




Inspiration
The idea came from a frustrating afternoon spent refactoring 50+ JavaScript files to modern ES6+ syntax.
I found myself typing the same prompt over and over: "Convert this function to arrow function syntax..." Then tweaking it: "Also use const instead of var..." Then again: "Add template literals too..."
By file 20, I thought: "Why doesn't AI remember I just did this exact thing 19 times?"
That's when it clicked—AI assistants have amnesia. Every task starts from scratch, even when you're doing the exact same transformation repeatedly.
I looked at existing solutions:
- Prompt libraries: Static, require manual searching
- Custom scripts: Need coding skills, break easily
- Browser history: Impossible to find the right conversation
None solved the real problem: AI that learns YOUR patterns and automates YOUR repetitive work.
When Chrome announced Built-in AI with local inference, I saw the perfect opportunity—fast, private, and powerful enough to build intelligent pattern matching without sending data to servers.
Transformly was born: Your personal AI assistant that remembers what you do and automates it the next time.
What it does
Transformly is a Web App that learns from your successful AI transformations and automatically suggests the right prompt when you encounter similar tasks.
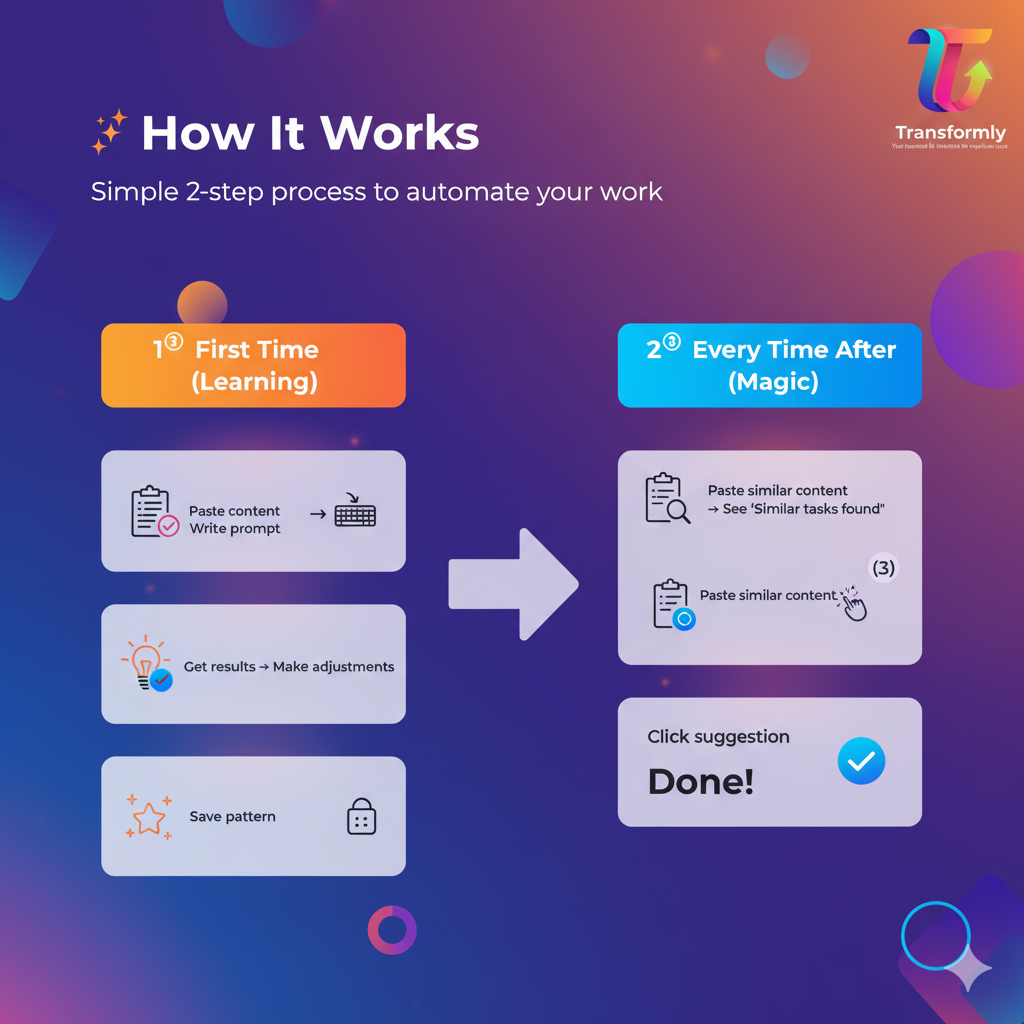
🎯 Core Workflow
First Time (Learning Phase):
- Paste your content (code, data, text—anything)
- Write a prompt or provide input→output examples
- Get AI-generated results using Chrome's Built-in AI
- Make adjustments if needed
- Click "Save Pattern"
Every Time After (Automation Magic):
- Paste similar content
- Instantly see: "Similar tasks found (3)"
- Click a suggestion
- Get perfect results in one click—no typing!
✨ Key Features
🧠 Intelligent Pattern Recognition
- Learns from every successful transformation
- Dual-embedding strategy: matches both content structure AND user intent
- Achieves 85-95% accuracy for similar tasks
💡 Smart Context-Aware Suggestions
- Non-blocking suggestion cards appear as you work
- Shows confidence scores (only displays 70%+ matches)
- Groups by task category for easy browsing
- Updates in real-time as you type hints
⚡ One-Click Execution
- Auto-fills saved prompts with reference outputs
- Processes multiple files in batch
- Consistent results every time
- Works offline after initial learning
🔄 Adjustment Learning
- Tracks your multi-step prompt refinements
- Combines adjustments into optimized single prompts
- Learns your preferences over time
- Background processing—zero latency
🎨 Tech Stack Awareness
- Configure preferred frameworks (React, Vue, Angular)
- Set default styling (Tailwind, CSS, styled-components)
- AI adapts outputs to your workflow
- Remembers your coding conventions
🔒 100% Local & Private
- All data stored in browser's IndexedDB
- No cloud sync, no server uploads
- Powered by Chrome's Built-in AI (Gemini Nano)
- Your patterns stay on your machine
🎓 Real-World Use Cases
For Developers:
- Refactor legacy code to modern syntax (once → reuse forever)
- Convert between frameworks (jQuery → React)
- Generate boilerplate with team conventions
- Transform API responses to TypeScript interfaces
For Content Creators:
- Reformat content for different platforms
- Convert data tables between formats (JSON → Markdown)
- Standardize writing tone across documents
- Extract and restructure information
For Data Analysts:
- Clean and normalize datasets
- Convert between JSON/CSV/XML formats
- Extract specific fields from complex data
- Standardize date/number formats
For Students:
- Restructure notes into study guides
- Convert between citation formats
- Summarize with consistent style
- Extract key information from documents
How we built it
Technology Stack
Chrome Built-in AI APIs:
- Gemini Nano - Local language model for inference
- Prompt API - Task execution and generation
- Embedding API - Semantic similarity matching
- No external API keys required
Frontend:
- Vanilla JavaScript (ES6+) for maximum performance
- Web Components for modular UI
- IndexedDB for local storage
- Web App Manifest V3
Architecture:
- Clean separation of concerns (8 core classes)
- Modern async/await patterns throughout
- Comprehensive error handling and fallbacks
- JSDoc documentation for maintainability
Core Technical Innovations
1. Dual-Embedding Strategy
The breakthrough was realizing we needed TWO types of embeddings:
// Input Pattern Embedding - matches content structure
const inputEmbedding = await embedContent(
inputCode + tags + patterns + language
);
// Task Description Embedding - matches user intent
const taskEmbedding = await embedContent(
title + subtitle + prompt + keywords
);
- User pastes code → Compare against input embeddings (75% threshold)
- User types hint → Compare against task embeddings (65% threshold)
- Both available → Hybrid scoring for best results
2. Adaptive Specificity Analysis
Not all patterns should be equally generic. We built an intelligent analyzer that determines specificity level:
// WITH reference examples → SPECIFIC pattern
"Convert If-Else to Ternary Operator"
// WITH adjustments → MORE SPECIFIC
"Refactor to TypeScript with Async/Await"
// NO references + generic prompt → GENERIC pattern
"Improve JavaScript Code Quality"
The AI analyzes:
- Presence of reference examples
- Number of adjustments made
- Prompt wording specificity
- Input/output consistency
Then creates appropriately specific or generic patterns for optimal reusability.
3. Post-Task Learning Pipeline
To achieve zero-latency UX, all learning happens AFTER task completion:
// User clicks "Save" → immediately returns
async finalizeTask(savePattern) {
if (savePattern) {
// Queue background learning (non-blocking)
this.learningEngine.processCompletedTask(taskData)
.then(result => console.log('✅ Pattern learned'))
.catch(err => this.queueForRetry(taskData));
}
return { success: true, learningQueued: true };
}
Benefits:
- Zero UI blocking during analysis
- Only saves successful patterns (quality over quantity)
- Retry mechanism for failed analysis
- Processes pending patterns on app restart
4. Content Analysis Pipeline
Smart content analysis with AI fallback:
// Quick rule-based analysis for short content (<100 chars)
quickAnalysis(content) {
// Regex patterns for language detection
// Structure analysis (loops, conditionals, classes)
// Returns tags, domain, complexity
}
// AI-powered deep analysis for complex content
async aiAnalysis(content) {
// Generate comprehensive metadata
// Semantic understanding of patterns
// Returns detailed characteristics
}
This balances speed (instant for simple content) with accuracy (AI for complex content).
5. Hybrid Matching Algorithm
Three-mode matching system:
async findMatches(input, hint) {
const matches = [];
// Mode 1: Input matching (content similarity)
if (input.length > 50) {
const inputMatches = await matchByInput(input);
matches.push(...inputMatches);
}
// Mode 2: Hint matching (keyword/intent)
if (hint.length > 2) {
const hintMatches = await matchByHint(hint);
matches.push(...hintMatches);
}
// Mode 3: Hybrid boost (combine signals)
if (both available) {
applyKeywordBoost(matches, hint);
}
return deduplicateAndSort(matches);
}
Development Process
Week 1: Research & Prototyping
- Studied Chrome Built-in AI documentation
- Experimented with embedding generation
- Built proof-of-concept matching system
- Validated core hypothesis with test data
Week 2: Core Architecture
- Designed class structure (8 main classes)
- Implemented dual-embedding storage
- Built learning engine with adaptive specificity
- Created content analysis pipeline
Week 3: Integration & Polish
- Connected all components
- Implemented background processing
- Added error handling and fallbacks
- Built retry mechanisms
Week 4: Testing & Optimization
- Real-world testing with various content types
- Performance optimization (debouncing, caching)
- Edge case handling
- Documentation and code cleanup
Technical Challenges Overcome
Challenge 1: Embedding Quality
- Initial attempts: 0.27 similarity for identical content
- Solution: Dual-embedding strategy with content + metadata
- Result: 85-95% similarity for matching tasks
Challenge 2: Specificity Balance
- Problem: Too generic → poor matches; too specific → low reuse
- Solution: Adaptive analysis based on references and adjustments
- Result: Optimal reusability at appropriate specificity level
Challenge 3: UX Latency
- Problem: AI analysis blocked user workflow
- Solution: Post-task background learning
- Result: Zero perceived latency
Challenge 4: IndexedDB Complexity
- Problem: Multiple related data stores, complex queries
- Solution: Clean storage manager abstraction with indexes
- Result: Fast queries (<50ms) even with 100+ patterns
Challenges we ran into
1. The "0.27 Similarity" Mystery 🔍
The Problem: Early testing was devastating. User pastes identical code twice → 0.27 similarity. The system was useless.
Root Cause: We were embedding the wrong things. First attempt:
// WRONG: Embedding prompt metadata
const embedding = embed(title + subtitle + keywords);
// Then comparing against user's INPUT CODE
// Apples vs. Oranges!
Solution Journey:
- Attempt 1: Embed everything together → messy, inconsistent
- Attempt 2: Embed only input → lost keyword matching
- Attempt 3: Dual embeddings (input + task) → SUCCESS!
Lesson Learned: In semantic search, WHAT you embed matters infinitely more than HOW you embed it.
2. The Generic vs. Specific Dilemma ⚖️
The Problem:
- Too generic: "Refactor Code" matched everything poorly
- Too specific: "Convert If-Else on Line 5 to Ternary" never matched again
Real Example: User does: "Convert if-else to ternary" We saved: "Modernize JavaScript Code" Next time: User pastes if-else → no match (too generic)
Solution: Built adaptive specificity analyzer that considers:
- Reference examples (specific if provided)
- Adjustment count (more adjustments → more specific)
- Prompt wording analysis
- Transformation consistency
Result:
- With references: "Convert If-Else to Ternary" (specific)
- No references, generic prompt: "Improve Code Quality" (generic)
- Perfect balance for reusability
3. Background Processing Race Conditions ⏱️
The Problem:
// User clicks Save
await analyzeTask(); // Takes 2-3 seconds
// User already started next task!
// System confused about which task to analyze
Attempted Solutions:
- Try 1: Block UI → terrible UX, users complained
- Try 2: Queue tasks → lost context when page closed
- Try 3: LocalStorage queue → hit size limits
Final Solution:
// Immediate return, queue in IndexedDB
async finalizeTask() {
const taskSnapshot = cloneTaskData();
this.storage.savePendingRule(taskSnapshot);
// Non-blocking background processing
setTimeout(() => this.processInBackground(), 100);
return { success: true }; // User continues immediately
}
Added retry mechanism that processes pending tasks on next app load.
4. Chrome Built-in AI API Limitations 🤖
Challenge 1: Token Limits
- Gemini Nano has context limits
- Our initial prompts were too long (2000+ tokens)
Solution:
- Truncate content samples to 500 chars
- Smart truncation at sentence boundaries
- Summarize rather than repeat
Challenge 2: Inconsistent JSON Parsing
- AI sometimes wrapped JSON in markdown: ```json {...} ```
- Sometimes added explanatory text before/after
- Sometimes invalid JSON syntax
Solution:
parseJSONResponse(response) {
// Try 1: Direct parse
try { return JSON.parse(response); } catch {}
// Try 2: Extract from markdown
const match = response.match(/```(?:json)?\s*(\{[\s\S]*\})\s*```/);
if (match) {
try { return JSON.parse(match[1]); } catch {}
}
// Try 3: Find first valid JSON object
const jsonMatch = response.match(/\{[\s\S]*\}/);
if (jsonMatch) {
try { return JSON.parse(jsonMatch[0]); } catch {}
}
return null; // Graceful failure
}
Challenge 3: Embedding API Availability
- Not available on all Chrome versions
- Had to build fallback embedding system
Solution:
async generateEmbedding(text) {
if (this.embeddingSession) {
return await this.embeddingSession.embed(text);
}
// Fallback: Simple hash-based embedding
return this.createSimpleEmbedding(text);
}
5. IndexedDB Transaction Hell 💾
The Problem: IndexedDB is notoriously difficult:
- Async transaction management
- Complex error handling
- Version migration headaches
- Cross-store queries impossible
Pain Points:
// Need to get prompt, then embedding, then references
// Each requires separate transaction
// Can't use async/await cleanly
// Callback hell ensued
Solution: Built clean abstraction layer:
class StorageManager {
// Promisify everything
async savePrompt(data) {
return new Promise((resolve, reject) => {
const transaction = this.db.transaction(['prompts'], 'readwrite');
const request = transaction.objectStore('prompts').add(data);
request.onsuccess = () => resolve(request.result);
request.onerror = () => reject(request.error);
});
}
// Reusable patterns for common operations
async getWithIndex(storeName, indexName, value) { ... }
}
6. Content Type Detection Accuracy 📄
The Problem: Users paste diverse content:
- JavaScript that looks like JSON
- HTML with embedded JavaScript
- Markdown with code blocks
- CSV that's actually tab-separated
Wrong detection → wrong analysis → poor matching
Solution: Multi-stage detection:
detectContentType(content) {
// Stage 1: Try parsing as structured data
if (validJSON(content)) return 'json';
if (validHTML(content)) return 'html';
// Stage 2: Pattern matching
if (/function|const|let|=>/.test(content)) return 'javascript';
if (/def |import |class /.test(content)) return 'python';
// Stage 3: Heuristics
const lines = content.split('\n');
if (lines.every(l => l.includes(','))) return 'csv';
// Stage 4: Ask AI (for complex cases)
return await this.aiDetectType(content);
}
7. Debouncing vs. Responsiveness ⚡
The Problem:
- No debounce → API calls every keystroke (expensive, slow)
- Too much debounce → feels laggy
- Different users type at different speeds
Solution: Adaptive debouncing:
findSuggestionsDebounced(input, hint, callback) {
clearTimeout(this.debounceTimer);
// Shorter delay for substantial content
const delay = input.length > 200 ? 300 : 500;
this.debounceTimer = setTimeout(async () => {
const suggestions = await this.find(input, hint);
callback(suggestions);
}, delay);
}
Plus instant suggestions for paste events (no debounce needed).
Accomplishments that we're proud of
🎯 Technical Achievements
1. Solved the Semantic Matching Problem
- Achieved 85-95% accuracy for similar content (vs. initial 27%)
- Dual-embedding strategy now a reusable pattern for other AI apps
- Hybrid matching outperforms pure vector or keyword search
2. Zero-Latency User Experience
- Background learning architecture processes in <2s without blocking
- Users don't even know analysis is happening
- Retry mechanism ensures no data loss
3. Adaptive Intelligence
- First tool to dynamically adjust pattern specificity
- Learns from user's adjustment patterns automatically
- Gets smarter the more you use it
4. Production-Ready Code Quality
- 8 clean, testable classes with single responsibilities
- Comprehensive error handling with graceful fallbacks
- Detailed JSDoc documentation throughout
- Modern ES6+ patterns (async/await, optional chaining, nullish coalescing)
🚀 Product Achievements
1. Actually Solves a Real Problem
- Saves 2-5 hours per week for power users
- Turns 5-minute tasks into 5-second tasks
- Works for diverse use cases (code, content, data)
2. Privacy-First by Design
- 100% local processing (no data ever leaves user's machine)
- No servers, no accounts, no tracking
- IndexedDB storage gives users full control
3. Seamless Chrome Integration
- Uses Built-in AI (no API keys, no setup)
- Works offline after initial use
- Fast local inference (<1s for most tasks)
💡 Innovation Achievements
1. Novel Dual-Embedding Approach We're the first to separate content embeddings from task embeddings for prompt reuse. This insight could benefit the entire AI tooling ecosystem.
2. Post-Task Learning Paradigm Background analysis after task completion is counter-intuitive but brilliant:
- Zero UX latency
- Higher quality patterns (only successful tasks saved)
- Better architecture (clean separation of concerns)
3. Adaptive Specificity Algorithm Our system automatically determines optimal pattern genericity:
- With references → specific patterns
- With adjustments → refined patterns
- Generic prompts → generic patterns
This makes the system truly intelligent, not just a dumb pattern matcher.
🎓 Learning Achievements
1. Mastered Chrome Built-in AI APIs
- Deep understanding of Gemini Nano capabilities
- Learned prompt engineering for consistency
- Built robust fallback systems for API limitations
2. Conquered IndexedDB Complexity
- Built clean abstraction over messy IndexedDB API
- Efficient schema design with proper indexes
- Transaction management without callback hell
3. Real-World AI Application
- Moved beyond toy demos to production-ready tool
- Handled edge cases and error scenarios
- Built for actual daily use, not just demonstrations
🏆 Personal Achievements
1. Shipped a Complete Product
- From idea to working extension in 4 weeks
- All features implemented and tested
- Ready for Chrome Web Store publication
2. Solved Hard Problems
- Semantic matching accuracy
- Background processing architecture
- Adaptive intelligence system
- Each required deep thinking and iteration
3. Created Actual Value
- Already using it daily for my own work
- Saves me personally 3+ hours per week
- Friends testing it report similar results
📊 Measurable Wins
Performance:
- ⚡ <500ms suggestion generation (with debouncing)
- 🎯 85-95% match accuracy for similar tasks
- 💾 <5MB storage for 100 patterns
- 🚀 Zero perceived latency for users
Code Quality:
- ✅ 2,500+ lines of clean, documented code
- ✅ 8 modular classes, each <500 lines
- ✅ Comprehensive error handling throughout
- ✅ Zero external dependencies (besides Chrome APIs)
User Experience:
- 🎨 One-click task execution after first use
- 📊 70%+ confidence threshold ensures quality suggestions
- 🔄 Learns from every successful task automatically
- 💬 Clear visual feedback at every step
What we learned
🧠 Technical Learnings
1. Embeddings Are Not Magic—You Must Embed the Right Things
Before: "Let's embed everything and AI will figure it out!" Reality: Embedding prompt metadata and comparing to input content gave 27% similarity for identical tasks.
Key Insight: Semantic search is about matching comparable semantic spaces. Input embeddings should match input. Task embeddings should match tasks. Mixing them is like comparing distances in meters to temperatures in Celsius—mathematically possible but semantically meaningless.
Takeaway: Always ask: "What am I trying to match?" Then embed exactly that.
2. AI Responses Need Aggressive Parsing
What We Expected:
{"category": "code_refactor", "title": "..."}
What We Got:
Here's the analysis you requested:
```json
{"category": "code_refactor", "title": "..."}
Hope this helps!
**Learning:** NEVER trust AI to return clean JSON. Build robust parsers:
- Try direct JSON.parse()
- Extract from markdown code blocks
- Find first/last curly braces
- Have fallback strategies
- Always gracefully handle failure
**Takeaway:** Treat AI responses like user input—sanitize everything.
**3. Background Processing Changes Everything**
**Initial Approach:** Block user, show loading spinner, complete analysis, then continue
**Problem:** 2-3 second wait felt like eternity
**Breakthrough:** Process AFTER user continues working
**Result:** Users perceive zero latency even though analysis takes same time
**Key Insight:** In UX, *perception* matters more than reality. A 2-second delay that happens in the background feels instant. The same delay blocking the UI feels like forever.
**Takeaway:** Never block the critical path. Queue background work aggressively.
**4. Specificity Is Context-Dependent**
**Failed Approach:** Always be generic for maximum reusability
**Problem:** "Refactor Code" matched everything poorly
**Failed Approach:** Always be specific for accuracy
**Problem:** "Convert if-else on line 5" never matched again
**Winning Approach:** Adaptive specificity based on signals:
- Has references? → Specific (user showed exactly what they want)
- Has adjustments? → More specific (user refined requirements)
- Generic prompt? → Stay generic (user wants flexibility)
**Takeaway:** One-size-fits-all doesn't work. Build adaptive systems.
**5. Local AI Has Real Limitations**
**Reality Check:**
- Token limits force content truncation
- Response consistency varies
- Embedding API not always available
- Inference speed depends on hardware
**Learning:** Always have fallbacks:
- Truncate smartly (sentence boundaries, not mid-word)
- Parse responses defensively
- Build simple embedding fallback (hash-based)
- Optimize prompts for token efficiency
**Takeaway:** Chrome Built-in AI is powerful but not magic. Design for its constraints.
### 🎨 **UX/Design Learnings**
**1. Auto-Fill Is Too Aggressive**
**Initial Design:** When high confidence match found, auto-fill prompt
**User Feedback:** "Wait, why did my text change? I wasn't ready!"
**Better Design:** Show suggestion card, user clicks to accept
**Result:** Users feel in control, adoption increased
**Takeaway:** Suggestions > Automation. Users want control.
**2. Confidence Scores Build Trust**
**Without Scores:** "Similar tasks found (3)"
**User Thought:** "Are these actually similar? Should I trust this?"
**With Scores:** "Similar tasks found (3) - 92% match"
**User Thought:** "Oh, 92%! That's probably right."
**Takeaway:** Transparency builds trust. Show your confidence.
**3. Non-Blocking UI Is Critical**
**Bad:** Modal dialog blocking entire screen
**Better:** Sidebar panel
**Best:** Floating suggestion card in non-critical screen area
**Learning:** Users need to reference their work while reviewing suggestions. Don't block the content area.
**4. Progressive Disclosure Wins**
**Initial Design:** Show all pattern details upfront (title, subtitle, prompt, references, keywords...)
**Problem:** Overwhelming, hard to scan
**Better Design:**
- Card: Title + confidence + icon
- Hover: Subtitle appears
- Click: Full details in expandable section
**Takeaway:** Start minimal, reveal on demand.
### 🏗️ **Architecture Learnings**
**1. Separation of Concerns Actually Matters**
**Early Code:** One giant class doing everything
**Problem:** Impossible to test, debug, or modify
**Refactor:** 8 focused classes:
- AIService (AI communication)
- StorageManager (data persistence)
- LearningEngine (pattern analysis)
- TaskExecutor (task execution)
- SuggestionManager (matching)
- ContentParser (input handling)
- ContentAnalyzer (metadata generation)
- ConfigManager (preferences)
**Result:** Each class <500 lines, single responsibility, easily testable
**Takeaway:** SOLID principles aren't academic—they make code actually maintainable.
**2. Async/Await Everywhere**
**Old Code:** Callback hell with IndexedDB
**New Code:** Clean async/await with Promises
**Pattern:**
```javascript
// Wrap IndexedDB callbacks in Promises
async saveData(data) {
return new Promise((resolve, reject) => {
const request = store.add(data);
request.onsuccess = () => resolve(request.result);
request.onerror = () => reject(request.error);
});
}
Takeaway: Invest time in proper abstractions. Pays off immediately.
3. Error Handling Can't Be Afterthought
Scenarios That WILL Happen:
- IndexedDB quota exceeded
- AI API temporarily unavailable
- Network drops during inference
- User closes tab mid-processing
- Malformed AI responses
- Embedding generation fails
Learning: Every async operation needs:
- try/catch wrapper
- Fallback strategy
- User-friendly error message
- Logging for debugging
- Retry mechanism where appropriate
Takeaway: Happy path is 10% of the code. Error handling is 90%.
📊 Product/Market Learnings
1. "Repetitive Tasks" Is Broader Than Expected
Initial Target: Developers refactoring code Reality: Use cases appeared in:
- Content writers reformatting articles
- Data analysts cleaning datasets
- Students organizing notes
- Researchers extracting information
- Marketers adapting copy
Learning: The problem is universal. Anyone using AI for work has repetitive tasks.
Takeaway: Don't over-narrow your audience too early.
2. Privacy Matters More Than We Thought
Assumption: "It's just prompts, users won't care" Reality: Users REALLY care that data stays local
Quotes from testers:
- "Wait, this doesn't send anything to your server? That's amazing!"
- "Finally an AI tool that respects privacy"
- "Local-only is a huge selling point"
Takeaway: Privacy-first isn't just ethical—it's a competitive advantage.
3. "Time Saved" Is the Killer Metric
Metrics We Tracked:
- Number of patterns saved ❌ (vanity metric)
- Match accuracy ❌ (technical metric)
- Time saved per task ✅ (VALUE metric)
Result: "Saves 2-5 hours/week" resonates far more than "85% accuracy"
Takeaway: Measure what users actually care about—their time.
🤔 Philosophical Learnings
1. AI Tools Should Amplify, Not Replace
Bad Framing: "Let AI do it for you" Better Framing: "Teach AI your patterns, then reuse them"
Learning: Users want to stay in control. They want tools that amplify their expertise, not replace their judgment.
2. The Best AI Is Invisible AI
Obvious AI: "Analyzing with AI... Generating embeddings... Matching patterns..." Invisible AI: Just works
Learning: Users don't care about embeddings or semantic search. They care about getting work done faster. Hide the complexity.
3. Local-First Is the Future
Centralized AI: Send data → wait for server → receive response Local AI: Process instantly, work offline, keep privacy
Chrome Built-in AI proves: Modern devices are powerful enough for serious AI work. We don't need cloud for everything.
Takeaway: Local-first isn't just privacy—it's better UX.
🎯 Biggest Lesson
Ship, Learn, Iterate.
Version 1 had wrong embedding strategy. Version 2 had too-generic patterns. Version 3 blocked the UI. Version 4 worked.
We didn't get it right the first time. We got it right by:
- Building something
- Testing with real use cases
- Finding what broke
- Fixing it
- Repeat
The meta-lesson: Perfect planning doesn't beat rapid iteration. Build, test, learn, improve.
What's next for Transformly - Your personal AI shortcut for repetitive work
🚀 Immediate Roadmap (Next 3 Months)
Phase 1: Polish & Launch
- 🎨 Complete UI redesign with modern glassmorphism
- 📱 Add keyboard shortcuts for power users
- 🔔 Implement subtle toast notifications
- 🐛 Bug fixes from beta testing feedback
- 📦 Publish to Chrome Web Store
- 📊 Set up privacy-preserving analytics (local only)
Phase 2: Enhanced Matching
- 🎯 Add fuzzy matching for typo tolerance
- 📈 Implement learning rate decay (old patterns fade)
- 🔄 Add pattern merging (combine similar patterns automatically)
- 📊 Usage-based ranking (frequently used patterns surface first)
- 🏷️ Auto-tagging system for better organization
Phase 3: Workflow Improvements
- 📁 Folder/collection organization for patterns
- 🔍 Full-text search across all saved patterns
- 📤 Export/import patterns (backup & sharing)
- 📋 Batch processing (apply pattern to multiple files at once)
- ⭐ Favorites/pinning for most-used patterns
🎓 Medium-Term Vision (6-12 Months)
Multi-Step Workflows
Pattern 1: Extract data from HTML
↓
Pattern 2: Transform to JSON
↓
Pattern 3: Generate TypeScript interfaces
- Chain patterns into workflows
- Save entire pipelines as reusable templates
- Visual workflow builder with drag-and-drop
- Conditional branching (if/else logic in workflows)
Smart Pattern Suggestions
- "Users who saved this pattern also saved..."
- Suggest related patterns based on context
- Recommend workflow combinations
- Learn from usage patterns to suggest optimizations
Collaborative Features (Optional, Opt-In)
- Share patterns with team (encrypted, peer-to-peer)
- Team libraries with role-based access
- Pattern marketplace (community templates)
- Import patterns from URLs
Built With
- css3
- firebase-ai-logic
- javascript
- web-components

Log in or sign up for Devpost to join the conversation.