Inspiration
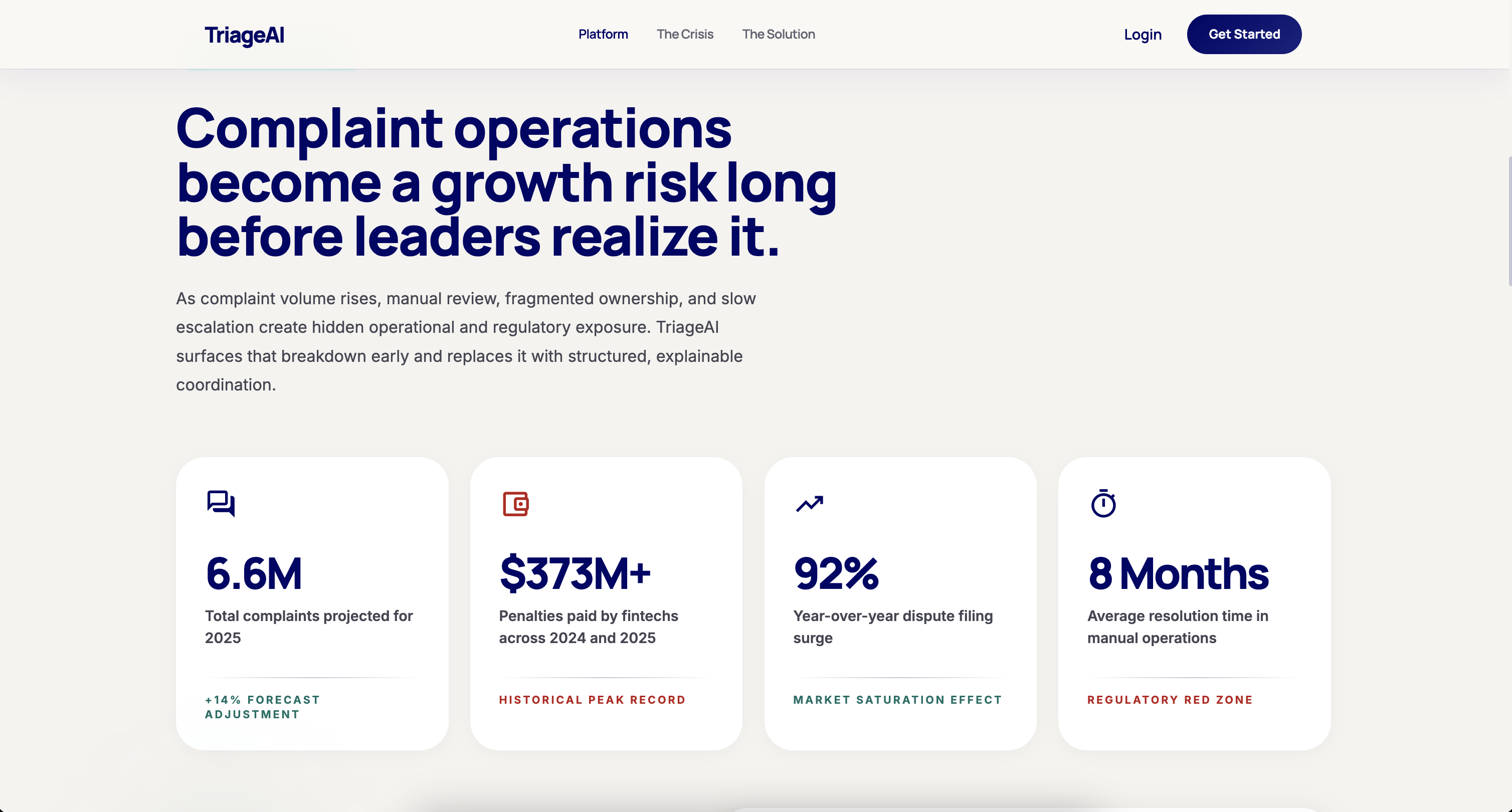
Financial institutions process millions of complaints every year. Each one is manually read, categorized, risk-assessed, and routed by a human analyst — a process that takes 10-20 days to resolve a case, burns compliance budgets, and still misses critical escalations. Regulators in the UK, EU, and US are tightening resolution deadlines. The cost of failure is existential.
We asked: what if every complaint was handled with the precision of your best analyst, at the speed of a machine, with a full audit trail — automatically?
That question became Triage AI.
What it does
Triage AI is an autonomous, multi-agent complaint resolution platform built for financial services.
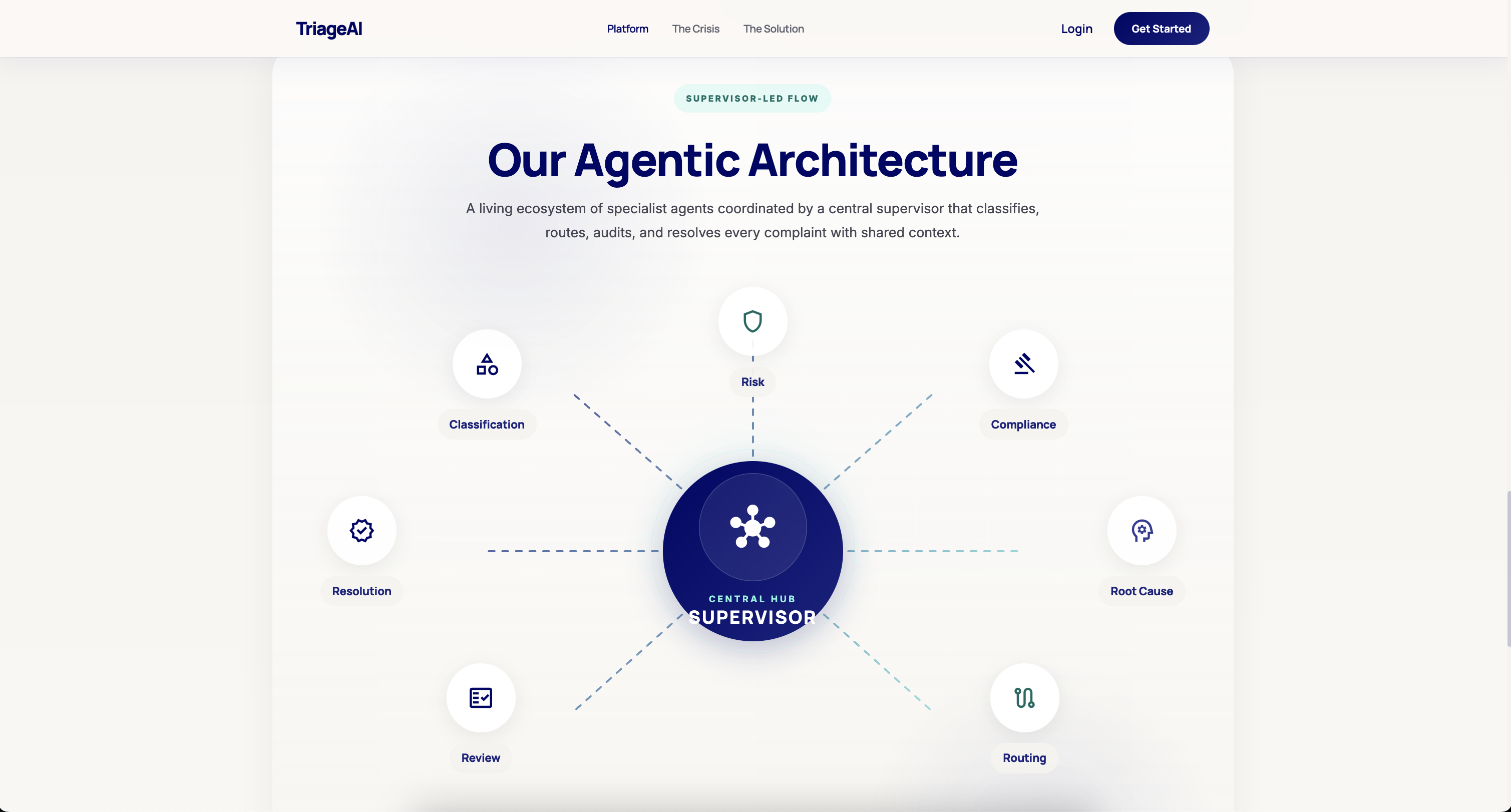
From the moment a complaint is submitted — via web form or voice — a coordinated pipeline of specialized AI agents takes over:
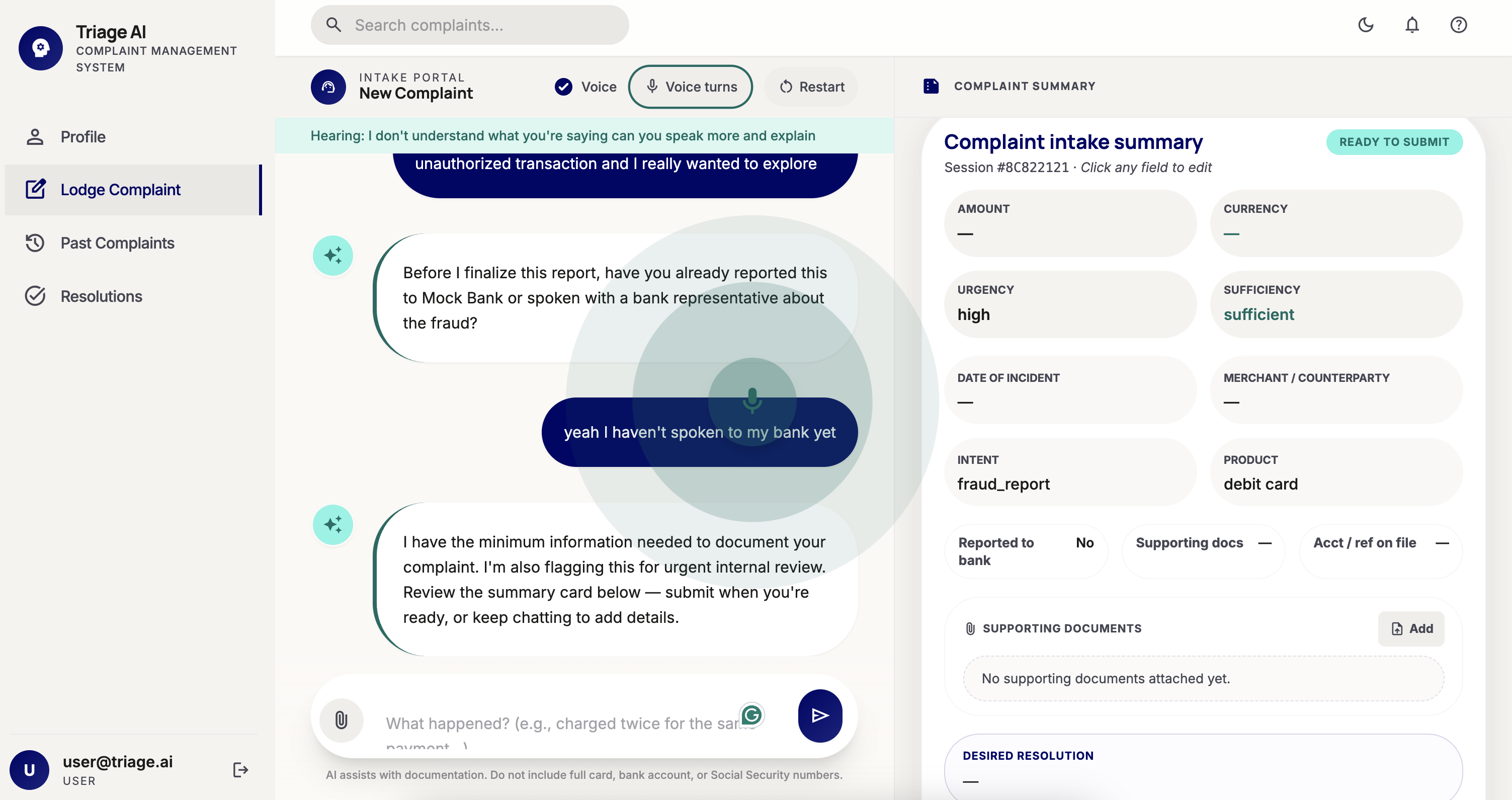
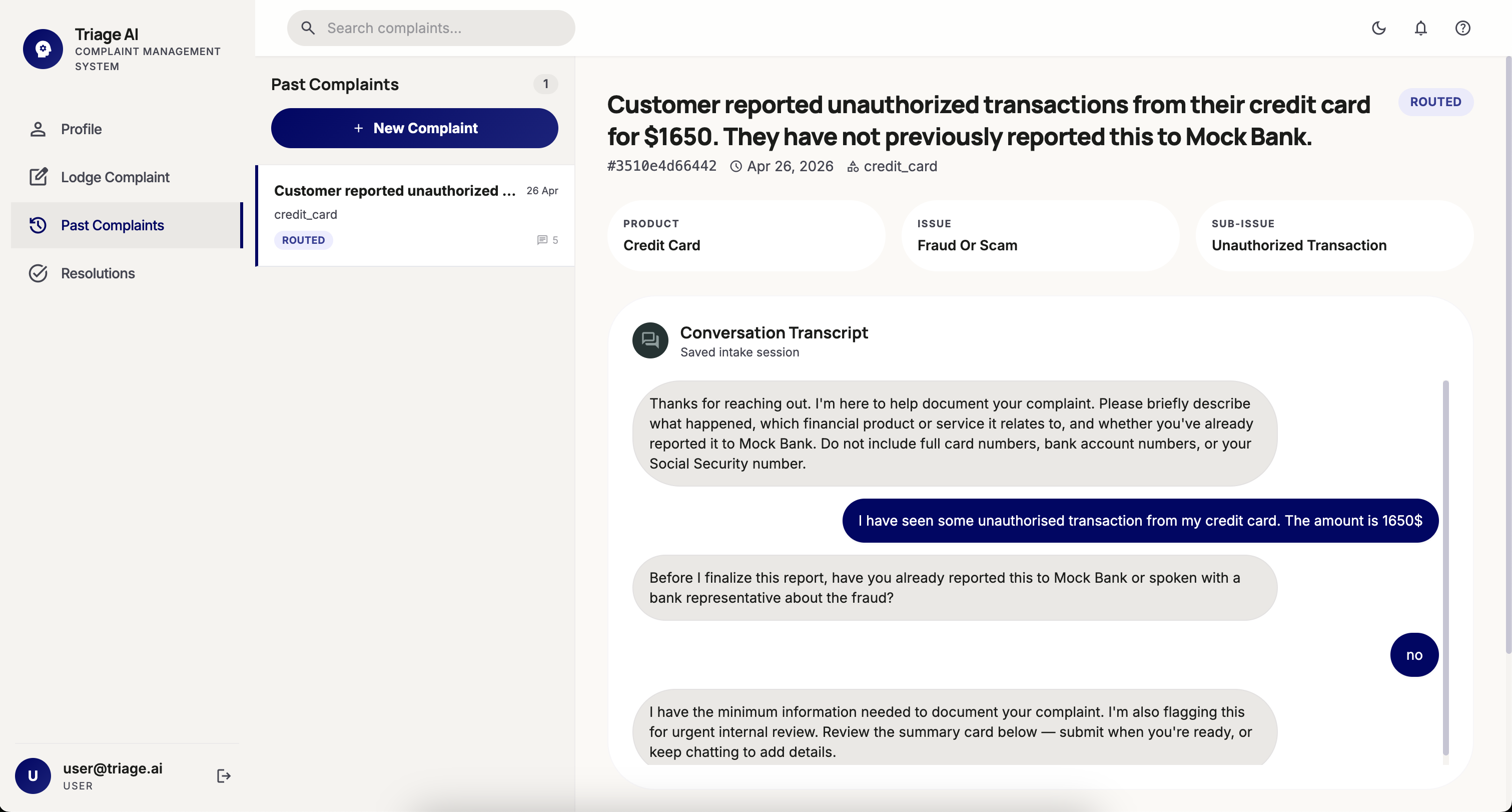
- Intake Agent — extracts the core issue, product, and customer intent from raw text or transcribed voice input, with PII redaction built in
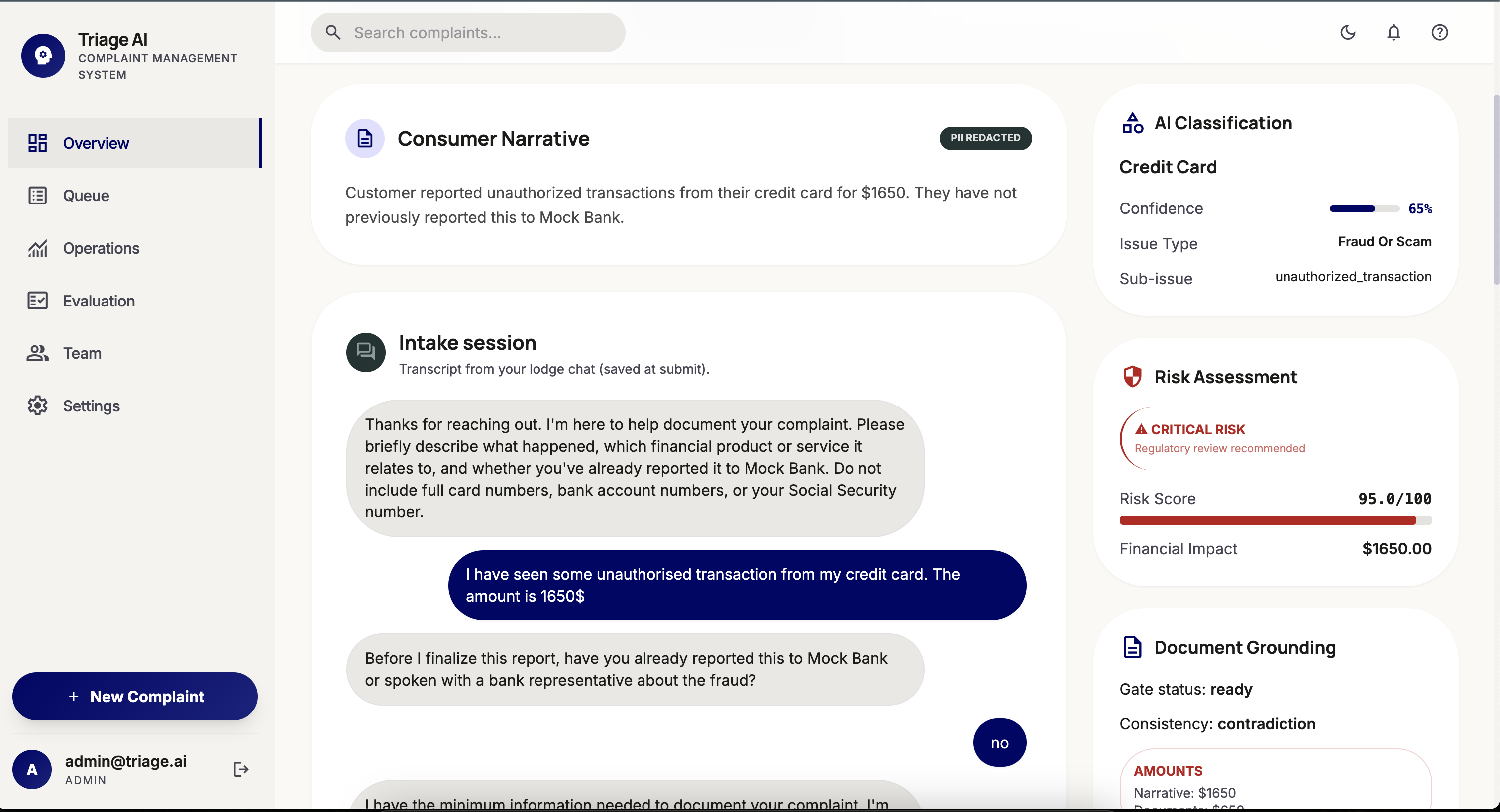
- Classification Agent — categorizes the complaint using deterministic rules layered with Gemini reasoning, with contextual fallback for edge cases
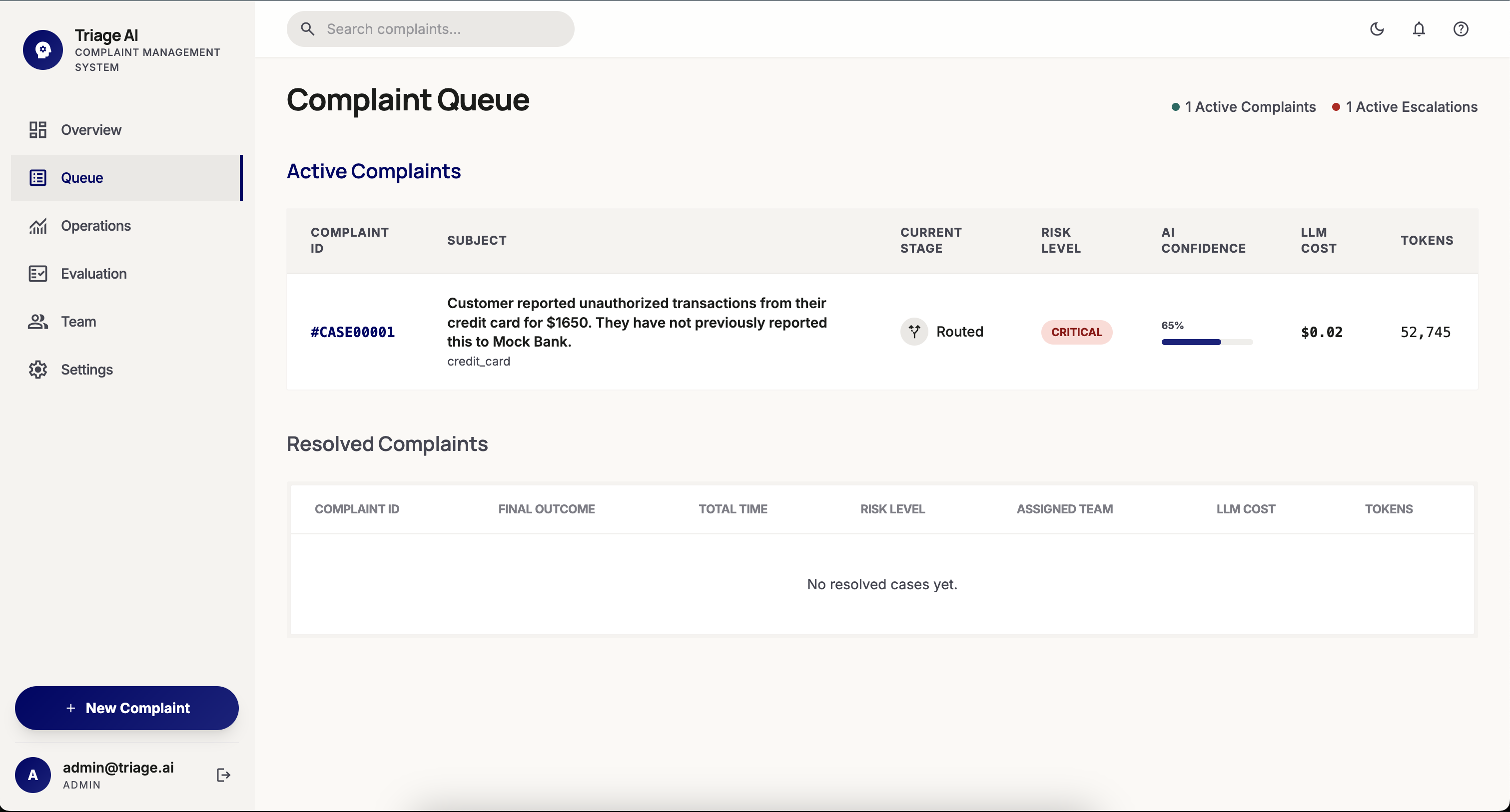
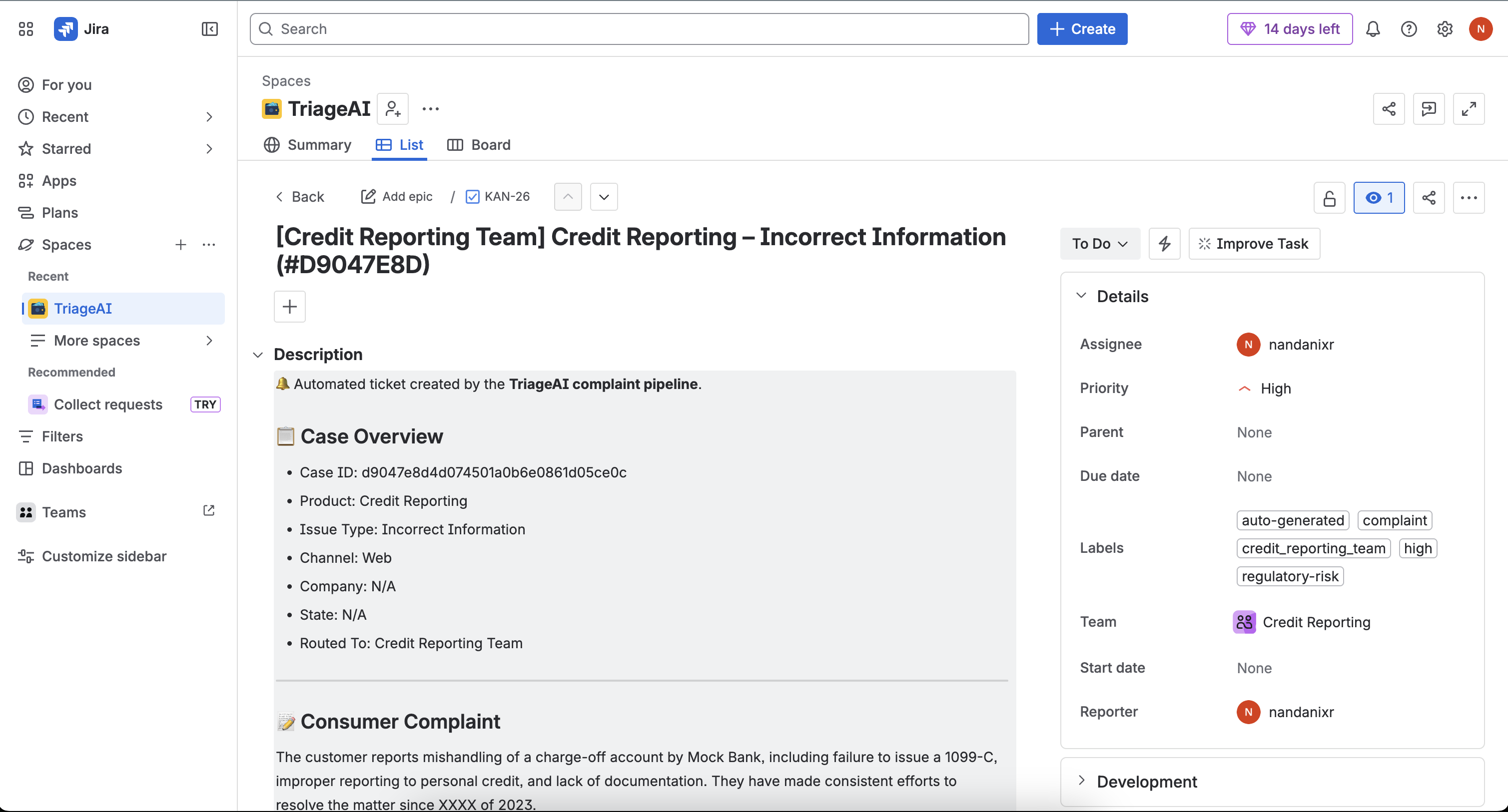
- Risk Agent — scores severity (low → critical), flags regulatory exposure, and surfaces escalations immediately
- Compliance Agent — checks the case against financial regulation frameworks and internal policy rules
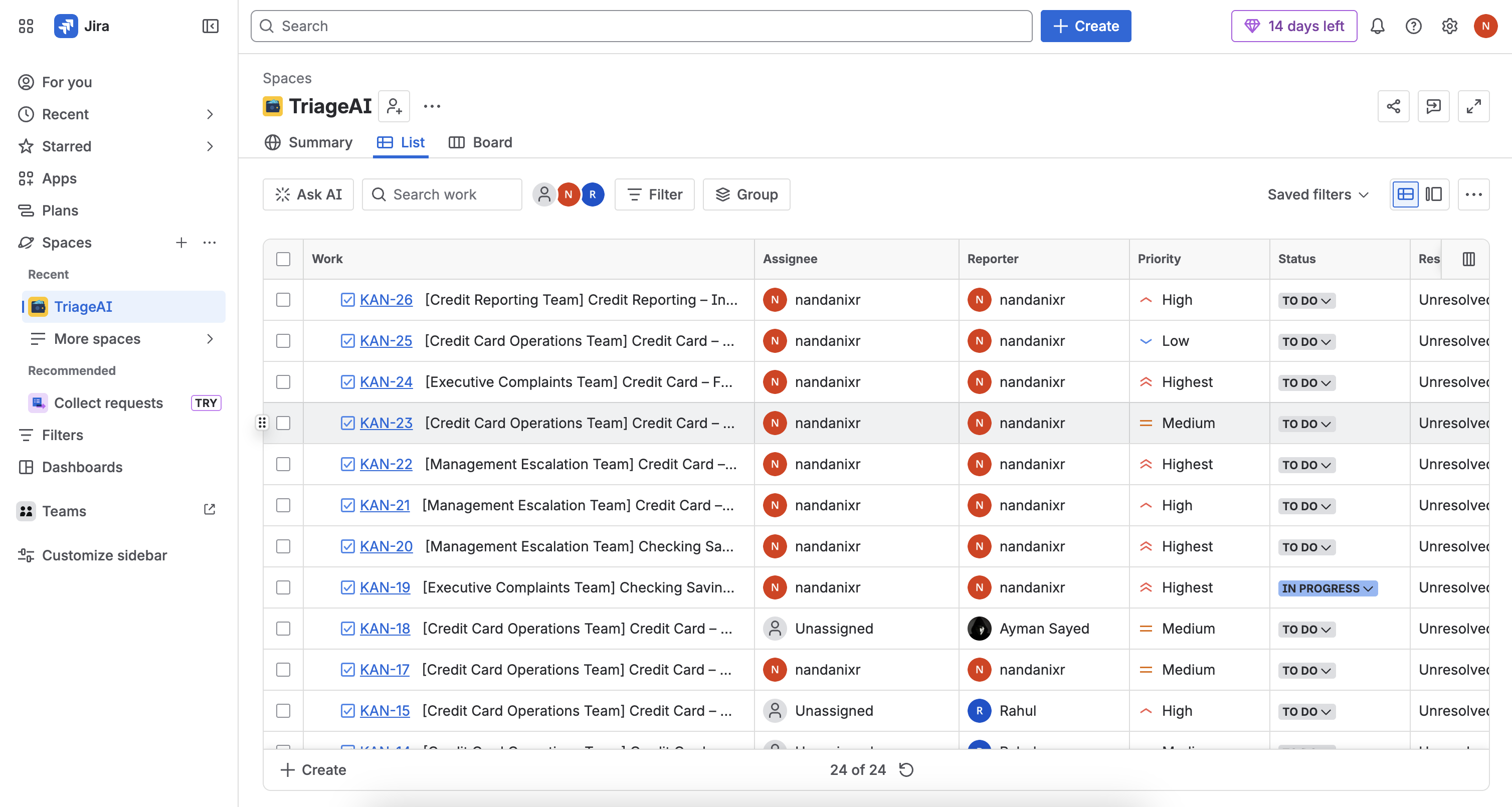
- Routing Agent — assigns the complaint to the correct team based on classification, risk, and domain context
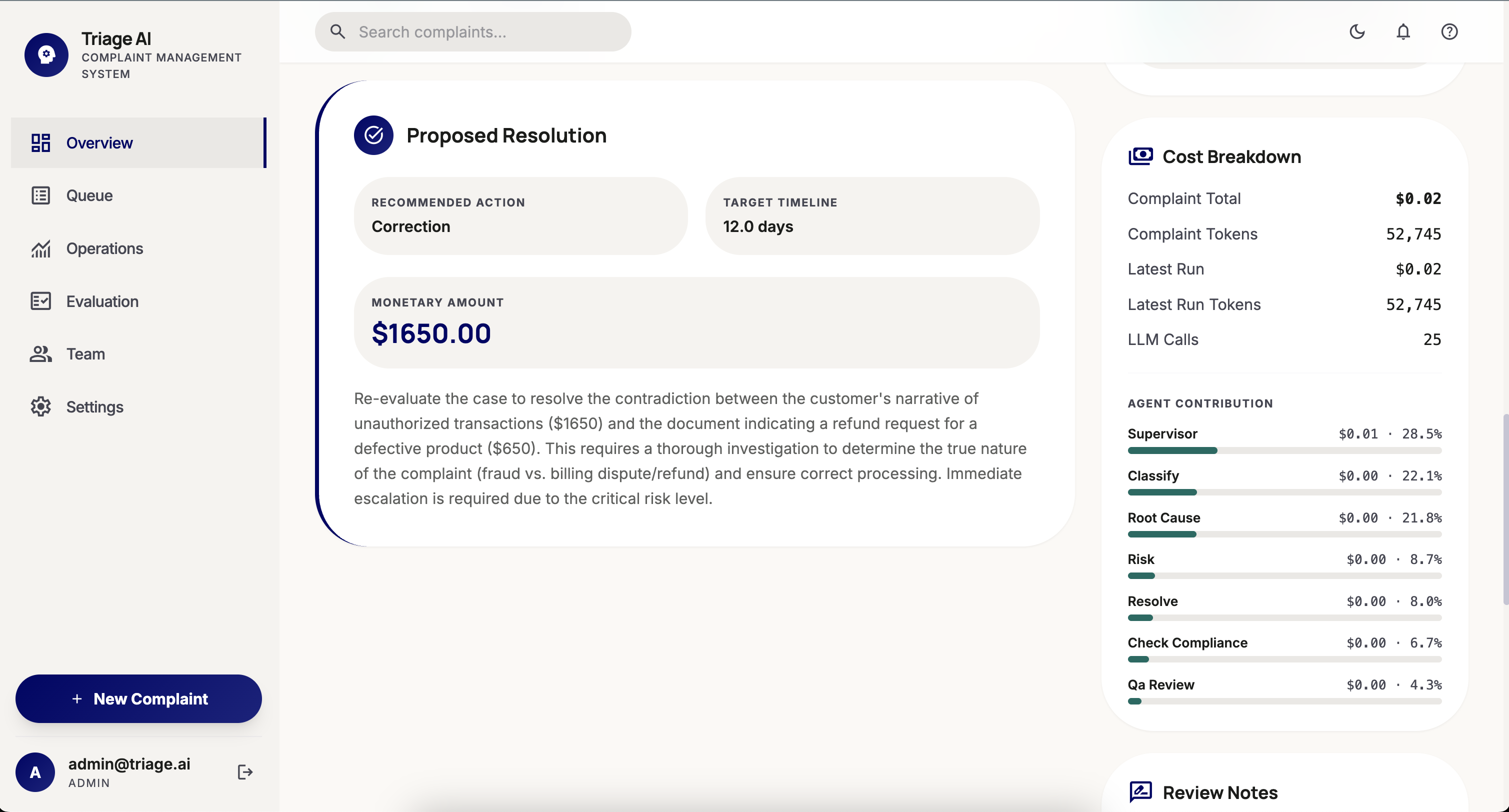
- Resolution Agent — proposes an outcome with full reasoning, ready for one-click human approval
- QA Review Agent — audits the full pipeline output for consistency before closing the case
What used to take days is done in under a minute. Every decision is logged, every agent call is traced, every token is accounted for.
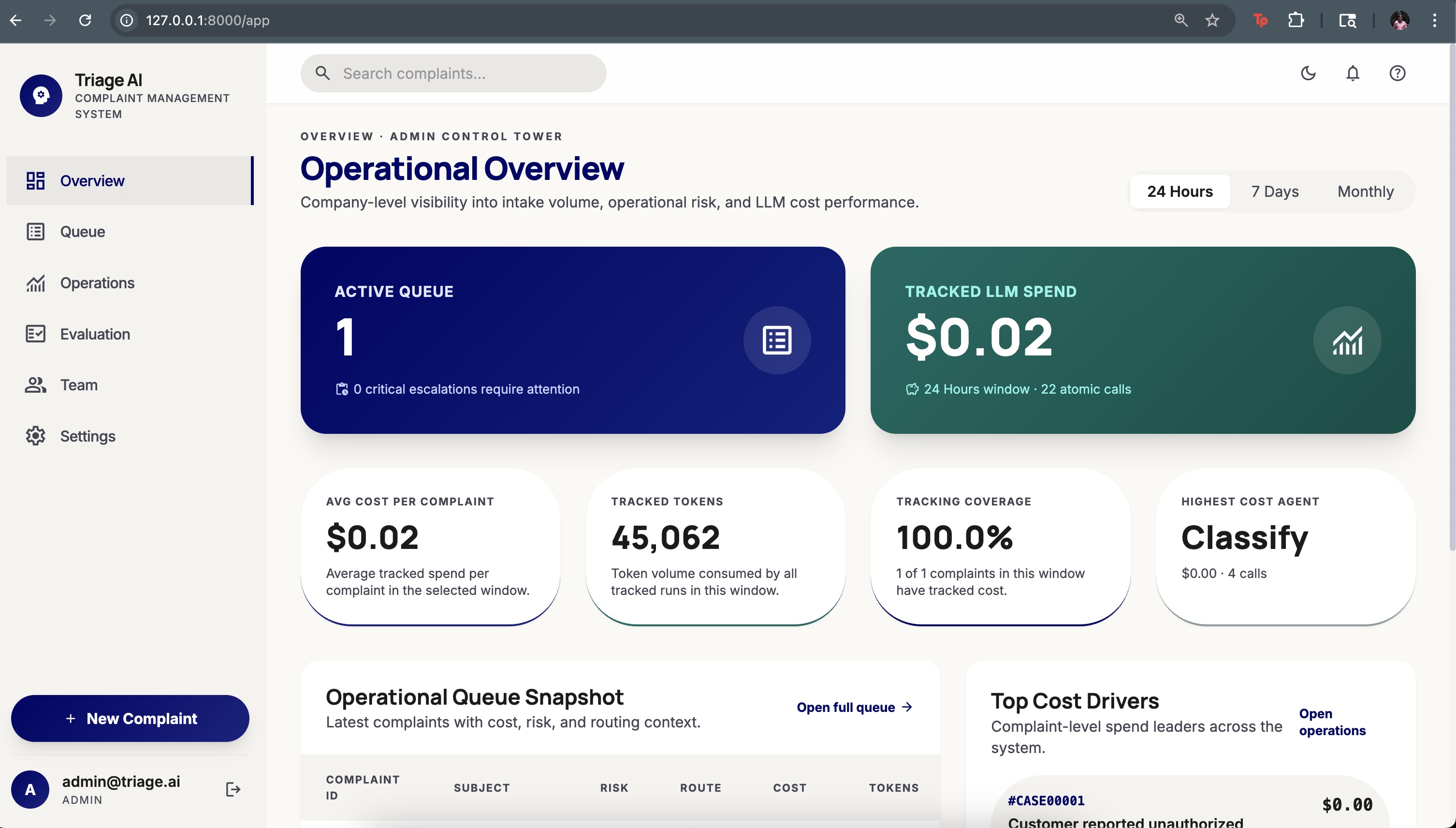
Operators get a real-time intelligence canvas: live queue with risk rankings, AI confidence scores, cost telemetry, and a step-by-step trace of every agent decision. Teams only see cases assigned to them. Admins see everything.
How we built it
Agentic Core: Built on Google ADK (Agent Development Kit), each specialist agent runs as an independent LLM-backed tool with its own prompt and output schema. A custom supervisor orchestrates state transitions across the full pipeline, deciding which agent to invoke next based on current workflow state.
LLM Layer: All agents run on Google Gemini (gemini-3.0-flash-preivew as default, with gemini-2.0-flash-lite and gemini-1.5-flash as fallbacks) via a centralized LLMFactory that handles model selection, retries, and structured JSON output validation.
Knowledge & Retrieval: pgvector on PostgreSQL for semantic retrieval of past complaints, resolutions, and policy documents. HuggingFace sentence-transformers (BAAI/bge-small-en-v1.5) for local embeddings — no external embedding API needed.
Backend: Python + FastAPI + SQLAlchemy + PostgreSQL. Every agent invocation writes a WorkflowStep record — node name, latency, token count, cost, input/output snapshots — giving full observability. Integrated with LangSmith for ADK agent tracing.
Voice Intake: ElevenLabs integration for voice-based complaint submission — transcribed and passed directly into the agent pipeline via a custom OpenAI-compatible endpoint.
Document Processing: Optional Google Document AI and Vertex AI Search integration for document extraction and managed retrieval.
Integrations: Jira REST API for automatic ticket creation on routed cases.
Evaluation Framework: A custom rubric-based judge benchmarks the classification pipeline against labeled datasets, tracking accuracy, precision, and recall — catching model drift before it hits production.
Frontend: Jinja2 + Tailwind CSS with a real-time queue, live trace streaming via SSE, and role-scoped views for admin and team users.
Challenges we ran into
- Agent coordination without state bleed — ensuring each agent's output was schema-valid and didn't corrupt downstream agent context required strict structured output enforcement and retry logic at every transition
- Google ADK async bridging — ADK's runner is async-first but parts of our FastAPI stack are synchronous; building a clean sync/async wrapper that didn't deadlock under load was non-trivial
- Cost vs. quality tradeoff — running 7 agents per complaint adds up fast. We implemented a deterministic pre-classification layer to short-circuit Gemini calls where rule-based logic suffices, significantly cutting cost per case
- Vector retrieval quality — tuning similarity thresholds for pgvector retrieval so agents pull genuinely relevant precedents without noisy context polluting the LLM prompt
Accomplishments that we're proud of
- A fully autonomous end-to-end pipeline — a complaint submitted at one end emerges classified, risk-scored, compliance-checked, routed, and resolution-proposed at the other, with zero manual intervention
- Per-step observability — every agent call has latency, token count, cost, input/output, and status recorded — full trace replay in the UI
- Voice intake — a complaint can be spoken, transcribed via ElevenLabs, and processed through the full pipeline without touching a keyboard
- Hybrid retrieval — local vector search over policies, past complaints, and resolutions gives every agent grounded, institution-specific context
- Live LLM evaluation harness — a benchmark system that runs against labeled datasets and scores outputs with a deterministic judge, giving us confidence in every deployment
What we learned
- Multi-agent systems live or die by their state contracts — clean, validated schemas between agents matter more than any individual prompt
- Deterministic rules and LLMs are complementary — layering rule-based pre-classification under Gemini reasoning cuts cost and improves consistency without sacrificing flexibility on edge cases
- Observability is not optional in agentic systems — without per-step tracing, debugging a 7-agent pipeline is nearly impossible. Instrument from day one
- Google ADK is powerful but opinionated — working with its session and runner model requires upfront architectural commitment, but pays off in clean agent isolation
What's next for Triage AI
- Multi-tenancy — full company isolation so multiple financial institutions run on the same platform with separate models, rules, and routing logic
- Regulatory rule engine — a structured, updatable compliance rulebook mapped to FCA, CFPB, and GDPR frameworks, dynamically injected into the compliance agent at runtime
- Proactive escalation alerts — Slack/email webhooks when a critical case is detected, before a human even opens the dashboard
- Fine-tuned classification — train institution-specific classifiers on historical complaint data to eliminate LLM calls for well-understood complaint categories
- Resolution feedback loop — capture human overrides on proposed resolutions and feed them back into the evaluation harness to continuously improve agent quality over time
- Google Agent Engine deployment — move from local ADK runner to fully managed Google Cloud Agent Engine for production scale

Log in or sign up for Devpost to join the conversation.