
Inspiration
Most publishing archives are valuable but hard for agents to use. Articles, research notes, source links, and follow-up context usually stay trapped as static pages. A reader can search them manually, but an agent cannot reliably resolve one article into durable source memory, evidence, and a follow-up conversation.
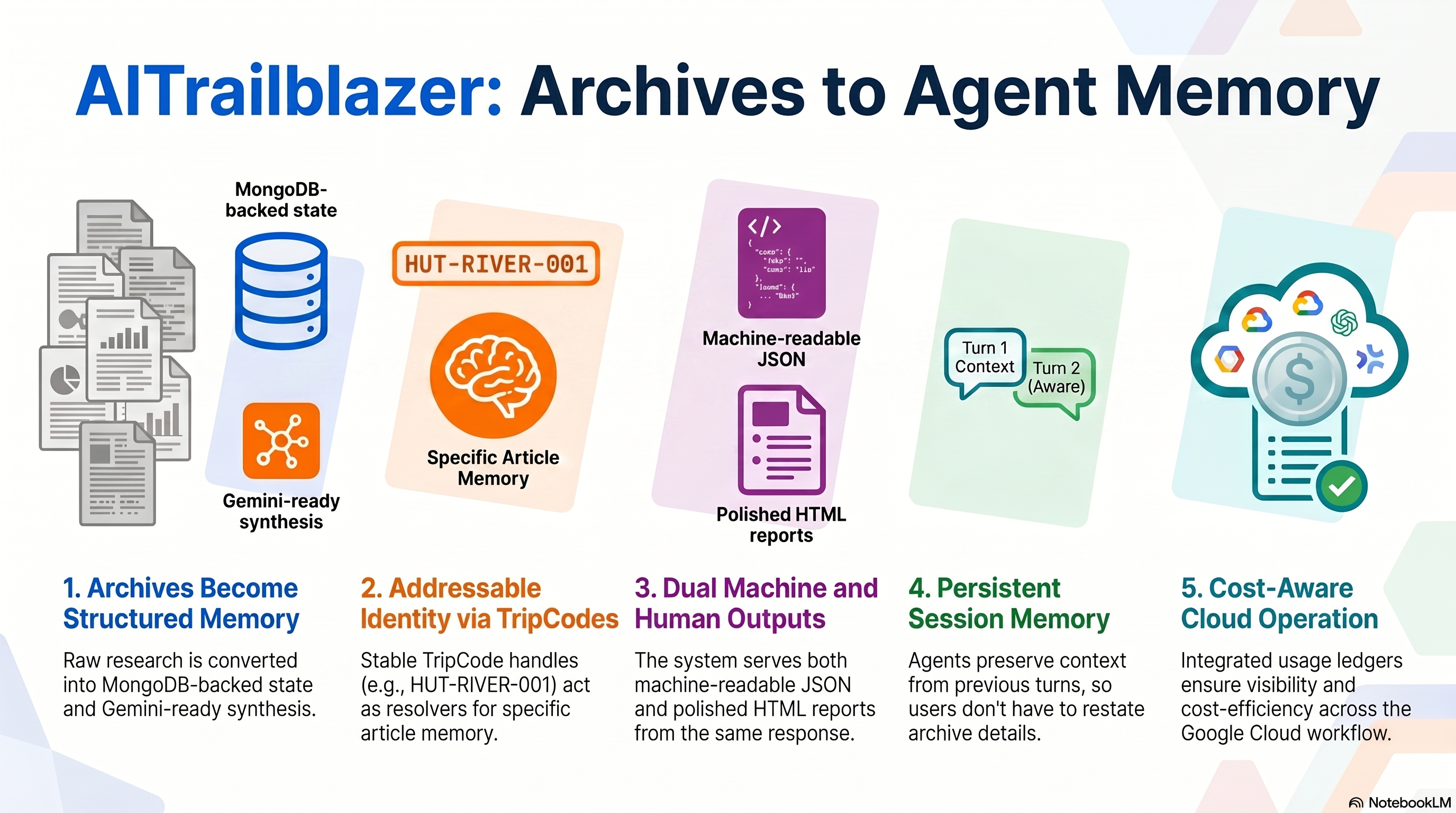
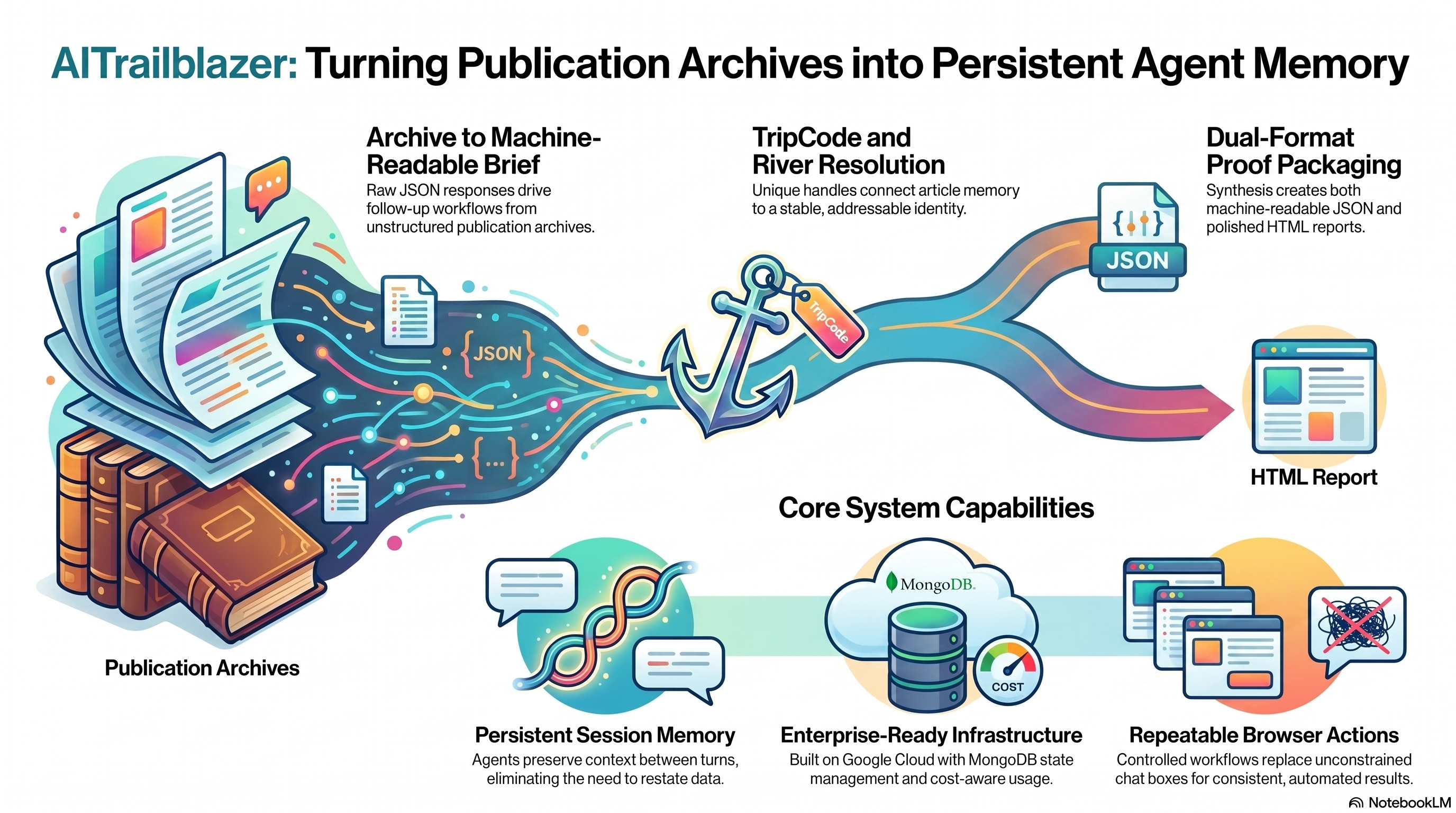
AITrailblazer AI Agent Publishing was built to solve that problem. The project turns a publication archive into agent-readable memory by giving articles stable TripCodes, grouping related articles into Rivers, storing source-grounded evidence in MongoDB, and exposing a live proof path that judges can run directly.
What it does
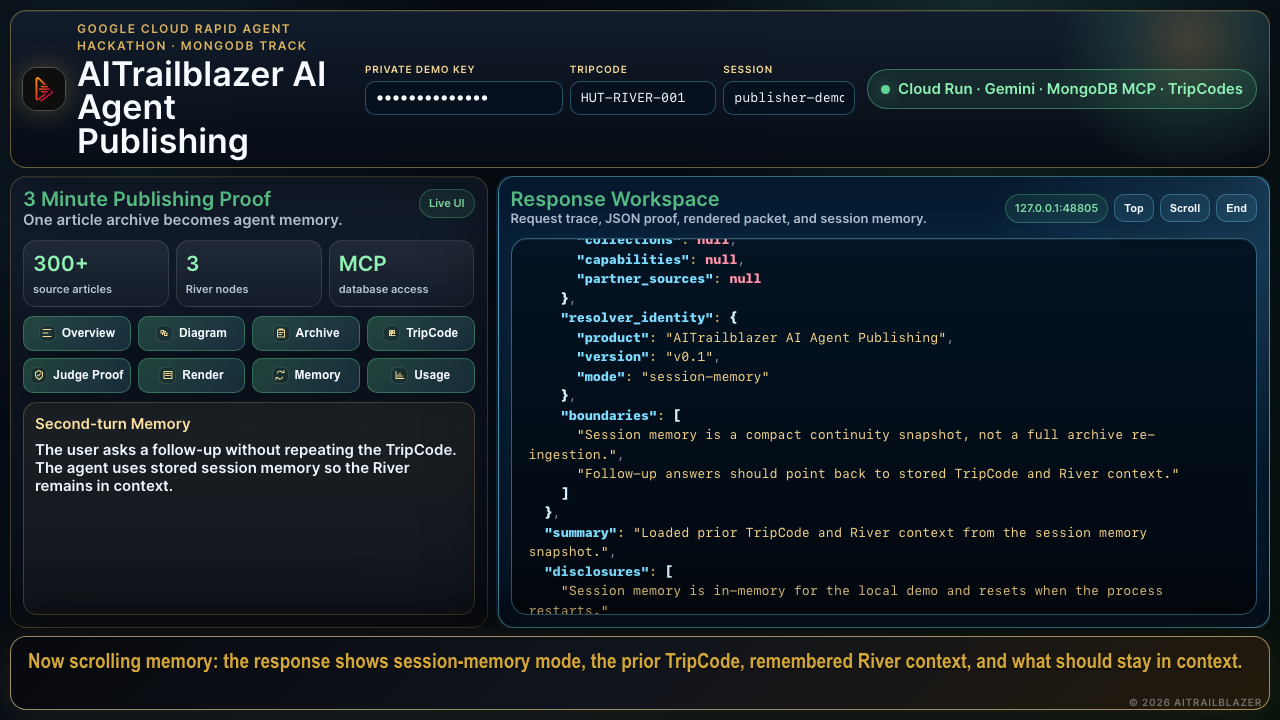
AITrailblazer AI Agent Publishing converts publication content into searchable, source-grounded agent memory. A judge can open the hosted demo, run the live proof, and see the system resolve a TripCode into an article packet, River context, claims, MongoDB collection proof, Gemini synthesis, Agent Builder retrieval evidence, MongoDB MCP evidence, and second-turn session memory.
The core demo uses the TripCode HUT-RIVER-001. It resolves a three-article River, produces a grounded synthesis packet, stores compact continuity for follow-up questions, and reports which runtime integrations are live. The goal is not just to answer a question, but to show how a publication can become a reliable memory layer for agents.
How we built it
The project is packaged as a Google Cloud-hosted Go service with a public HTML/Lit demo surface, Cloud Run deployment, Docker image, Cloud Build workflow, and judge-friendly API endpoints.
Google Cloud Run hosts the service. Vertex AI Gemini provides synthesis for the TripCode packet. Google Cloud Agent Builder / Discovery Engine provides searchable retrieval context. MongoDB stores the archive-memory shape: source packets, River nodes, claims, session memory, and judge-visible collection proof. The official MongoDB MCP server is wired through the runtime so agent workflows can query MongoDB-backed evidence without putting credentials in the public repository.
The public repository is intentionally secret-free. Configuration is environment-based, sample values live in templates, and private operator traces, session material, and credentials are excluded from the publishable surface.
Challenges we faced
The main challenge was making the demo verifiable instead of just descriptive. It is easy to say that an agent uses Gemini, Agent Builder, MongoDB, MCP, and Cloud Run; it is harder to make those integrations visible in a way a judge can inspect quickly. We built a deterministic judge proof endpoint and a public UI that renders runtime status, source packets, collection proof, live flows, and second-turn memory.
Another challenge was keeping the project competition-safe. The public repo needed to show enough implementation detail to be credible while avoiding secrets, private browser captures, local operator traces, and unsupported claims. We added validation scripts and scans so the submission can stay public without leaking private material.
Accomplishments that we're proud of
We built a live Google Cloud demo that turns a TripCode into an agent-readable memory packet and exposes the result through a clear public UX. The implementation includes Cloud Run hosting, Gemini synthesis, Agent Builder retrieval, MongoDB memory design, official MongoDB MCP wiring, API endpoints, Docker deployment, validation scripts, and 100% Go test coverage.
We are especially proud that the demo is not a generic chatbot. It shows a reusable pattern for publishers: convert articles into stable TripCodes, connect related pieces through Rivers, store evidence in MongoDB, and let agents resolve the archive with provenance.
What we learned
Agent publishing needs more than generation. It needs stable IDs, retrieval contracts, source packets, persistence, and evidence that can survive follow-up questions. MongoDB is a strong fit for this because article memory is not one flat document; it is a connected record of sources, claims, Rivers, sessions, and runtime proof.
We also learned that a good judge experience should make the system observable. The hosted proof shows what is live, what was resolved, and what memory was preserved, so the submission can be evaluated without private credentials or hidden setup.
What's next
Next we want to record the public under-three-minute demo video, expand the archive ingestion path beyond the seeded proof case, support more publication formats, and add a production Atlas-backed mode for larger archives. The same pattern can support Substack writers, research teams, analyst shops, newsletters, and any publisher that wants its archive to become reliable agent memory.

Log in or sign up for Devpost to join the conversation.