Inspiration
Enterprise procurement teams handle requests that are often incomplete, multilingual, contradictory, or missing the context needed for a defensible sourcing decision. The ChainIQ challenge stood out because it rewarded uncertainty handling, not just automation. We built TrailsIQ around that idea: an agent should escalate when the data is not good enough, and every recommendation should be traceable.
What it does
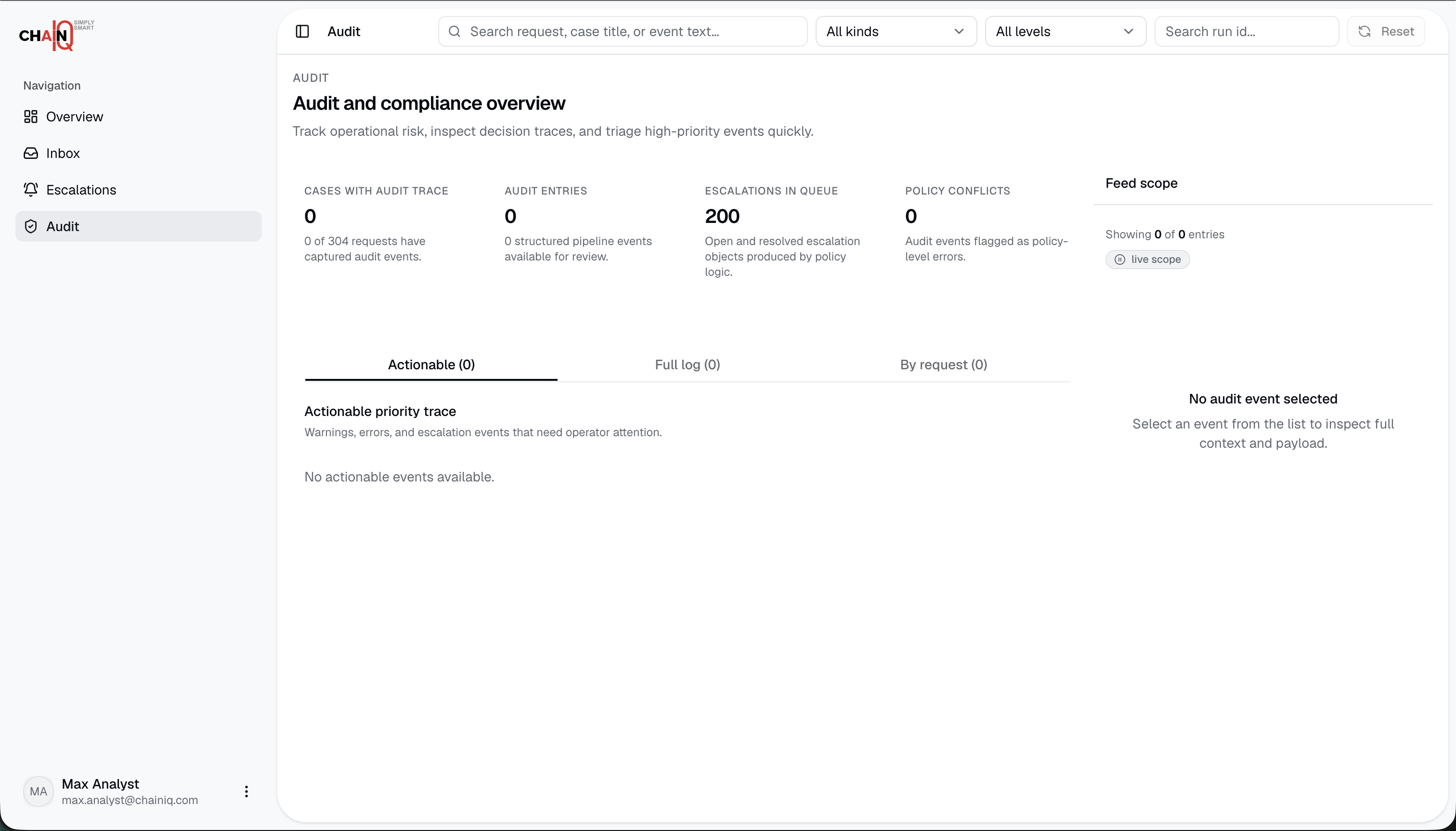
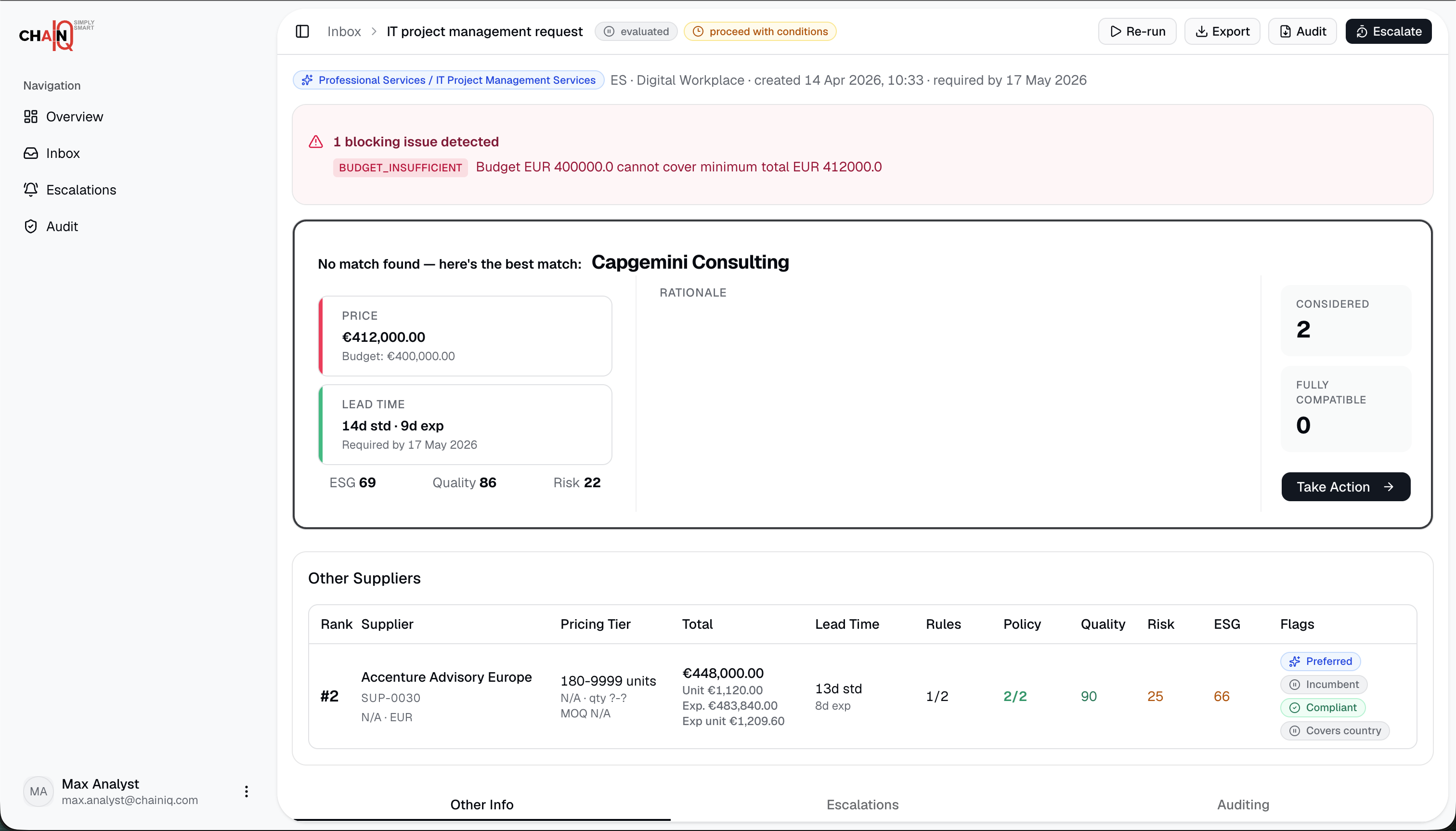
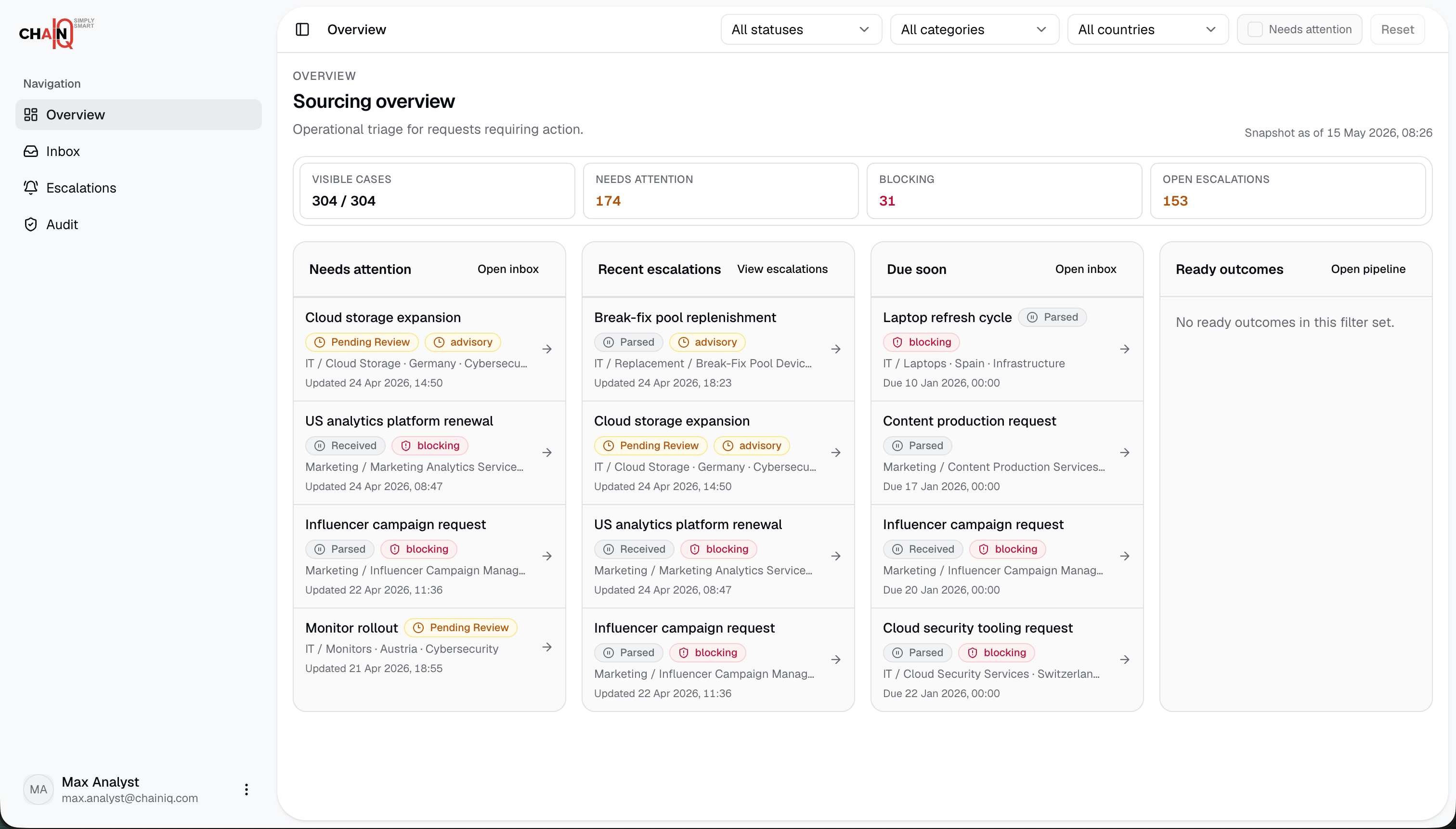
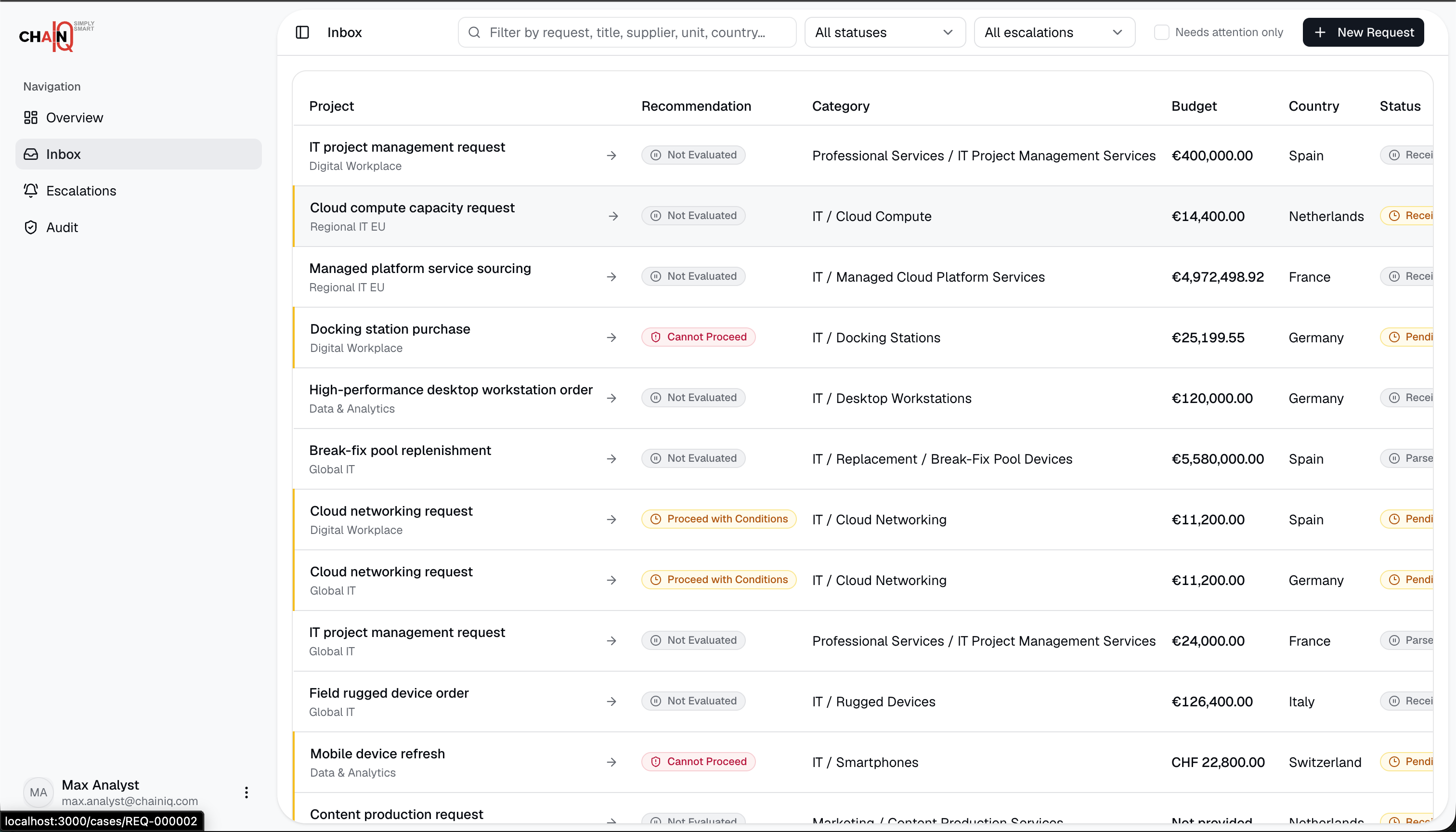
TrailsIQ converts free-text purchase requests into structured procurement decisions. It validates the request, checks policy requirements, finds compliant suppliers, prices the right quantity tiers, ranks the shortlist, explains exclusions, and creates an audit trail for the final recommendation.
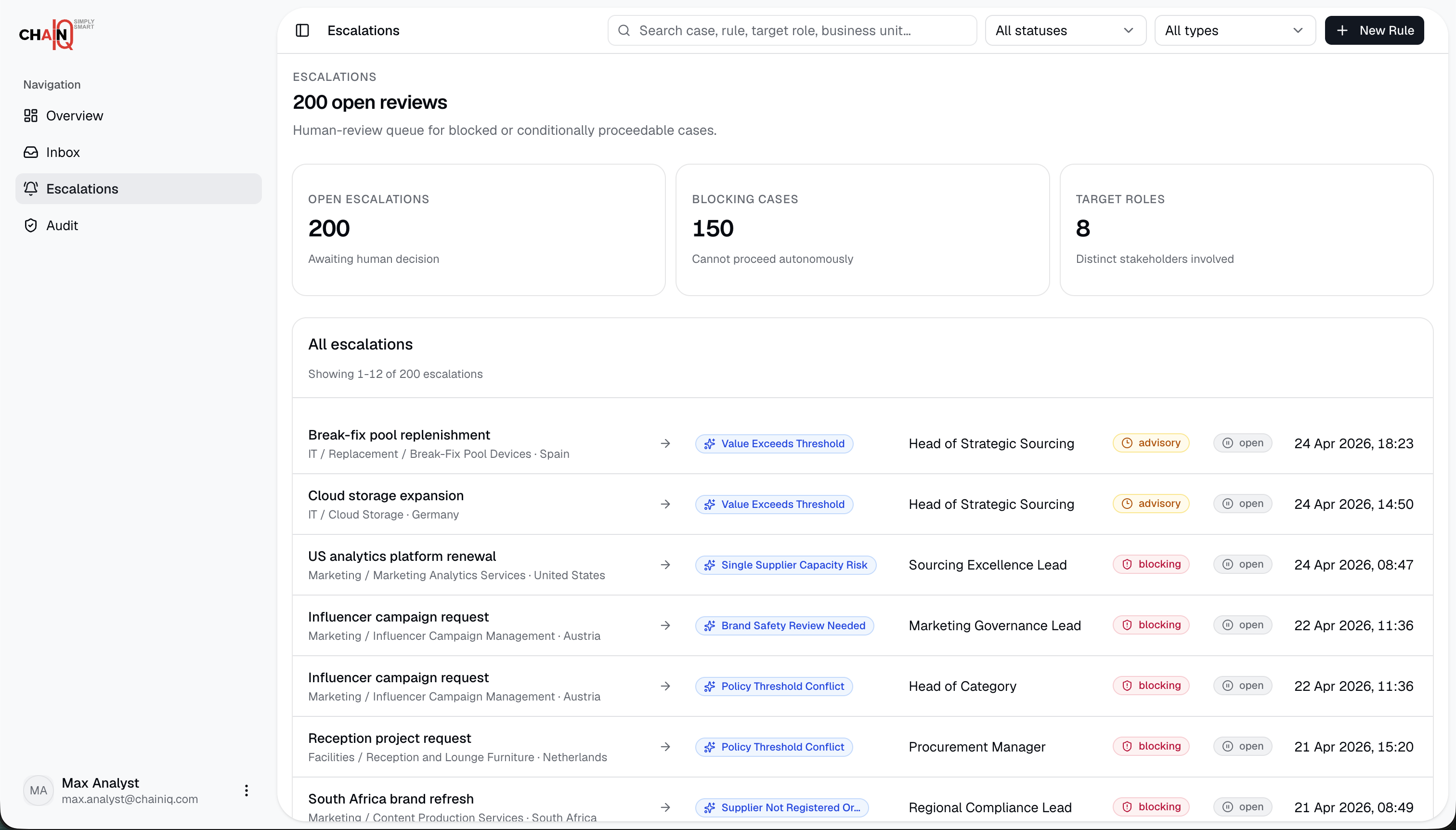
The demo covers standard purchase requests and edge cases such as missing information, restricted suppliers, budget issues, lead-time problems, and contradictory request text. Users can inspect supplier comparisons, rule checks, escalation targets, evaluation history, and downloadable audit reports.
How we built it
The app is split into three services. A Next.js frontend provides the case workspace, intake assistant, supplier comparison views, and escalation management screens. A FastAPI organisational layer owns the MySQL data model, analytics APIs, rule versioning, escalation records, and audit logs. A separate FastAPI logical layer runs the procurement decision pipeline and communicates with the organisational layer through REST APIs.
The pipeline is deterministic for decisions and selective about LLM use. Rules, supplier filtering, pricing, ranking, confidence scoring, and escalation status are implemented in Python. Anthropic Claude is used for structured request parsing, contradiction detection, concise recommendations, and natural-language rule authoring, with fallbacks so the core decision remains valid if an LLM call fails.
Challenges we ran into
The hardest part was making the system robust against messy data instead of only optimizing for the happy path. The challenge dataset includes inconsistent policy schemas, supplier rows duplicated across categories, unreliable restriction flags, semicolon-delimited regions, nullable quantities, multilingual requests, and missing historical awards.
We also had to keep the system auditable. That meant storing frozen rule snapshots, recording per-supplier checks, preserving pipeline telemetry, and making sure the frontend did not show supplier or pricing data before a request had actually been processed.
Accomplishments that we're proud of
We built an end-to-end sourcing workflow that can process real request scenarios, surface compliant supplier shortlists, explain every inclusion and exclusion, and escalate when the agent should not decide alone.
We are especially proud of the traceability features: dynamic rule versioning, evaluation run history, per-supplier compliance breakdowns, audit logs, and PDF audit reports. These make the prototype feel less like a demo chatbot and more like a procurement tool that a reviewer could interrogate.
What we learned
We learned that procurement automation depends as much on governance and data modeling as it does on AI. The LLM is useful for interpreting messy human language, but the actual sourcing decision needs deterministic rules, stable schemas, and explicit escalation logic.
We also learned how important it is to design for uncertainty. A procurement agent that says "I need clarification" at the right moment is more valuable than one that always returns a confident recommendation.
What's next
Next steps would include authentication and role-based permissions, deeper approval workflows, stronger deployment hardening, richer supplier performance signals, and a review queue for human procurement managers. We would also expand the natural-language rule management flow so business users can safely propose, test, approve, and roll back policy changes.
Built With
- anthropic
- docker
- fastapi
- mysql
- next.js
- typescript

Log in or sign up for Devpost to join the conversation.