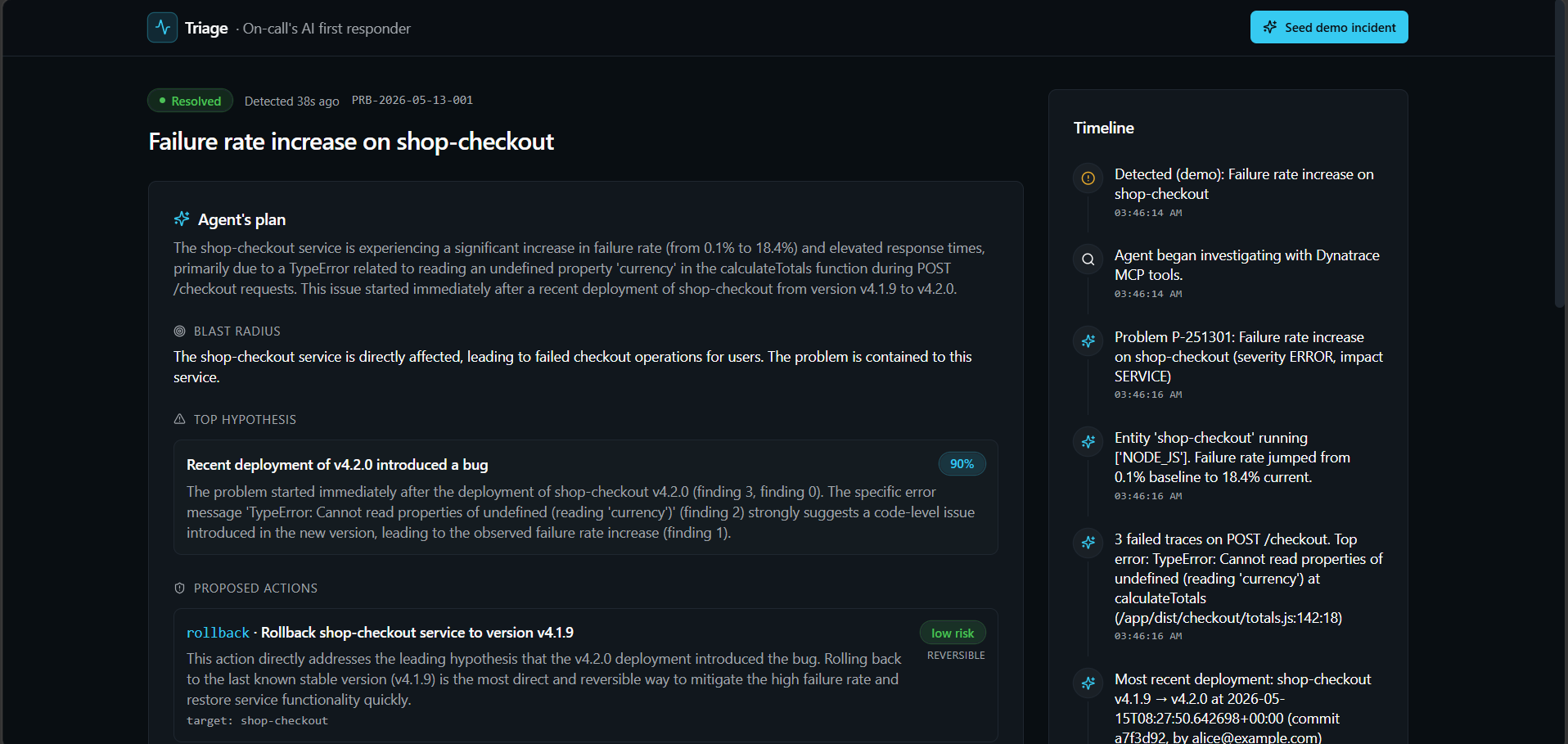
Triage is an autonomous on-call SRE agent that watches your Dynatrace tenant and responds to production incidents end-to-end:
- Listen — Dynatrace fires a problem; a webhook hits Triage.
- Investigate — The agent calls the Dynatrace MCP server to pull problem context, affected entities, recent traces, error logs, and change events.
- Reason — Gemini forms hypotheses ranked by confidence and impact.
- Plan — The agent proposes one to three concrete remediation actions (rollback, scale, restart, mute non-critical alerts).
- Approve — A human reviews the plan on a Next.js dashboard and approves with one click. Trusted action classes can be pre-approved.
- Act — The agent executes the approved actions via the Dynatrace MCP or external integrations.
- Verify — Polls Dynatrace until metrics recover, then writes a postmortem and closes the incident.
Every action that touches production is human-gated. The agent does the boring work; the human keeps the judgment.
How I'm building it
Orchestration: Google Cloud Agent Builder, with a plan-and-execute workflow that pauses at a human-approval gate before any state-mutating tool call.
Reasoning: Gemini, prompted to produce a structured IncidentPlan (hypotheses + actions + confidence) so the dashboard can render it deterministically.
Partner integration: the Dynatrace MCP server, giving the agent first-class access to problems, entities, traces, logs, and remediation actions.
Backend: a Python FastAPI service on Cloud Run that ingests Dynatrace webhooks, drives the agent loop, and brokers human approvals.
State: Firestore for incident timelines and approval queues.
Dashboard: a Next.js app, also on Cloud Run, where the operator sees the live timeline and approves proposed actions.
Auth: Firebase Auth.
Everything runs on Google Cloud — no competing-cloud dependencies — and is open source under Apache 2.0.
What's next for Triage
- Per-team auto-approve policies (rollback-only, never scale-down, etc.)
- Slack and Microsoft Teams adapters for the approval flow
- Multi-tenant deployment so a single Triage instance can serve multiple Dynatrace tenants
- Learned playbooks: incidents the agent has resolved before become higher-confidence first proposals
- A shadow mode where Triage proposes plans for every incident but never acts, used to build operator trust before flipping on auto-execute
Built With
- agent-builder
- cloud-run
- dynatrace
- fastapi
- firebase-auth
- firestore
- gemini
- google-cloud
- mcp
- nextjs
- python
- shadcn-ui
- typescript

Log in or sign up for Devpost to join the conversation.