-
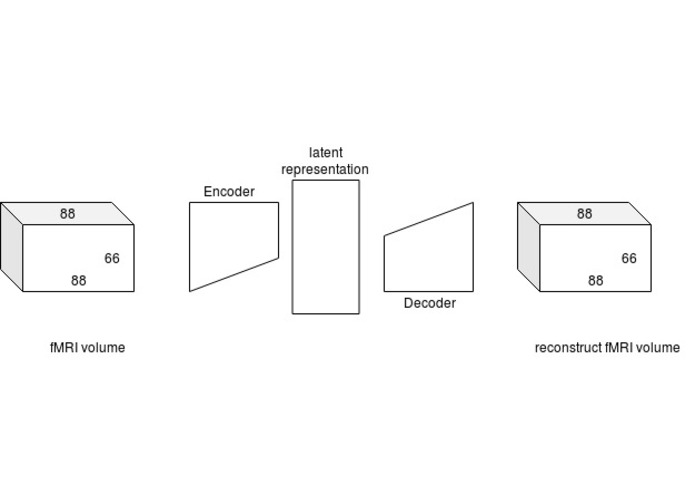
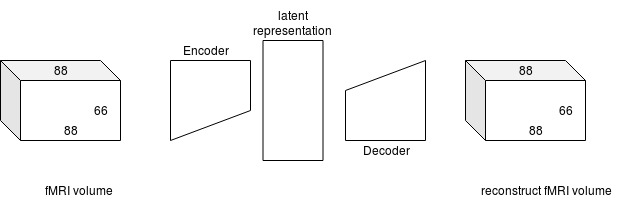
Simple deep convolutional autoencoder
-
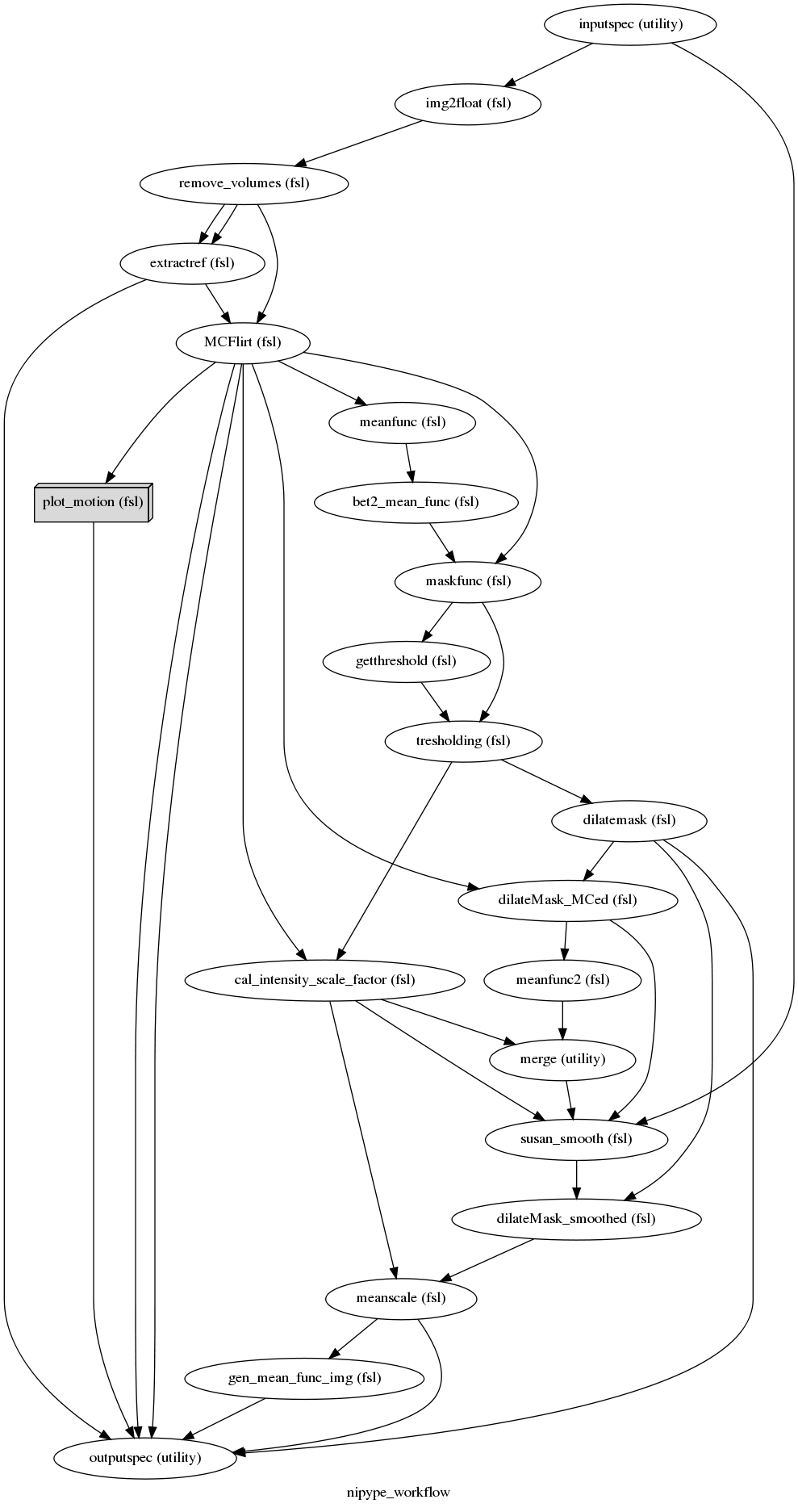
Preprocessing fMRI data
-
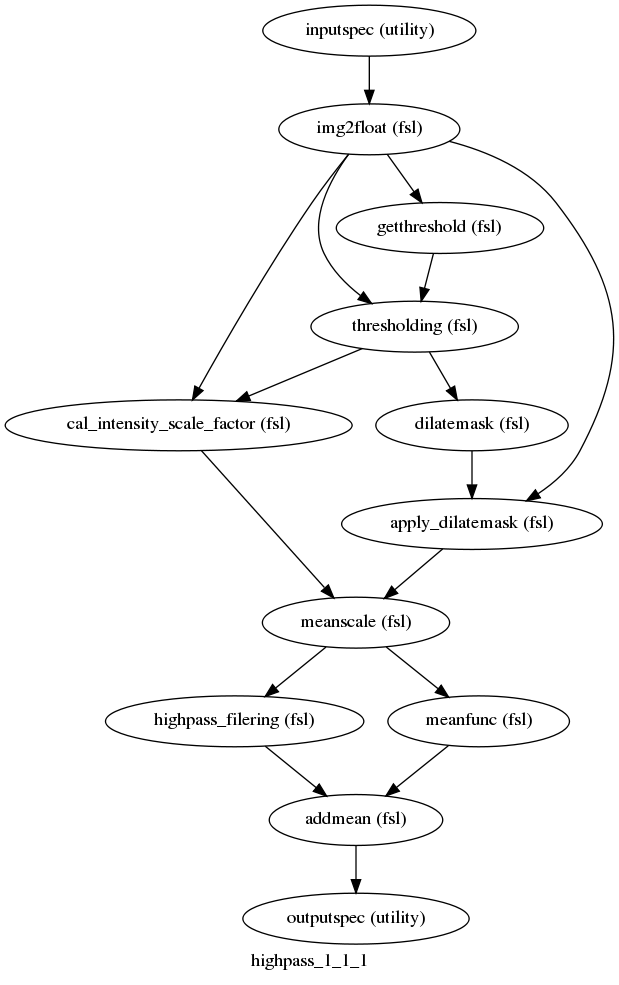
High pass filtering of fMRI data
-
Preprocessing structural MRI data
-
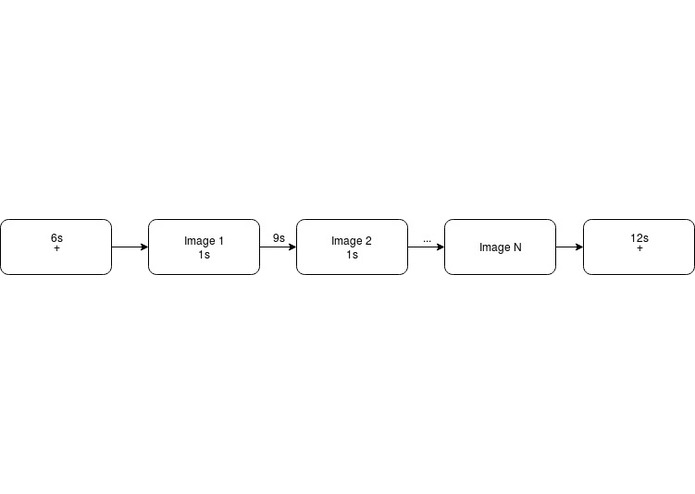
BOLD5000 experiment protocol

Inspiration
Even when participants view images of living and non-living objects that they are not able to discriminate behaviorally, we are able to classify the correct categories based on the functional magnetic resonance imaging blood-oxygen-level-dependent (fMRI BOLD) responses above chance level. In short, the BOLD response provides more information than behavior in classifying the categories. While significant, the area under the receiver operating characteristic curve (ROC AUC) is low, so we sought to utilize transfer learning (Yosinski et al., 2014) to improve the performance. Yosinski et al.’s work was based on supervised machine learning, but a system trained with unsupervised machine learning is more generalizable (Bengio, 2012). Thus we trained an autoencoder which is an unsupervised machine learning algorithm that consists of two parts: an encoder and a decoder. An encoder extracts “features” that compresses the input, and then the decoder reconstructs the input based on the extracted “features”.
What it does
Before testing the generalizability of an autoencoder (i.e., the extent to which it can transfer learned knowledge from the BOLD5000 dataset (Chang et al., 2019) to a new dataset), we first wanted to learn how to train a deep convolutional autoencoder. For this project, we preprocessed the BOLD data and trained a deep convolutional autoencoder.
How we built it
For detailed steps on how we preprocessed the BOLD data and trained the autoencoder, please refer to our GitHub repository.
Challenges we ran into
Familiarizing ourselves with Pytorch workflow
Designing the architecture of the autoencoder
Determining which loss function to use (we tried all of the suitable ones in the Pytorch documentation)
Autoencoders are difficult to converge (i.e., the loss is not low enough)
Because it’s a deep network, it is hard to know which regularization to apply to the weights and activations
What we learned
Pytorch workflow
How to use transfer learning to make an autoencoder
How to train an autoencoder end-to-end
Accomplishments that we're proud of
We are pretty proud of the repository’s clear steps and explanations on how we preprocessed the BOLD data and trained the autoencoder. We believe that this project has deepened our understanding of autoencoders and the interaction of BOLD with the brain's cognitive processes, which will aid in our ultimate goal of using variational autoencoders.
What's next for "Training an autoencoder on visual images and fMRI data"
Train a variational autoencoder (see also: Checklist section on our GitHub repository)
Train a variational autoencoder with the data
Train a convolutional neural network using the pre-trained simple autoencoder with the BOLD data and images
Examine the generalizability of the simple/variational autoencoder to a new fMRI dataset, using the autoencoder as a "feature extractor"
References
Yosinski, J., Clune, J., Bengio, Y., & Lipson, H. (2014). How transferable are features in deep neural networks? In Advances in neural information processing systems (pp. 3320-3328).
Bengio, Y. (2012, June). Deep learning of representations for unsupervised and transfer learning. In Proceedings of ICML workshop on unsupervised and transfer learning (pp. 17-36).
Chang, N., Pyles, J. A., Marcus, A., Gupta, A., Tarr, M. J., & Aminoff, E. M. (2019). BOLD5000, a public fMRI dataset while viewing 5000 visual images. Scientific data, 6(1), 49.

Log in or sign up for Devpost to join the conversation.