-
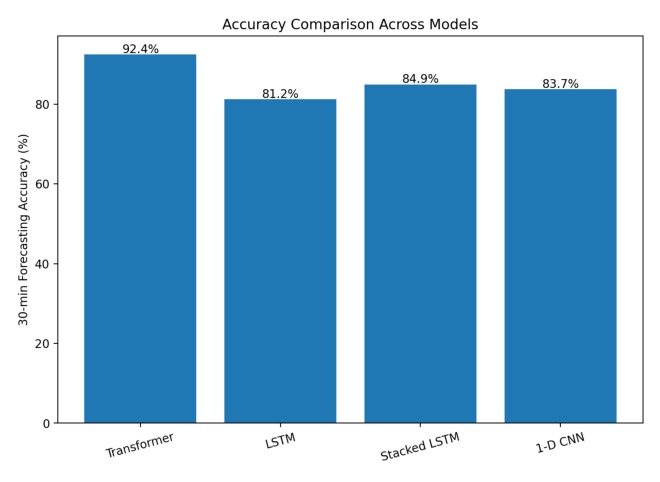
Transformer achieves highest 30 minute traffic forecasting accuracy, outperforming LSTM, stacked LSTM, and 1-D CNN baselines.
-
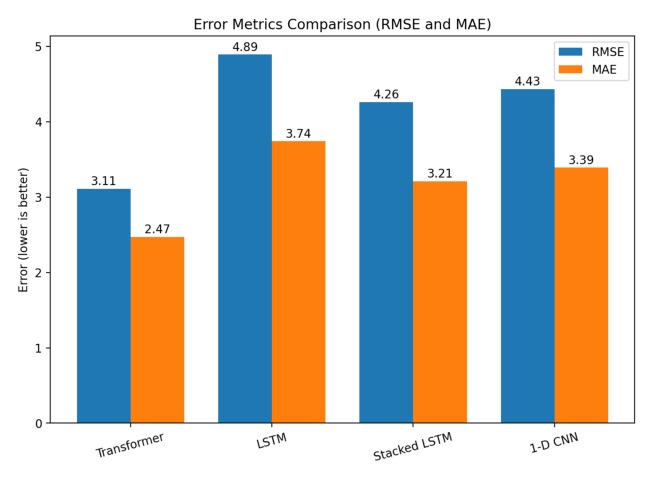
Transformer produces the lowest RMSE and MAE, indicating more precise short term traffic predictions than baseline models.
-
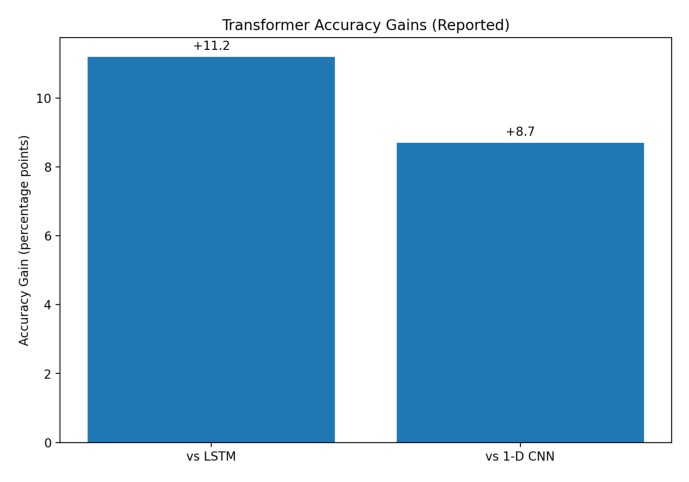
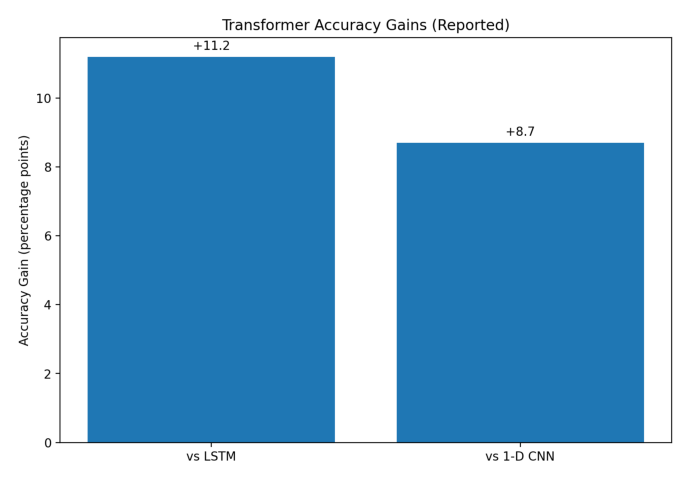
Transformer improves forecasting accuracy by 11.2 points over LSTM and 8.7 points over 1-D CNN models.

Inspiration
Traffic congestion is an issue that affects millions of people on a daily basis, yet many current traffic prediction models assume only short-range or local traffic pattern propagation. I wanted to explore whether recent attention-based models could better capture how traffic patterns propagate across an entire city. While studying Transformers for natural language processing, I noticed that they solve a problem very similar to traffic propagation by modeling long-range dependencies. This inspired me to apply Transformer architectures to traffic forecasting with the goal of improving both accuracy and explainability.
What it does
The Traffic Transformer forecasts citywide traffic conditions 30 minutes into the future using historical traffic sensor data. The model learns how traffic congestion propagates across road segments by attending to relevant road sensors, intersections, and bottleneck sections. In addition to forecasting traffic conditions, it generates attention maps that indicate which road segments most influence future traffic behavior.
How we built it
The model was trained and tested using real-time freeway traffic data from the Caltrans Performance Measurement System (PeMS). The dataset included speed, flow, and occupancy observations collected at five-minute intervals. Data preprocessing involved normalization and missing data imputation. A Transformer encoder with multi-head self-attention was implemented, and positional encodings were added to capture temporal cycles. To enable system-wide information acquisition, a global context vector was introduced. The model was trained using the AdamW optimizer and evaluated against LSTM and 1-D CNN baselines using accuracy, RMSE, and MAE metrics.
Challenges we ran into
Handling missing and noisy sensor data without introducing bias was a major challenge. Another difficulty was managing the computational cost of attention across a large number of sensors while preventing overfitting. Interpreting attention maps and validating that they reflected meaningful traffic propagation patterns, rather than spurious correlations, also required careful analysis.
Accomplishments that we're proud of
The model achieved an accuracy of 92.4% for 30-minute traffic flow prediction, significantly outperforming both LSTM and CNN models. The attention map visualizations illustrated realistic traffic flow patterns, including congestion at intersections and merging sections, indicating that the model learned true spatiotemporal correlations rather than simple associations.
What we learned
This project demonstrated that attention-based models have strong relevance beyond natural language processing. I learned that interpretability is just as important as accuracy when deploying models in real-world systems. The project strengthened my understanding of large-scale time-series modeling, deep learning system design, and simulation-based analysis, and increased my interest in modeling and simulations.
What's next for Traffic Transformer for Citywide Traffic Forecasting
Next steps include incorporating weather information and traffic event reports into the learning process. The model will be extended to support multimodal inputs, generalized to larger geographic regions, and optimized for improved efficiency and speed. Ultimately, the system will be capable of enabling adaptive traffic routing for smarter transportation systems.

Log in or sign up for Devpost to join the conversation.