-
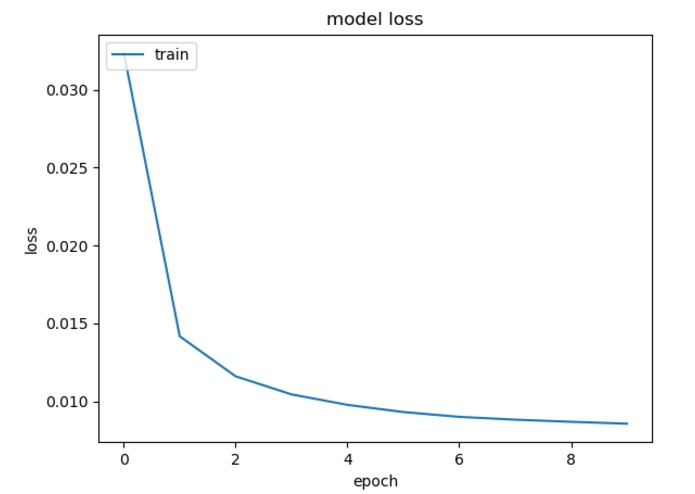
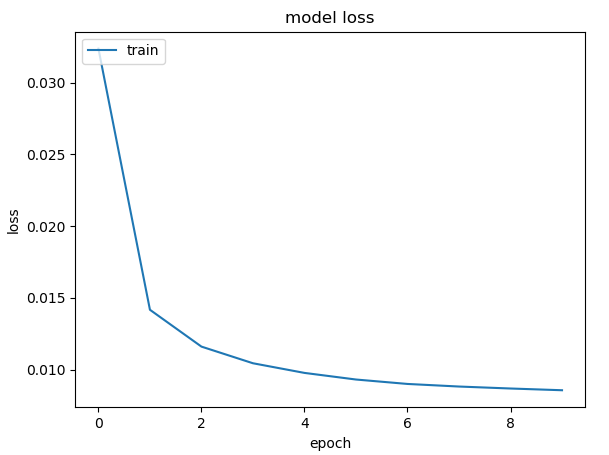
Proof of learning model
-
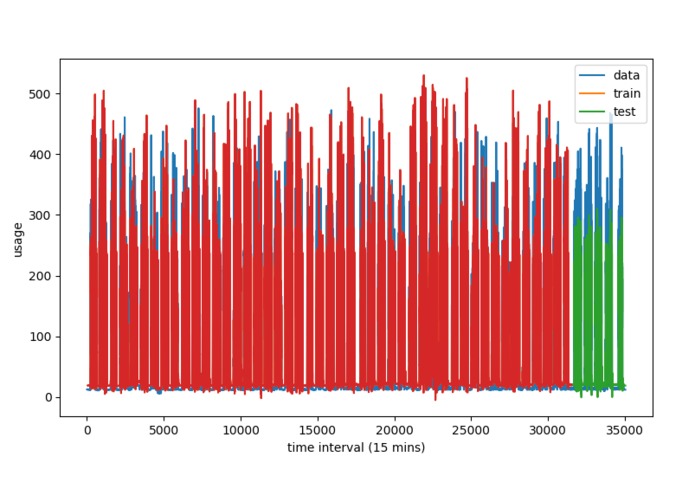
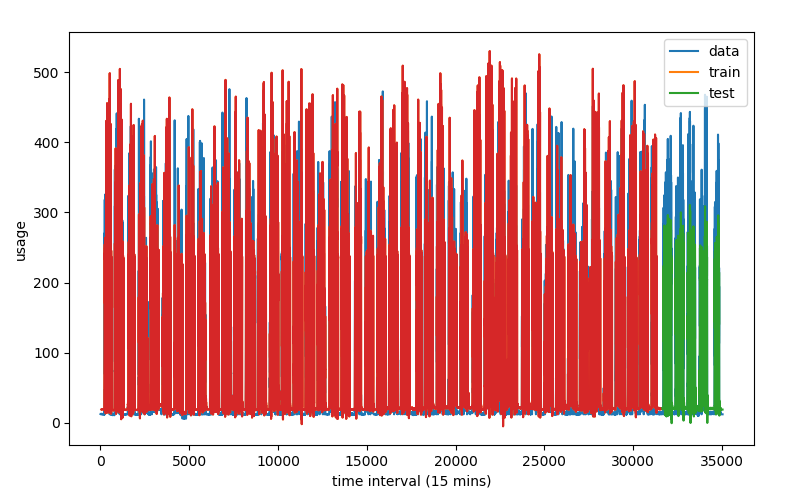
Main plot w/ correction factor
-
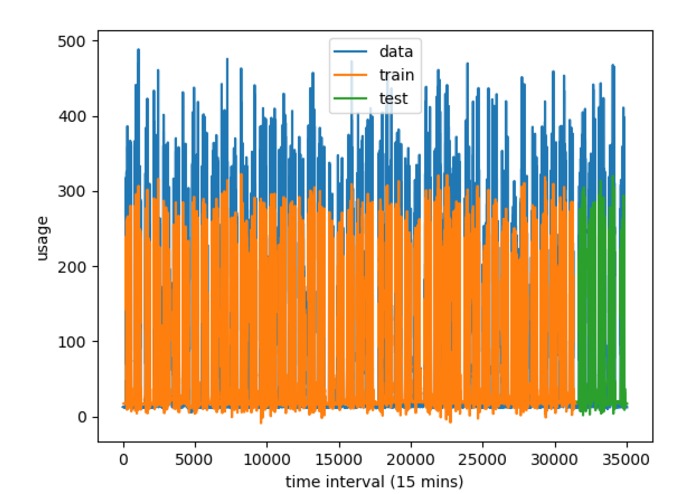
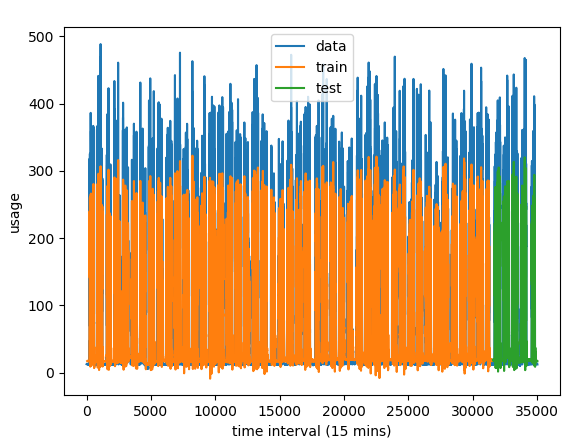
Main plot
-
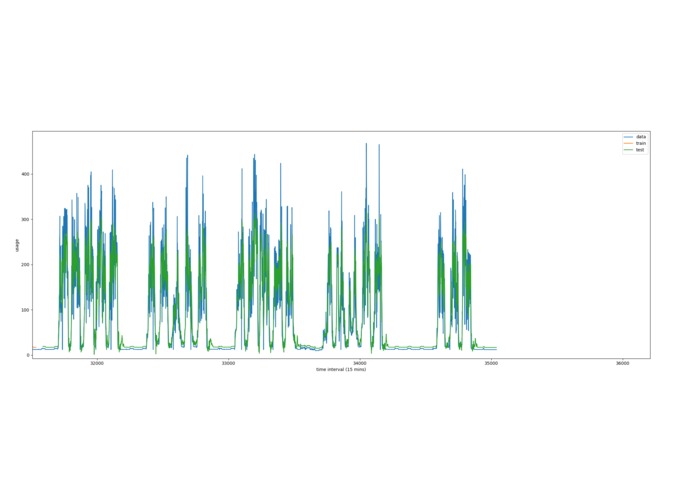
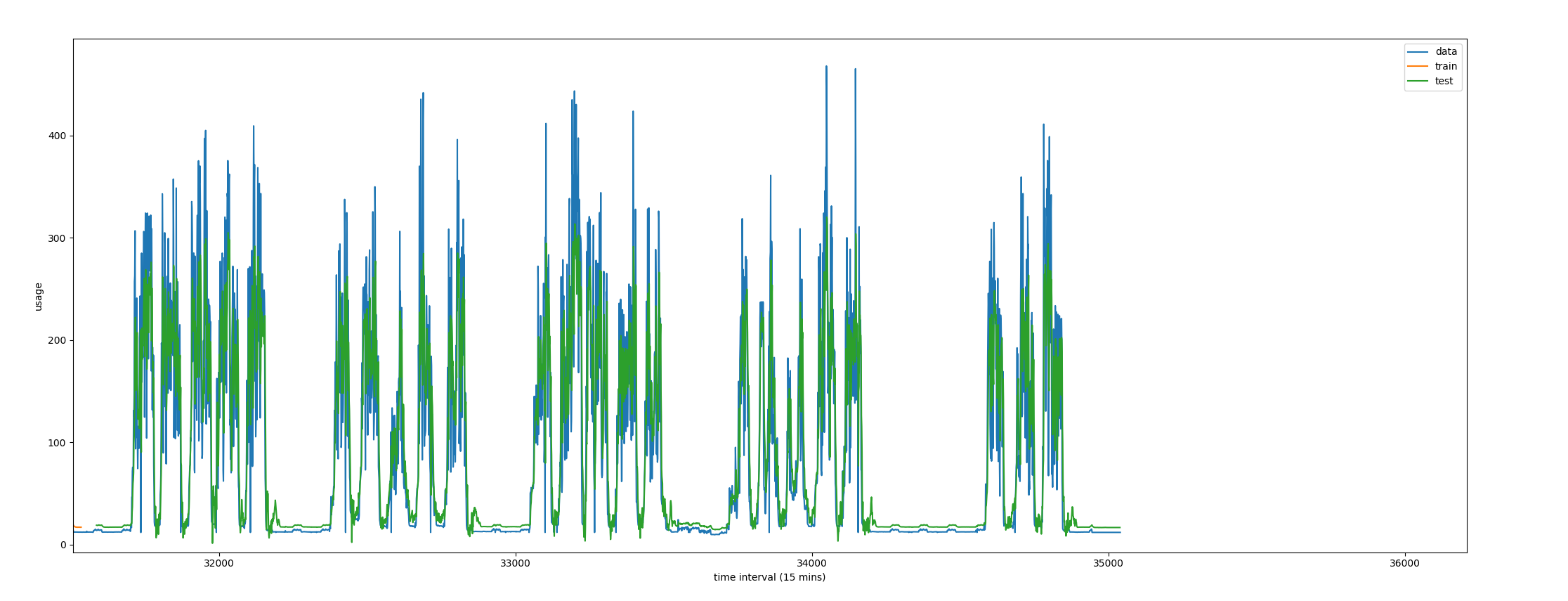
Zoomed in prediction
treehacks-energy Challenge
Submission for TreeHacks 2018 - Stem's Challenge.
Challenge
To forecast one site's energy consumption and simulate the activity of a behind-the-meter energy storage system in order to reduce this client's energy bill through peak shaving.
Getting Started
The analysis and prediction model (as well as the dataset provided) can be found in this repo. To run, simply modify the path of the file in:
analysis.py and seeding_LSTM.py
Running the code will yield the results shown below. Alternatively, you can reproduce or enhance the plots:
Using: data_points.p
pickle.dump([trainPredict, trainY, testY, testPredict], open(dir+'data_points.p', 'wb'))
Our Solution
Using long term short term memory layer (LTSM), we are able to learn sequence patterns better by having memory of what it has seen before.

As the train decreases over epoch, it's evident that the model is learning.
Train Score: 44.57 RMSE
Test Score: 46.17 RMSE
Since train and test scores are close, the model can correctly predict on data it hasn't seen yet.
Main Plot
Here, is comparison of our known data (in blue), our training output (in orange), and our test data (in green).

One issue that's evident in this plot is that our algorithm consistently underestimates the values. But since the understimation is consistent across time, we can design a correction factor to compensate for the offset.
 This plot shows what a simple error correction would look like. Notice how the red lines (magnitude of peaks predictions) match the the actual data much more accurately now.
This plot shows what a simple error correction would look like. Notice how the red lines (magnitude of peaks predictions) match the the actual data much more accurately now.
 It's evident and remarkable when zoomed in that the shape closely matches the actual data. The only issue is the biasing issue, which is why we have a correction factor. This essentially shows the the model can learn qualitative geometric features of the usage by training on past pulses.
It's evident and remarkable when zoomed in that the shape closely matches the actual data. The only issue is the biasing issue, which is why we have a correction factor. This essentially shows the the model can learn qualitative geometric features of the usage by training on past pulses.
Code source:
- Tensorflow
- Keras
Acknowledgements
- Built for TreeHacks 2018
- Made by Nathan Zhao, Yu-Lin Yang, and David Ta
Built With
- jupyter-notebook
- python

Log in or sign up for Devpost to join the conversation.