-
-
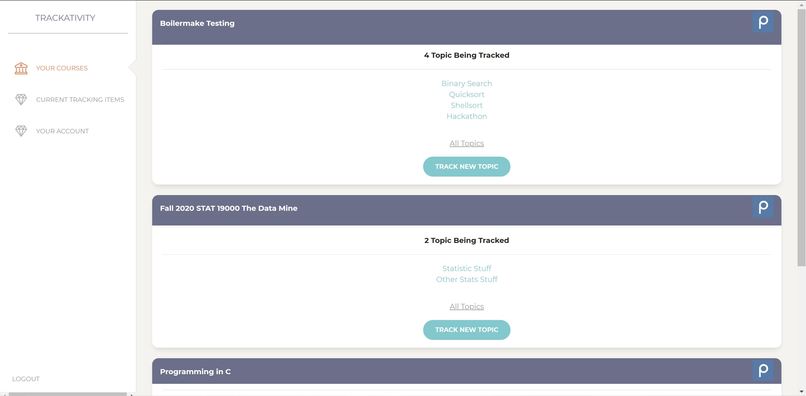
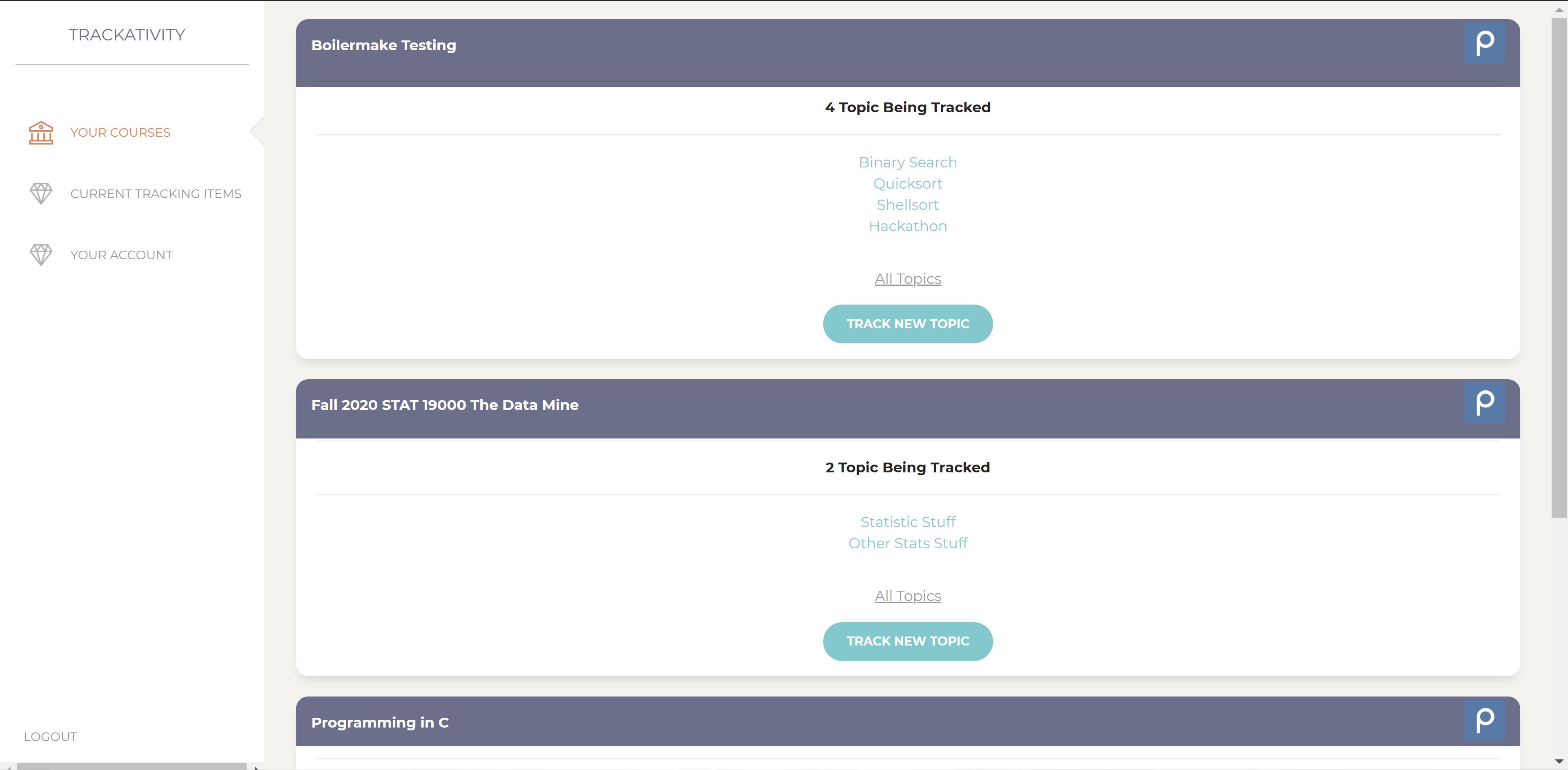
This shows the main course page, where users can view their topics as organized by the courses they belong to.
-
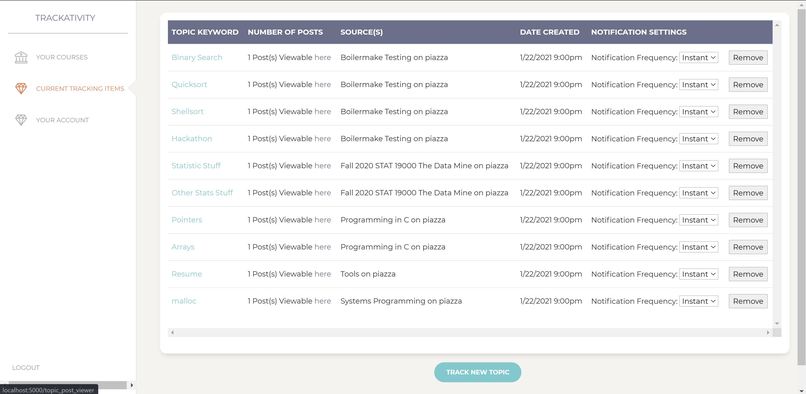
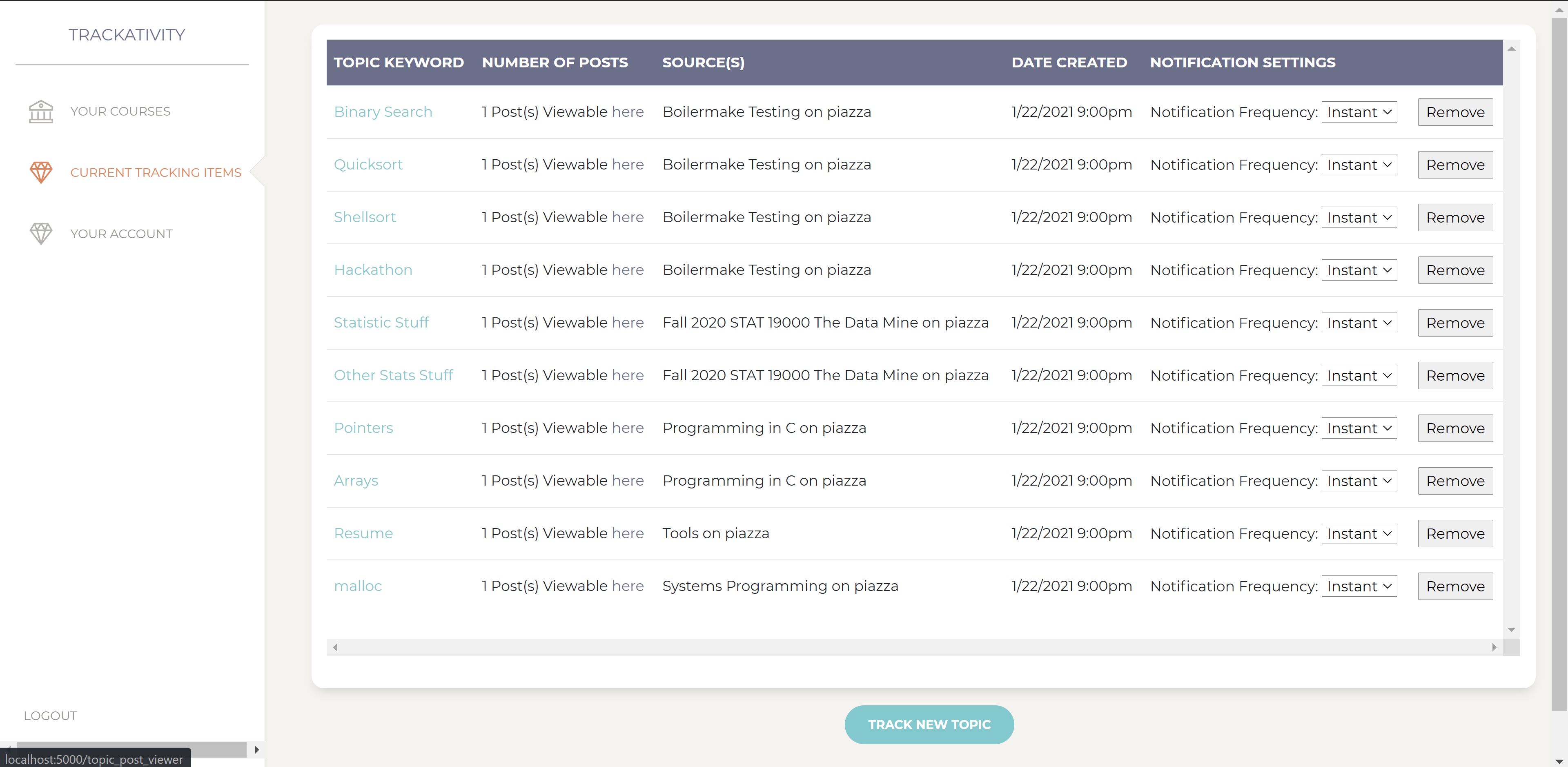
This shows the main topic viewing page, where users can view all of their active topics, as well as remove them.
-
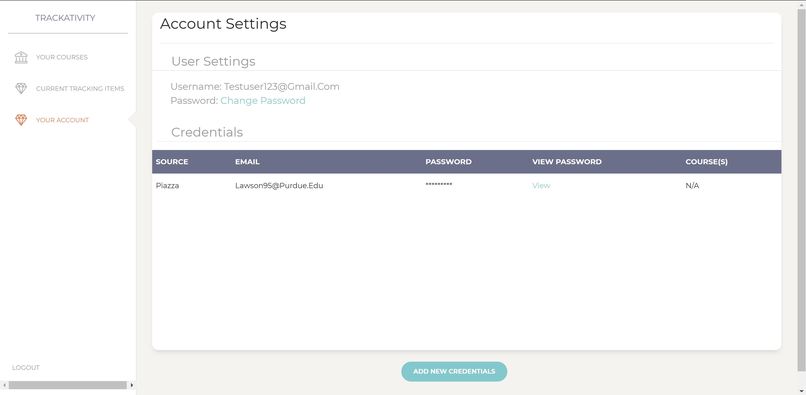
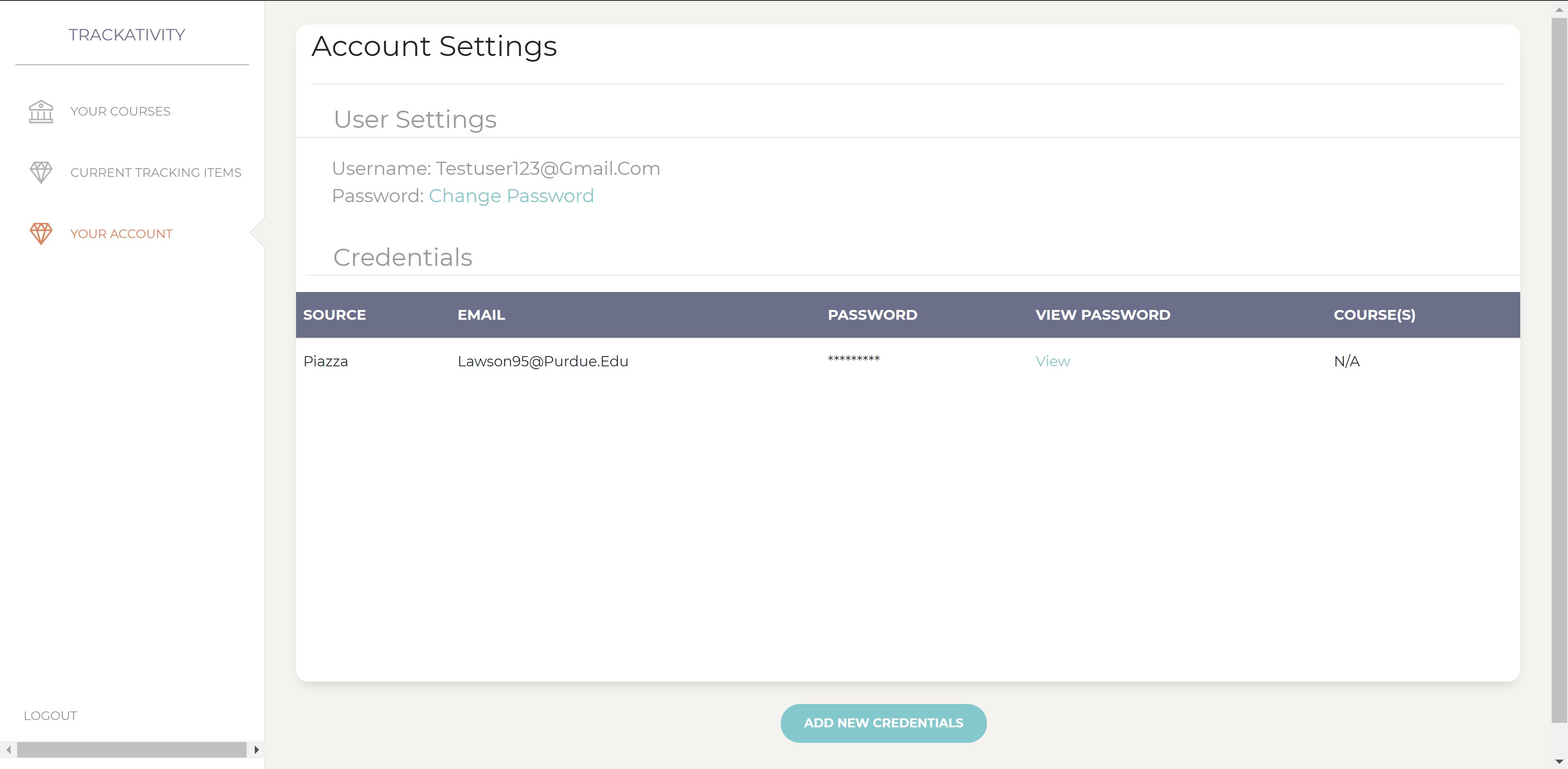
This shows the main account settings page, where users can add and manage credentials for supported websites(currently only Piazza)
-
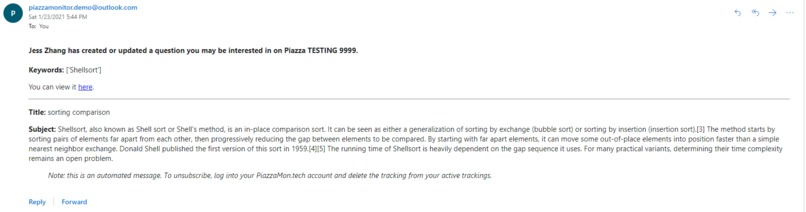
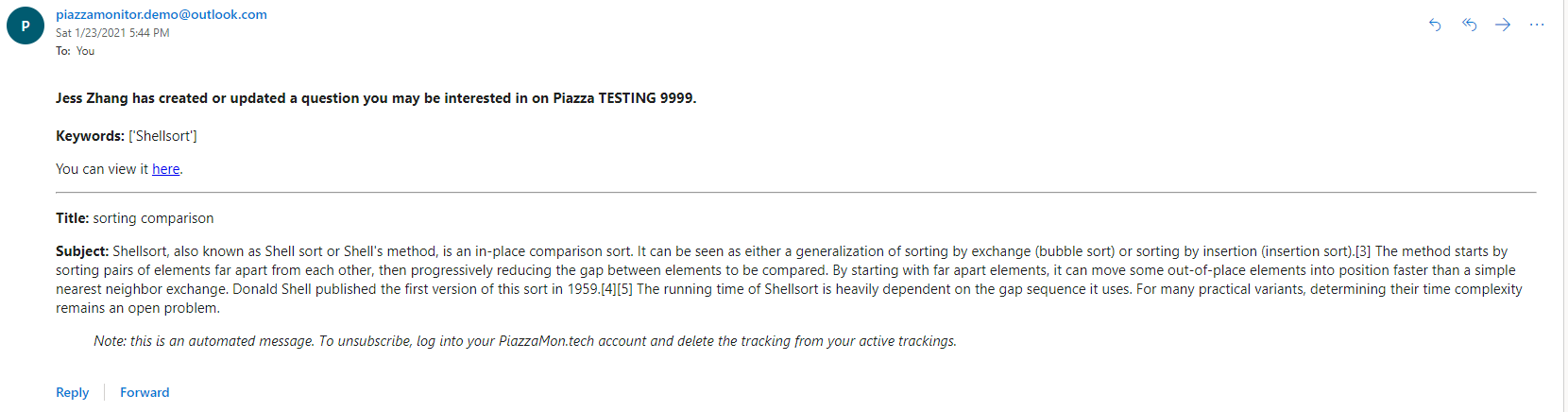
This shows an example of an email that a user might receive to be alterted that there is a new posts that fits one of their topics
-
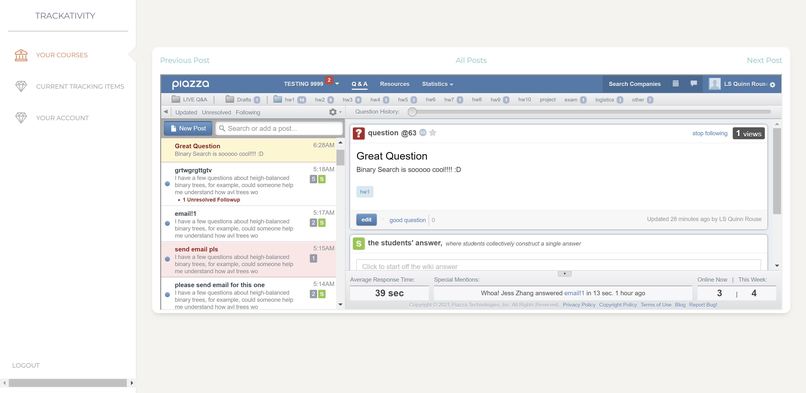
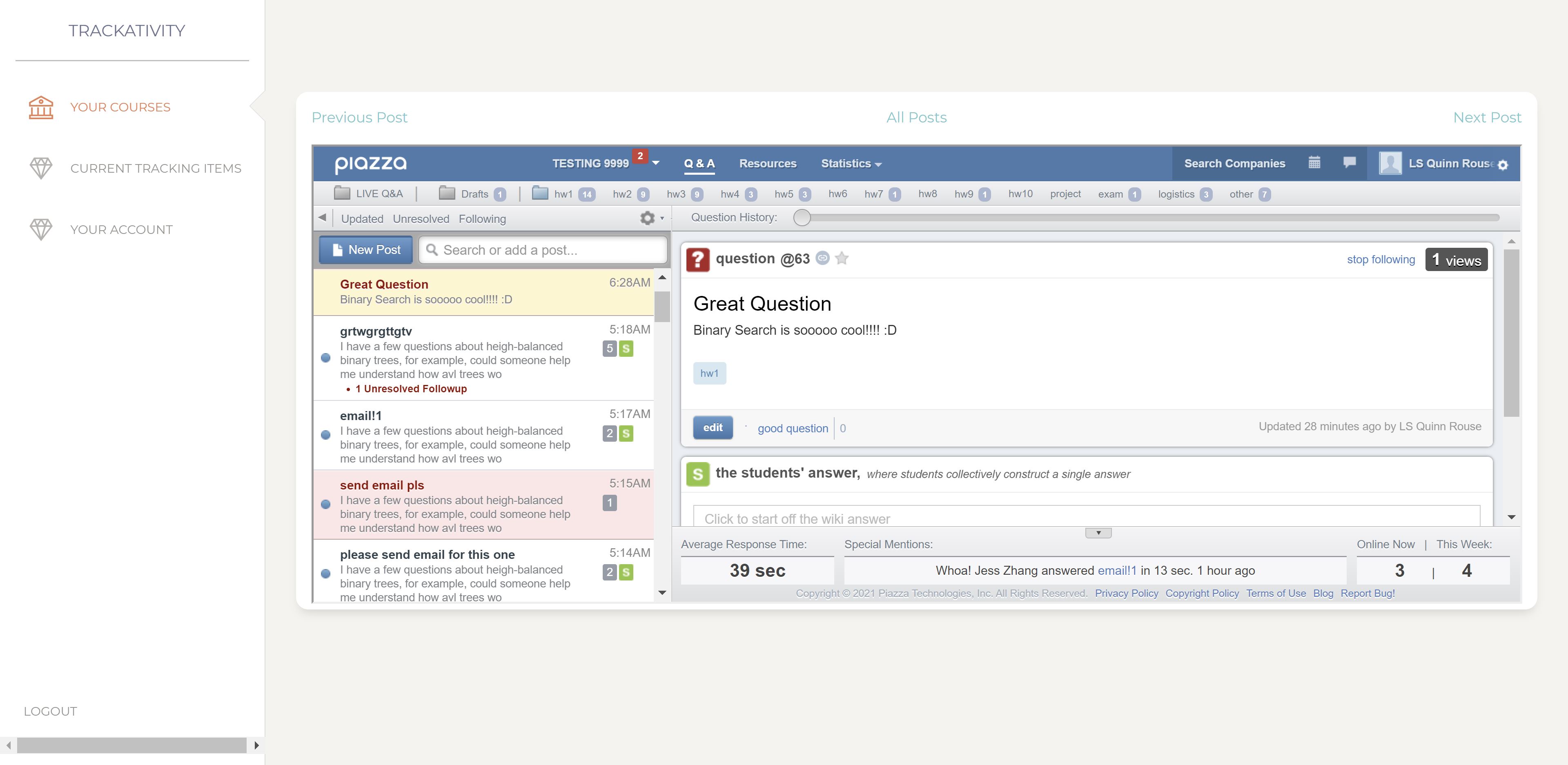
This shows an incomplete feature where users could easily browse posts flagged for one of their topics easily in our website
Inspiration
It is difficult for student's for track and keep up with topics they are interested in tracking on Piazza. Piazza only offers either real-time notification with posts students manually follows or periodic notification about all new posts. We wanted to make something that would help people follow specific keywords or ideas that they would like to be notified on.
What it does
Trackativity is a web-based content monitoring system for discussion forums. Users interested in tracking keywords and topics can sign up for a Trackativity account using their email. To actually access the discussion forums' posts, the user needs to link their discussion forum account to their account for our service. After the user has specified what topics or keywords they would like to be notified on, we will monitor all the new posts in discussion forums and notify the user via email if the new post matches their interest in their preferred interval. The notification email will include a summarized version of the post, as well as a link to that post.
How we built it
The core of our service is running as a Python Flask web server. We manage user information and credentials using MongoDB, and use basic html/css with bootstrap on our website. We further extended a preexisting Piazza library and created a custom websocket that provides real time activity monitoring for any Piazza class. To see if a post contains a query or topic that a user is interested in, we have experimented with and used a variety of natural language processing techniques predominantly using the NLTK library. We have also leveraged the STMP library to send emails to users with a custom HTML rendering engine.
Challenges we ran into
Piazza's API is very hard to use and understand, and there's few documentations available, so we spent way more time than we should to reverse engineer it.
It was also difficult to determine which NLP technique we were interested in using, since most of the team members don't have too much previous experience with NLP. We started off easy with the base model and used basic NLP techniques such as tokenizing, stemming and lemmatization to process the post content. Then we performed keyword matching in the processed text. We wanted to explore more sophisticated models, so we started researching into areas like semantic search, transformer models, topics extraction models. We decided on using the widely used BERT model to improve upon the base model. We used the similarity results between the post and user's keyword to determine if the post is worth sending to our user.
The similarity score was quite unpredictable with the test cases we tried, sometimes it would be high while the keyword and post clearly don't match. We then tried comparing the similarity score between each sentence of the post and the keyword, then taking the average, instead of comparing the similarity score between the whole post and keyword. It slightly improved our model performance. But not significantly. In the end, we relied more on the base model than we did the BERT model. We'd love to keep working on this project and improve upon our BERT model after this hackathon.
It also took a little bit to get the front end working with account authentication.
Alternatively, we have experimented in designing the usage of custom-made libraries to better workflows for
Accomplishments that we're proud of
We have made a custom Piazza client that offers stable websocket connections to any arbitrary Piazza courses. The client is exhaustively documented, designed to be straightforward, and can be published for others to deploy instantly.
While our service currently only supports Piazza, we have created a relatively platform agnostic system that would allow us to track other services such as Campuswire, or even open online discussion platforms such as Reddit or news sites.
What we learned
Most of our project members were new to new development in general, and using flask and mongodb. We have also learned more about websocket programming, nlp, and various other technologies depending on each of our previous skill sets. Most importantly, we learned about rapidly developing and tying together an end-to-end project. We learned how to balance intermittently working independently and then routinely joining together our components to confirm that our service is working.
What's next for Trackativity-Piazza
We plan to extend our service to more platforms, and implement more content analysis techniques such as emotion analysis and more sophisticated deep learning-based topic extraction. We also are interested in finetuning our models with domain specific information. For example, maybe a course instructor could provide a textbook or other resources which we could use to finetune our models for that course.





Log in or sign up for Devpost to join the conversation.