


Inspiration
User testing should always be the gold standard. Sit a real person down, watch them struggle, learn something. But we ship so fast now. A founder deploys at 2am and it's live before anyone's tested it. Why can't testing keep up with shipping? And why are we limited to testing our own stuff? What if you could paste any URL and instantly see how real people experience it, what's working, what's broken, who's getting left behind?
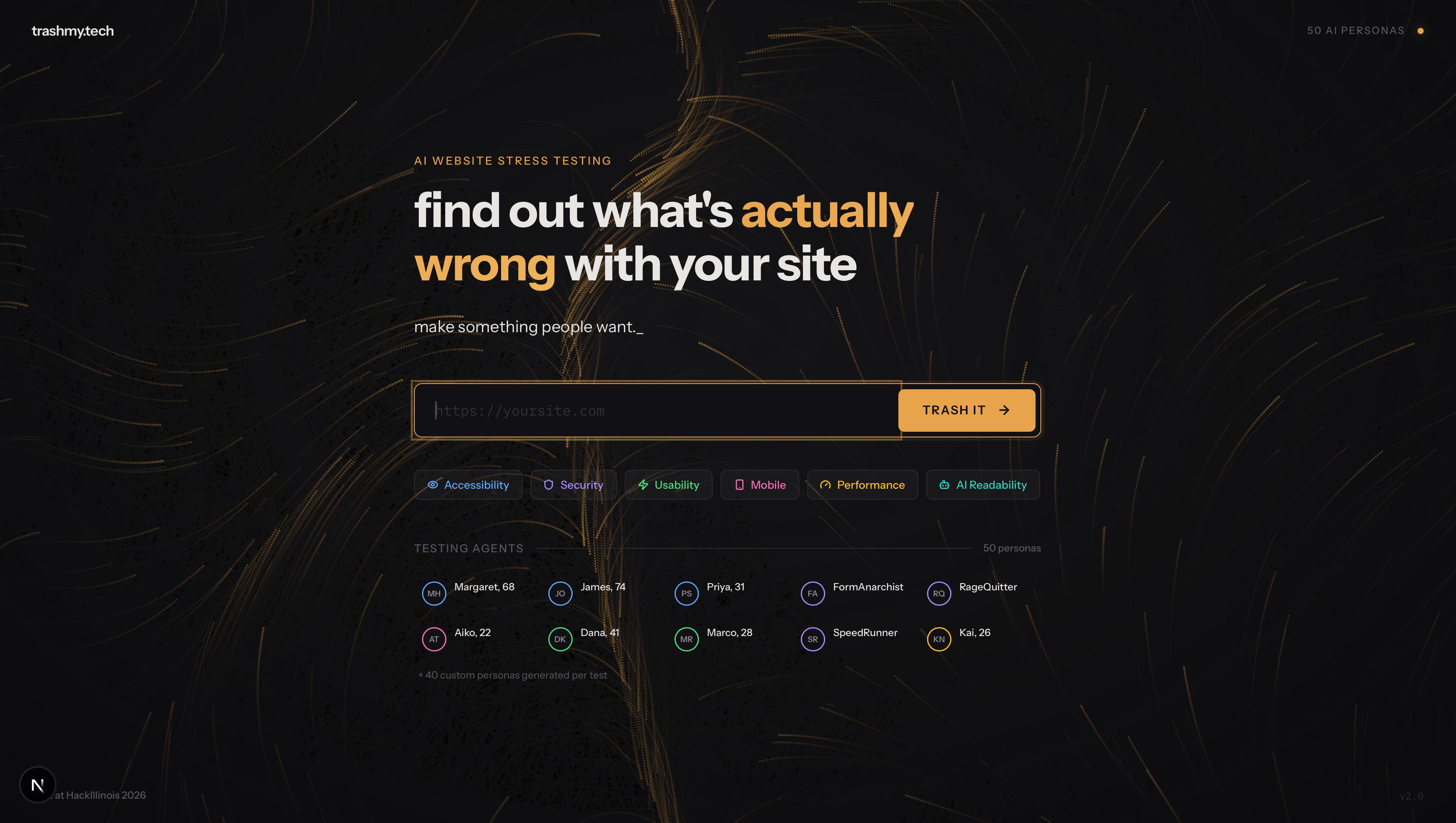
That's trashmy.tech. Paste a URL. 50 AI personas attack your site in 60 seconds. Then we tell you exactly what to fix and hand you the prompt to do it.
I started HackIllinois on a hardware track with a team. 15 hours in, my teammates decided they didn't want to commit. So I walked over to a solo table, and spent 10 minutes thinking what can I build alone that I actually care about?
What it does
You paste a URL and optionally describe your target audience ("college students applying for financial aid, mostly on phones"). Then three things happen:
50 personas launch in parallel. Each one is a real browser instance running on Modal, not a simulation. A 68-year-old woman zooming to 200%. A blind developer on a screen reader. A chaos agent injecting SQL into every form field. A 13-year-old on a cracked iPhone SE. 20 of these are our permanent testing crew. The other 30 are generated specifically for YOUR audience using Gemini, each with a name, backstory, and a specific task they're trying to accomplish on your site.
We audit how AI reads your site. Not Google SEO. AI SEO. We check if ChatGPT, Claude, and Perplexity can even access your content by auditing robots.txt for 12 AI-specific bots, checking for llms.txt, evaluating your structured data, and scoring how extractable and citable your content is. Lighthouse gives you a Google score. We give you an AI score.
You get a report that actually helps. Score out of 100, six category breakdowns, annotated screenshots with red bounding boxes pointing to exact problems ("Button: 1x44px, below WCAG minimum"), persona verdicts, and ranked fixes. The last section generates a complete prompt with all your audit data baked in. Copy it, paste it into ChatGPT or Claude, get code-level fix instructions immediately.
Every test result feeds into a shared knowledge base powered by Supermemory. When we test apple.com, we learn what good navigation looks like. When we test a broken checkout flow, we learn what bad form validation looks like. Over time, the system builds a persistent memory of patterns across thousands of sites, what works, what doesn't, which issues are common in e-commerce vs SaaS vs content sites. Your second test is smarter than your first.
How we built it
Modal is the backbone. Each of the 50 personas runs in its own isolated Modal container with a dedicated Playwright browser instance. That's 50 headless browsers launching simultaneously, each with different viewport sizes, accessibility settings, and behavioral scripts. Modal's serverless infrastructure handles cold starts, memory allocation, parallel execution, and teardown. A full 50-agent test completes in under 60 seconds because every persona runs concurrently, not sequentially. No queue. No waiting.
Gemini does the thinking. We split AI work across two models. Gemini 3.1 Pro (thinking_level HIGH) handles report generation, the single most important call that needs deep reasoning to calibrate scores and synthesize 50 sessions into a coherent audit. Gemini 3 Flash handles the volume work: generating 30 custom personas, annotating screenshots with bounding boxes, planning agent tasks, building the LLM export prompt. One API key, two models, about 60-90 total calls per run.
Supermemory provides the learning layer. Every finding, pattern, and score gets stored in Supermemory's memory API, indexed per-site and per-user. When someone tests a new e-commerce site, the system retrieves context from previous e-commerce audits to calibrate expectations. Users get persistent history of their own tests, and the collective knowledge base gets smarter with every URL.
Playwright needed serious work. Simple page.click("Sign Up") fails on any real JavaScript-heavy site. We built a smart_click system with 12 fallback strategies and a failure classifier that distinguishes "Playwright can't click this but a human could" (tool limitation, doesn't count against the site) from "this element genuinely has a usability problem" (real finding, goes in the report). That single distinction is the whole ballgame.
Stack: Next.js 14, FastAPI, Playwright, Modal, Gemini API (3.1 Pro + 3 Flash), Supermemory, axe-core, Pillow, WebSockets.
Challenges we ran into
Going solo 15 hours in was the big one. Forced me to cut ruthlessly and ship what matters.
Playwright reliability on real websites ate the most time. Every major site has its own JavaScript framework weirdness that breaks automation. I studied four open-source repos (browser-use, Skyvern, axe-playwright, unlighthouse) to build the smart_click system.
Gemini free tier rate limits meant surgical model selection. Semaphore-based rate pacing, 6-second delays between annotation calls.
Scoring calibration was sneaky. First version scored Apple.com 35/100 because the tool couldn't click anything, not because Apple's site is bad. Had to build tool_limitation vs ux_failure classification to make scores meaningful.
Accomplishments that we're proud of
Built this solo after my team dropped out. Still shipped 50 parallel agents.
The AI SEO audit doesn't really exist yet in this form. Tools that do something similar cost $50-500/mo and mostly just check if ChatGPT mentions your brand. We tell you the technical reasons it doesn't.
The Supermemory-powered learning database means the tool gets better with every site tested. Not a one-shot audit. A growing knowledge base.
The "Feed to Your LLM" export. Test your site, copy one prompt, paste it into ChatGPT, get code-level fixes. The report doesn't just identify problems. It hands you the next step.
What we learned
The gap between "Playwright can automate a browser" and "Playwright can reliably interact with a real production website" is enormous. Classifying why clicks fail was the key insight.
AI SEO is real and growing. Most website owners have no idea whether their robots.txt blocks GPTBot or ClaudeBot. That's going to matter a lot soon.
Solo hackathoning forces better decisions. No bikeshedding about frameworks. Just "what's the fastest path to working" on repeat.
What's next for trashmy.tech
Deeper learning database. As more sites get tested, Supermemory accumulates patterns across industries and frameworks. Eventually the system predicts your likely issues before agents even run, just from the URL.
CI/CD integration. Run trashmy.tech as a GitHub Action on every PR. Block merges that drop accessibility below a threshold.
Live AI visibility monitoring. Query ChatGPT, Claude, and Perplexity about your domain and track if they mention you over time.
Persona persistence. Save audience configs. Track how individual personas' experiences change across deploys.
The long-term vision: every website gets tested by its actual users before those users ever show up.
Built With
- axe-core
- fastapi
- gemini-api-(3.1-pro-+-3-flash)
- modal
- next.js-14
- pillow
- playwright
- python
- react
- supermemory
- tailwind-css
- typescript
- websockets




Log in or sign up for Devpost to join the conversation.