-
-
Transcribio logo
-
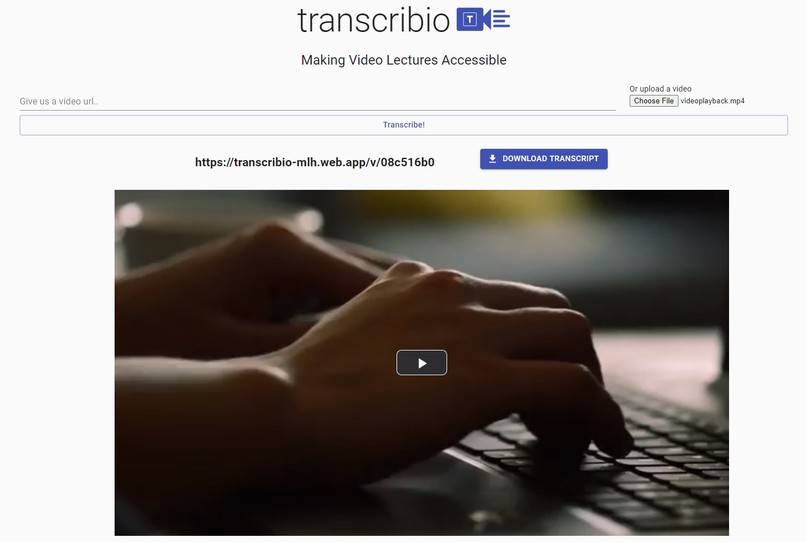
Video player, download transcript, sharable permalink
-
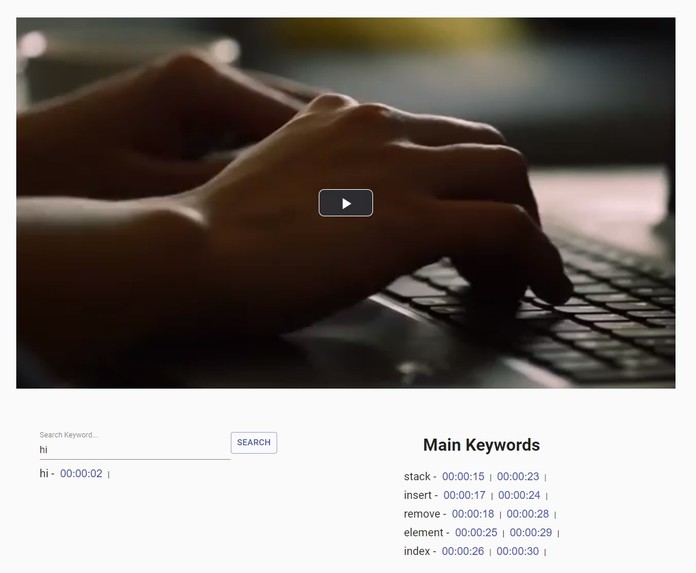
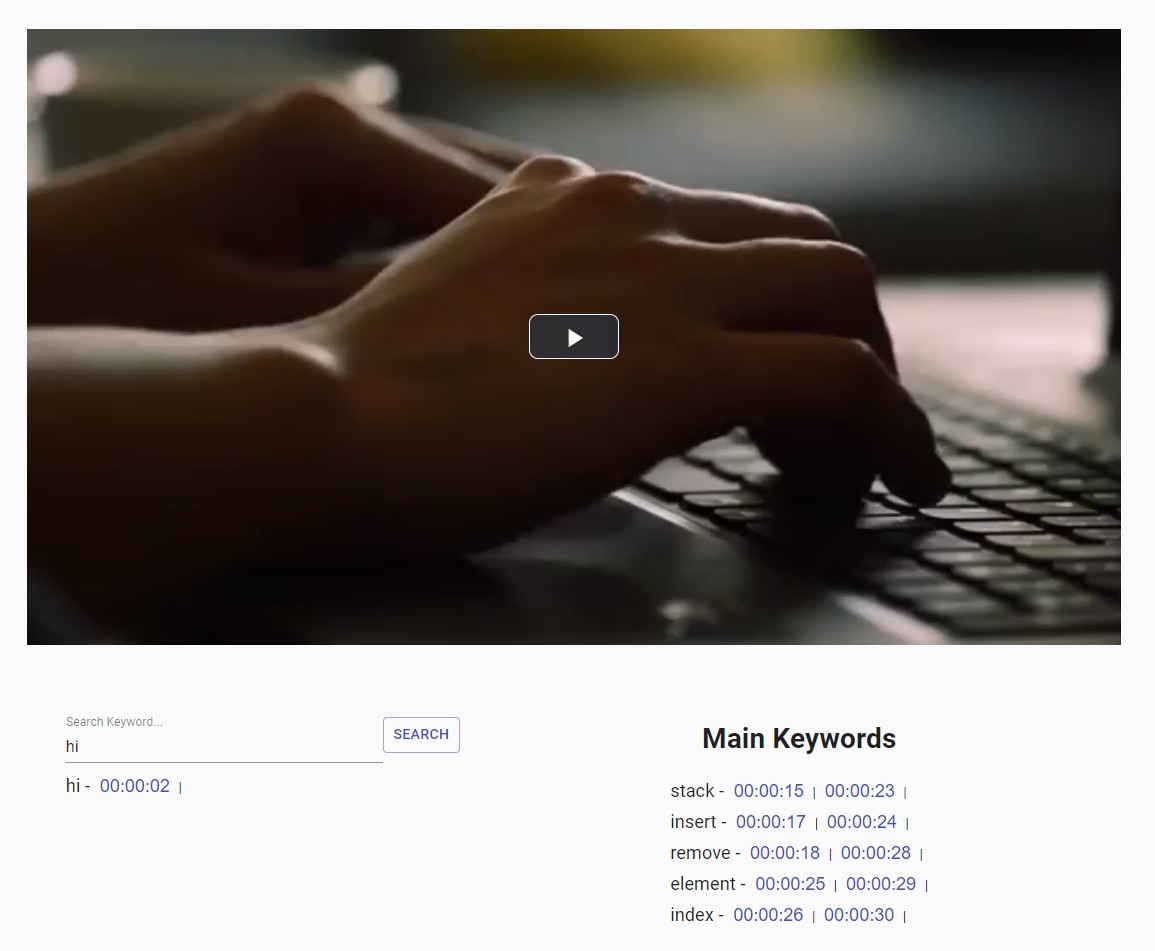
Keyword search, main keywords

Inspiration
The sudden advent of remote learning due to the pandemic has had some drastic effects on the quality of education. Video lectures and podcasts have become the predominant methods of teaching 📽, but this medium of education doesn’t cater to different learning styles and accessibility of students. We wish to empower students and educators by making video lectures more accessible, more convenient, and ultimately create a better learning experience during the virtual environment 🎓.
Students find it tiresome to go through long videos and podcasts 😴. They are not always interested in the whole content for revision and simply want to explore a particular concept in that long video 🔎. However, finding the particular timestamp where that particular concept was taught becomes pretty difficult, especially when most lectures are 1 hour long or more. This proves a challenge for students when they want to review their course material, resulting in reduced individual productivity and overall course performance.
What it does
Transcribio generates a full transcript for the video and offers a multitude of features related to the transcription that makes video lectures more interactive and accessible. It allows educators and students to generate transcriptions and keyword timestamp links for their video lectures and share the results (using the provided permalink) with their class or colleagues for a more convenient and accessible experience.
Transcribio has, even more, to offer for students 🎉. They can search for a particular keyword and jump to that timestamp in the video instead of skipping through the video to look for the part they wish to revisit manually.
How we built it
We developed our frontend using React and connected it to a containerized Flask backend. Our backend has various endpoints that do all the heavy lifting such as processing the video, extracting the audio, converting the audio to text using Google Cloud Speech To Text, and then finding the relevant keywords using Natural Language Processing. The relevant keywords are mapped with their corresponding timestamps in the video and presented to the user for easy navigation. All our processed results are stored in a database against the uploaded file hashes, so we can provide instant results for a video that has been processed before in the code.
Challenges we ran into
A couple of speech to text solutions did not provide us with the specific timestamps for each word in the video. None of our team members were familiar with Natural Language Processing, but we kept researching and experimenting. Ultimately we were able to find the pieces of the big puzzle and solve the problem that we thought of.
We faced blockers with the Google Cloud credit limitations for the Speech to Text API free tier, so we had to look for a better solution to process the uploaded videos in a more efficient way. We implemented hashing of the uploaded content to avoid redundant processing, save on our free-tier quota, storage, and also provide a faster average response time.
Accomplishments that we're proud of
💡 Took the project from an idea stage to a working prototype stage
👍 Maintained best-practices for our Github repository and code
💬 Good team communication
💪 Avoided redundant processing through hashing of the uploaded content, saved on our free-tier quota, storage, and also provided a faster average response time
What we learned
- Containerizing our code
- Building APIs with Flask
- Project management with Github
- Google Cloud Speech to Text Integration
- NLP (different techniques for keyword extraction)
Open Source Projects that we used
react.js- our frontend Javascript frameworkaxios- that made our API callsnotistack- that serves our feisty snackbarsflask- our backend Python frameworkdocker- our friend with containersgit- of course!- and many more that help maintain these projects...
What's next for Transcribio
- Captioning/subtitles
- YouTube support coming soon!
- Supplemental video recommendations based on the lecture topic
Built by HackSparrows 🐤 (Pod 1.1.2)
- Ajwad Shaikh
- Chau Vu
- Rajat Kumar Gupta






Log in or sign up for Devpost to join the conversation.