-
-
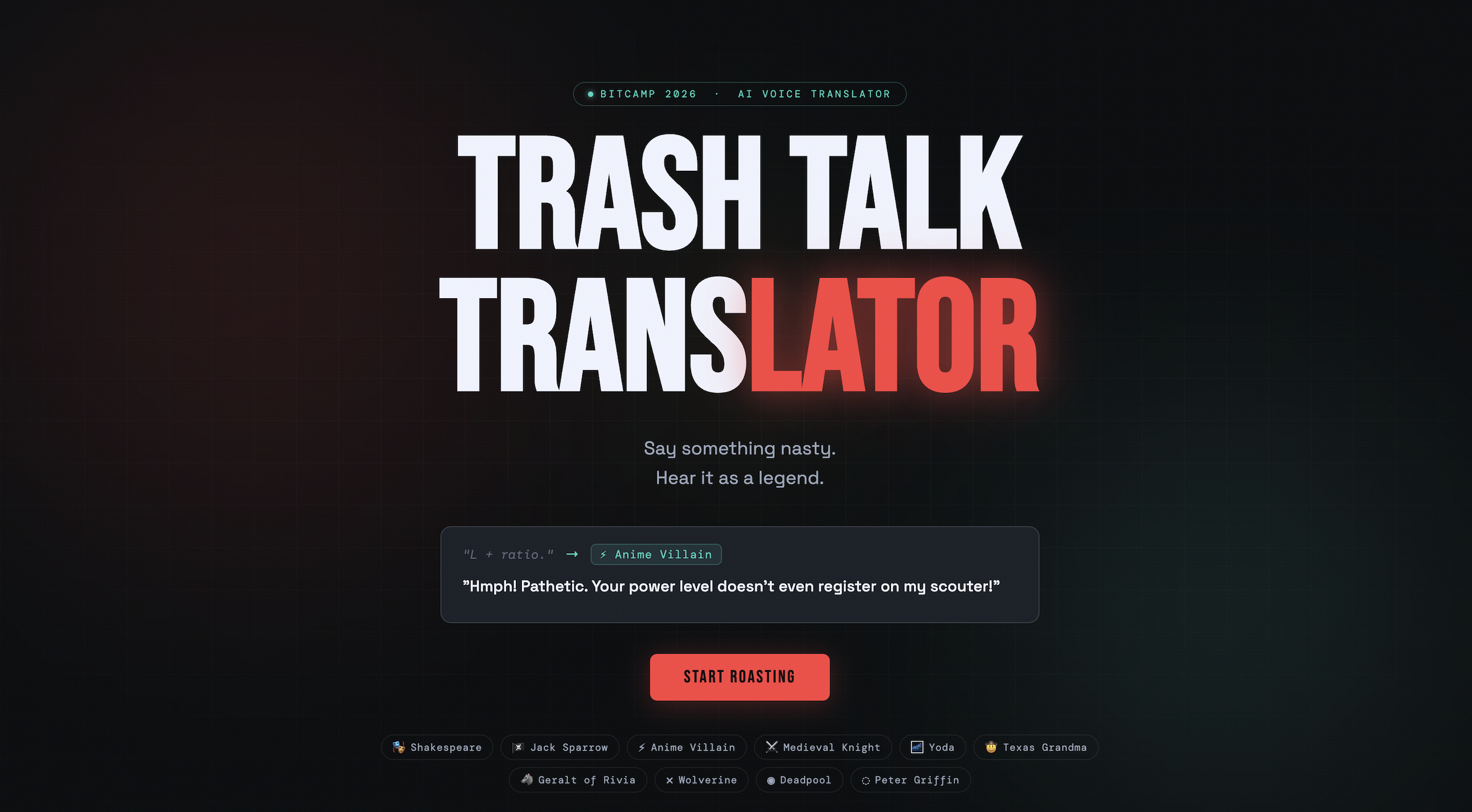
Homepage
-
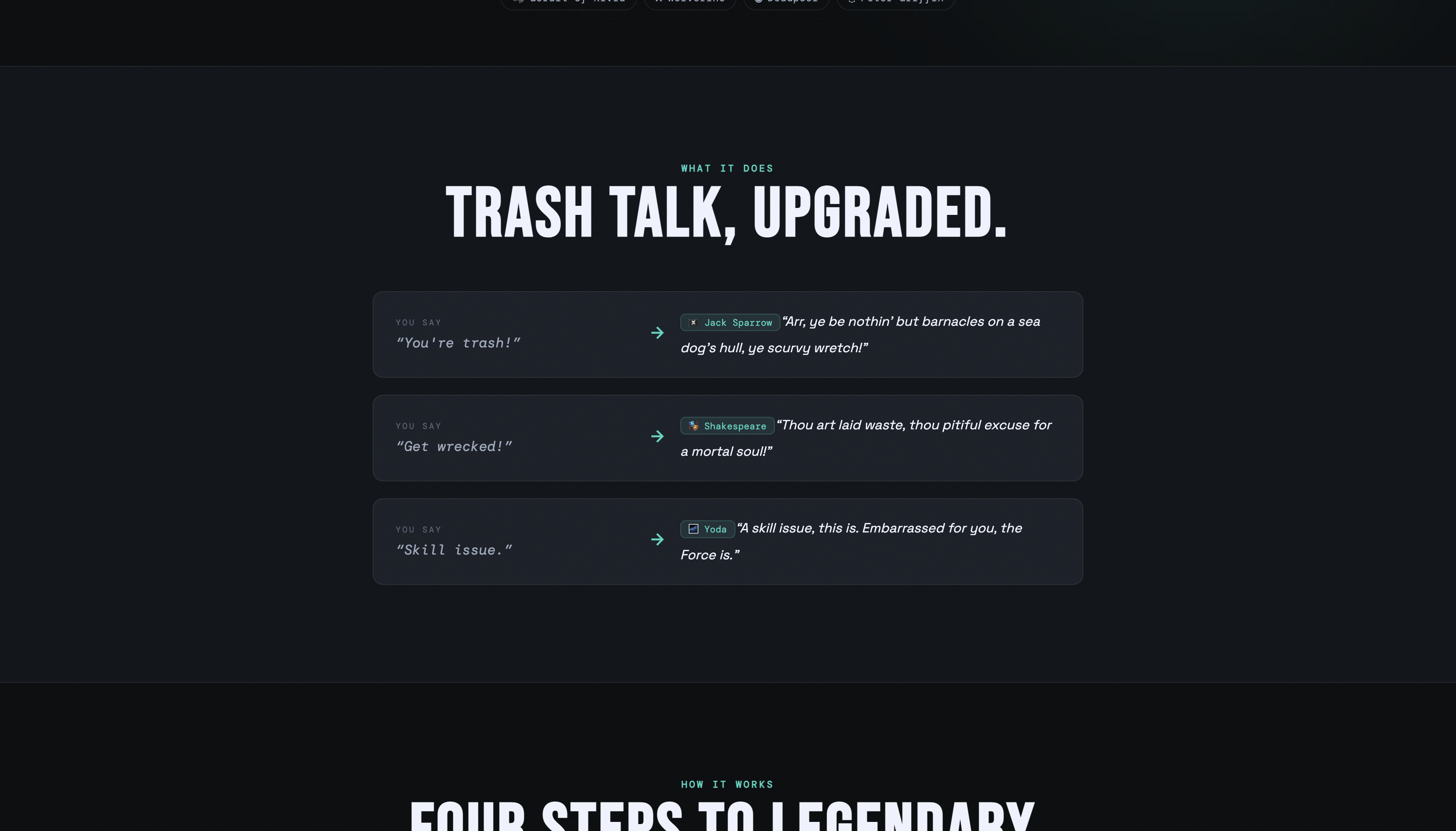
Examples of trash talk translation
-
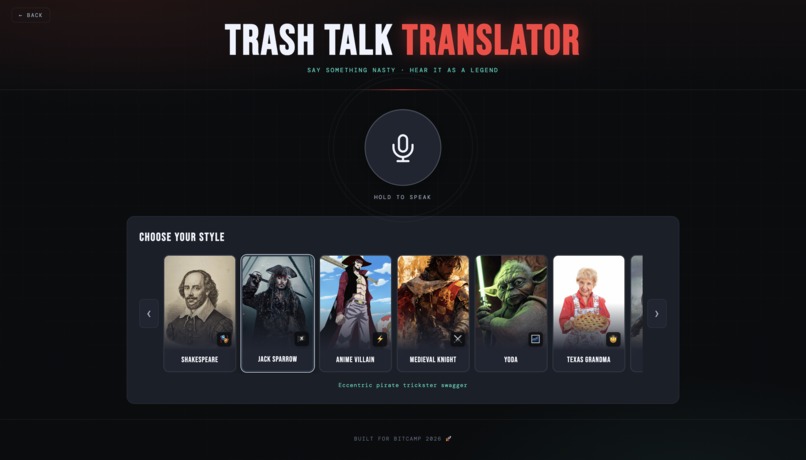
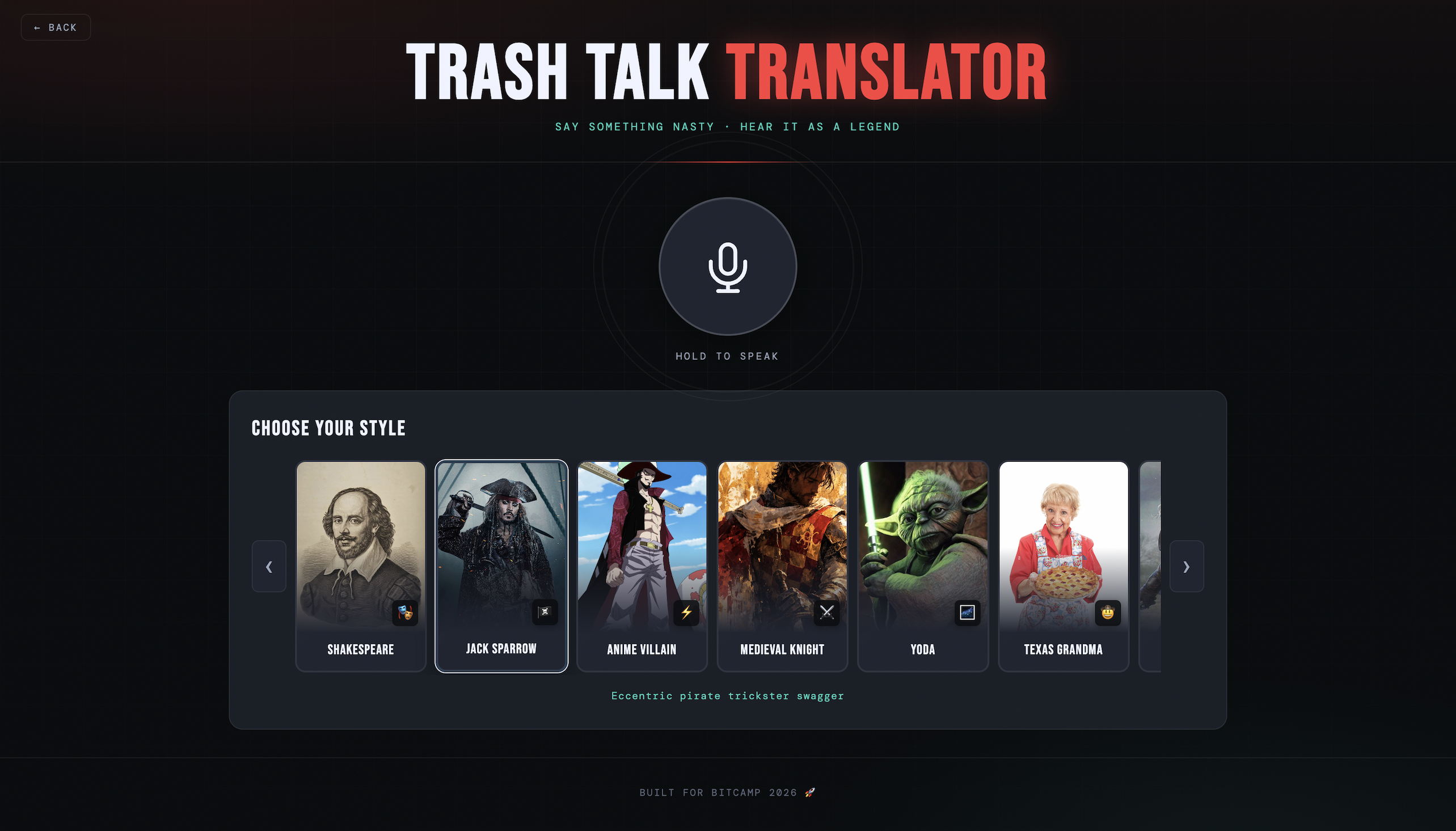
Available Personalities
-
You deserve better
-
Add audio and create trash talk

Inspiration
Every gamer has been there. Someone on your team misses a shot, feeds the enemy, or steals your kill, and the urge to say something hits hard. But modern trash talk has a problem: it's either genuinely toxic and ruins the experience for everyone, or it's so bland it doesn't land at all. We wanted to fix that. The idea was simple: what if your trash talk could come out the other side as Shakespeare? As Yoda? As a disappointed Texas grandma? The insult still lands, but now it's hilarious instead of harmful. It diffuses tension, makes people laugh, and turns a frustrating gaming moment into a memorable one. We also just wanted to build something we'd actually use ourselves.
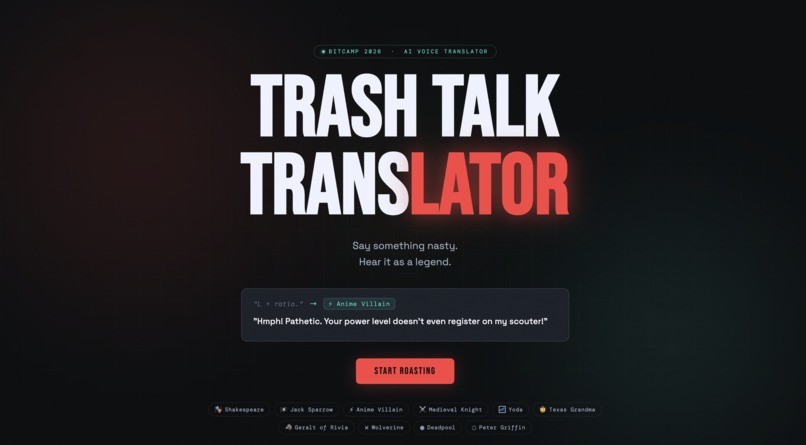
What it does
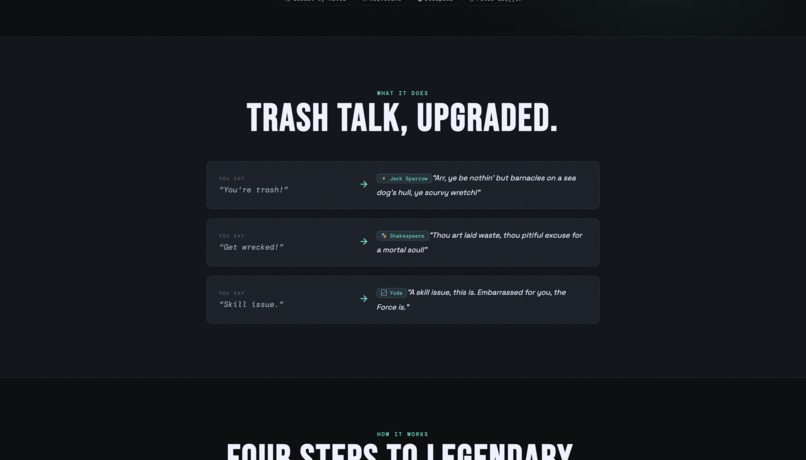
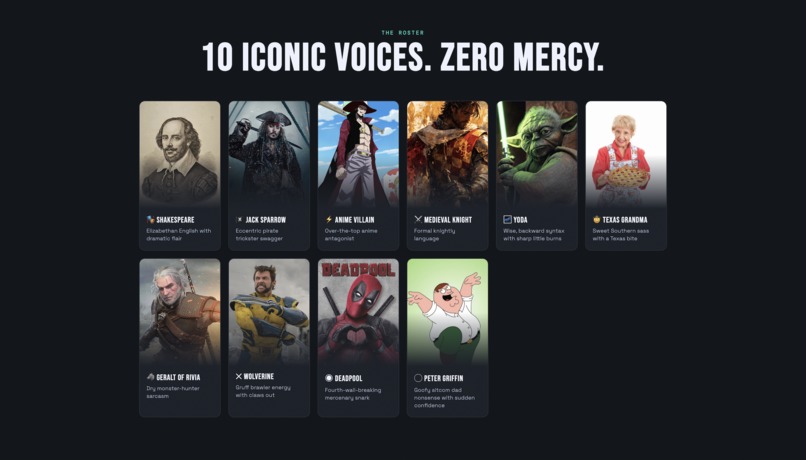
Trash Talk Translator is a real-time AI voice filter for gamers. You speak your trash talk into a microphone, the app translates it through one of 9 iconic personalities, and plays it back in a fully voiced, AI-generated audio response. The 10 personalities are Shakespeare, Jack Sparrow, Anime Villain, Medieval Knight, Yoda, Texas Grandma, Geralt of Rivia, Wolverine, Deadpool, and Peter Griffin, each with their own carefully engineered voice, prompt style, and ElevenLabs voice profile. There's also a Discord bot that brings the whole thing into voice channels. Mid-game, a teammate can hit the soundboard to fire off a freshly AI-generated roast in character, live, in the call.
How we built it
The frontend is a React + Vite app styled with a post-apocalyptic arcade brutalism aesthetic, Bebas Neue display font, dark surfaces, red accent glow, and animated mic rings. It uses the Web Speech API for push-to-talk input and streams audio back from the backend. The backend is a FastAPI server that handles translation and audio generation. We built a provider-agnostic translation layer that routes to either Claude (Anthropic) or Gemini (Google) based on an AI_PROVIDER environment variable, so we can swap models without touching any application code. Translations go through carefully tuned personality prompts stored in a shared prompts.json, and audio is generated via ElevenLabs with per-personality voice mappings. The Discord bot is built with discord.py, uses Deepgram for real-time voice transcription in voice channels, and shares the same translation and TTS pipeline as the web app, with no duplicate logic. Both the web app and API are deployed on Render. The frontend is also accessible at http://www.trashlator.club.
Challenges we ran into
Prompt engineering was harder than expected. Getting each personality to sound genuinely distinct, not just a few stock phrases swapped in, took a lot of iteration. Early Shakespeare outputs read as a thesaurus exploded. Early Geralt outputs were melodramatic monologues. We ended up with detailed rule sets for each personality covering tone, word limits, what to avoid, and what references to use naturally versus sparingly. The Discord bot's SSRC mapping was a silent failure. When the bot joined a voice channel before /listen was called, Discord had already sent the SPEAKING events that map user SSRCs to audio streams. Without those mappings, the bot received audio data it couldn't attribute to anyone and silently dropped it. The fix was to force a rejoin on every /listen command so the bot always catches the initial SPEAKING events. CORS in production. The frontend is served from both a Render URL and a custom domain. The backend was only whitelisting one origin, so requests from http://www.trashlator.club were blocked. We refactored the settings to accept a comma-separated ALLOWED_ORIGINS environment variable, allowing multiple origins to be configured without code changes.
Accomplishments we're proud of
The personality system genuinely works. Each of the 10 characters sounds like themselves, not a generic "funny voice", and the prompts hold up across a wide range of input. You can say something completely absurd, and Yoda will still find a way to make it land with inverted syntax. The full pipeline, mic input, AI translation, ElevenLabs voice synthesis, and audio playback run end-to-end in under two seconds in most cases. The Discord bot that brings real-time voice translation to a live call mid-game is the feature that consistently gets the biggest reaction when we demo it.
What we learned
Prompt engineering is a craft. The difference between a personality that feels alive and one that feels like a costume is entirely in the specificity of the instructions; what to avoid is just as important as what to do. Shared infrastructure matters. Building the translation layer as a provider-agnostic service with a single AI_PROVIDER toggle meant we could run Claude during the hackathon and Gemini as a fallback without duplicating any logic across the web app and the Discord bot. Browser audio APIs have sharp edges. The Web Speech API behaves differently across Chrome, Safari, and Firefox in ways that aren't well documented, and ElevenLabs audio playback requires careful cleanup of object URLs to avoid memory leaks in long sessions.
What's next
More personalities. Community voting on who gets added next. Multiplayer mode. Each player in a session picks a different personality, and everyone hears each other's trash talk translated in real time. Twitch / Streamer integration. Viewers trigger personality roasts as channel point redemptions. Mobile app. The web experience works on mobile, but a native app would make the mic input far more reliable. Custom personalities. Let users define their own character with a name, description, and voice style.





Log in or sign up for Devpost to join the conversation.