



💡 Inspiration
Only 31% of Gen Z feel financially secure, and over half report being "very or extremely" worried about not having enough money (EY, 2023). Yet 42% plan to go into debt for summer travel (Bankrate, 2024), and nearly one in four admit they join trips they can't actually afford due to social pressure (Empower).
This is the Gen Z paradox: high financial anxiety paired with rising travel spending. And when they turn to AI for budget guidance, most tools make the problem worse — confidently generating numbers with no data behind them. A hallucinated budget doesn't just mislead; it creates a real-world financial trap.
We asked: What if an AI agent could only answer when it had mathematical proof? Not smarter wording — stricter evidence. So we built a tool-driven Elastic agent that must query real records before producing any number.
💬 "Confidence without data is a well-dressed lie."
🛠️ What it does
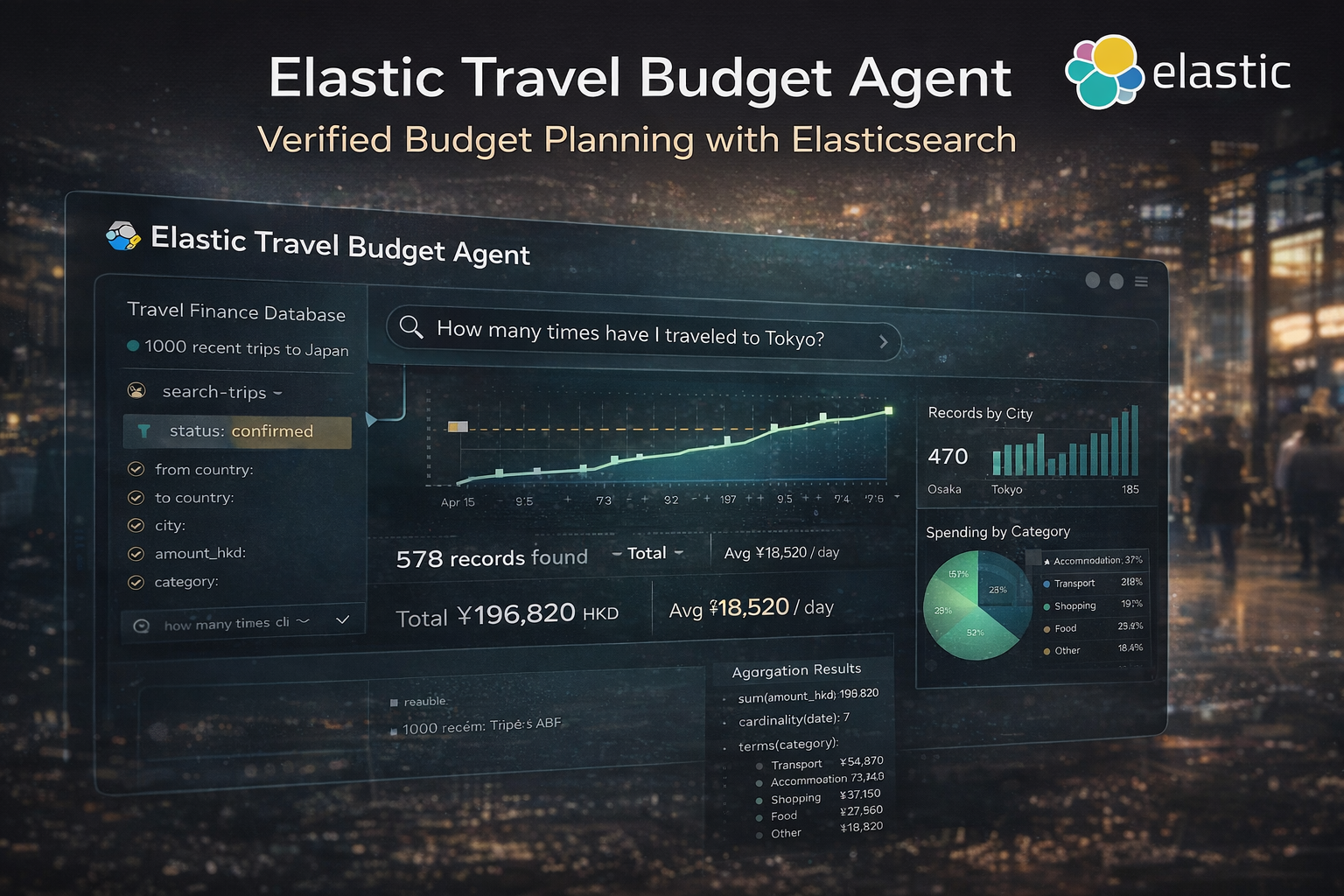
The Elastic Travel Budget Agent is a deterministic financial guardian powered by Elastic Agent Builder. It answers travel budget questions using only Elasticsearch data and ES|QL aggregation.
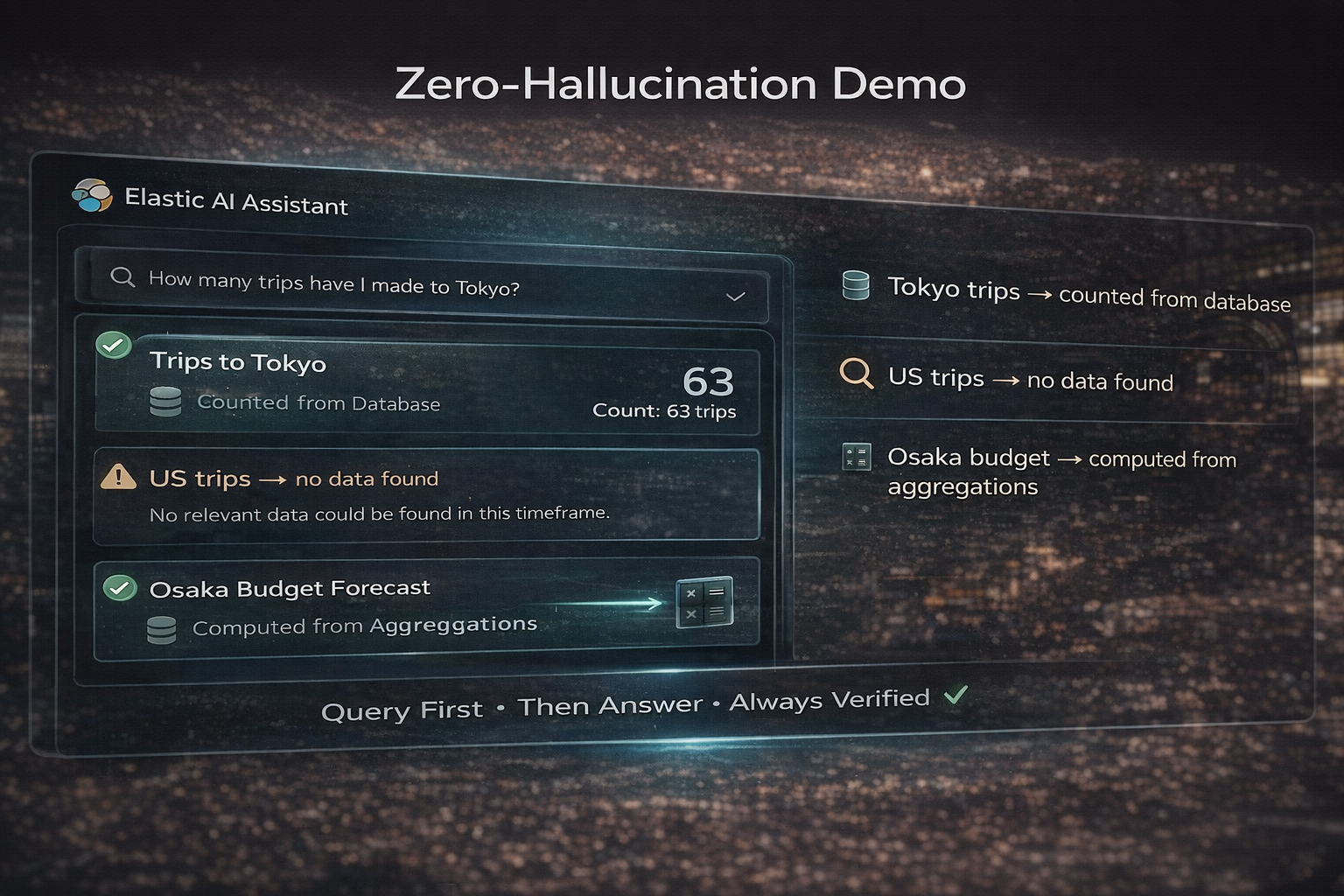
🔒 Zero-hallucination numeric answers — Every number comes from ES|QL aggregation results (SUM, COUNT_DISTINCT, daily averages), never from model prediction. 80 records tested (https://github.com/rainingsnow0914tw-ship-it/elastic-travel-budget-agent/blob/main/mock-data.csv), 20 queries verified, 0 hallucinations.
🚫 The "No Query, No Number" policy — If Elasticsearch returns zero records, the agent admits ignorance. No data = no answer. Tested across 3 LLMs (OpenAI GPT-5.2, Google Gemini 2.5 Pro, Anthropic Claude Sonnet 4.5) with consistent enforcement.
💱 Cross-currency budget projection — Handles mixed portfolios (TWD/JPY) normalized to HKD, with deterministic formulas: daily_average = total ÷ unique_days, projected_budget = daily_average × planned_days.
🔍 Full transparency — The Agent Builder tool panel exposes the complete reasoning chain — tool calls, raw ES|QL queries, aggregation steps, and calculation inputs. Trust is the primary currency.
⚙️ How we built it
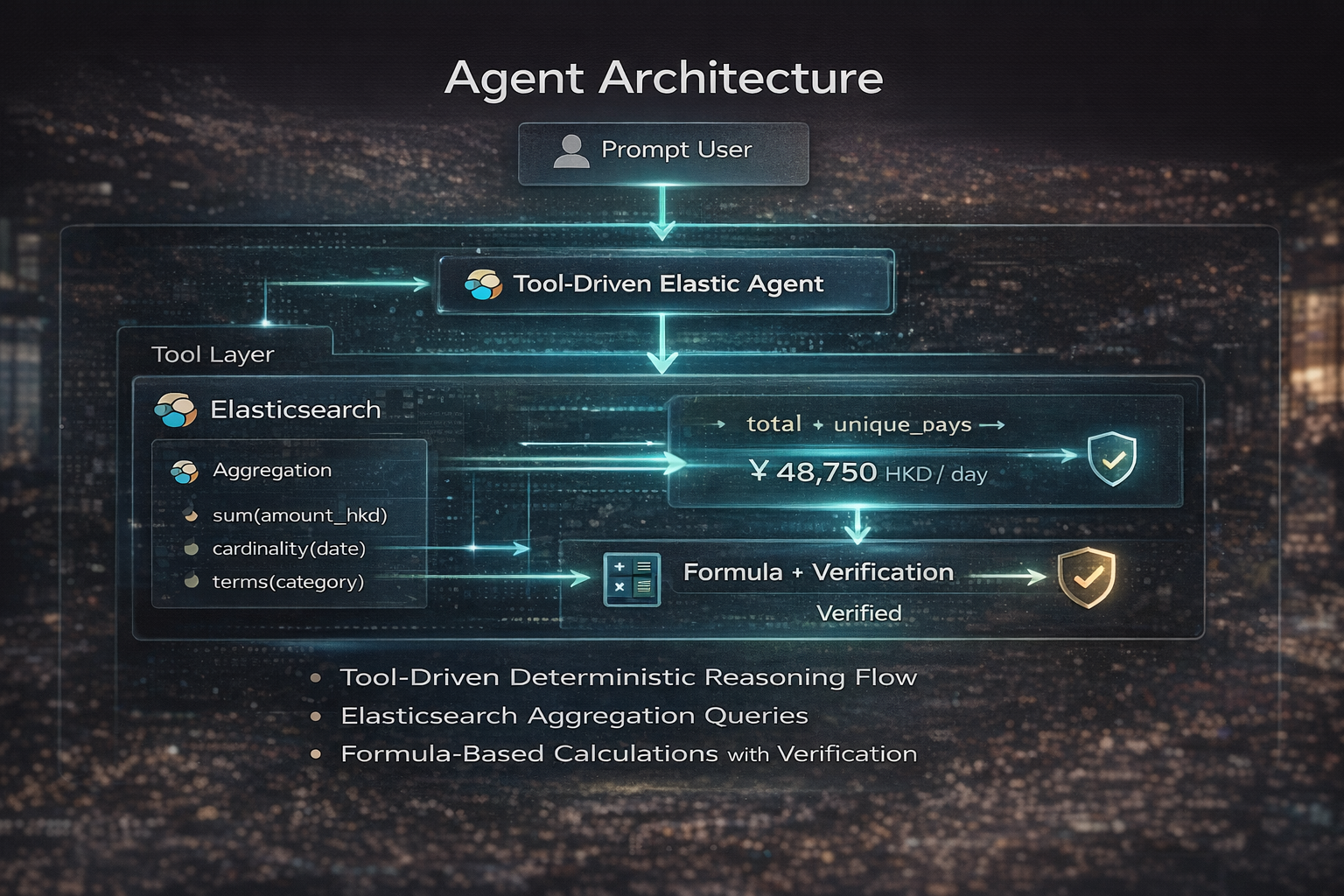
Architecture: Tool-Driven Deterministic Agent
Built entirely on Elastic Agent Builder with four platform tools. The agent follows a strict unidirectional flow:
User → Agent → Tool Call → ES|QL → Elasticsearch → Deterministic Calculation → Answer
All numeric computation happens in Elasticsearch, never in the LLM.
Elastic Agent Builder Tools Used
| Tool | Role in Agent |
|---|---|
platform.core.search |
🔑 Primary tool. Executes ES |
platform.core.get_index_mapping |
Validates index schema before querying. Ensures field names and types match expected structure. |
platform.core.list_indices |
Discovers available data sources. Confirms travel_database exists before search operations. |
platform.core.get_document_by_id |
Retrieves individual expense records for detailed drill-down after aggregation. |
🛡️ Guardrail System (The "Constitution")
We implemented strict rules directly in the system prompt to override the LLM's default tendency to "helpfully guess":
Rule 1: No query → no number. Numeric answers require prior tool calls in the same response.
Rule 2: No aggregation → no calculation. Only ES|QL aggregation outputs may produce numbers.
Rule 3: Zero records → no estimate. The agent must admit ignorance, not invent.
Rule 4: Mandatory sanity check:
daily_average × unique_days ≈ total_hkd. If the check fails, stop and re-query.Rule 5: Every response must show: filters used, fields used, formulas used, and raw query results.
ES|QL Aggregation Pipeline
total_hkd = SUM(amount_hkd)
unique_days = COUNT_DISTINCT(date)
daily_average = total_hkd / unique_days
projected_budget = daily_average × planned_days
All math is executed inside Elasticsearch's aggregation layer. The LLM acts only as a translator — converting human language into queries and formatting results back into natural language.
🧪 Multi-Model Validation
To prove the guardrails work regardless of model, we tested the same agent configuration across three LLMs: OpenAI GPT-5.2, Google Gemini 2.5 Pro, and Anthropic Claude Sonnet 4.5. Response times ranged from 6–18 seconds depending on model and query complexity — a deliberate trade-off: every second is spent on real tool calls and verified aggregation, not on generating plausible-sounding guesses. All three models achieved 0 hallucinations across 20 test queries on 80 expense records(https://github.com/rainingsnow0914tw-ship-it/elastic-travel-budget-agent/blob/main/mock-data.csv).
🤖 Multi-AI Collaboration
We used multiple AI assistants throughout the development process — for system prompt design, guardrail refinement, data schema review, demo scripting, and video production — while keeping the core agent logic strictly grounded in Elastic tools. This multi-AI workflow accelerated iteration without compromising the deterministic architecture.
🧗 Challenges we ran into
Challenge 1: Fighting the LLM's instinct to guess. Language models are trained to be helpful — they produce plausible answers even without evidence. Our first prompt draft still allowed the model to "estimate" when data was sparse. We iterated the guardrail prompt dozens of times, progressively tightening rules until numeric answers required tool call results as mandatory inputs. The breakthrough was making failure cases (zero records) a valid, expected outcome rather than something the model should "work around."
Challenge 2: Cross-currency aggregation. Our dataset spans TWD (Taiwan Dollar) and JPY (Japanese Yen) expenses. Early queries mixed currencies in aggregations, producing meaningless totals. Solution: normalize all amounts to a single base currency (HKD) at data ingestion, and enforce that the agent always queries the amount_hkd field. This moved currency handling from runtime (error-prone) to data design (deterministic).
Challenge 3: Demo-repo-agent alignment. Ensuring the demo video, GitHub repository, and live agent all describe the exact same execution flow was harder than expected. We created a shared demo script (https://github.com/rainingsnow0914tw-ship-it/elastic-travel-budget-agent/blob/main/docs_demo-script.md) that serves as the single source of truth, and verified each query shown in the video produces identical results in the live agent.
🏆 Accomplishments we're proud of
We built an agent that correctly says "I don't know." When asked "How many times have I traveled to the United States?" the agent queries Elasticsearch, finds zero records, and responds: "You have 0 trips to the United States. Your database only contains trips to: Tokyo, Osaka, Fukuoka, and Taichung." In the AI world, honest silence is a revolutionary act.
| Metric | Result |
|---|---|
| Hallucination rate | 0% (20 queries, 3 models) |
| Expense records indexed | 80 records, 4 cities, 6 categories |
| LLMs validated | OpenAI GPT-5.2, Google Gemini 2.5 Pro, Anthropic Claude Sonnet 4.5 |
| Response time | 6–18s (tool-verified, not prompt-guessed) |
| Failure handling | Verified: zero records → honest "no data" response |
| Transparency | Full reasoning chain visible in Agent Builder panel |
🎬 Demo Production: All cinematic sequences in the demo video were generated using AI video tools (Runway, Google Veo 3.1) with custom prompts. Voiceover and background music were produced using CapCut's AI audio generation. No stock footage, third-party copyrighted material, or pre-existing video assets were used. The entire demo is original AI-assisted production.
📚 What we learned
Reliable AI agents need better tool constraints and data pipelines — not just better prompts. Search + aggregation + guardrails produce more trustworthy behavior than prompt cleverness alone. The most important insight: treating "I don't know" as a first-class feature, not a failure mode, fundamentally changes how you architect an AI system. Multi-AI collaboration (5 AI assistants for design, refinement, testing, and demo production) accelerates development when core logic stays tool-grounded.
🚀 What's next
🔜 Short-term (2–4 weeks): Multi-city budget comparison (e.g., "Tokyo vs Osaka for 5 days"), category-level drill-down (accommodation vs dining vs shopping), and expanded dataset with more cities and travel patterns.
📈 Medium-term (2–3 months): Anomaly detection for spending spikes, policy-based budget alerts (e.g., "your shopping exceeded 40% of total"), and multi-lingual support for non-English-speaking travelers.
🌍 Long-term (6+ months): Applying the same deterministic, zero-hallucination pattern to finance and operations domains. We also see strong potential for accessibility applications — supporting users with cognitive challenges or motor impairments who rely on voice-first, structured data tools for independent financial management.
🧠 Technology Footprint
elastic-agent-builder · elasticsearch · es|ql · platform.core.search · openai · google-gemini · anthropic-claude · voice-interface · guardrailed-llm-prompting · runway · veo · capcut
Built With
- ai
- csv-dataset
- demo
- deterministic-aggregation-pipeline
- elastic-agent-builder
- elasticsearch
- es|ql
- for
- gpt-class-models
- guardrailed-llm-prompting
- json-index-mapping
- multimodal
- platform.core.search-tool
- tool-driven-ai-agent-architecture
- tools

Log in or sign up for Devpost to join the conversation.