TradeWizard
The intelligence layer for real-world prediction markets. A multi-agent AI system that turns event-driven markets on Polymarket into explainable, probability-driven trades - with a closed-loop learning fabric and a bounded-autonomy Portfolio Manager governed by hard, auditable risk limits.
Inspiration
Prediction markets are one of the cleanest signal-generation mechanisms ever built. They aggregate dispersed information into a single number - the price - and that number is a probability. In theory, anyone can trade them. In practice, almost nobody can trade them well.
To consistently price an outcome on Polymarket you need to monitor breaking news, read polling internals, watch order books for whale activity, track narrative velocity across media and social platforms, and time entries against catalysts. Those are five different jobs. Most retail traders have none of them. So they trade headlines, lose money, and quit. The asymmetry isn't liquidity - it's intelligence.
We started TradeWizard because we kept noticing the same gap: the markets were real, the events were tradable, but the analytical layer was missing. Bloomberg-grade analysis exists for equities. Nothing comparable existed for political, legal, economic, and geopolitical outcomes. We wanted to build the intelligence layer the prediction market category has been waiting for - not a content site, not a Twitter feed, but an actual decision system that produces explainable, probability-disciplined recommendations and stands behind them with a measurable accuracy track record.
We also wanted to confront the part most "AI trading" products avoid: what happens after the recommendation. Reading a thesis is one thing. Acting on it under time pressure, with the right size, with mandatory exits, while the market is moving - that's where retail loses. So we built an opt-in autonomous Portfolio Manager that executes inside hard guardrails the user pre-approves, with a kill switch that fails closed. Bounded autonomy, not unbounded delegation.
What it does
TradeWizard is two products that share a brain.
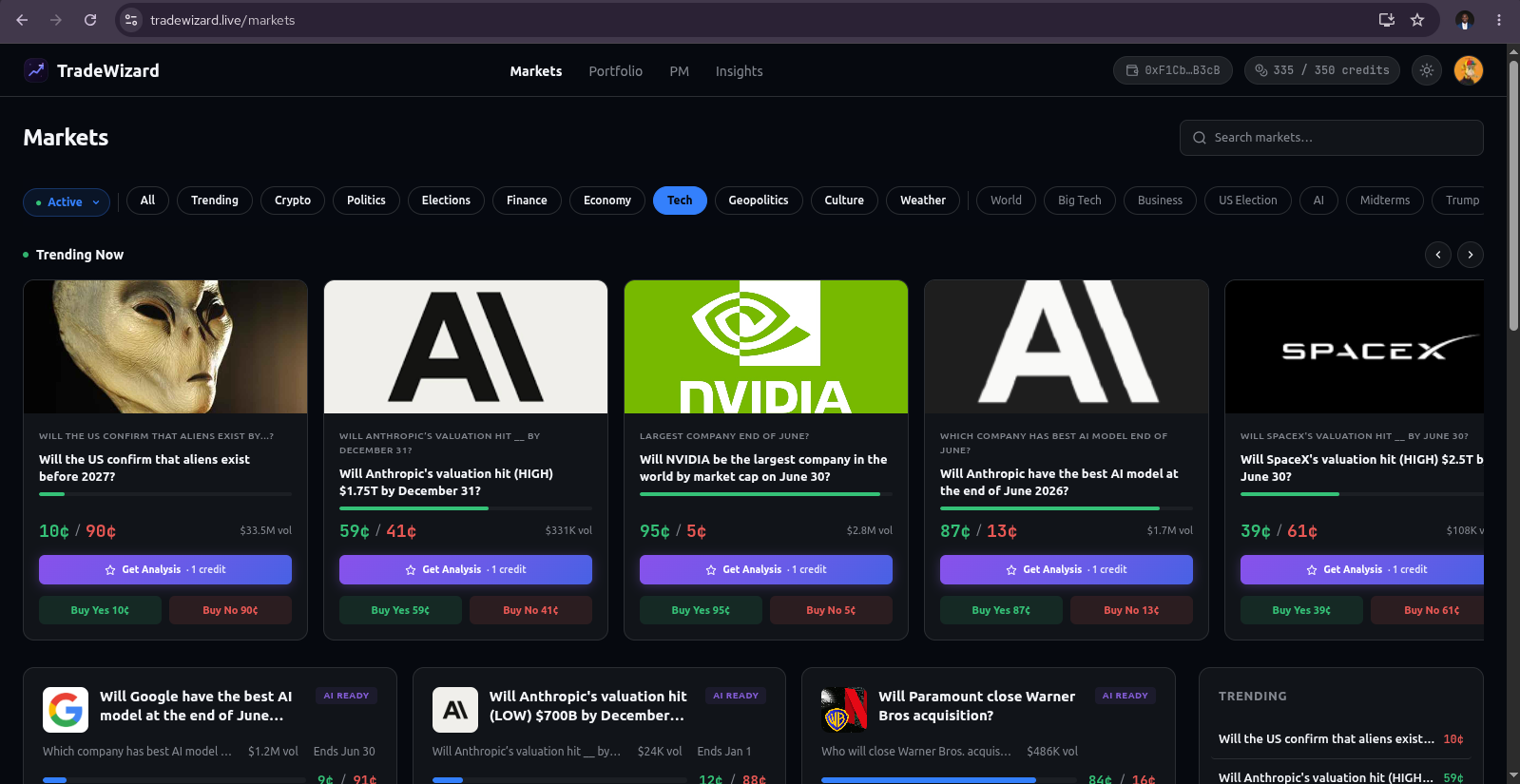
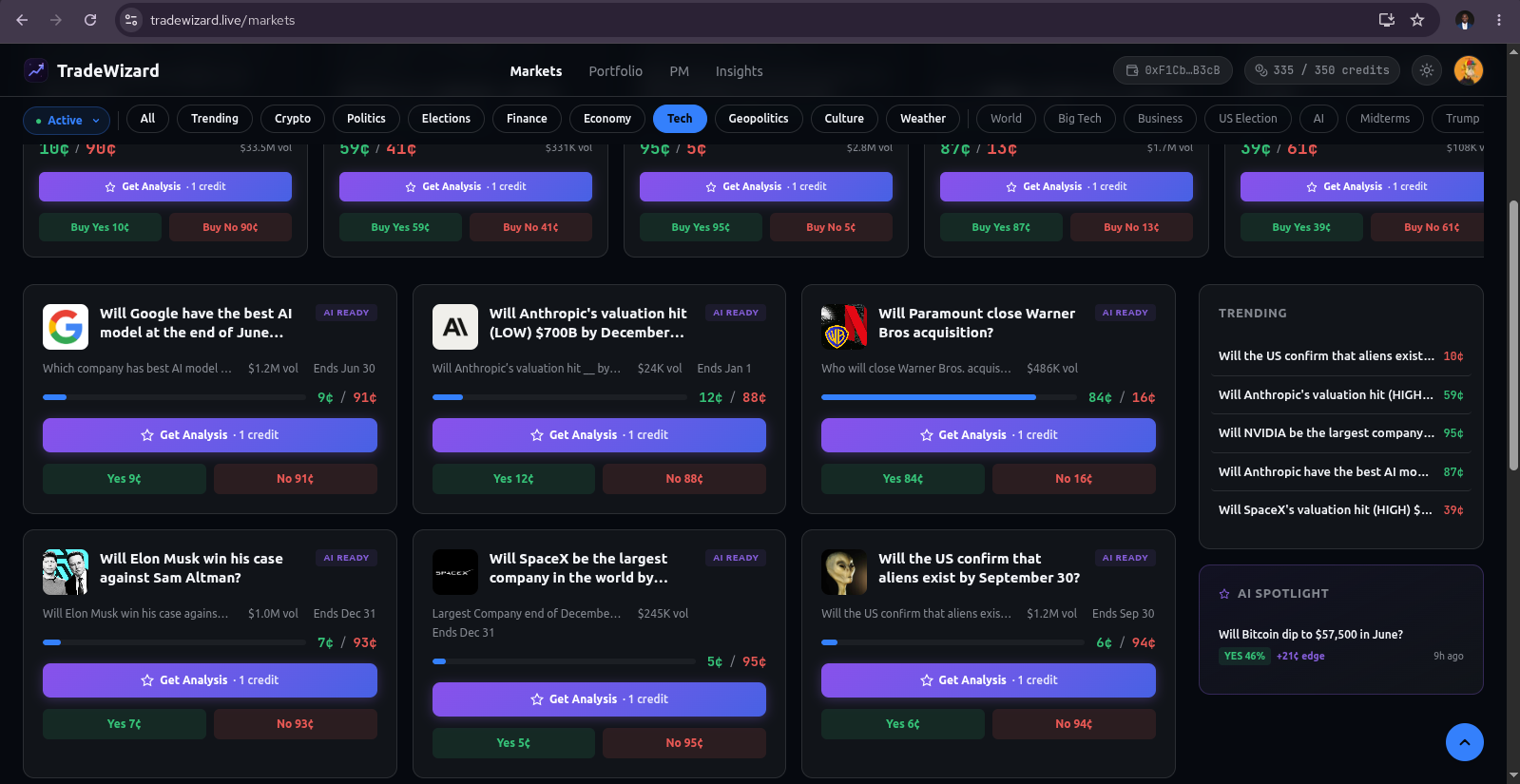
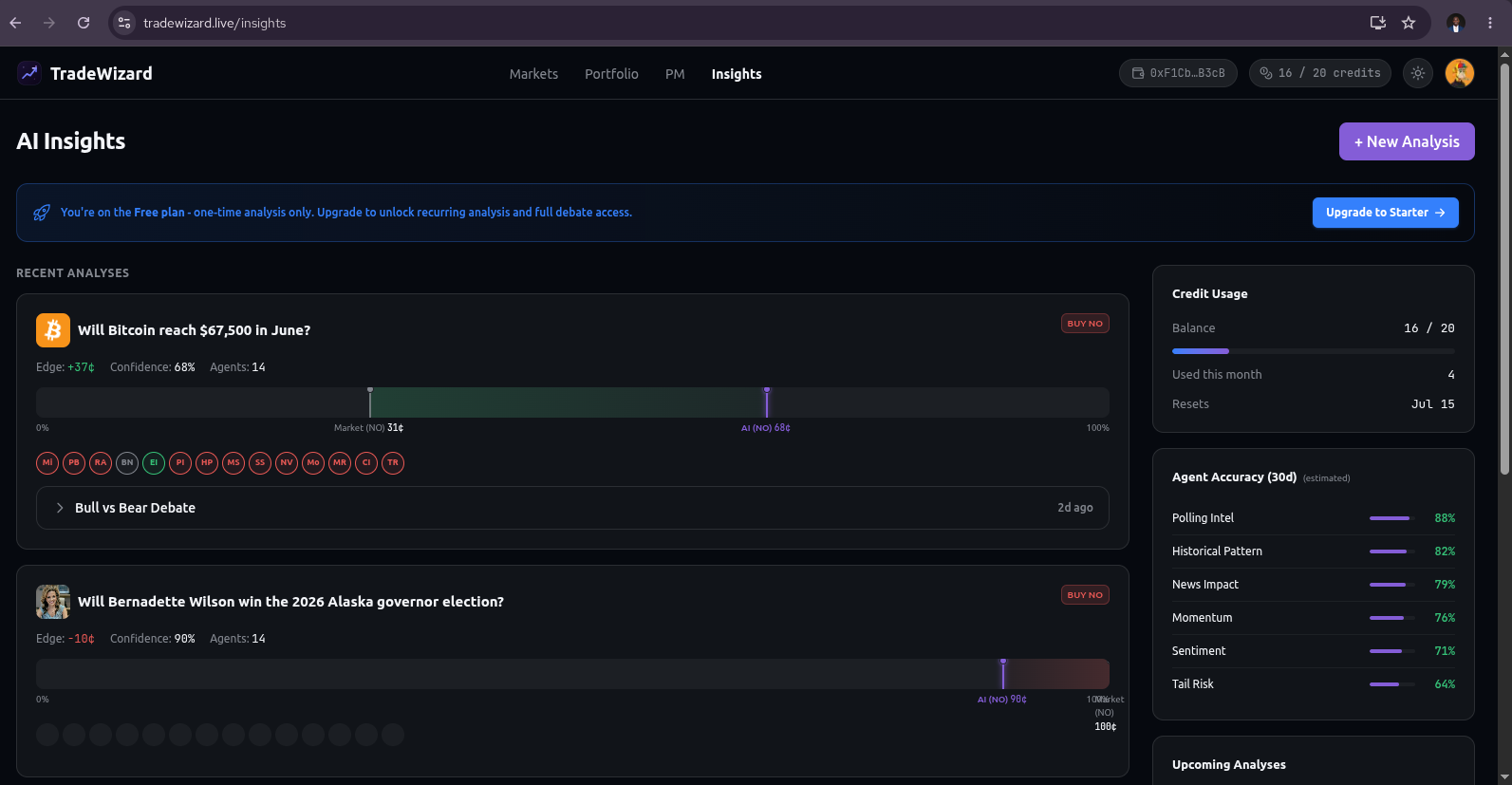
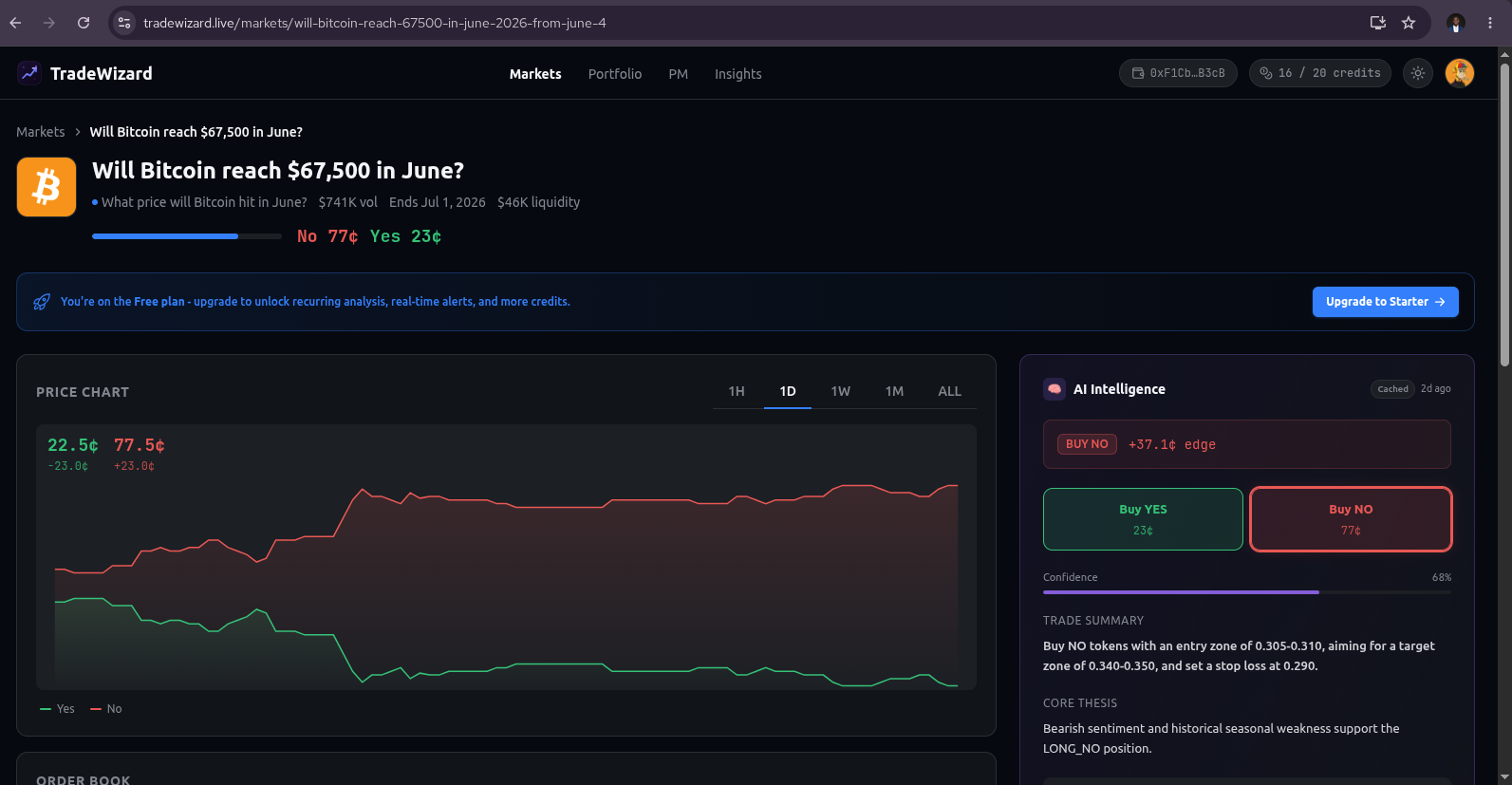
Intelligence layer. Any user can request analysis on any Polymarket market. Behind the request is an 11-stage workflow that runs 14 specialized intelligence agents in parallel, fuses their signals deterministically, debates the resulting thesis adversarially, runs a deterministic consensus engine, asks three risk-philosophy agents to weigh in on sizing, and emits a final recommendation with entry zone, target zone, mandatory stop-loss, expected value, win probability, and a full reasoning chain. If the agents disagree above a hard threshold, or if the expected value is non-positive, the system refuses to recommend - it returns NO_TRADE and explains why. Results are delivered through WebSocket, email, push, and webhook, respecting quiet hours and notification preferences. Every recommendation is scored after recommendations hit take-profit or stop-loss limits, and every agent has a public accuracy leaderboard.
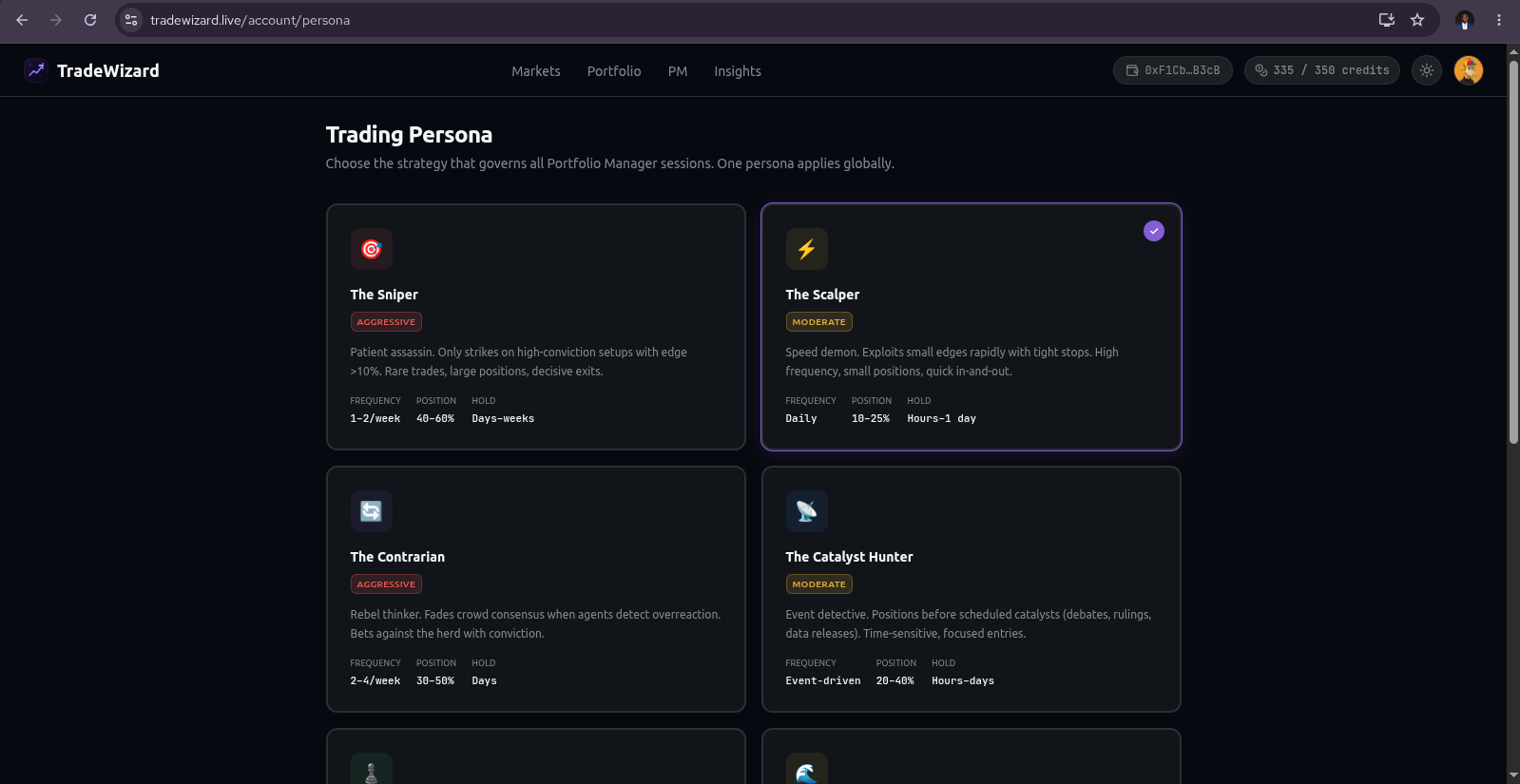
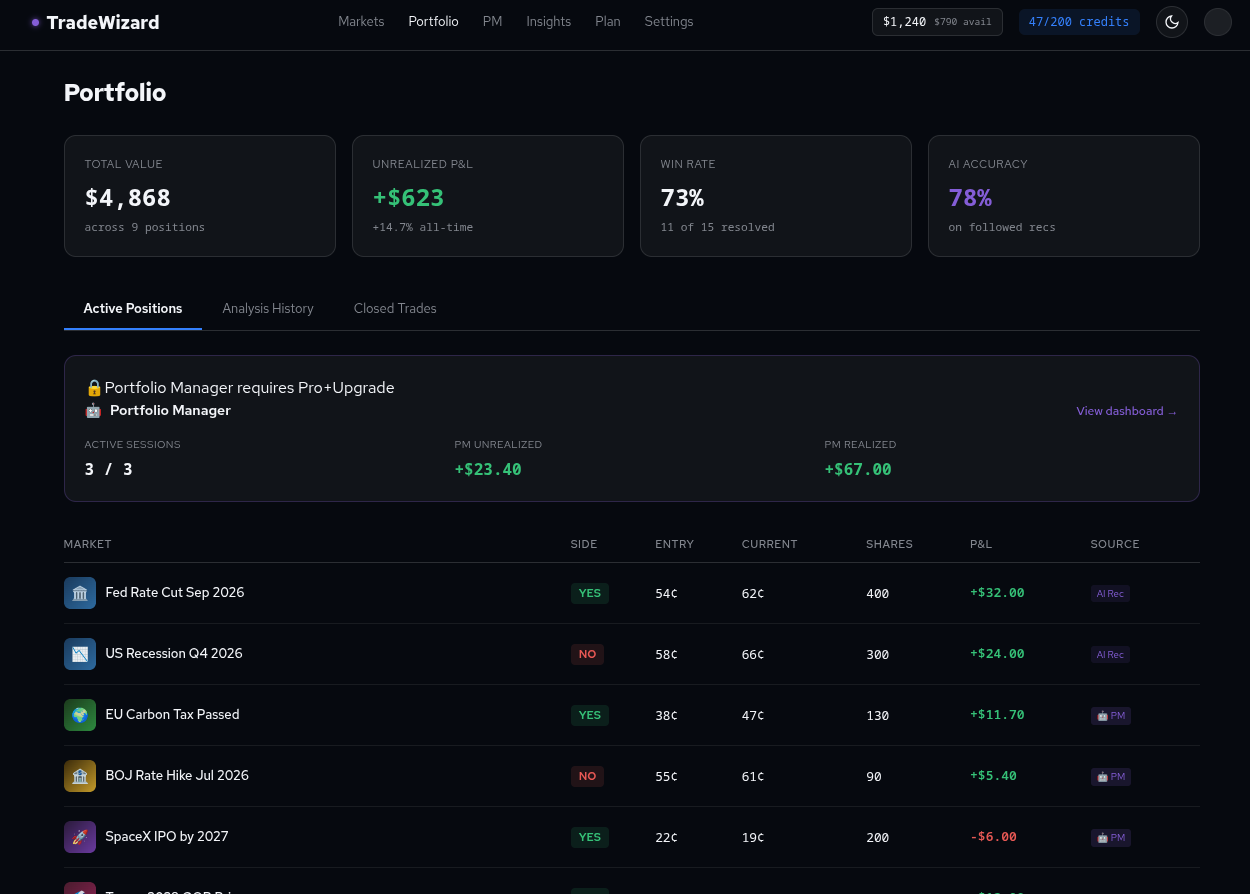
Autonomous Portfolio Manager (Pro and Elite). A user can opt into autonomous execution on a specific market by activating a session with a chosen persona (Sniper, Scalper, Contrarian, Catalyst Hunter, Hedge Architect, Momentum Rider), an investment amount, and pre-approved guardrails. The Portfolio Manager Lambda consumes recurring analyses for that market - it never triggers its own - and decides entry, sizing, stop-loss, and take-profit per trade. Orders are placed via the Polymarket CLOB API. A Position Guard monitors every open position for regime shifts and stale markets. A Risk Engine enforces loss limits, cooldowns, and a kill switch that fails closed. The user can pause, resume, stop, or kill all sessions at any time, and every trade, exit, and risk event fans out across notification channels in real time.
Around these sit the platform pieces a real product needs: passwordless Cognito Magic Link auth, on-chain USDC.e billing on Polygon with auto-renewal via ERC-20 allowances, a market-level analysis pool that prevents redundant compute, a credit system with an immutable audit trail, and a Next.js 16 / React 19 frontend that surfaces all of it through a clean trading-terminal UI.
How we built it
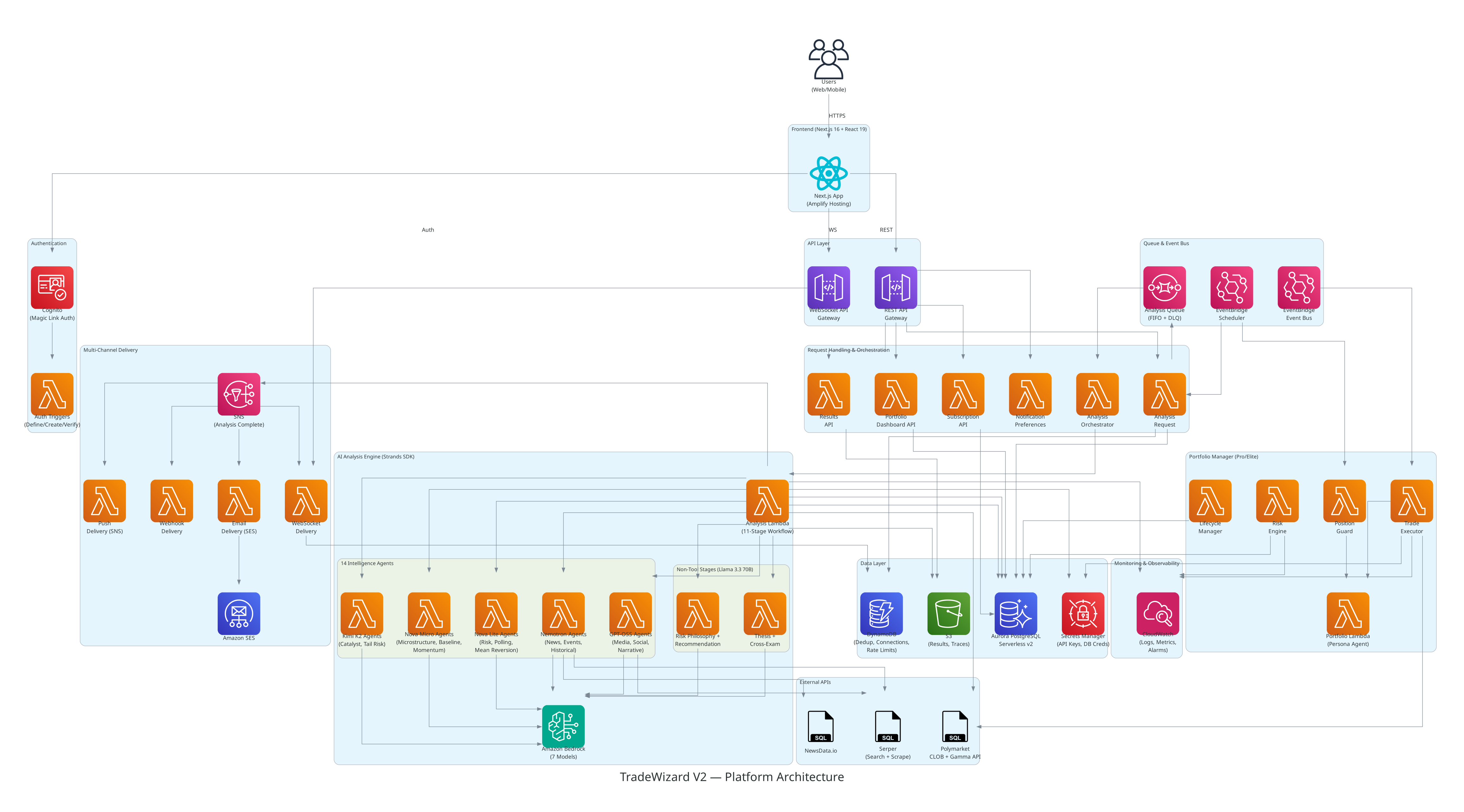
The product framing is simple. The architecture is where the work is.
AI Architecture Explanation
Inputs (what data goes in)
Every analysis begins with a market identifier from Polymarket. From that single seed, the system collects:
- Price history - OHLC-style price data fetched from the Polymarket CLOB API, written as a deterministic CSV to
/tmpfor agents to query numerically. - Market metadata - Resolution criteria, expiry date, current probability, bid/ask spread, volume, and liquidity score from the Gamma API. Related sibling markets are also fetched and their aggregate metrics computed.
- Agent memory - Per-agent historical signals from Aurora PostgreSQL's
agent_memorytable. Each agent loads only its own prior signals on this market (configurable depth, default 5). No cross-agent history. - Real-time web context - An autonomous research agent uses NewsData.io and Serper search/scrape tools to gather breaking news, expert opinions, polling data, and social discourse relevant to the market's question.
- Agent performance weights - Historical accuracy data from the
agent_performancetable, used to scale each agent's influence during signal fusion.
For the Portfolio Manager, additional inputs include: the user's active session (persona, capital envelope, current position state), the order book depth, the latest completed analysis, trade history, and session performance metrics - all fetched via read-only tools.
AI capabilities used
TradeWizard employs four distinct AI capabilities in a single pipeline:
| Capability | Where it's used | Models |
|---|---|---|
| Multi-agent reasoning | 14 intelligence agents producing independent probability estimates and directional signals from different analytical perspectives | Nova Micro, Nova Lite, Nemotron 3 Super, GPT-OSS 120B, Kimi K2 Thinking |
| Autonomous tool use | Agents calling external APIs (news, search, scrape, shell) to gather real-time data and perform numeric analysis | Nemotron 3 Super (web research), Nova Micro (shell/price analysis), Nova Lite (polling data) |
| Adversarial debate & synthesis | Thesis construction, cross-examination (5 tests × 2 theses), risk philosophy perspectives, and final recommendation generation | Llama 3.3 70B |
| Persona-driven decision-making | Portfolio Manager agent reasoning about entry/exit/sizing through the lens of a chosen trading persona with market context and performance history | Nova 2 Lite (Portfolio_Lambda) |
None of these are chatbots or classifiers. They are agentic workflows - LLMs orchestrated with tools, structured outputs, and deterministic gates that constrain what the models are allowed to conclude.
What processing happens
The 11-stage pipeline processes data through a sequence of parallel and serial stages:
- Data Preparation (deterministic) - Fetches market data from CLOB and Gamma APIs. Writes price CSV and related-markets JSON to
/tmp. No LLM involved. - Historical Context Retrieval (deterministic) - Loads per-agent memory and performance weights from Aurora PostgreSQL. No LLM involved.
- Web Research (agentic) - A Strands Agent with news and search tools autonomously gathers real-time context. 60-second timeout, max 10 searches + 5 scrapes.
- Agent Selection (deterministic) - All 14 agents are activated. No conditional filtering.
- Parallel Intelligence Agents (agentic) - 14 agents execute in parallel via
Promise.all, each assigned to a specific Bedrock model. Each produces a Zod-validatedAgentSignal: direction (YES/NO/NEUTRAL), confidence (0–1), fair probability (0–1), key drivers, and risk factors. 120-second per-agent timeout. If an agent fails to produce valid output, it is excluded from downstream stages. - Signal Fusion (deterministic, no LLM) - Weighted aggregation of all valid agent signals. Weights = type weight × confidence × historical accuracy score. Computes: weighted fair probability, fusion confidence, signal alignment, and a conflict map (all agent pairs diverging > 30%). If max divergence exceeds 70%, fusion confidence is halved.
- Thesis Construction (agentic) - Llama 3.3 70B generates competing bull and bear theses from the fused signal. Each thesis includes fair probability, edge, core argument, catalysts, and failure conditions.
- Cross-Examination (agentic) - Llama 3.3 70B runs 5 adversarial tests against each thesis (10 total): evidence, causality, timing, liquidity, tail risk. Each test produces a survived/weakened/refuted outcome with a numeric score.
- Consensus Engine (deterministic, no LLM) - Computes weighted consensus probability from bull/bear fair probabilities weighted by debate scores and per-agent accuracy. Computes disagreement index (stddev of agent fair probabilities). If disagreement > 30%, consensus fails → forced NO_TRADE. Determines action: LONG_YES, LONG_NO, or NO_TRADE.
- Risk Philosophy (agentic) - Three agents (aggressive, conservative, neutral) run in parallel on Llama 3.3 70B. Provide position-sizing perspectives - Kelly criterion, hedging, spreads - without influencing probability estimates.
- Recommendation (agentic) - Llama 3.3 70B synthesizes all upstream context into a final
TradeRecommendation. Validated through Zod schema and price-ordering constraints. If EV ≤ 0, the recommendation is rejected → forced NO_TRADE. Falls back to a structured NO_TRADE explanation on any parse failure.
For the Portfolio Manager, processing is simpler: the Portfolio_Lambda receives the latest analysis result and session context, runs a single persona-driven agent with 7 read-only tools, and produces a structured entry/exit/skip decision. The Trade Executor then validates the decision against hard limits (SL/TP present, size within cap, cooldown clear, loss limit intact) before placing orders on the CLOB.
Outputs (what the user receives)
From the Intelligence Layer:
A TradeRecommendation delivered via the user's preferred channels (WebSocket, email, push, webhook):
- Action: LONG_YES, LONG_NO, or NO_TRADE
- Entry zone: [low, high] price range for position entry
- Target zone: [low, high] take-profit range
- Stop-loss: Hard exit price (mandatory)
- Expected value: Calculated EV of the trade (must be positive for any recommendation)
- Win probability: Agent's estimated probability of the trade reaching target
- Explanation: Multi-paragraph reasoning chain including core thesis, key catalysts, failure scenarios, and uncertainty notes
- Metadata: Agents used, disagreement index, consensus probability, edge vs. market price, market question, analysis duration
Additionally, each recommendation exposes: the full per-agent signal breakdown (direction, confidence, fair probability, key drivers, risk factors per agent), bull and bear thesis memos with cross-examination scores, and the three risk-philosophy perspectives.
From the Portfolio Manager:
Real-time notifications for every event in the trading lifecycle:
- Trade entered: Direction, size, entry price, SL price, TP price, persona reasoning
- Position exited: Exit price, P&L, exit reason (TP hit, SL hit, regime shift, manual)
- Risk alert: Warning at 30% session loss, position size reduction activated
- Kill switch triggered: Reason, sessions affected, positions exited
- Session status changes: Paused, resumed, stopped, terminated (with reason)
- Daily summary: Session P&L, trade count, win rate, capital utilization
The Portfolio Manager dashboard surfaces: active sessions, historical trades with full decision logs, aggregate statistics (total P&L, win rate, average hold time), and the agent decision audit trail showing exactly why each entry, exit, or skip was made.
Human-in-the-Loop Decision
The AI never decides how much of your money is at risk.
TradeWizard's intelligence layer recommends trades and the Portfolio Manager can execute them autonomously - but the system cannot activate itself. A human must explicitly choose: which market to expose capital to, how much capital to commit, which trading persona governs decision-making, and whether to enable autonomous execution at all. These four choices define the blast radius of the system, and the AI is architecturally excluded from making any of them.
This is deliberate. A probabilistic system - no matter how well-calibrated - should never unilaterally decide what fraction of a person's wealth to put in play. The AI can estimate that a market has a 72% fair probability and a positive expected value, but it cannot know the user's total financial picture, risk tolerance, liquidity needs, or emotional capacity for loss. Those are human judgments that no model has the context to make responsibly.
Concretely, this means:
- The Portfolio Manager activation handler requires the user to submit a capital amount and confirm it. The Lambda cannot self-activate or increase the committed capital.
- The
amount_availablefield on a session is set by the user and can only be increased through an explicit investment-increase API call that the user initiates. - The kill switch - the ultimate human override - is always available and fails closed. No amount of positive expected value can override a user who wants out.
- Even on the intelligence layer (non-PM), the system delivers a recommendation but the user places the trade manually. The AI never touches the order book unless the user has explicitly opted into bounded autonomy.
The risk perimeter is always human-drawn. The AI operates inside it.
Responsible AI Guardrail
Risk: Over-reliance - users trusting AI recommendations without critical evaluation, leading to financial harm.
Over-reliance is the most dangerous failure mode in any AI trading system. If users treat recommendations as certainties rather than probabilistic estimates, they will over-size positions, ignore warning signals, and suffer outsized losses when the system is inevitably wrong. The risk compounds when the system is accurate most of the time - success breeds uncritical trust.
We reduce this risk through four architectural mechanisms:
1. The system visibly refuses. When agent disagreement exceeds 30% or expected value is non-positive, TradeWizard returns NO_TRADE with a structured explanation of why. This is not a soft suggestion - it is the only output the pipeline can produce under those conditions. Users who see the system regularly decline to recommend learn that it is not omniscient. A system that always has an answer trains users to stop thinking. A system that sometimes says "I don't know" trains users to evaluate.
2. Uncertainty is surfaced, not hidden. Every recommendation exposes its disagreement index, confidence band, the specific agents that dissented, and the failure scenarios that would invalidate the thesis. The UI does not present a clean "BUY YES" button without context - it presents the full reasoning chain, the cross-examination scores, and the conditions under which the recommendation would be wrong. This is a deliberate UX choice: we make it harder to act without reading.
3. Mandatory stop-losses bound the cost of misplaced trust. Even if a user over-relies on a recommendation, the mandatory stop-loss ensures the maximum loss per position is bounded. The Portfolio Manager enforces this at the executor layer - no position can exist without an exit plan. This does not prevent over-reliance, but it caps its financial consequence.
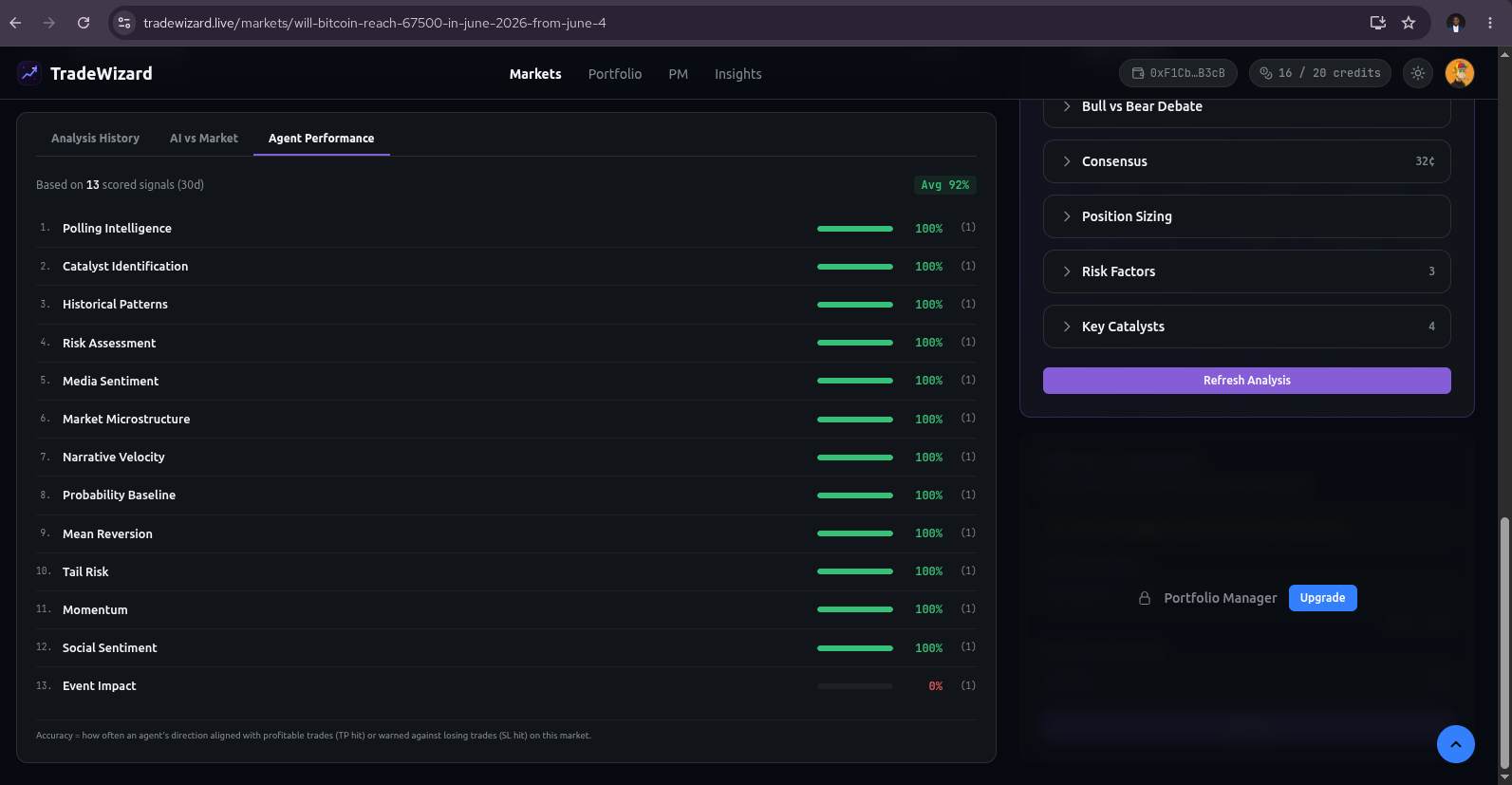
4. The accuracy leaderboard creates calibrated expectations. Every recommendation is scored against eventual outcomes (TP hit = success, SL hit = failure). The public agent accuracy leaderboard shows users - with real numbers - that the system is not always right. An agent at 62% accuracy is visibly, provably fallible. Users who see calibrated accuracy data develop calibrated trust, rather than binary faith.
The goal is not to prevent users from following recommendations - that would defeat the product's purpose. The goal is to ensure they follow recommendations with appropriate confidence, informed by visible uncertainty, bounded by mechanical exits, and calibrated by historical accuracy. Over-reliance is reduced not by disclaimers, but by making the system's limitations structurally visible at every decision point.
Stack at a glance
- Infrastructure: AWS CDK in TypeScript. Stacks for network, database, auth, queue, notification, storage, monitoring, and compute. Aurora PostgreSQL Serverless v2 for state, DynamoDB with TTL for dedup and WebSocket connections, SQS FIFO for the analysis queue with a DLQ, EventBridge for scheduling and routing, SNS topic fan-out for delivery, S3 for analysis artifacts and agent traces.
- Compute: AWS Lambda on Node.js 20 throughout. No long-lived servers. No NAT Gateway. Aurora is reachable on a public endpoint with SSL enforcement, scales to 0.5 ACU at idle, and auto-scales under load. Baseline infrastructure runs around fifteen to twenty dollars a month - the architecture is shaped to make scaling a revenue decision, not a survival one.
- AI runtime: Self-hosted Lambda with the Strands Agents SDK in TypeScript. Two agentic Lambdas -
Analysis_Lambdaruns the 11-stage intelligence workflow,Portfolio_Lambdaruns the persona-driven trade decision. Both use Amazon Bedrock as the model provider with multi-model routing across 7 foundation models distributed by capability and RPM budget. Intelligence agents (tool-capable) are spread across Nova Micro (200 RPM), Nova Lite (200 RPM), Nemotron 3 Super (100 RPM), GPT-OSS 120B (100 RPM), and Kimi K2 Thinking (100 RPM). Non-tool stages (thesis, cross-exam, risk philosophy, recommendation) use Llama 3.3 70B at 8000 RPM. Web research uses Nemotron (needs tools, runs alone). Total tool-capable RPM budget: ~720 - well above what 14 parallel agents need. All model IDs are env-driven for per-environment overrides. - Frontend: Next.js 16 App Router on AWS Amplify Hosting. React 19, TypeScript strict, Tailwind 4, TanStack Query, WebSocket client with exponential backoff and ping keepalive. Magic SDK plus viem for on-chain operations. Polymarket CLOB client for order placement.
- Payments: On-chain USDC.e on Polygon. Subscriptions and credit packs are settled by transaction hash verification using viem; auto-renewal works through a pre-approved ERC-20 allowance and
transferFrom. No card processor in the loop.
Agent architecture and coordination
The 14 intelligence agents run on every analysis. There is no conditional selection by market type, no router model deciding who gets to talk. We tried router-style designs early and they introduced a single point of failure that hides behind the appearance of efficiency: when the router is wrong, the rest of the system is missing the agent that mattered. Running all 14 in parallel via Promise.all costs more on a per-analysis basis but produces a complete, comparable signal set every time, which is what the deterministic stages downstream need to do their job.
The agents are distributed across five tool-capable models based on capability matching and RPM budgets. Data-crunching agents (microstructure, momentum, mean reversion) run on fast models like Nova Micro and Nova Lite. News and event agents that hit external APIs run on Nemotron 3 Super, which is optimized for agentic tool use. Sentiment agents requiring nuanced reasoning run on GPT-OSS 120B. Deep-reasoning scenario agents (catalyst identification, tail risk) run on Kimi K2 Thinking. Non-tool stages - thesis construction, cross-examination, risk philosophy, and recommendation - run on Llama 3.3 70B, which has 8000 RPM but no tool-calling support, making it ideal for pure reasoning stages that don't need external data access. This distribution means no single model bottlenecks the parallel stage: each model handles at most 3 intelligence agents concurrently, well within RPM limits.
The agents fall into six tool-use categories - market microstructure, news, polling, sentiment, narrative, price action, scenario - and each gets a tool kit appropriate to its job. News agents get the NewsData.io tool. Browser-style agents get the Serper search-and-scrape tool. Price-aware agents get a sandboxed shell tool that can run Python and bash on /tmp for numeric work over the price-history CSV the data-preparation stage writes. Tools are wrapped with timeouts, key rotation, and error handling so a single dead key or slow source doesn't crater the run.
Each agent emits an AgentSignal - a typed record with direction, confidence, fair probability, key drivers, and risk factors. We do not let the LLM decide what the structure is; we use the JSON extractor and Zod schemas to enforce shape, and we have explicit fallback paths when the LLM produces something unparseable.
Conflict resolution and validation chain
This is the part that distinguishes TradeWizard from a chat-bot recommending trades. There are three deterministic gates between raw agent output and what reaches the user.
Gate 1: Signal Fusion (no LLM). Agent signals are aggregated through weighted fusion. Weights respond to agent type, confidence, data freshness, and historical accuracy from the leaderboard. Divergence is measured directly - when the spread between fair-probability estimates is extreme, a divergence penalty drops fusion confidence. The fusion stage produces a single fair probability with a conflict map, not a vote.
Gate 2: Adversarial Debate. A thesis-construction agent generates competing bull and bear cases from the fused signal. A cross-examination agent then runs five adversarial tests against each thesis - evidence, causality, timing, liquidity, tail risk - for ten tests in total. Each test produces a survived/weakened/refuted outcome and a numeric score, so the debate output is a structured object, not prose.
Gate 3: Consensus Engine (no LLM). A weighted consensus probability is computed from the bull and bear fair probabilities, weighted by debate scores and per-agent leaderboard accuracy. We compute a disagreement index - the standard deviation of agent fair probabilities - and if disagreement exceeds 30%, consensus fails. The system refuses to recommend. The recommendation stage receives the failure flag and is forced to emit NO_TRADE with a structured explanation. The same is true for negative expected value: if EV is non-positive, the recommendation is rejected and replaced with NO_TRADE. These are not LLM behaviors we hope for. They are deterministic checks in the pipeline that the LLM cannot override.
The risk-philosophy agents (aggressive, conservative, neutral) run after consensus, in parallel. They contribute position-sizing perspectives - Kelly criterion, capital preservation, market-neutral structures - but they do not influence probability estimates. Sizing and probability are kept architecturally separate so a single risk view cannot bias the underlying belief.
Memory without anchoring
Each agent's prior signals on the same market are loaded from the Aurora agent_memory table before each run. Crucially, an agent only sees its own history. We deliberately avoided exposing cross-agent history because we found it produced anchoring - agents converging on each other rather than reasoning independently. Independence at the agent layer is what makes the disagreement index a meaningful signal. The history depth is configurable through ANALYSIS_HISTORY_DEPTH, clamped to a sensible range, and every signal a user sees is logged back to memory and to the recommendation scorer that grades agents against eventual market outcomes.
Hallucination resistance
A multi-agent LLM system is a hallucination amplifier if it isn't built carefully. Our defenses are layered. Tools are real - NewsData.io, Serper, the Polymarket CLOB and Gamma APIs - and the data-preparation stage writes deterministic CSV and JSON to /tmp so any agent quoting numbers is quoting numbers that exist. Outputs are forced through Zod schemas. The JSON extractor in lib/json-extractor.ts handles markdown code fences, balanced-brace recovery, and falls back to NO_TRADE rather than to a guess. If more than ten of fourteen agents fail to produce valid signals on a given run, the workflow aborts with NO_TRADE and the user is refunded - analysis_deliveries records that they never received the result.
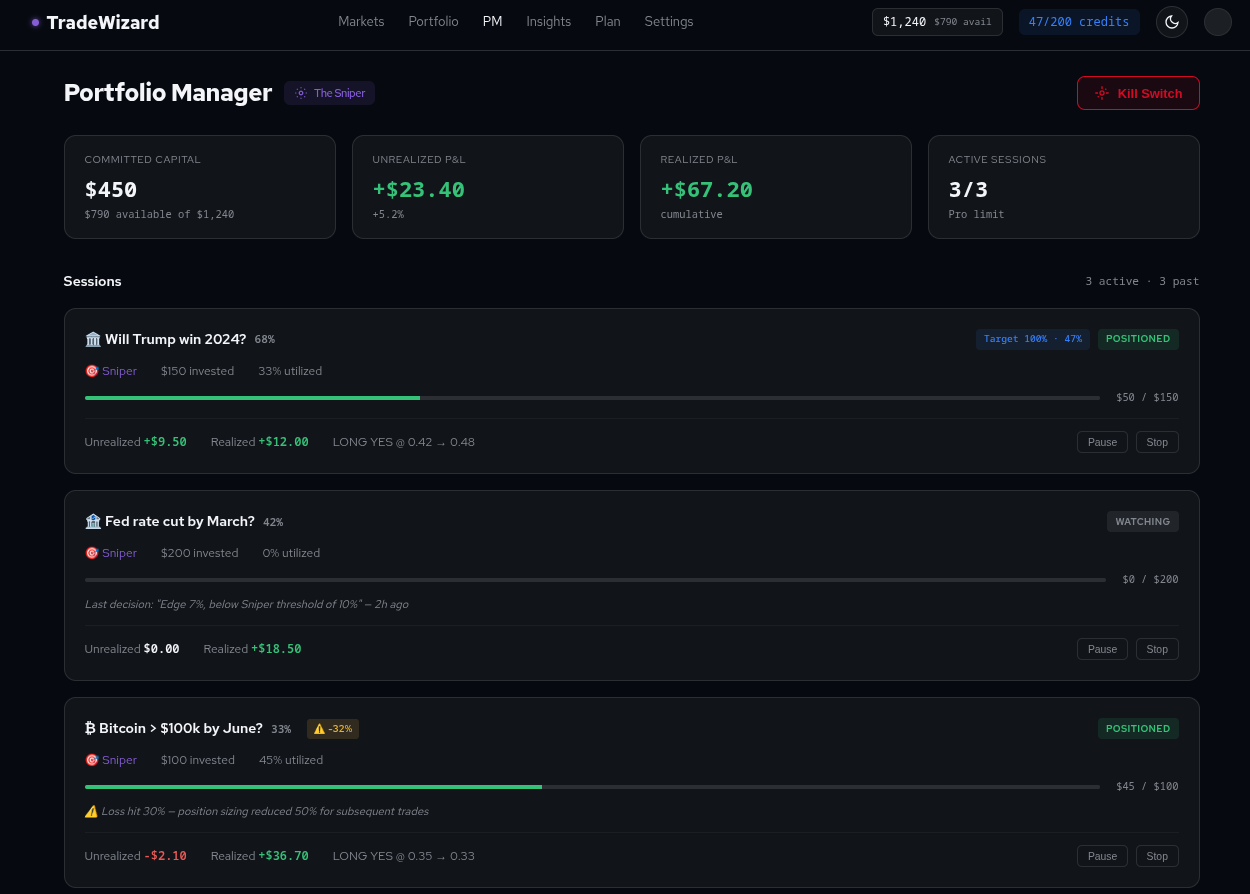
Autonomous Portfolio Manager: bounded autonomy
This is where the critic asks the right question: how does an autonomous trade executor coexist with "the user is the final decision maker"? Our answer is that the autonomy is bounded by an Investment Policy that the user explicitly signs at activation, encoded as hard, machine-checked invariants.
When a user activates the Portfolio Manager on a market, the activation handler validates the prerequisites: subscription tier, concurrent session quota, recurring analysis present on that market, sufficient wallet balance, persona selected. The user provides three things the Lambda cannot change: the market, the capital envelope, and the persona. Everything else flows from those choices.
The decision Lambda is intentionally read-only at the tool layer. Its tools fetch market data, the order book, full analysis, trade history, session performance, and agent accuracy. It does not have a "place order" tool. Its output is a structured decision; the Trade Executor service validates that decision against hard limits and only then calls the CLOB. This split - the agent decides, a separate service enforces - is what lets us reason about safety properties.
The hard limits are concrete and enforced in code, not in prompts:
- Mandatory stop-loss and take-profit on every position. A trade is rejected at the executor level if SL or TP is missing or out of bounds.
- Per-session loss limit at 50% of capital, cross-session at 40%. Hitting either terminates the offending session or trips the kill switch.
- 30-minute cooldown after a loss exit. Re-entry attempts are blocked at the executor.
- Position size cap at 50% of session capital. Concentration is bounded.
- Concurrent session limits: 3 for Pro, 10 for Elite.
- Capital conservation invariant. No trade can be sized above what the session has uninvested. The executor checks this before submission.
- Mutual exclusion between Trade Executor and Position Guard. The Guard can decide to exit, the Executor can decide to enter, but the pair cannot act on the same position simultaneously. This eliminates a class of double-action races.
- Token-ID resolution by outcome string, never by array index. The CLOB does not guarantee outcome ordering, and indexing by position is the kind of bug that puts a YES order on a NO token. We resolve by matching the outcome field explicitly.
- Kill switch totality. The kill switch immediately exits all positions and terminates all sessions. It fails closed: if any check inside the switch errors, the system errs on the side of stopping. Re-activation requires explicit user action.
The autonomy is real, but the perimeter is auditable. The user has not handed over their wallet. They have authorized a specific capital envelope on a specific market under a specific persona, and the system cannot exceed that envelope by design. If the market resolves, capital depletes, the user's subscription downgrades, the user cancels the underlying recurring analysis, or the kill switch fires, the lifecycle handler tears the session down cleanly. Every state change emits a notification across the user's enabled channels.
What happens when a recommendation is wrong
This is the question critics should ask first. A system that only describes its successes is not a system anyone should trust with money. TradeWizard is designed around the assumption that recommendations will be wrong - regularly - and the architecture's job is to contain the damage, learn from it, and get less wrong over time.
At the intelligence layer: scoring, demotion, and memory correction
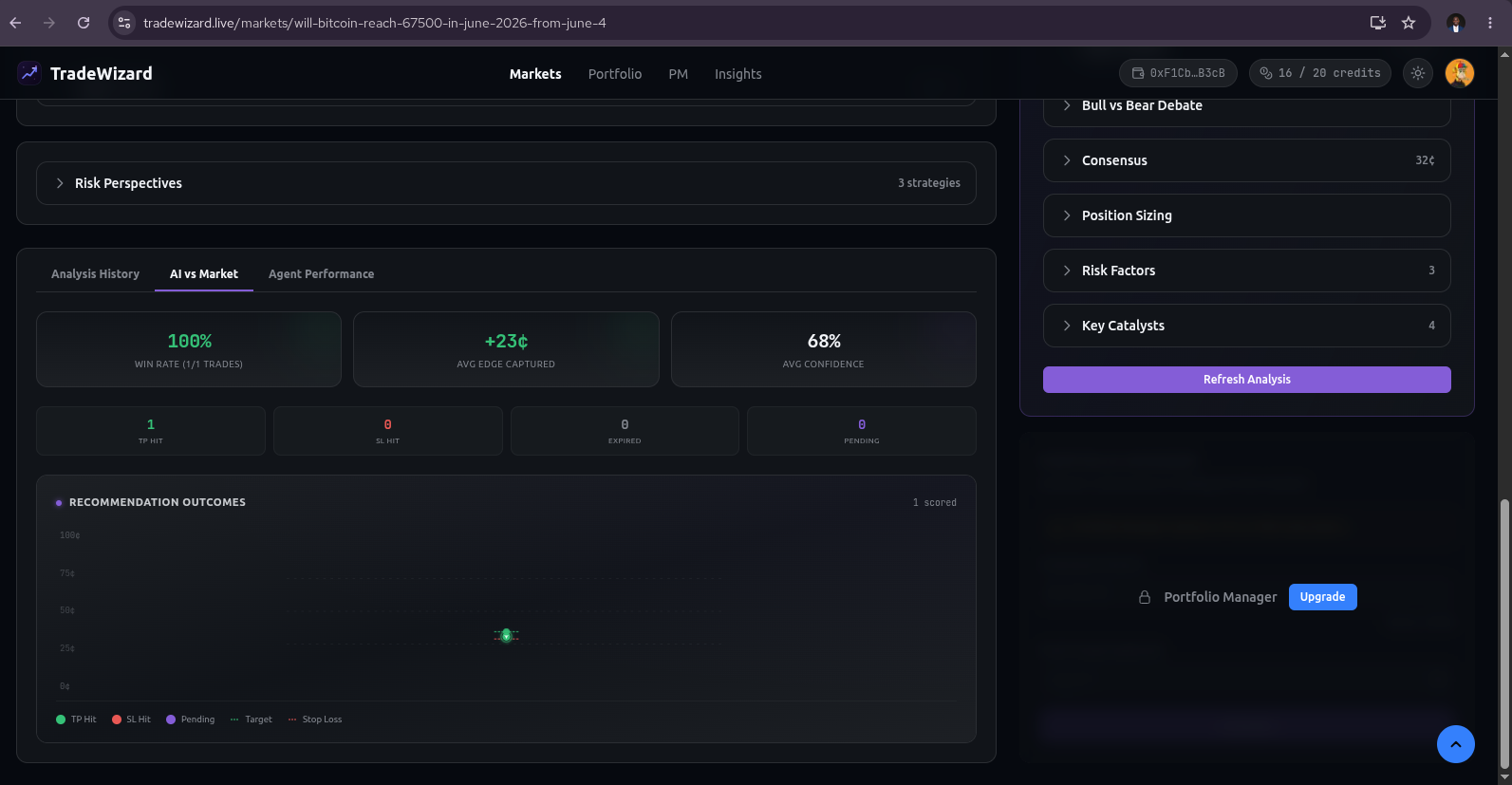
Every recommendation that carries a trade action (LONG_YES or LONG_NO) enters a pending outcome state in the analysis_results table. A Recommendation Scorer Lambda runs every five minutes via EventBridge Scheduler. It fetches the current YES-token midpoint price from the Polymarket Gamma API for each pending recommendation and checks whether the target price (take-profit) or the stop-loss price has been hit.
Three outcomes are possible:
- Target hit (success). The price reached the recommendation's take-profit zone. The recommendation is marked
outcome_status = 'success'. - Stop-loss hit (failure). The price fell through the stop-loss zone. The recommendation is marked
outcome_status = 'failure'. - Expired. After a configurable window (default 7 days), neither TP nor SL was hit. The recommendation is marked
expired- no agent scoring occurs because the market gave no clear verdict.
When a recommendation is marked failure, agent scoring kicks in. Every agent that contributed a signal to that analysis is evaluated:
- Aligned agents - those whose direction matched the failed recommendation (e.g., direction = YES on a LONG_YES that hit stop-loss) - receive
+1 incorrecton theiragent_performancerecord. - Dissenting agents - those who signaled against the recommendation - receive
+1 correct. They were right to dissent. - Neutral agents are excluded from scoring entirely. Taking no side earns no credit and no blame.
This is not a cosmetic leaderboard. The accuracy data feeds directly back into the next analysis through fetchAgentPerformanceWeights, which runs at the start of every workflow. The function queries per-market accuracy first (minimum 2 scored signals per agent, at least 3 agents qualified), falling back to global accuracy over the last 30 days if per-market data is insufficient.
The weight formula normalizes accuracy into a 0.5–2.0 range:
- An agent at 0% accuracy gets weight 0.5 (half influence on signal fusion).
- An agent at 50% accuracy gets weight 1.0 (neutral - no bonus, no penalty).
- An agent at 100% accuracy gets weight 2.0 (double influence).
This means a consistently wrong agent doesn't just appear lower on a dashboard - it is mathematically demoted in real time. Its fair-probability estimate counts for half as much in the weighted fusion. Conversely, an agent that dissented correctly across multiple failed recommendations rises in influence. The system self-corrects toward the agents that were right when it mattered.
If insufficient performance data exists (cold start, new market category), all agents fall back to the default weight of 1.0 - the system does not hallucinate confidence in its own track record.
At the Portfolio Manager layer: mechanical damage containment
When the PM enters a trade that goes wrong, the containment is not probabilistic - it's mechanical.
Stop-loss fires. Every position has a mandatory stop-loss order placed at the CLOB at entry time. This is not a trailing stop managed by the Lambda - it is a resting order on the exchange that executes regardless of whether our infrastructure is available. If our Lambda goes down, the stop-loss still fires. The order is placed by the Trade Executor only after confirming the SL price is present and within bounds. If both SL and TP order placement fail after the initial BUY, the BUY is cancelled entirely to prevent an unprotected position.
Cooldown activates. When a position exits at a loss, the session records last_loss_exit_at. On the next analysis-complete event, the Trade Executor checks this timestamp against the 30-minute cooldown (LOSS_EXIT_COOLDOWN_MINUTES). If cooldown is active, the decision is recorded with skipReason: 'cooldown' and no trade is attempted. This prevents tilt - the automated equivalent of revenge trading.
Loss limit approached. At 30% session loss, the Risk Engine fires a warning notification and activates position_size_reduction_active, which halves the maximum position size for subsequent trades. This is not a prompt instruction - it's a flag the Trade Executor reads before sizing.
Loss limit hit. At 50% session loss (maxPct: 0.5), the session is terminated. All pending orders are cancelled, the open position is exited at market price via an emergency exit (aggressive limit order at 5% worse than best bid if market order doesn't fill within 60 seconds), and the session transitions to terminated with termination reason risk_limit.
Cross-session loss limit. If cumulative losses across all sessions for a user cross 40% (crossSessionPct: 0.4), the kill switch fires automatically. This is not the user pressing a button - the Risk Engine trips it programmatically. All sessions are terminated, all positions are exited, and the kill switch state is persisted in DynamoDB. The user must explicitly reset it to trade again.
Kill switch fail-closed semantics. If any step inside the kill-switch execution errors (e.g., the CLOB API is unreachable during exit), the system errs on the side of stopping - it does not retry and continue trading. Sessions are marked terminated regardless. Positions left un-exited are flagged for manual review and the user is notified. API unreachability (3 consecutive failures) independently triggers a pause on all activity.
What the user sees
When a recommendation fails:
- The analysis result in their history updates from
pendingtofailurewith the price at which stop-loss was hit. - The agent accuracy leaderboard updates - the agents that were wrong are visibly demoted, the dissenters are promoted.
- If they had the Portfolio Manager active on that market, they receive a multi-channel notification (WebSocket + email/push/webhook per preferences) with the exit price, the loss amount, and the cooldown window.
- Their session dashboard updates in real time with the loss reflected in P&L.
- If the loss tripped a limit, they receive a separate risk-event notification explaining what happened and what was stopped.
The user is never in the dark about a wrong recommendation. The system treats failure as a first-class event with its own notification path, its own scoring path, and its own mechanical response. The goal is not to never be wrong - that's impossible in probabilistic markets - but to be wrong in a way that is bounded, visible, and self-correcting.
Cost and operational shape
The market-level analysis pool is the single most consequential design choice for unit economics. Analysis is one-per-market-per-hour minimum, deduped through DynamoDB with a 1-hour TTL. Per-user delivery is tracked in Aurora's analysis_deliveries table. Users pay one credit when they receive an analysis they haven't seen before, and never twice for the same one. Recurring schedules from many users on the same market coalesce to the shortest active interval. At meaningful scale, this turns ten thousand users requesting the same popular market into one Bedrock execution while still collecting ten thousand credits of attribution. We designed it that way deliberately because the failure mode of naive per-user execution is bankruptcy.
The same shape extends to delivery. SNS topic fan-out triggers WebSocket, email, push, and webhook Lambdas in parallel, each respecting quiet hours, notification preferences, and plan-based channel availability. Stale WebSocket connections are cleaned up on 410 Gone. SQS DLQ handles failed dispatches with three retries and exponential backoff, and any failure refunds all subscribers - not just the requesting user - because under coalescing, a failed analysis affected everyone.
Challenges we ran into
The autonomy paradox. "Human is the final decision maker" and "autonomous trade execution" sound contradictory. We spent serious time landing on the right framing: bounded autonomy, with the boundary expressed as machine-checked invariants the user pre-authorizes at activation. The breakthrough was separating the agent's decision authority from the executor's enforcement authority, and treating the kill switch as a fail-closed totality rather than a feature.
LLM determinism is a fantasy; pipeline determinism is achievable. Early prototypes tried to make the model behave consistently. That never worked at the tail. The fix was to stop asking the model to be deterministic and instead bracket it with deterministic stages - signal fusion, consensus, EV check, schema validation, divergence threshold. The LLM produces signals; the pipeline decides what to do with them.
Agreement is not consensus. When all 14 agents agree, that's frequently a sign they're all looking at the same news item, not that the market is clear. Our first version under-weighted divergence. We added the divergence penalty and the 30% disagreement gate, and we made each agent see only its own history to break cross-agent anchoring. Counter-intuitively, the system became more useful once we let it refuse to answer.
Cost runaway under naive deduplication. Initial designs cached per user, which is the same as not caching. The market-level pool with shared coalescing is the fix, but it forced us to redesign delivery accounting end-to-end so users pay only when they receive a result they haven't seen.
Token ID and outcome ordering on the CLOB. Outcome arrays are not stably ordered. A trade-executor that indexes YES at [0] will eventually place a YES position on a NO token. We rewrote the resolver to match by outcome string and added a regression test.
Mandatory SL/TP and the cost of a missing exit. Position sizing is the cheap part of execution. Exits are expensive. We made stop-loss and take-profit mandatory at the executor layer rather than at the prompt layer, because prompts are persuasive and executors are not.
Graceful degradation without lying. Partial agent failure must not crash the pipeline, but it also must not pretend everything is fine. We landed on: degrade the run, surface what failed, and abort to NO_TRADE if the failed share crosses a threshold. Refund the credit. The user is told a failure happened.
Accomplishments that we're proud of
- A multi-agent system that is allowed to refuse. When disagreement is above 30% or expected value is non-positive, TradeWizard returns
NO_TRADEwith a structured explanation and does not bill the user. Most "AI trading" products are constitutionally incapable of saying "we don't know." Ours is built around it. - Three deterministic gates around the LLMs. Signal fusion and the consensus engine are non-LLM stages. Schema validation and EV rejection are non-LLM stages. The model's job is to produce signals; the pipeline's job is to decide whether anything happens.
- Bounded-autonomy execution. A kill switch that fails closed, mandatory SL/TP, hard loss limits, cross-session caps, cooldowns, capital conservation, mutual exclusion between executor and guard, and token-ID resolution by outcome. The Portfolio Manager's perimeter is small and provable.
- A market-level analysis pool with per-user delivery accounting. Costs scale with markets analyzed, not with users requesting. Users only pay for analyses they actually receive, exactly once.
- Closed-loop learning. Every recommendation is scored against eventual recommendation resolution. Every agent has a leaderboard. Memory feeds back into signal weighting. The system gets better with every recommendation that resolves, not just with model upgrades.
- An AWS-native platform that runs at fifteen to twenty dollars a month at idle. No NAT, no ElastiCache, no always-on compute. Aurora Serverless v2 scales to 0.5 ACU. The architecture rewards growth instead of punishing it.
- Multi-channel delivery that respects user preferences. WebSocket, email, push, webhook - each with quiet hours, thresholds, and plan-based gating. Kill-switch and loss-warning events override quiet hours because some events are too important to wait.
- End-to-end TypeScript, multi-model Bedrock. One language across CDK, Lambdas, Strands agents, and frontend. Seven foundation models on Bedrock distributed by capability - no single model bottleneck, no Python runtime in the agent path.
What we learned
- Refusing to recommend is a feature, not a failure mode. The most professional thing a trading system can do under high disagreement is decline. Critics expect AI products to over-recommend; ours under-recommends on purpose, and the design is built to make under-recommending easy.
- Independence beats agreement at the agent layer. Cross-agent history made our agents more confident and less informative. Per-agent isolated memory made disagreement signal-bearing.
- The right place to enforce safety is below the LLM, not inside it. Prompts that say "always set a stop-loss" will eventually be ignored. Executors that reject any trade missing a stop-loss never will.
- Dedup is product strategy, not infrastructure. A market-level pool reshapes unit economics; the credit-and-delivery model has to be built around it from the start, not bolted on.
- Explainability is a UI feature first and a regulatory feature second. Reasoning chains, debate scores, agent leaderboards, and disagreement indices make users trust the output. They also make the system defensible if the output is ever questioned.
- You can't separate analysis from execution and call the job done. The hard part of retail trading is the gap between the recommendation and the trade. The Portfolio Manager exists because that gap is where users get hurt.
What's next for TradeWizard
- Model performance benchmarking. Multi-model routing is live across 7 models. The next step is systematic quality and cost benchmarking per agent-category, with automated routing updates when a model's price-to-quality ratio shifts.
- Agent specialization and ablation. Now that we have a leaderboard with real outcome data, we can systematically retire under-performing agents, split high-performing ones into more specialized variants, and run A/B comparisons with statistical rigor.
- Verticals beyond politics. The architecture is event-agnostic. Macro and central-bank decisions are next, then sports and entertainment. Each new domain inherits the same workflow with domain-specific tools.
- Institutional surface. A research-grade API for hedge funds and political-risk firms, with audit logs, signed reasoning chains, and SLA-backed delivery. The intelligence layer is already explainable enough; the work is packaging.
- Position-aware analysis. Today the analysis is market-aware. The next iteration is portfolio-aware - recommendations conditioned on the user's existing exposure, with correlation-aware sizing and cross-market hedges.
- Persona evolution and Elite customization at depth. Elite users already customize exit sensitivity, monitoring frequency, and position sizing. Next is user-defined persona blends with backtesting on resolved markets.
- Independent audit and public performance reporting. We track recommendation accuracy internally. Publishing it - with methodology - is a moat.
- More guardrails as we learn. Every new failure mode we observe in production becomes a deterministic check in the pipeline, not a prompt instruction. That ratchet is the long-term safety story.
TradeWizard is a product. It's also a system that was designed assuming critics would read every line. The agent league produces signals; the deterministic gates decide what the user sees; the executor enforces what the autonomous Portfolio Manager is allowed to do; the kill switch ends everything if it has to. The user always retains the perimeter - they choose the market, the capital, the persona, and the off switch - and inside that perimeter, an AI hedge fund of fourteen specialists works the problem twenty-four hours a day.
Built With
- amazon-dynamodb
- amazon-ses
- amazon-sns
- aurora-postgresql
- cognito
- lambda
- nextjs
- sqs
- strands

Log in or sign up for Devpost to join the conversation.