Inspiration
Our team members all come from diverse backgrounds: from France, Turkey, Khazakhstan, and even from far east Japan. However, we all were fortunate enough to have the opportunity to study English, as we grew up, so had instant google-search access to the entire open-source community's knowledge, where English is the standard medium for communication. However, not everyone in this world is fortunate enough to have this opportunity.
What it does
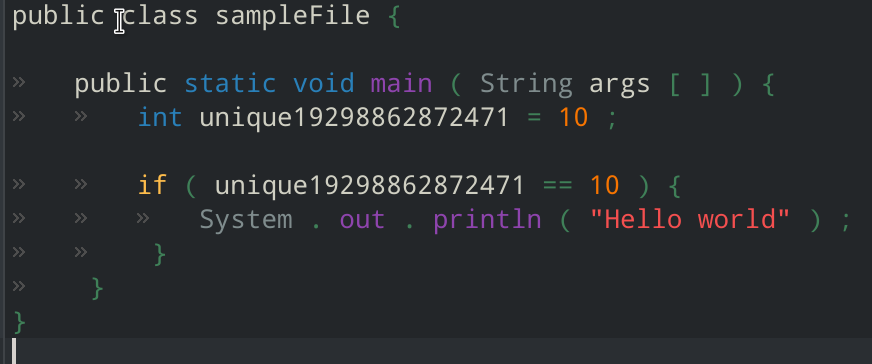
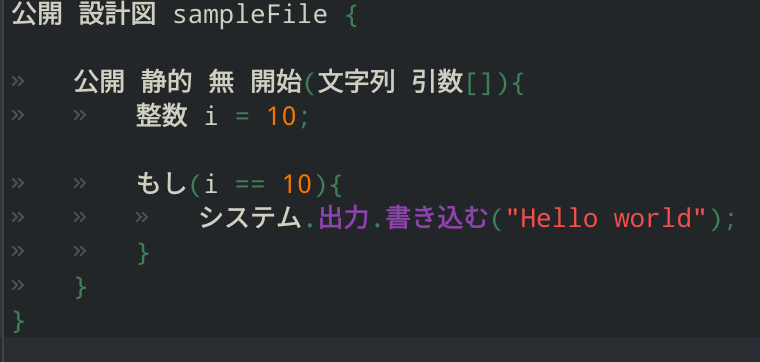
In an attempt to increase access to computer science and programming fundamentals, we developed an ecosystem to allow users to write scripts and program in their mother-tongue.
This project sets up an ecosystem where users anywhere around the globe can contribute translations of programming languages (https://github.com/OcEaNvS/trnpkgs), and our parsers will integrate all that data into our engine to comprehend any human language.
NOTE Please read README.md for further details on the design
How we build it
You need to use Gradle to build our program, using the following command from the repository root:
gradle build
How to run
You can run it with gradle with the following command:
gradle run --args="sampleFile.java -u --lang java --source jp --target en"
sample/java/sampleFile.java => language you want to translate -u => update the translation file from server --lang java => programming language you want to translate to --source jp => translate from japanese --target en => default
Alternatively, you can also use the bashscript after building it
./transpire samples/java/sampleFile.java -u --lang java --source jp
NOTE
We have some test files under ./samples/** that you are free to use as inputs from a variety of languages.
Challenges we ran into
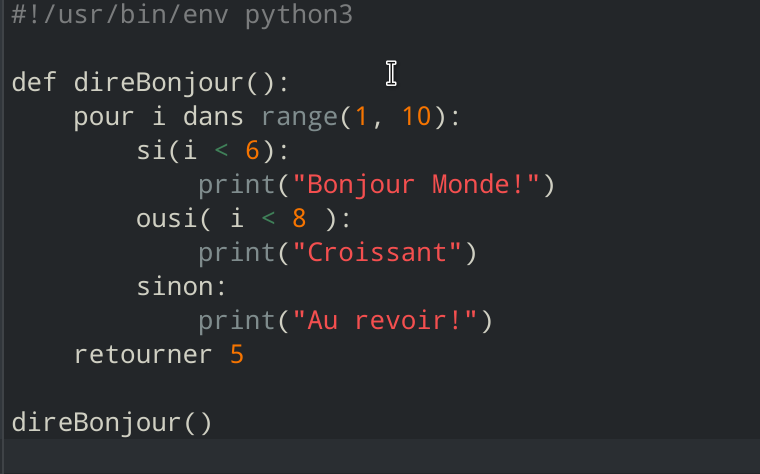
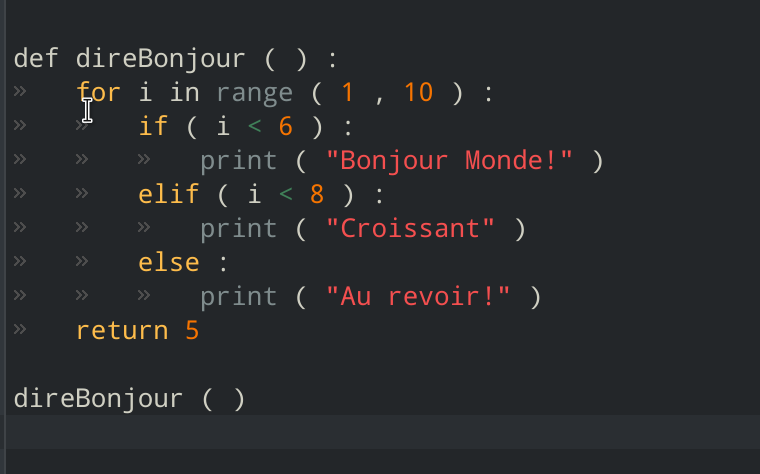
Abstracting the parsing was the most difficult part of implementing our program. For example, there are programming languages that depend on indentation and spacing (such as Python) and ones that use curly braces (like C and Java). Making our parsers general enough to handle various different scripting structure was challenging.
Another challenge worth mentioning was preventing the parser from switching out words inside comments and quotes -- since these are elements that interface with the user and changing them would devestates the program.
Accomplishments that we're proud of
We are very proud of two points:
- How general and powerful our program is
We implemented a Japanese to Java translation, Turkish to C, French to Python in the span of 1 hour as an example to show how general and powerful our program is.
- Creating this whole ecosystem in a short amount of time
Our program allows users to add translations of language tokens just by modifying a JSON file, and creating pull requests to the master branch. We have a daemon running in our servers that fetches recent commits every 5 minutes and constantly keeps track of changes. Finally, the users get to use new translations when our parsers requests for changes to the translation data.
What we learned
We gained a lot of experience with regular expressions and got to appreciate how much work the language parsers and language servers we use all day and take for granted.
What's next for Transpiler
Adding more language translations ( Collaboration with the Open Source Community )
More powerful parsers that can comprehend the underlying logical structure of the programming languages.


Log in or sign up for Devpost to join the conversation.