-
-
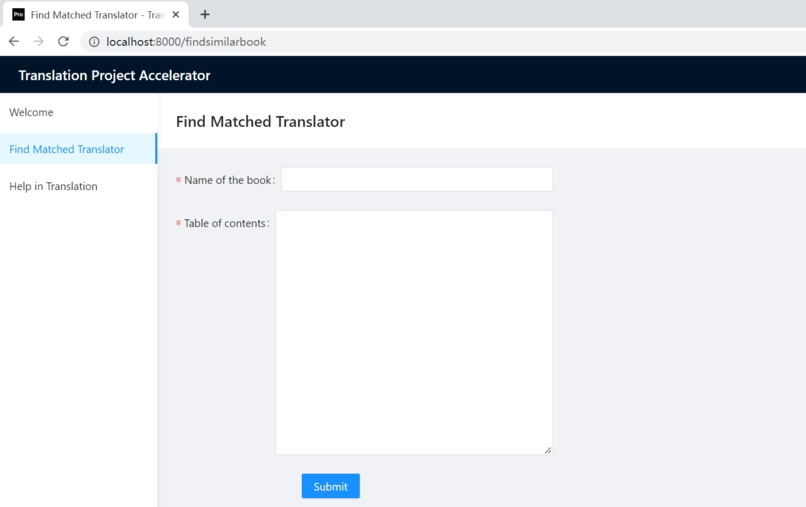
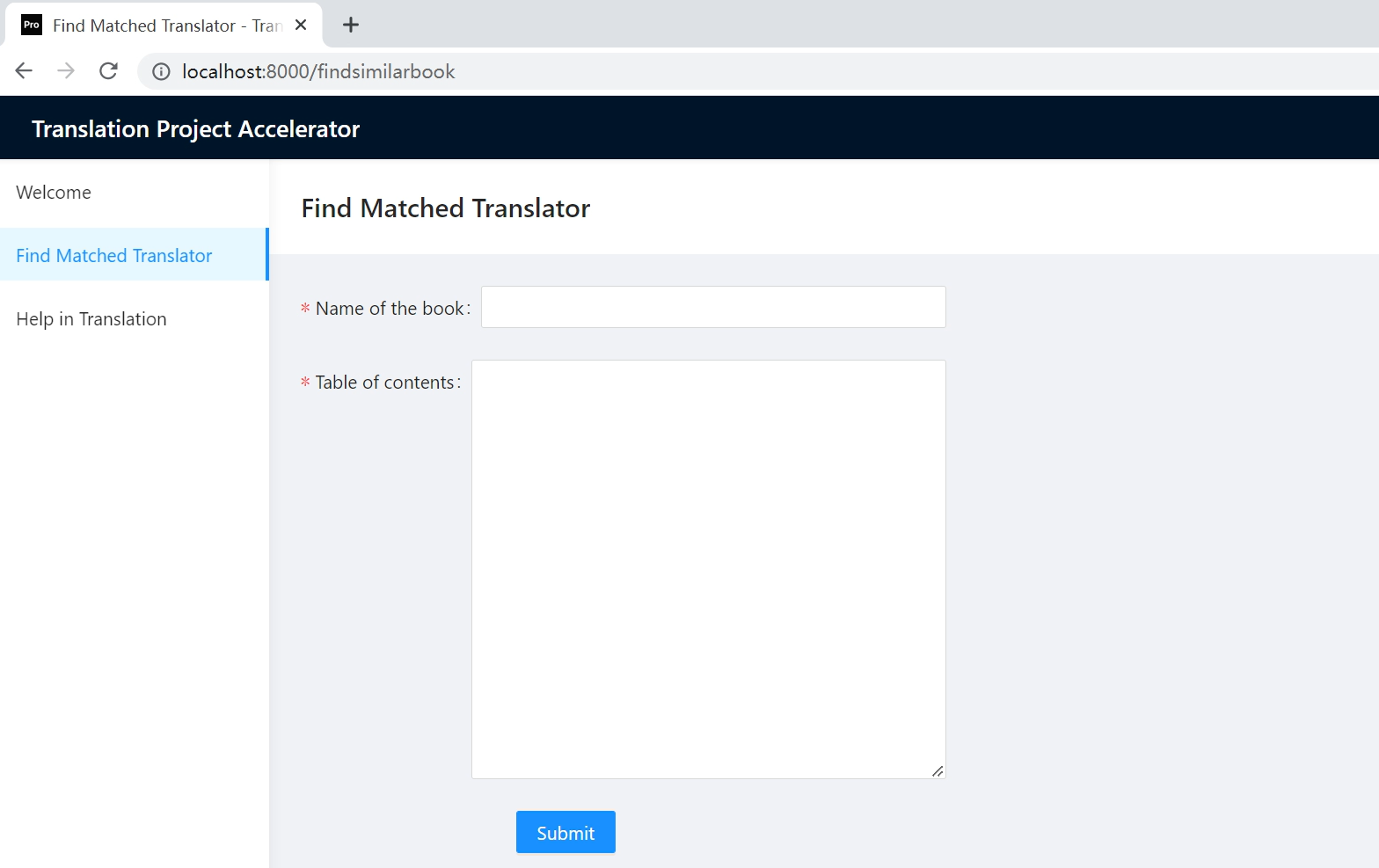
Find Matched Translator
-
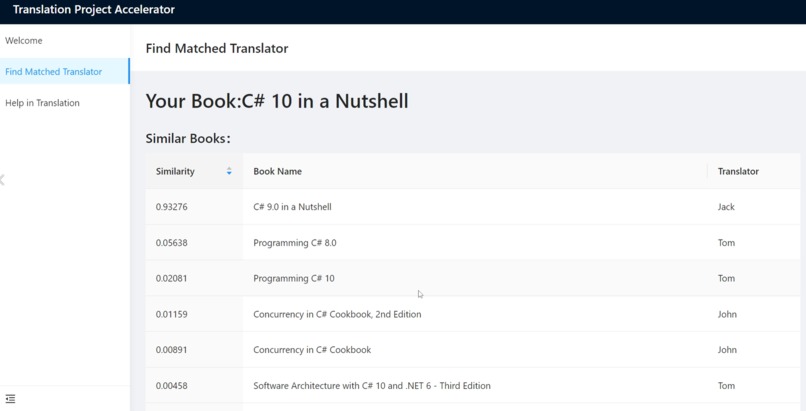
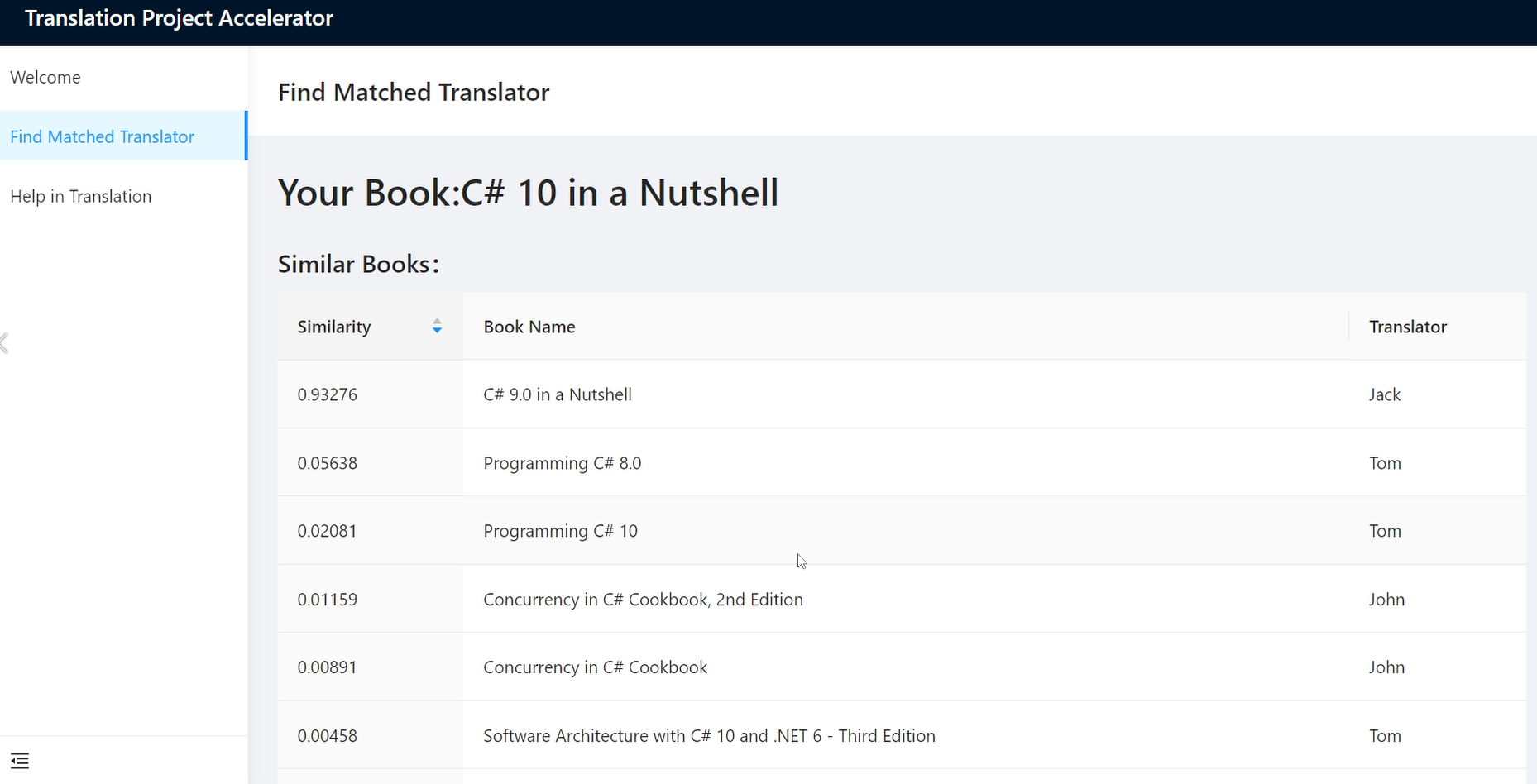
The Result of Find Matched Translator
-
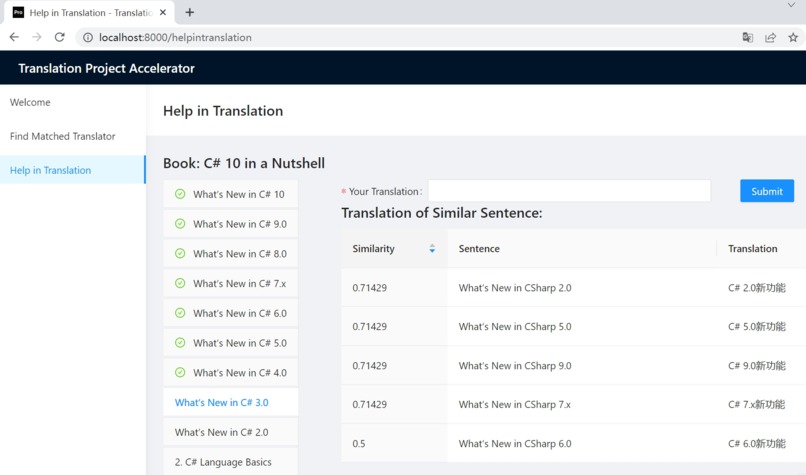
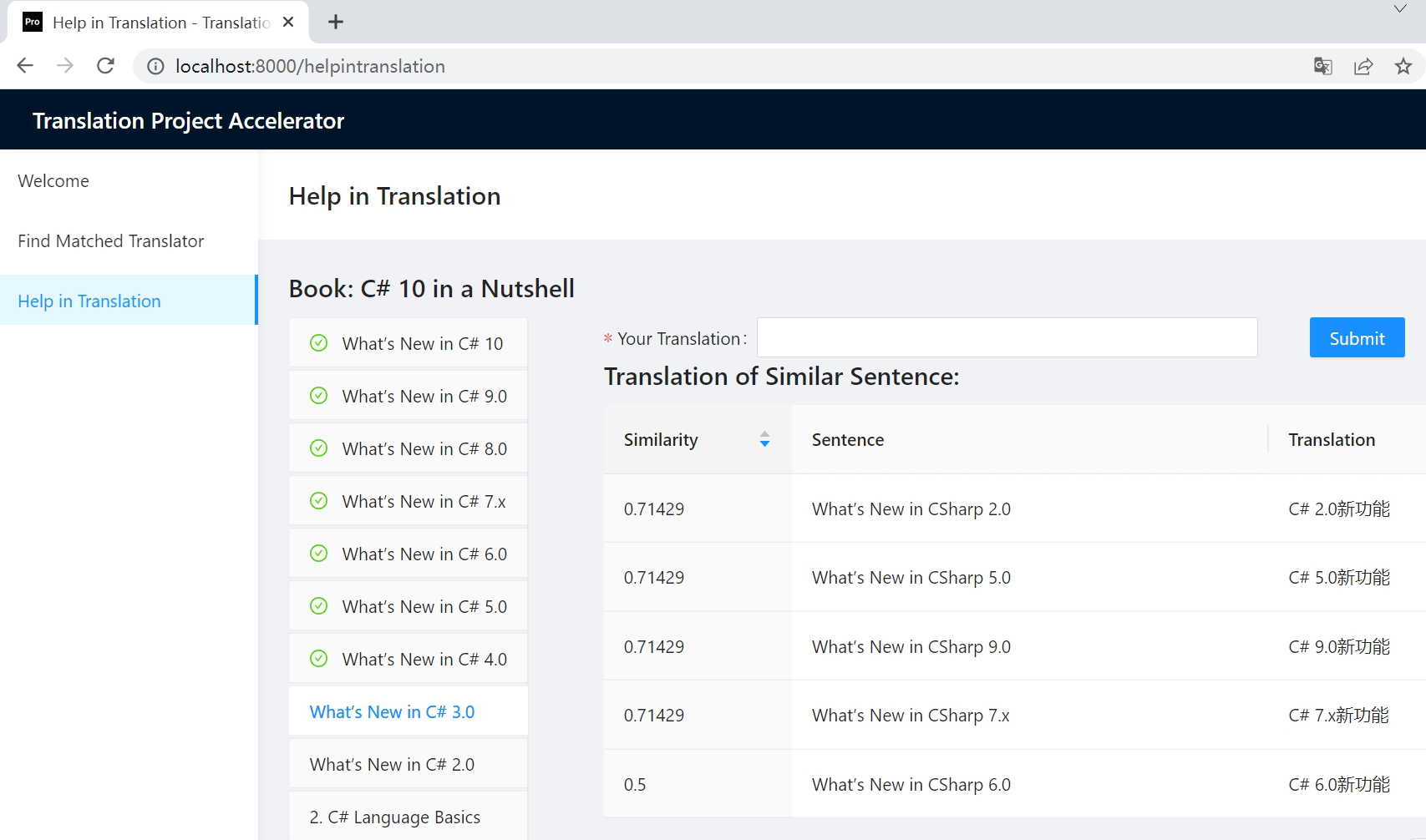
Help In Translation
-
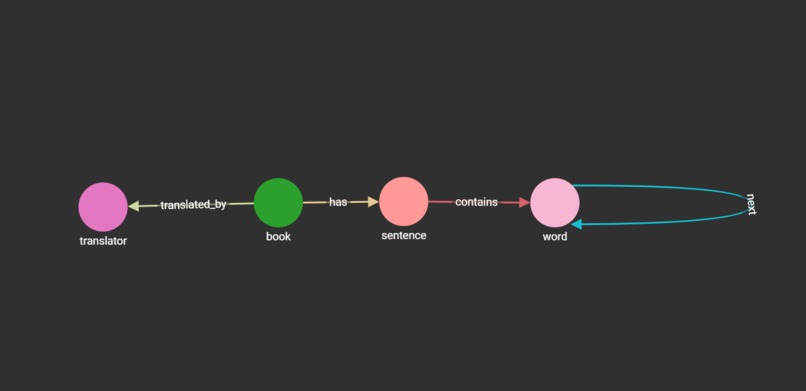
Graph Schema

Inspiration
I am a translator of nine books. Based on my experience in translating nine books, I found that there are two challenges in the professional translation field:
- Presses and translation companies have difficulty in finding translators who match the books, If presses and translation companies can find translators of similar works, the translation efficiency of works will be greatly improved.
- Translators have difficulty in finding similar sentences for reference during translating. If there is a service can provide published translations of similar sentences as references, the translation efficiency of works will be greatly improved.
What it does
There are 2 modules in our project, Find Matched Translator module and Help in Translation module:
Through the Find Matched Translator module,
Presses and Translation companies input the name of a book and the Table of contents. Our system will return the similar books and related translators ranked by similarity. Presses and Translation companies can contact the matched translators to make sure the shortest time prepods of translation project.
Through the Help in Translation module, Translators can find translations of similar sentences as references. It will reduce duplicated work and speed up the translation.
How we built it
- Use TigerGraph Cloud to write the draft of schema.
- Use Jupyter notebook to NLP and initialize data into TigerGraph.
- Use Jaccard Similarity Algorithm to return the result from database directly with less python and typescript code in backend and frontend.
- Use Flask as backend.
- Use Ant-Design as frontend.
Challenges we ran into
- We never know TigerGraph before. It is our first time to touch TigerGraph in this hackathon. I thought it was a challenge, but I found it was simpler and better than expected.
- The default implementation of Jaccard Similarity Algorithm in TigerGraph GitHub can’t return translator vertex. So I change the code of Jaccard Similarity Algorithm and apply antipatterns to add translator as an attribute of book vertex. Problem resolved! Open source is very important here.
Accomplishments that we're proud of
- I have some NLP project experience. It is my first time to save the NLP sentencizing and tokenizing result into graph database. It is speed up a lot.
What we learned
- TigerGraph does save a lots of time because I can save and store the caculation result in NLP sentencizing and tokenizing work. So I don't need to caculate again in next time. I think TigerGraph is the best tool & product to save and store the caculation result.
- Jaccard Similarity graph algorithm is powerful.
What's next for Translation Project Accelerator
I am using Translation Project Accelerator in my current translation work. I will add more features base on my current translation work.
When I think it is prefect enough, I will sale it to book presses and translation companies via my connections.
In future, I will host it as SAAS online for individual translator at the world.
Built With
- ant-design
- ant-design-pro
- flask
- pandas
- python
- pytigergraph
- react
- spacy
- tigergraph
- typescript


Log in or sign up for Devpost to join the conversation.