-
-
kv cache
-
model architecture
-

problem

Training-Free Interactive World Models
Real-time, voice-controlled video generation that you can steer while it is being generated, added to a model that was never trained to be interactive. No fine-tuning, no new data, no architectural surgery. Just inference engineering and a few ideas about where to inject control.
Team: Ray Kasichainula, Subha Vadlamannati, Bryan Dong, Gino Chiaranaipanich
Inspiration
Thinking Machines' "Interaction Models: A Scalable Approach to Human-AI Collaboration" got us thinking about interaction as a first-class property of a generative system rather than something you bolt on at the application layer. Most generative video today is fire-and-forget: you write a prompt, you wait, you get a clip, and if it is wrong you start over. Video is one of the slowest generative mediums there is, so that loop is painful.
We wanted the opposite. Say "dog running in a meadow," watch it generate, then say "winter background" and watch the meadow turn to snow without a cut, without restarting, and without the clip ever pausing. The catch is that the base model has zero notion of interaction. So the entire problem becomes: can you get interactive, real-time behavior out of a non-interactive model purely through inference, and can you do it fast enough that a person feels like they are steering a live world?
What it does
We take an off-the-shelf autoregressive video diffusion model with no interaction capability and turn it into a live, voice-driven world model. You speak, and the video responds mid-generation:
- "dog running in meadow" then "dog becomes a wolf in a winter background"
- "luxury car near beach" then "neon city replaces the beach"
- "beach scene" then "a storm erupts on the beach"
The transition is continuous. The scene morphs into the new prompt instead of hard-cutting to it. The whole thing runs faster than real time, so the video never stalls waiting for the next frame, and the path from your voice to a changed frame is about two thirds of a second.
Key numbers:
- 700ms to generate a chunk that contains 750ms of video, so generation outruns playback
- 0.69s end-to-end, voice to generation
- Training-free and data-free. We never touched the weights.
Why autoregressive, and why that matters for interaction
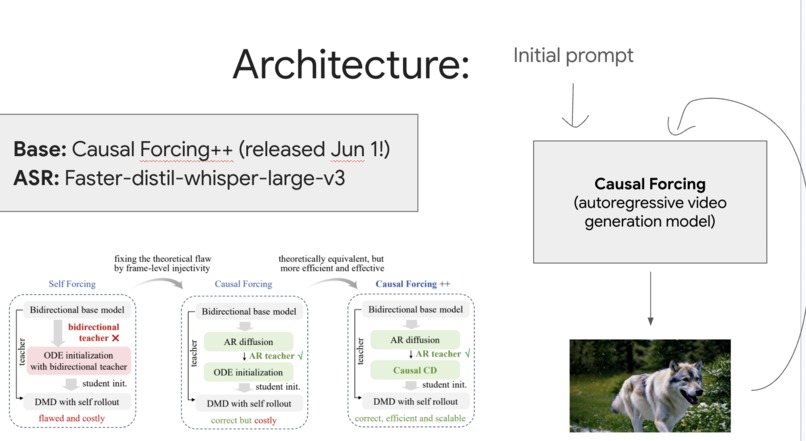
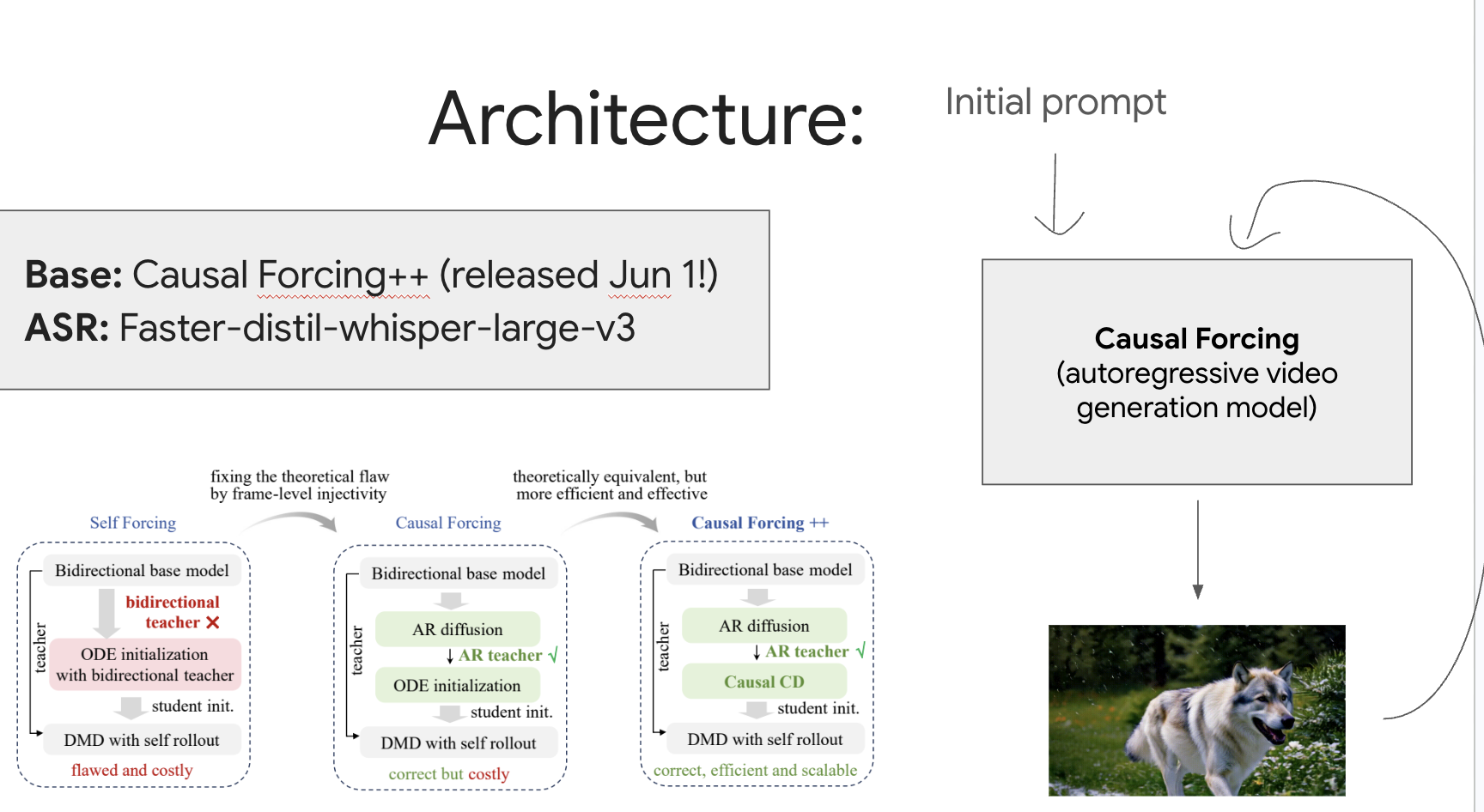
The base is Causal Forcing++ (an autoregressive video generation model, released June 1) with Faster-distil-whisper-large-v3 doing speech recognition.
The choice of an autoregressive base is the whole reason interaction is even possible here. An autoregressive model factorizes the joint distribution over the video as a product of conditionals, one per time step, rather than producing the clip in a single forward pass or a fixed number of global refinement iterations. That means at any moment there is a concrete, already-computed partial output (the frames so far, plus the KV cache that summarizes them) that the model is conditioning on to produce the next frames. Partial outputs are discrete and committed, so there is something real to grab onto and amend. A purely parallel or whole-sequence-refinement model has no clean intermediate state to intervene on, because every position is being co-decided at once and a local edit invalidates the rest. Causal forcing gives us a well-defined "now" to inject into, and any injection only affects the future frames, never the past ones, which is exactly what you want for a live edit.
How we built it
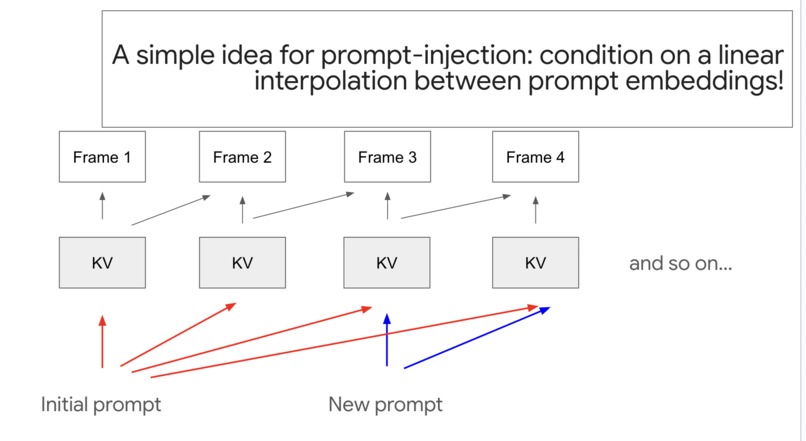
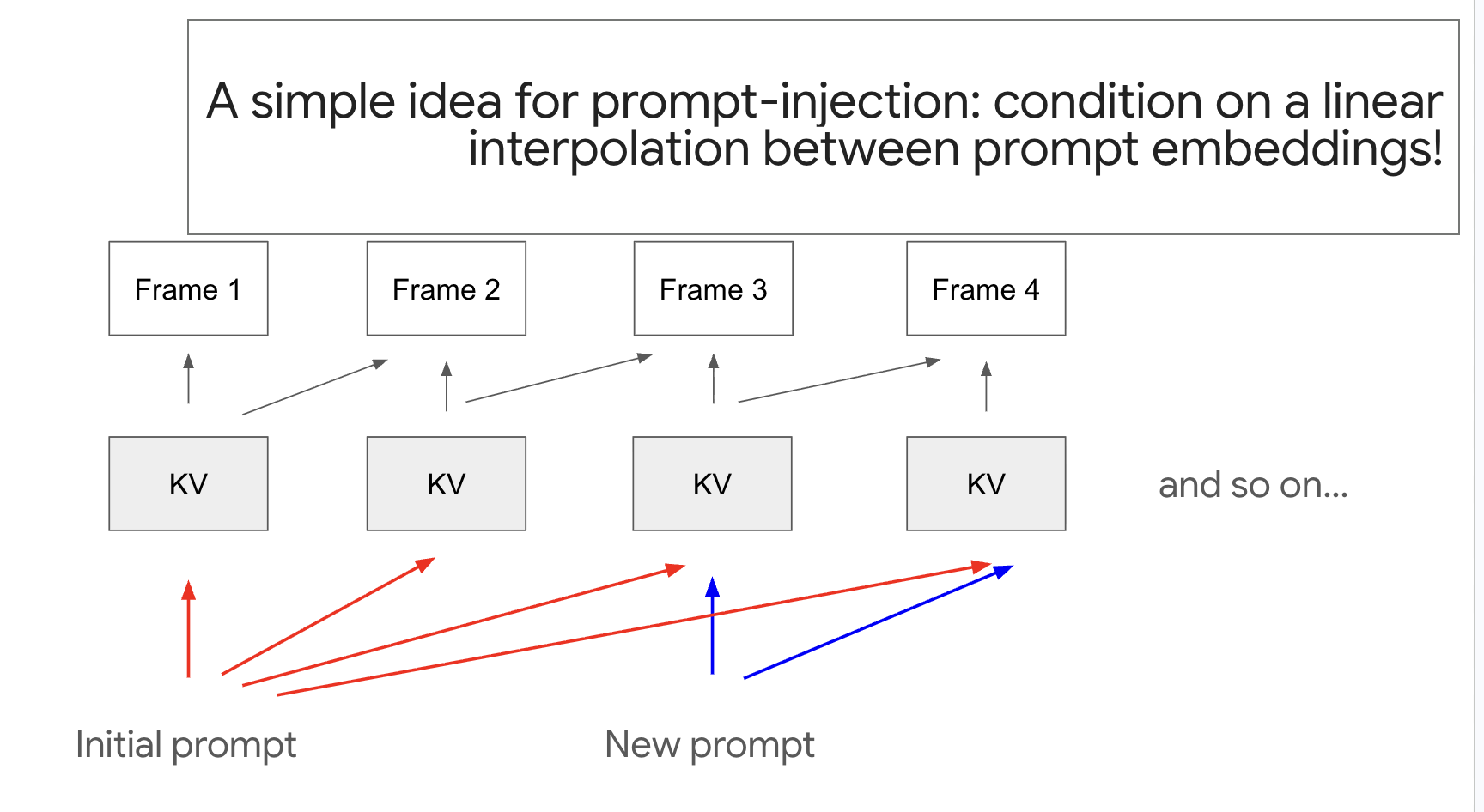
Prompt injection by embedding interpolation
The simplest idea that worked: when a new prompt arrives, do not hard-swap it in. Condition the next frames on a linear interpolation between the old and new prompt embeddings, and walk that interpolation across frames so the scene blends from one to the other. This is what buys the smooth morph instead of a jarring cut.
Getting this stable took a lot of iteration. We spent about nine hours on prompt-blending alone, trying and discarding:
- Naive hard-swapping of the prompt (jarring, breaks continuity)
- Backfilling the KV cache, which then had to play nicely with the sliding context window
- Sweeping coefficients alpha and beta to separately weight self-attention and cross-attention contributions
- Growing the attention window after the injection point to keep things stable through the transition
The KV-cache recomputation window approach did not pan out. Embedding interpolation plus careful attention weighting did.
The latency problem
Our first working version was unusable as a real-time system. With one GPU doing both denoising and VAE decode, producing 750ms of video took 976ms. That is slower than real time, so playback was choppy and the live feeling was gone. Closing that gap is where the inference work came in.
Pipeline parallelism across GPUs
The model emits video in chunks of 3 latent frames, which is 0.75s of video. Each chunk goes through two very different stages: diffusion generation (compute-heavy) and VAE decode (a different cost profile entirely). Running them back-to-back on one device wastes time.
We deliberately did not shard individual ops like the matmuls across GPUs. That tensor-parallel style needs fast inter-GPU communication at every single layer, which is a great trade for huge models but a terrible one for ours at around 1.3B parameters, where the communication would dominate. Instead we split by stage:
- GPU 0 runs DiT generation: raw noise through 5 denoising steps to a latent tensor, about 700ms
- GPU 1 runs VAE decode: latent tensor to RGB frames, about 276ms
The two are connected by a FIFO queue over NVLink. While GPU 0 generates chunk N, it ships chunk N-1 to GPU 1 for decode, so the decode time hides behind the next chunk's generation. This cut end-to-end latency by 28% and is what pushed us across the real-time line.
Kernel-level optimization
We profiled the model and the cost was lopsided:
- Attention: 64%
- Memory movement and elementwise: 24%
- GEMM / linear: 12%
- Norm: about 1%
Since attention dominated, we moved it to FlashAttention 3 for a large saving. We also wrote fused megakernels to overlap compute and communication, and replaced hot elementwise paths with custom kernels: a custom RMSNorm came in at 7.71x over the baseline and a fused SiLU gate at 1.68x.
SPEED: Spectral Progressive Diffusion
Denoising a grid of tokens costs O(n^2) in the token count because of self-attention, which is brutal as resolution and clip length grow. Diffusion models are "spectrally autoregressive" though: in the frequency domain, low-frequency structure like overall shape and color emerges early in denoising, while high-frequency detail only resolves near the end. So computing high frequencies at full resolution early on is wasted work on what is still basically noise.
SPEED exploits this by growing resolution along the denoising trajectory instead of running full resolution the whole way. An optimal resolution schedule decides when to grow, using the measured power spectrum and each resolution's Nyquist limit to find the timestep where a frequency band stops being noise and starts carrying signal. A spectral noise expansion step decides how to grow: it lifts the latent into the frequency domain, keeps the already-denoised low-frequency content, and injects noise into the newly opened high-frequency bands at exactly the variance the noise schedule expects, so the larger latent looks in-distribution to the unmodified model. We integrated it for a 10% gain on the Causal Forcing model with no quality regression.
Challenges we ran into
- Prompt blending was the hard part, not the speed. Nine hours of dead ends before interpolation plus attention weighting gave us smooth, controllable transitions.
- Making the KV cache, the sliding context window, and a mid-stream prompt change all agree with each other.
- Starting out slower than real time and having to claw back every millisecond through parallelism and kernels rather than touching the model.
Accomplishments we are proud of
We added a genuinely new capability, live voice-driven mid-generation steering, to a model that had no such ability, with zero training and zero data. And it is not a demo that limps along: generation outruns playback at 700ms per 750ms chunk, voice-to-frame is 0.69s end-to-end, and the transitions are smooth rather than hard cuts. The interactivity is entirely an inference-time construction.
What we learned
The factorization of the underlying model decides what interaction is even possible. Autoregressive generation gives you committed partial state and a clean causal boundary between past and future, and that is the hook everything else hangs on. On the systems side, the lesson was to match the parallelism strategy to the model: stage-level pipeline parallelism beats tensor parallelism for a 1.3B model where per-layer communication would eat the gains, and profiling first told us to spend our effort on attention rather than guessing.
What's next
- More control axes than text: pose, camera, and region-targeted edits
- Longer, more stable rollouts so scenes can persist and accumulate state like a real world model
- Pushing SPEED harder across the trajectory and folding in a light fine-tune to close the small distribution gap from spectral expansion
- Multi-user shared worlds where several people steer the same generation at once



Log in or sign up for Devpost to join the conversation.