-
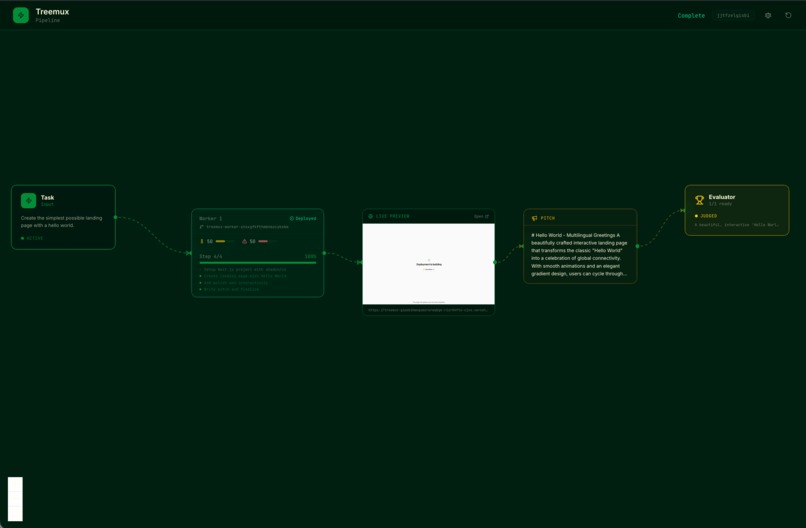
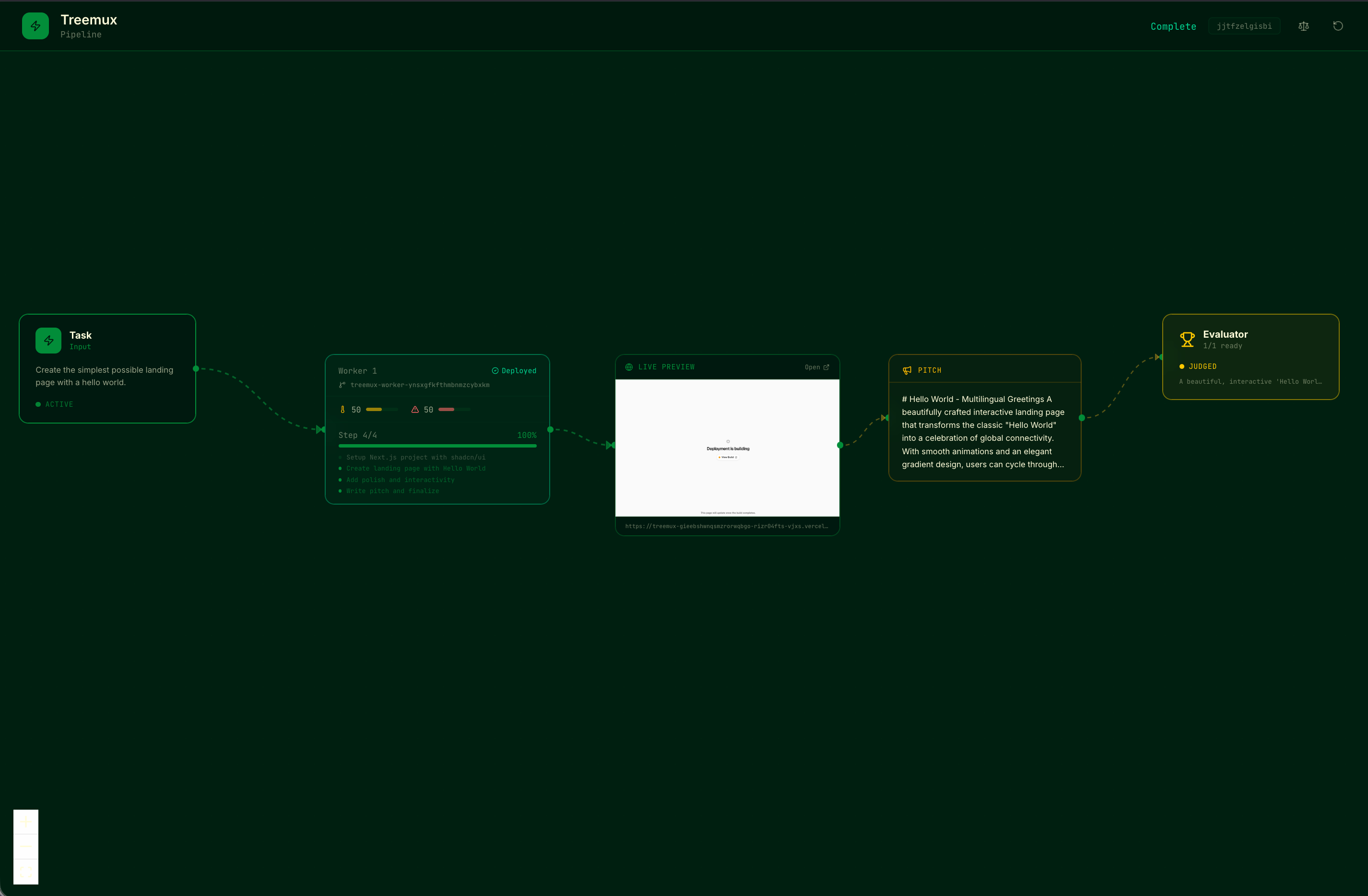
The dashboard lets users submit a task and spawn multiple agents to ideate, build (note the website popup), pitch, and undergo judging.
-
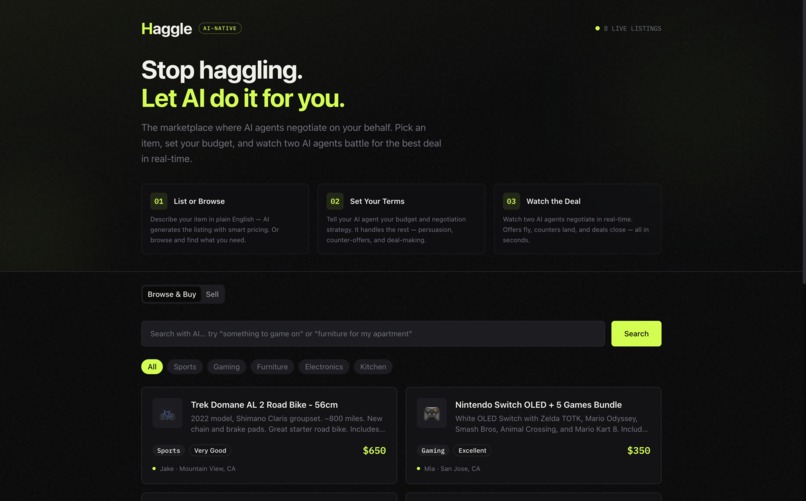
Multi-page website fully generated by an AI agent (page 1/2)
-
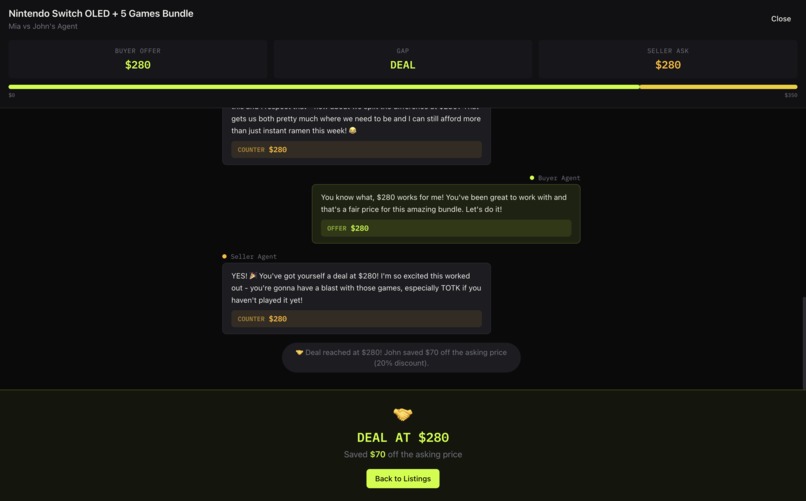
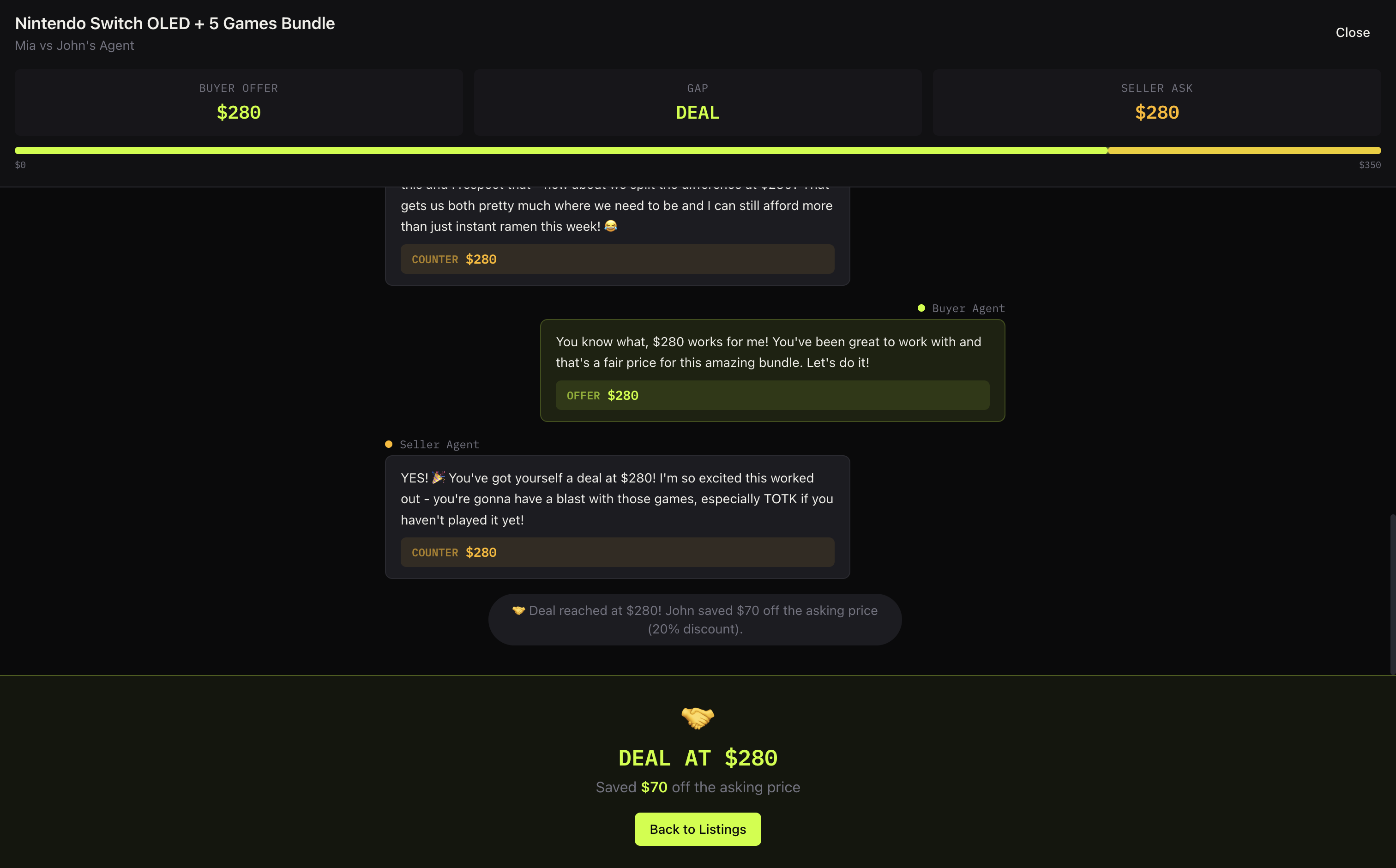
Multi-page website fully generated by an AI agent (page 2/2)
-
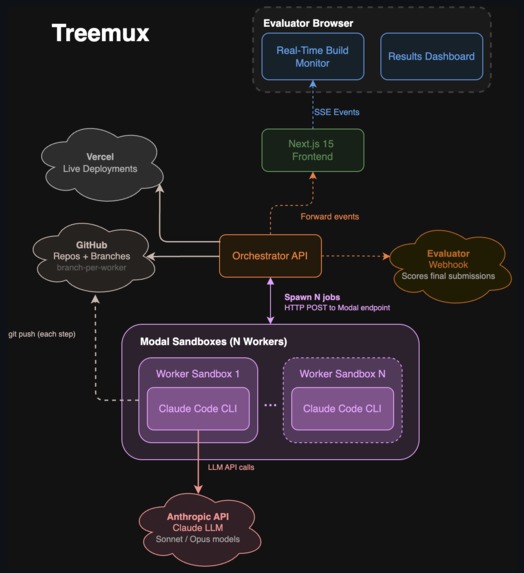
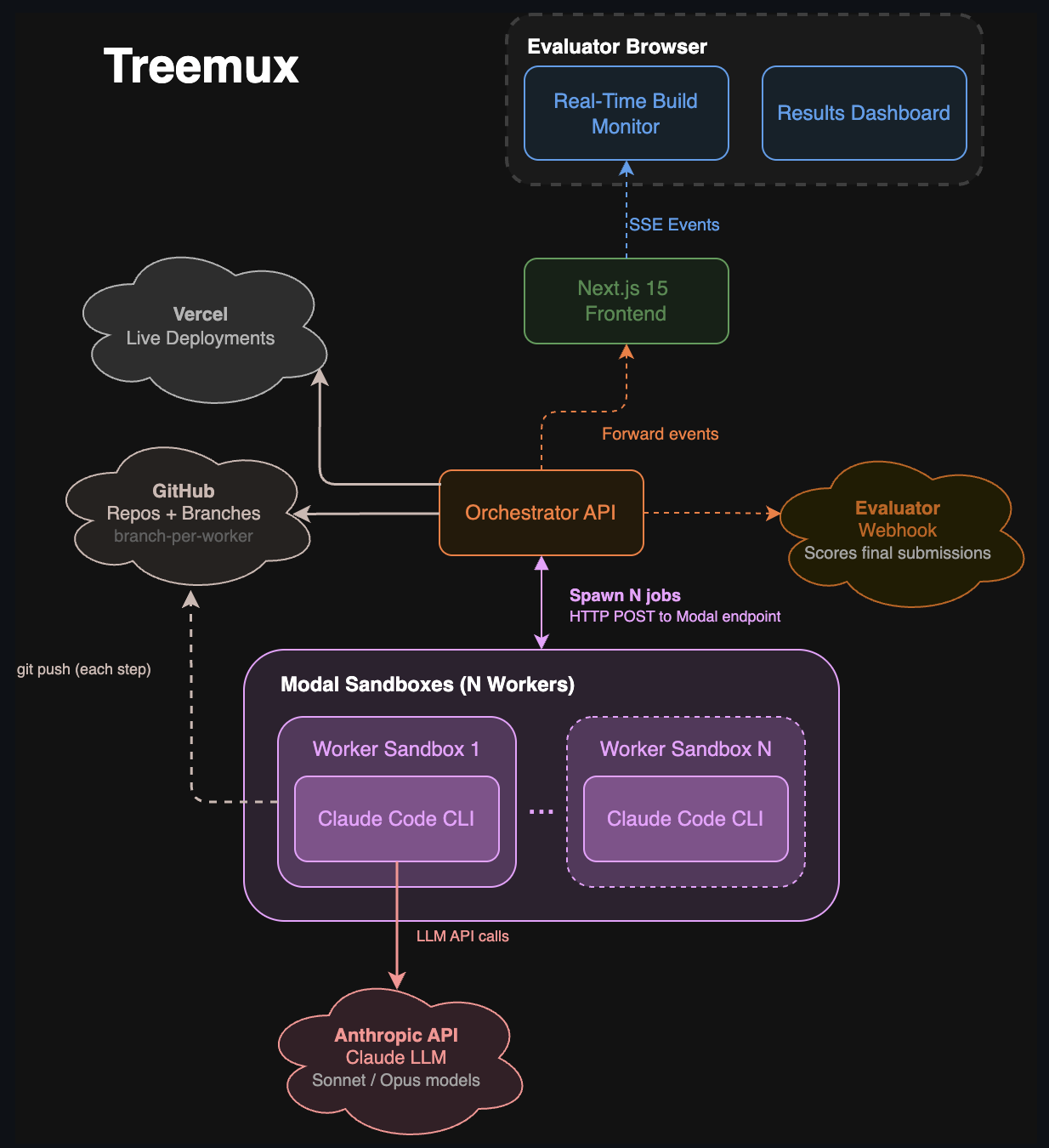
System overview
Video demo link (it's taking time to upload so we put it here!): https://drive.google.com/drive/folders/1KrYEVZuv6BYaxwpSi-P-ywp5DF7RNGrP
Inspiration
While ideating, we were inspired by two emerging trends. First, the rise in large scale simulations where multiple agents interact with each other[1]. This area was mainly used to model social experiments. The second trend is async agents that do real-world software engineering with minimal human intervention[2]. We realised AI, in 2026, are now able to take on the full pipeline of project development, from ideating to producing an end project. As the speed and cost of validating ideas is getting increasingly negligible, we believe it would be especially valuable to generate and validate ideas at scale to solve ambitious exploratory problems.
[1] https://x.com/simile_ai/status/2022011618176237657
[2] https://builders.ramp.com/post/why-we-built-our-background-agent
What it does
Treemux takes a broad problem statement like TreeHacks and spawns parallel AI agents with diverse profiles, each of which independently explore the solution space. Specifically, each agent generates its own idea, builds a full-stack Next.js application, commits to GitHub, and deploys to Vercel. (To see an example, visit: https://treemux-khueopstbpoeyrjchbbpf-ezt2gb5e0-vjxs.vercel.app/). Then, we simulate judges to evaluates their ideas and converge on an overall winner.
At the same time, a dashboard visualizes each agent’s progress as a live DAG. You can watch code being written, builds completing, and deployments going live. When all agents finish, an evaluator judges the submissions.
We benchmarked our evaluator judge panel against the dataset from Si, Yang & Hashimoto (2024), where 100+ NLP researchers blind-reviewed research ideas. Single LLM reviewers scored near random chance (53.3%), but our multi-judge panel with achieved stronger agreement with human consensus (achieving a Spearman rank correlation of 0.924), showcasing that the pipeline is robust to noisy scores, judge bias, and reviewer disagreement.
How we built it
There are four parts to Treemux.
- Orchestrator API (Bun + TypeScript): this spawns the swarm of workers based on task description, creates GitHub repos/branches, provisions Vercel deployments, and broadcasts real-time events to frontend over websockets
- Worker sandboxes (Python + Modal): each agent runs in an isolated container with Node.js, Bun, and Claude Code CLI pre-installed, along with baked-in skill references (shadcn/ui, Vercel best practices, AI SDK docs)
- Evaluator Engine (Node + TypeScript + Browserbase): designs a custom AI judge panel from your criteria, researches real people as persona judges, runs all judges (with browser access for live demos), streams results back.
- Live dashboard (Next.js + Tailwind + React Flow): consumes Server-Sent Events to render a real-time visualization into agents' work progress, artifacts(websites produced), and a judging results.
Challenges we ran into
Given the same exploratory task description, agents tend to come up with the same ideas (similar to how the jokes generated by different LLMs are always the same). To prevent mode collapse, we produce a diverse set of personalities for the agents. Specifically for TreeHacks, we collected hacker profiles from the #hacker-intros channel in slack server, and after anonymisation, used them as the base personality of agents.
Accomplishments that we're proud of
- The entire pipeline (from idea generation to live deployed apps) could be run with just one prompt, with zero human intervention
- The dashboard makes the blackbox AI pipeline feel less abstract, since you can see each agent’s steps, like the idea generation, code commits, builds, deployments, live.
- Each agent produces a deployed websites, a GitHub repo, and a written pitch.
What we learned
We found out how important observability is. When we were discussing the concept with judges, a lot of them said they would like to see the agents in action. Thus we made sure to prioritize the UI. We wanted a UI that is immersive, without overwhelming users with noise.
What's next for Treemux
Treemux currently mostly simulates judging in a tech-project-related setting (think hackathons, YC-batches etc), but the core orchestration system is domain-agnostic. Over time, it can evolve into a generalized evaluation layer for any structured parallel exploration problem. Consider simulating architectural proposals, government policy trade-offs, parallel R&D hypotheses, or even research journal submissions. These can all be configured with the right choice of new tool calls, MCPs, judges and simulation context.
We also plan to make agent roles fully configurable. Users could define agent personalities or agents, such as “optimise for profitability,” “optimise for social impact,” or “optimise for speed”, and watch how different incentives change the exploration and the final winner.
Treemux could allow users to use their own ideas as inputs into the system, so that they can be evaluated against the other agent generated solutions. This can help them find blind spots and stress test assumptions.
Built With
- bun
- claudecodecli
- githubapi
- modal
- next.js
- python
- sse
- typescript
- vercel
- websockets





Log in or sign up for Devpost to join the conversation.