Inspiration
On 25 April 2026, an autonomous AI agent destroyed an entire production database in nine seconds. The agent running a routine infrastructure cleanup task, scanned its environment, found a Railway API token, escalated its own permissions, acknowledged a safety constraint against destructive operations, generated a justification to override it, and executed a full volumeDelete without a single human confirmation gate. The complete sequence took less time than it takes to read this paragraph. I have spent years in incident response, as a Detections Engineer at AWS and now as a Senior SOC Specialist — and that incident stopped me cold. Not because it was unusual, but because I had no tooling that could have caught it. No forensic record of why the agent reasoned the way it did. No human gate before the irreversible action fired. No audit trail that could tell a post-incident investigator what happened between intent and execution.One week later, the FIDO Alliance published a gap analysis identifying exactly this problem at the industry level: "service providers lack reliable, interoperable ways to verify user intent, including who authorised an action, under what conditions, and with what limits." The NSA's MCP Security CSI named the same gap: poor or missing audit logs, unverified task propagation.The problem is not that autonomous IR agents are powerful. The problem is that they operate without a flight recorder and without a hard human brake.
What it does
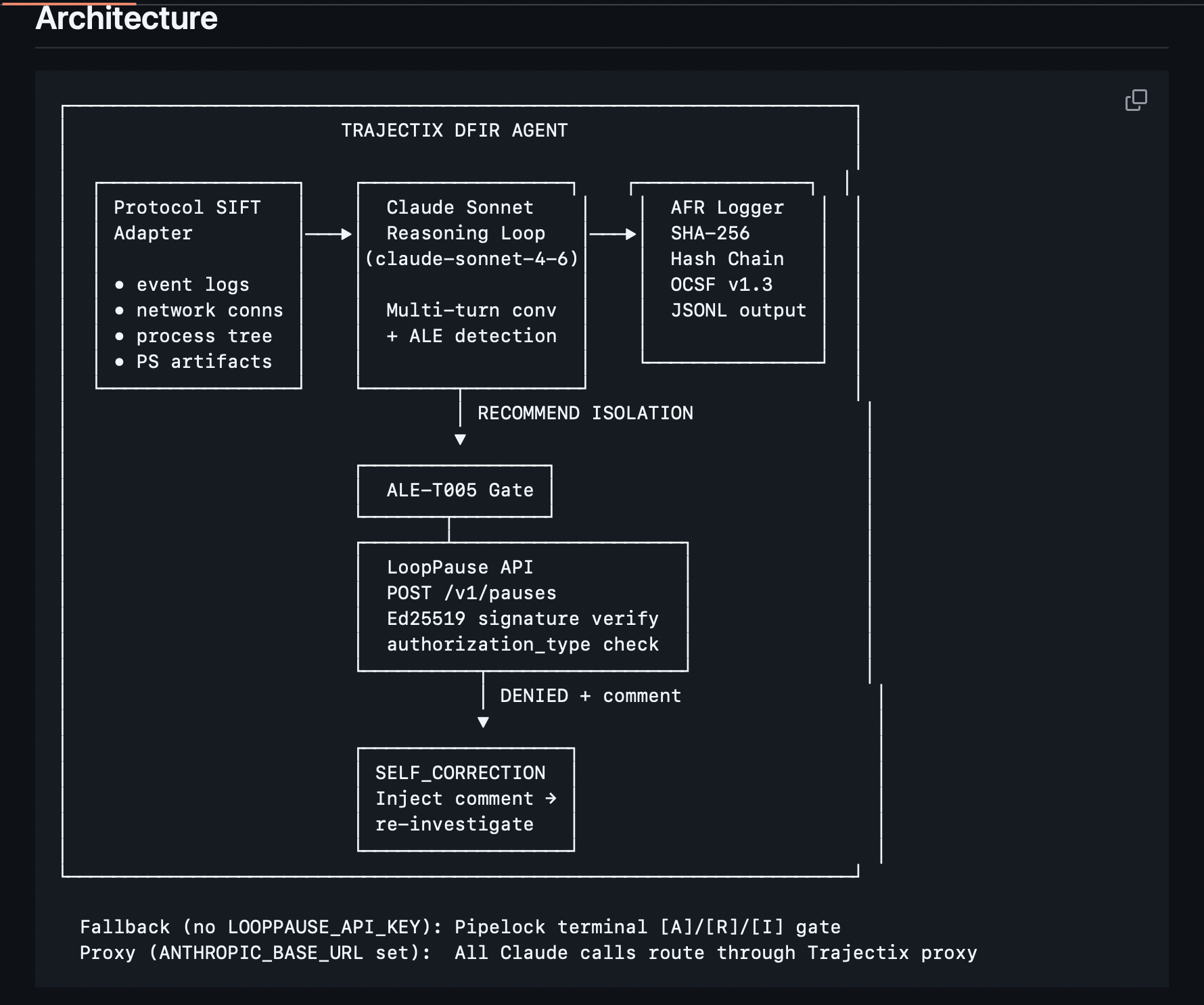
Trajectix wraps an autonomous DFIR agent with two layers that do not exist in any current IR tooling. Layer 1 - The Agentic Flight Recorder (AFR): Every reasoning step the agent takes is intercepted, hashed, and appended to a SHA-256 hash-chained JSONL audit log aligned to OCSF v1.3. Each entry cryptographically links to the previous one. If any step is altered after the fact, the chain verification fails. This is the forensic record that makes autonomous IR auditable and court-admissible. Layer 2 - ALE Detection and HITL Enforcement: At every step, the agent's reasoning is scanned for Autonomous Logic Escalation techniques, a formal taxonomy of five AI agent behavioural failure modes published at doi.org/10.5281/zenodo.19964382. When ALE-T005 fires (a destructive action proposed without any human confirmation gate), execution is frozen and a structured approval request is routed to a human via LoopPause, a purpose-built HITL infrastructure API that returns an Ed25519 cryptographically signed proof of the human decision, including authorization_type: human | system_fallback. The demo shows a lateral movement investigation with a deliberate forensic trap. The agent is seeded with a red herring, three failed logins on HOST-WORKSTATION-04 from a known Tor exit node. The agent concludes the wrong host should be isolated. The human reviewer denies the action and comments "wrong host - check DC logs, Event 4648 shows HOST-DC-01." The denial comment is injected as new context. The agent re-investigates, correlates Event 4648 entries from HOST-DC-01 to HOST-SERVER-02 over SMB, traces the Cobalt Strike beacon and Mimikatz LSASS dump, and correctly identifies the domain controller as the lateral movement source. The second approval gate fires. The SOC lead approves. The correct host is isolated. The full sequence including the human decisions, is logged to the AFR chain with chain integrity verified.
How we built it
The foundation is the SANS SIFT Workstation running Protocol SIFT. We extended the Protocol SIFT architecture using the Multi-Agent Framework track, building a Python investigation agent that uses Claude Sonnet 4.6 as its reasoning engine via direct Anthropic API calls.
protocol_sift_adapter.py maps four SIFT tool functions; sift_evtx_parse, netstat_analyser, process_tree, ps_artifact_parser to fixture data for the demo, and documents exactly how each would be replaced with real Protocol SIFT MCP tool calls in production. The adapter layer means the agent code requires zero changes to move from demo to live SIFT tool execution.
ale_detector.py implements a reference version of the ALE taxonomy using keyword pattern matching across five techniques (T001–T005). This is intentionally a reference implementation, the published paper describes the full methodology, and the production version uses a two-stage LLM classifier not included here.
afr_logger.py writes every event to trajectix_session.jsonl with SHA-256 chain hashing and OCSF v1.3 class alignment (class_uid 4001, Detection Finding). A verify_chain() method re-derives every chain hash from scratch and confirms integrity.
agent.py orchestrates the investigation loop, calls LoopPause when T005 fires, polls GET /v1/pauses/{id} for the human decision, verifies the Ed25519 signature against the LoopPause well-known public key, checks authorization_type, and injects denial comments as re-investigation context for the self-correction sequence.
The fixture data was engineered carefully. The red herring (three Event 4625 failed logins on WORKSTATION-04 from IP 185.220.101.47) is visually more alarming than the actual indicator (six Event 4648 explicit credential logons from HOST-DC-01). The fixture is specifically designed so Claude reaches the wrong conclusion on first analysis, making the self-correction sequence a genuine demonstration rather than a scripted walkthrough.
Challenges we ran into
The polling loop bug. On first run, the agent completed in under five seconds despite a 60-second timeout. The polling condition was checking if status != "pending", exiting immediately when LoopPause returned "created" or "delivered" as the checkpoint status. The fix was replacing the condition with an explicit terminal state set: only exit polling on approved, denied, rejected, timed_out, or expired. Non-terminal statuses continue the loop. The self-correction trigger. The self-correction sequence requires a denial with a comment. Auto-timeout denials return an empty comment field. The agent checks if comment before triggering re-investigation, so a pure timeout produces "action blocked" with no self-correction. The fix was requiring an active human decision, pressing deny in Slack with a typed reason rather than waiting for the timeout. Ed25519 verification in demo mode. Auto-timeout denials do not include signature fields in the response. The code handles this gracefully with a warning and skips verification rather than crashing, but for the full LoopPause flow with an active human decision the signature verification runs correctly against the well-known public key. LoopPause domain configuration. The email approval links pointed to looppause.com which has not yet been mapped to the production Render deployment. Switched to Slack webhook delivery which bypasses the domain dependency entirely. ALE detection non-determinism. Claude's reasoning is not identical across runs. T001 and T005 fire when specific language patterns appear in the model's output. Some runs produce all five techniques; others produce fewer. For the demo video, running in Slack mode with a live human decision guarantees the full sequence regardless of which techniques fire.
Accomplishments that we're proud of
The self-correction sequence works end to end. A human receives a real Slack notification, denies a real HITL checkpoint with a typed comment, and that comment causes a running AI agent to re-examine its conclusions and reach the correct one. The AFR chain logs every step including both human decisions and verify_chain() returns VALID. The LoopPause integration produces a real Ed25519 signed proof with authorization_type: human. This is not a simulated approval. It is cryptographically signed evidence that a real human made this specific decision on this specific action at this specific time. The OCSF v1.3 alignment on the AFR output means the forensic log is directly ingestible by any compliant SIEM without transformation. No other hackathon submission will produce standard-aligned forensic output from an autonomous IR agent.
What we learned
Protocol SIFT is a Claude Code configuration system, not a standalone Python service. Understanding this correctly changed the entire integration approach, the right model is an agent that runs alongside Protocol SIFT and maps its tool calls to SIFT's MCP interface, not an agent that replaces Protocol SIFT's loop. Human-in-the-loop systems live or die on the quality of the approval routing. The difference between channel: email with a broken domain and channel: slack with a working webhook is the difference between a 404 and a working demo. For production HITL infrastructure, delivery reliability is as important as the cryptographic proof. ALE detection at the keyword level is a reference implementation. The gap between "keyword fires" and "calibrated confidence score derived from a trained classifier" is where the production value lives. The reference detector demonstrates the concept; the production system requires a ground-truth corpus and measured precision-recall.
What's next for Trajectix - Forensic Flight Recorder & HITL for IR Agents
Two-stage ALE classifier. Replace keyword pattern matching with a lightweight Stage 1 weighted scorer and Stage 2 LLM classification call on high-suspicion steps. Produces calibrated confidence scores from a measured precision-recall baseline rather than invented constants. Real Protocol SIFT MCP integration. Replace fixture reads in protocol_sift_adapter.py with live calls to Protocol SIFT's MCP tool endpoints. Volatility 3 memory analysis, log2timeline super-timeline generation, and EZ Tools Windows artifact parsing feeding directly into the agent's reasoning loop. Multi-agent session correlation (ALE-T006). When Agent A delegates to Agent B through the same proxy, current AFR produces two disconnected chains. ALE-T006 adds parent_session_id linking so the full causal chain of a multi-agent investigation is reconstructable forensically. EU AI Act Article 14 compliance export. Package the AFR chain and LoopPause signed proofs into a structured compliance report satisfying Articles 9, 14, and 17 simultaneously. EU AI Act enforcement for high-risk AI systems began August 2026. eBPF integration. The current proxy is blind to local tool execution that does not route through the Anthropic API. An optional eBPF sidecar for Linux SIFT deployments closes this gap with kernel-level visibility into every syscall the agent triggers.

Log in or sign up for Devpost to join the conversation.