-
-
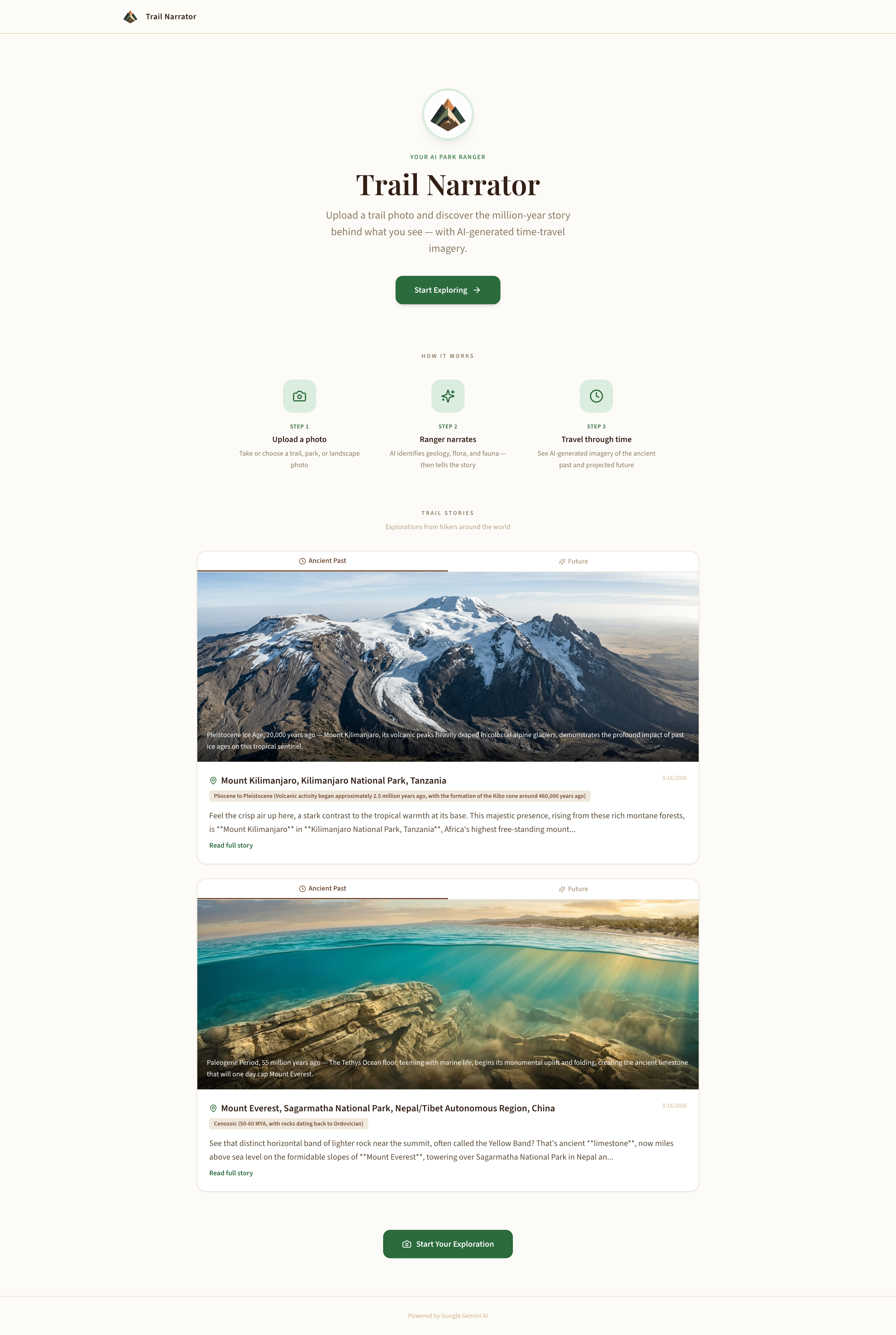
Landing Page
-
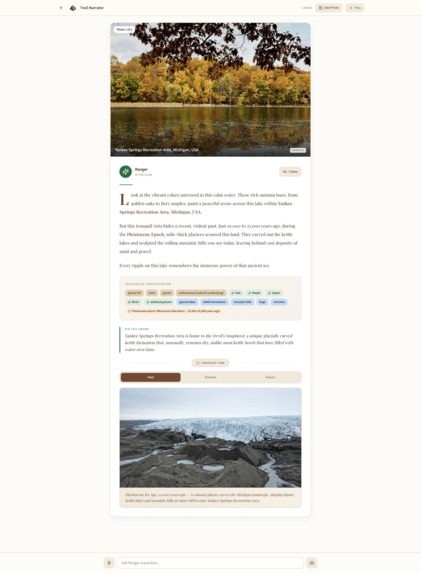
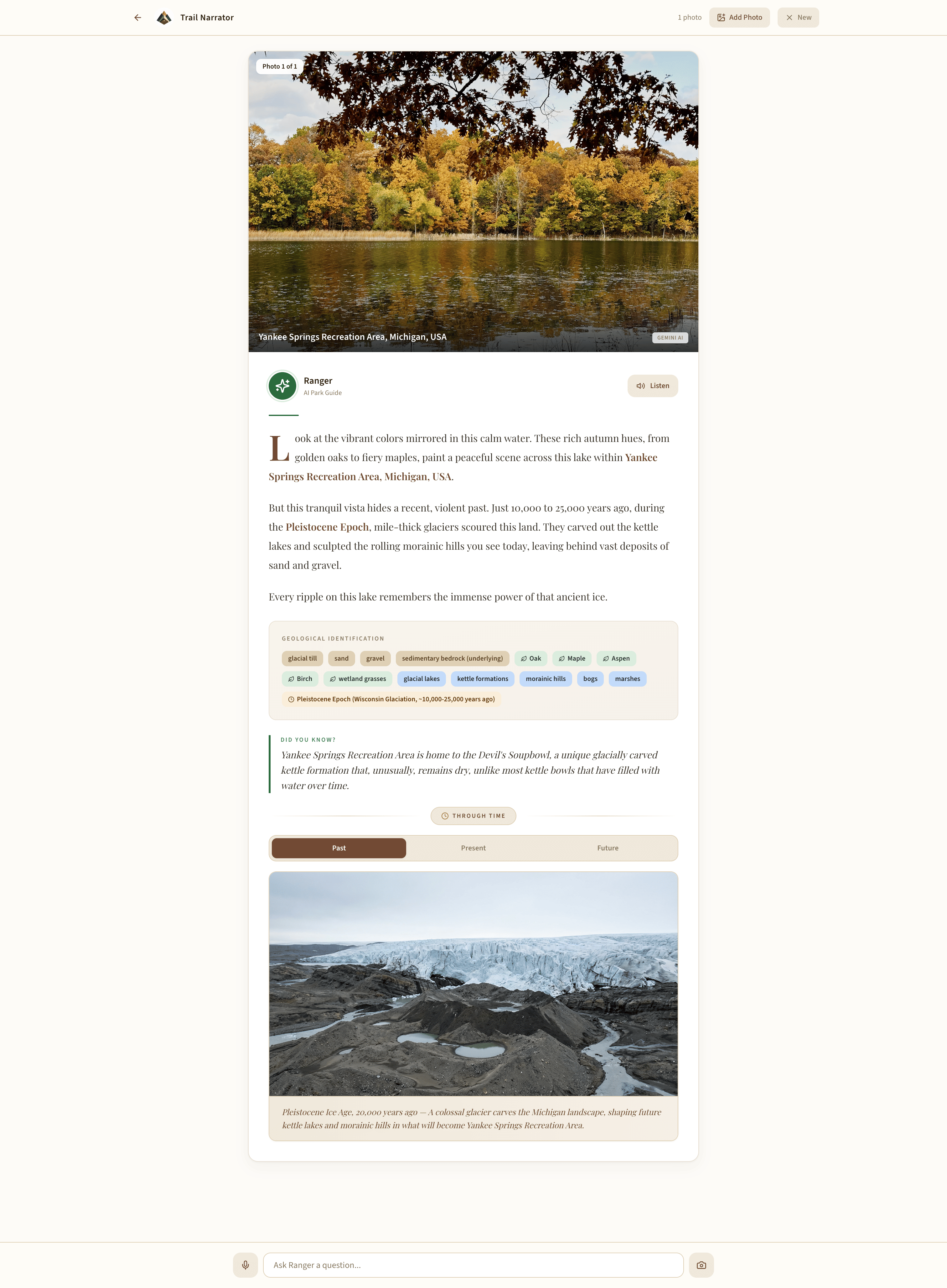
Past time travel image with narration
-
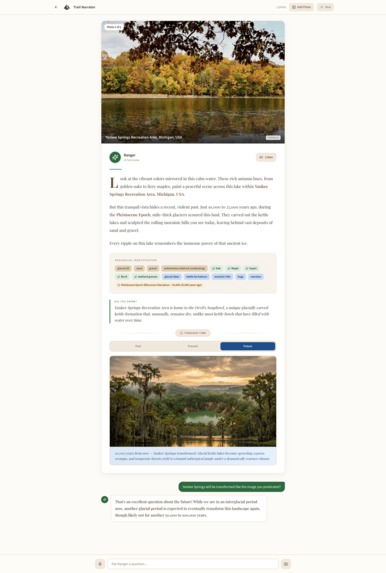
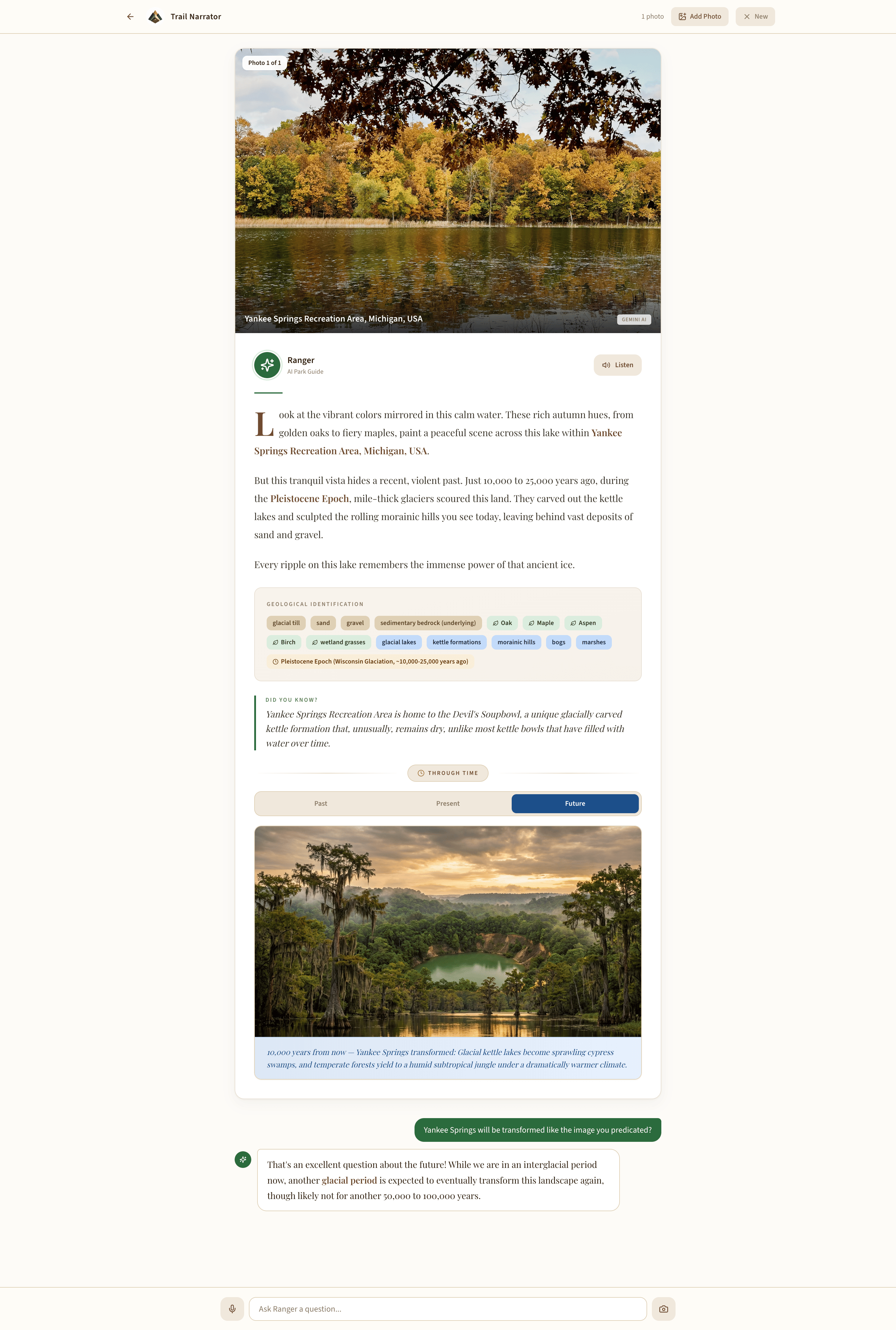
Future time travel image with narration
-
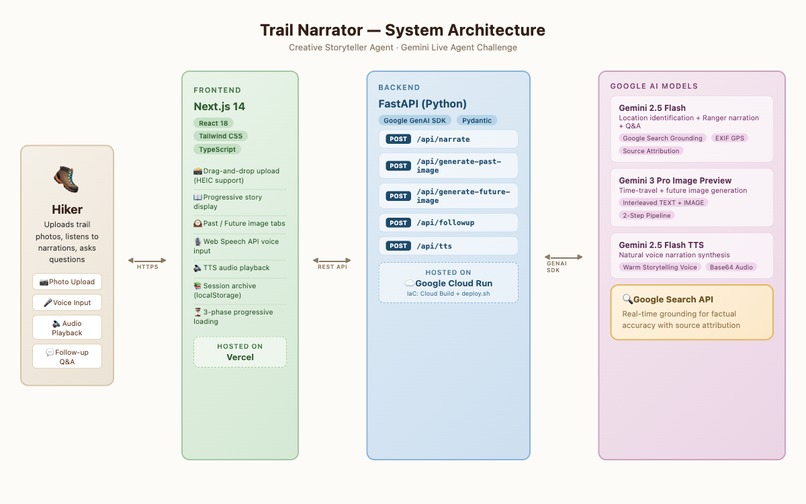
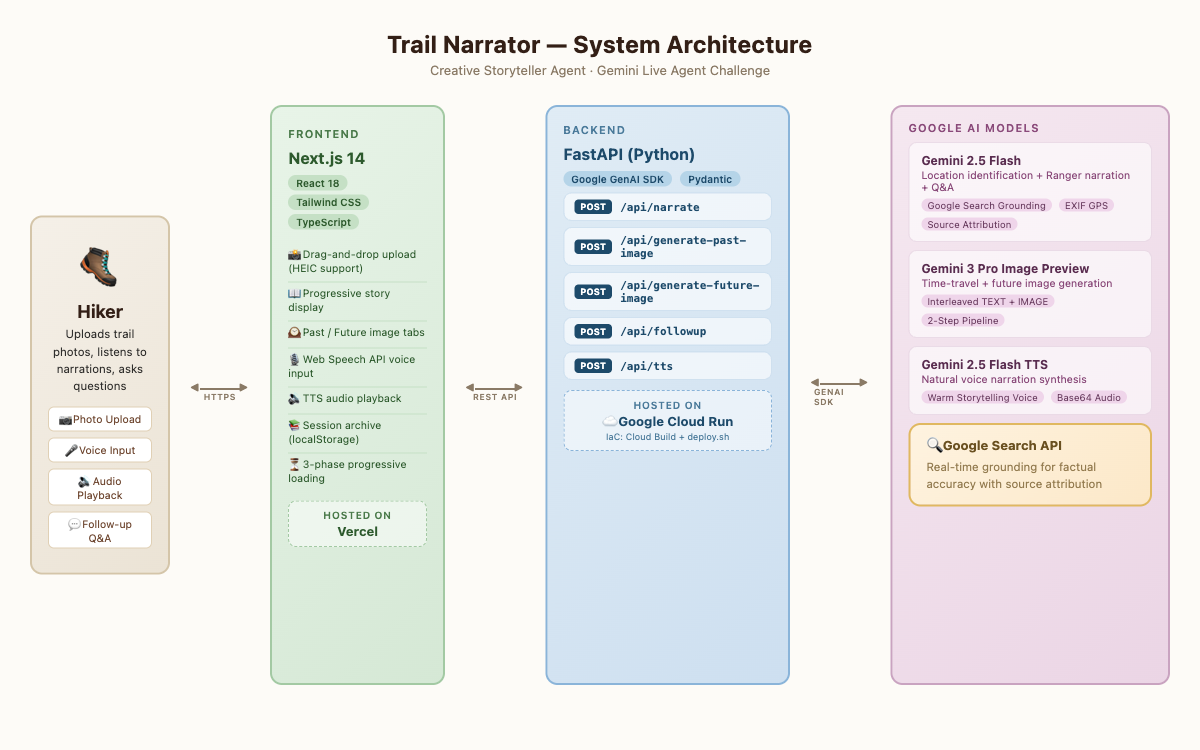
Architecture Diagram
-
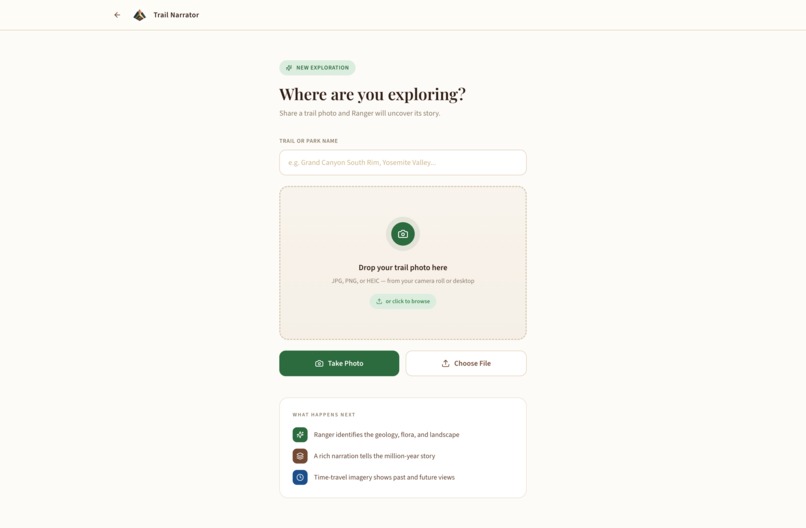
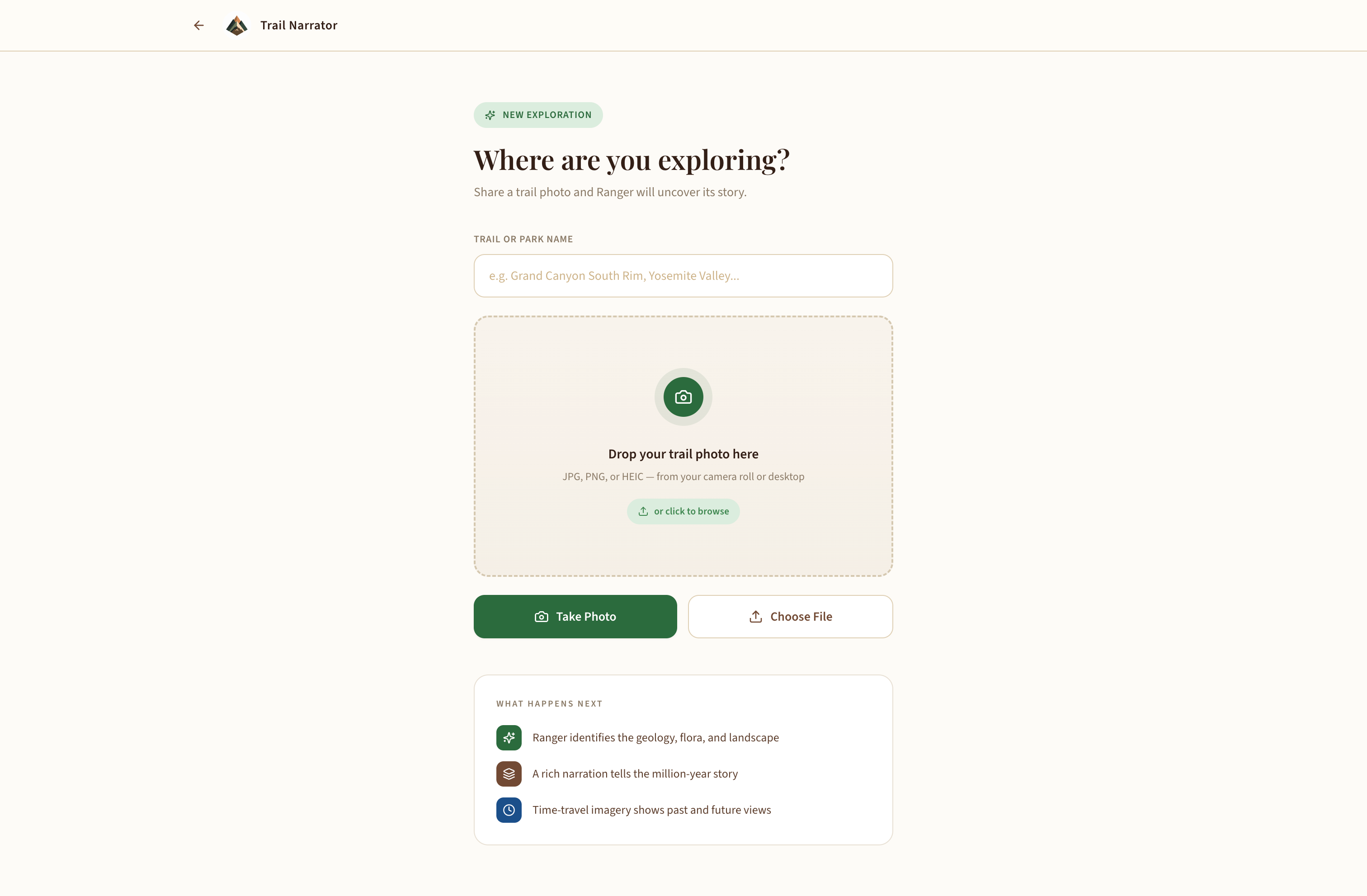
Upload Page to add photos
Inspiration
Every national park trail has a story stretching back millions of years — but most hikers walk right past it. I wondered: what if every trail photo could unlock that story? What if you could see the Grand Canyon as a shallow tropical sea, or Yosemite Valley before the glaciers carved it?
Trail Narrator was born from a simple idea: combine Gemini's multimodal capabilities to turn any trail photo into an immersive, narrated journey through deep time — guided by a warm, knowledgeable AI park ranger.
What it does
Trail Narrator transforms ordinary hiking photos into rich, multi-sensory storytelling experiences:
- Upload a trail photo — drag-and-drop or snap from your phone (HEIC supported)
- Instant identification — Gemini identifies the location, geology, flora, and fauna using Google Search grounding for factual accuracy
- Ranger narration — a campfire-style story about the landscape's history, delivered in a warm David Attenborough-meets-park-ranger voice
- Time-travel imagery — AI-generated visualizations of what the landscape looked like millions of years ago and what it may look like in the future
- Voice interaction — listen to narrations via Gemini TTS and ask follow-up questions naturally
- Story archive — save and revisit your trail narratives across sessions
How I built it
Architecture:
User Browser (Next.js on Vercel)
↓ REST API
FastAPI Backend (Google Cloud Run)
├── Location ID → Gemini 2.5 Flash + Google Search Grounding
├── Narration → Gemini 2.5 Flash (Ranger persona)
├── Past Image → Gemini 3 Pro Image Preview (interleaved output)
├── Future Image → Gemini 3 Pro Image Preview (interleaved output)
└── Voice → Gemini TTS
AI Pipeline: The core pipeline uses three Gemini models in concert:
- Gemini 2.5 Flash with Google Search grounding identifies the real-world location from the photo, extracting geological era, rock formations, and ecosystem data with source-backed accuracy
- Gemini 3 Pro Image Preview generates time-travel visualizations using interleaved TEXT+IMAGE output — first planning the scientifically accurate scene, then rendering it
- Gemini TTS converts narrations into natural, expressive speech with a warm storytelling voice
Progressive Loading UX: Since image generation takes longer than text, I built a three-phase progressive loading system:
- Phase 1 (~10s): Narration text appears immediately
- Phase 2 (~30s): Past time-travel image loads in background with toast notification
- Phase 3 (~45s): Future projection image loads in background
This keeps users engaged with the story while richer content generates behind the scenes.
Frontend: Built with Next.js 14 (App Router) and Tailwind CSS, featuring drag-and-drop upload, tabbed past/future image viewing, voice input via Web Speech API, and a session archive system with localStorage persistence.
Backend: FastAPI handles image uploads, session management, and orchestrates all Gemini API calls. EXIF GPS data is extracted from photos when available for more precise location identification. Deployed on Google Cloud Run with Infrastructure-as-Code via Cloud Build.
Challenges I faced
- Balancing speed and richness — Image generation can take 30-60 seconds. Progressive loading was my solution: show the narration instantly, load visuals in the background
- Scientific accuracy for geological eras — Getting Gemini to produce historically accurate descriptions of landscapes millions of years ago required careful prompt engineering and a two-step pipeline (research era → generate image)
- HEIC image handling — iPhone photos use HEIC format by default, which required adding pillow-heif and heic2any conversion on both backend and frontend
- Model fallback resilience — Image generation models occasionally fail, so I built a cascading fallback chain across multiple Gemini model variants
What I learned
- Google Search grounding is a game-changer for factual accuracy — it transforms Gemini from a creative writer into a reliable source-backed narrator
- Interleaved text+image generation in Gemini 3 Pro is incredibly powerful for creative applications where context matters
- Progressive disclosure is essential for AI-heavy UX — users are happy to wait when they have something engaging to interact with
- Persona prompting (my Ranger character) dramatically improves output quality over generic instructions
What's next for Trail Narrator
- Gemini Live API for real-time voice conversations while on the trail
- AR overlay — point your camera at a landscape and see the time-travel image overlaid
- Trail community — share your narrated stories with other hikers
- Offline mode with cached narrations for backcountry use
- Multi-photo stories — stitch a full hike into a narrative journey

Log in or sign up for Devpost to join the conversation.