-
-
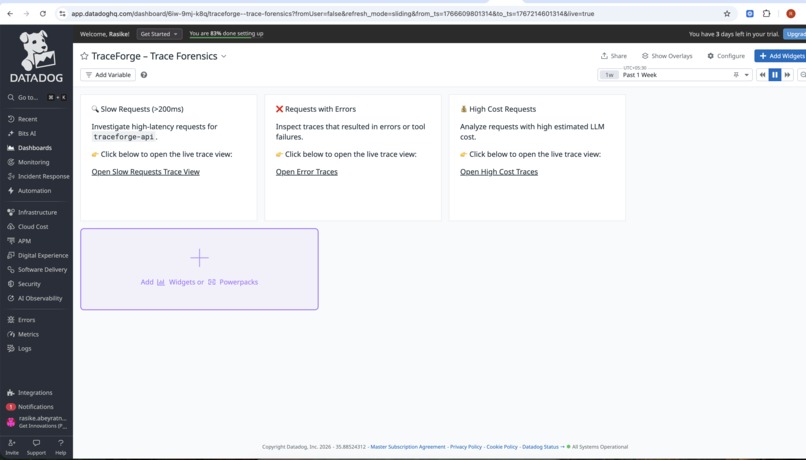
dashboard-4
-
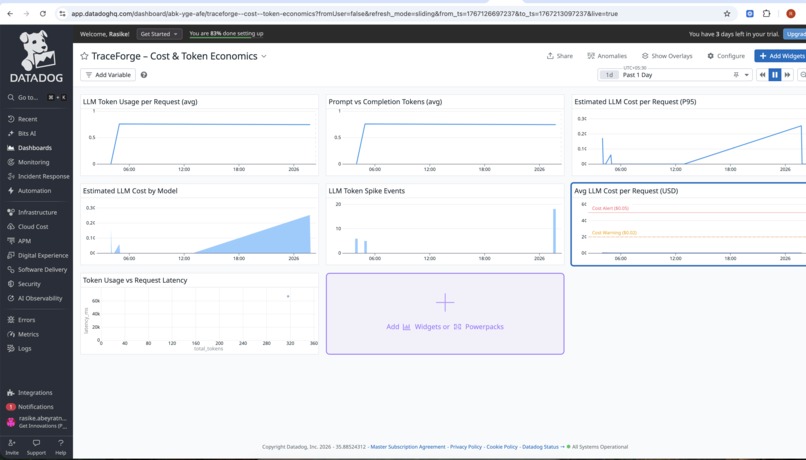
dashboard-2
-
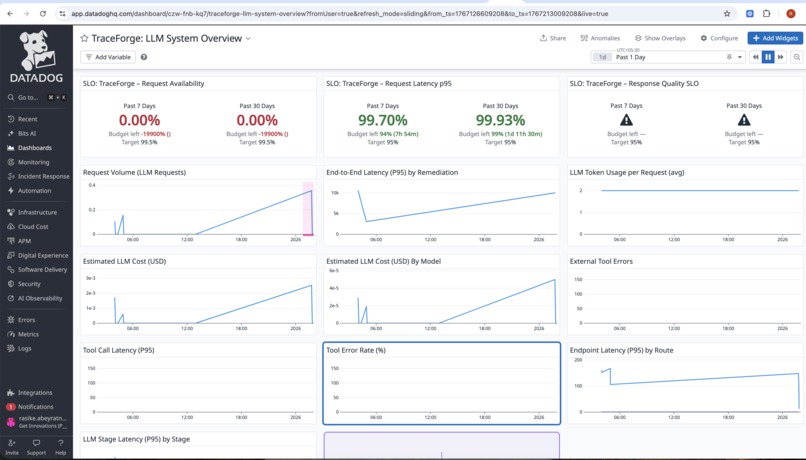
dashboard-1
-
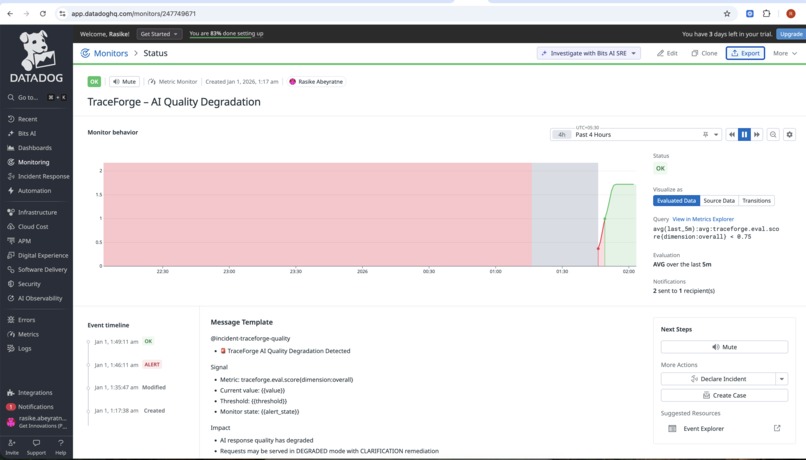
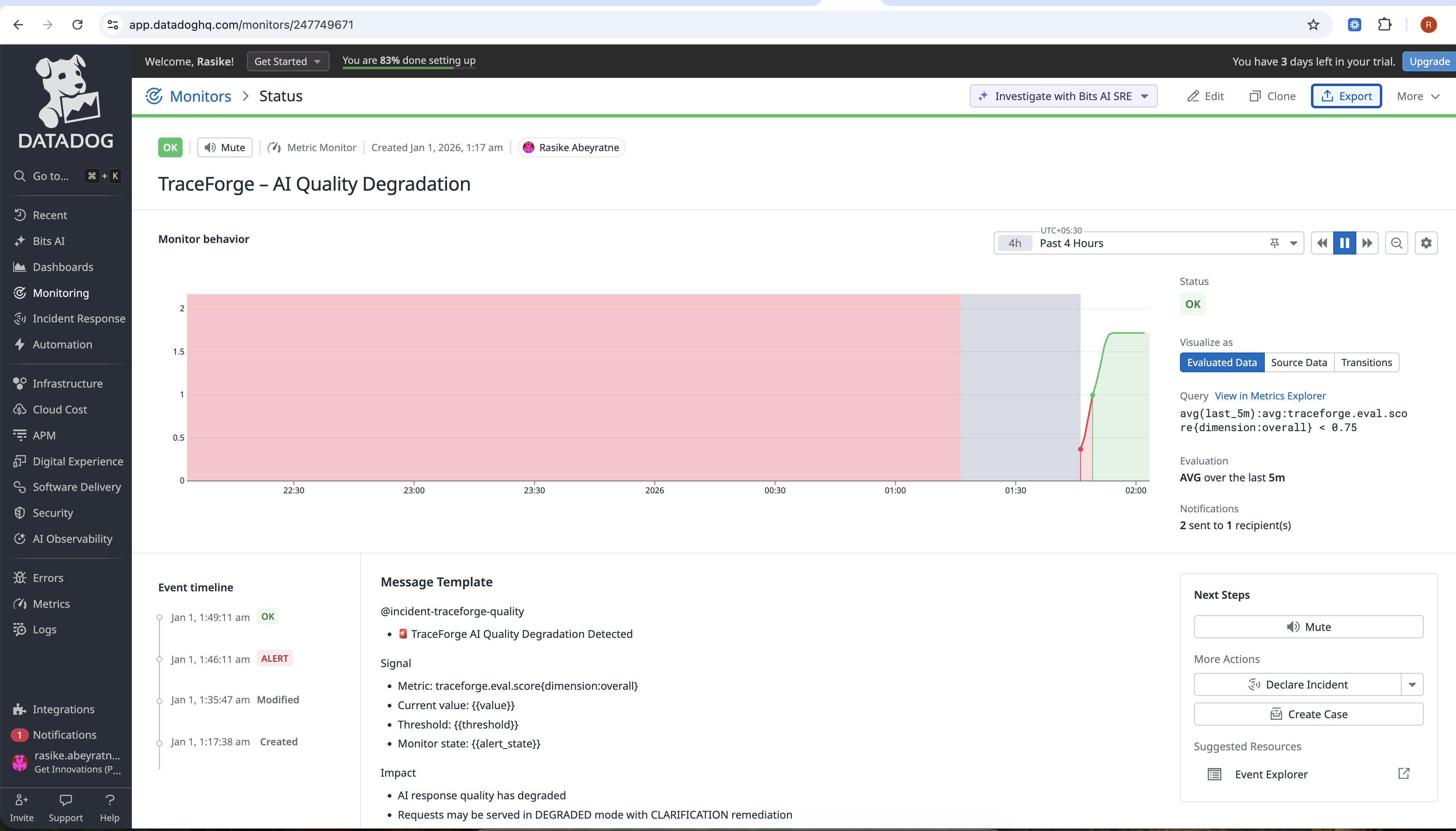
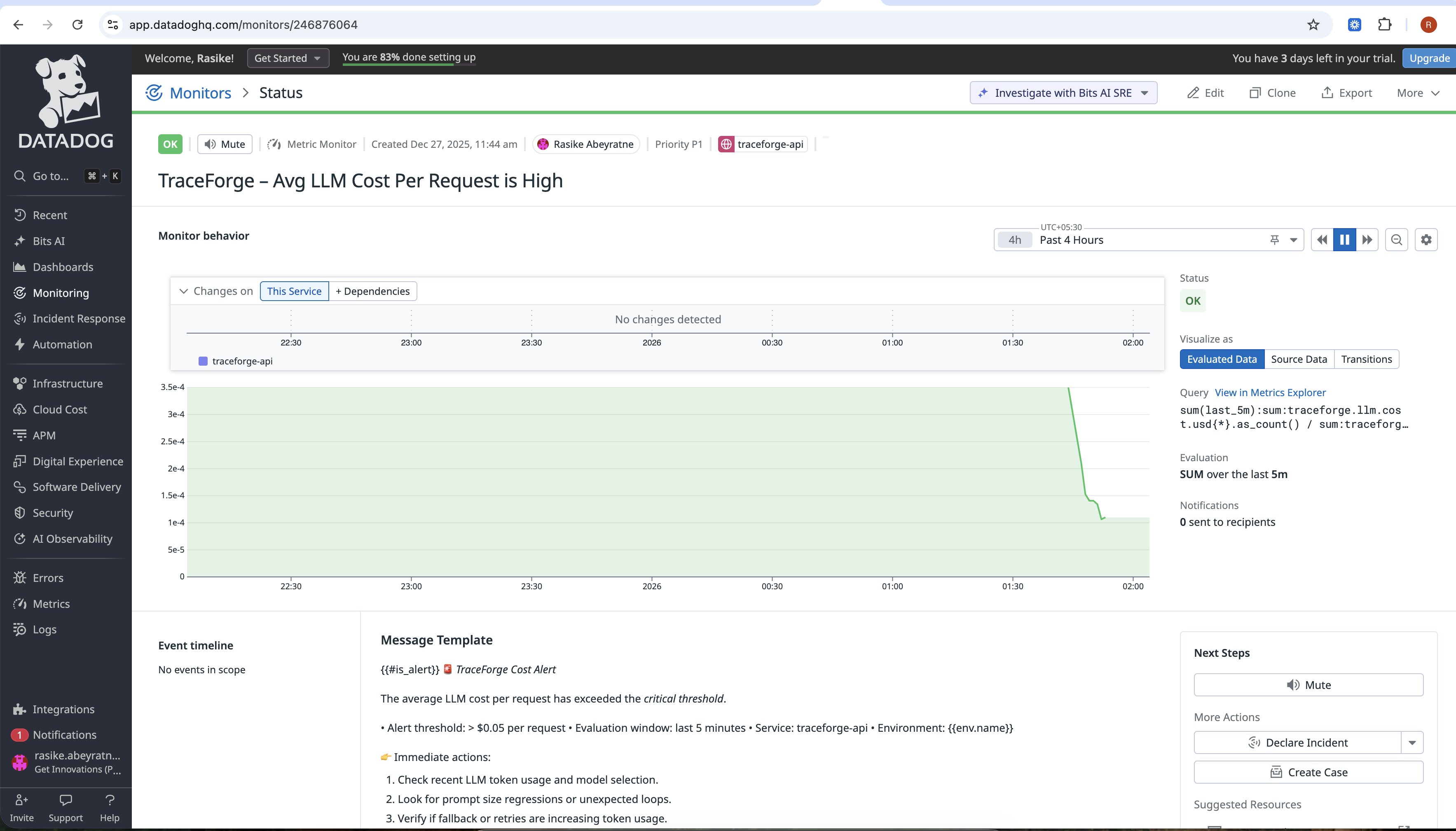
monitors-2
-
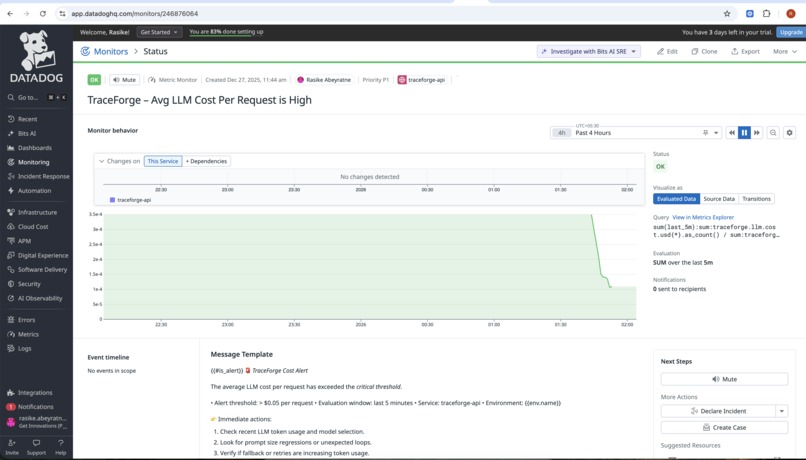
monitors-1
-
dashboards with alert notification in side
-
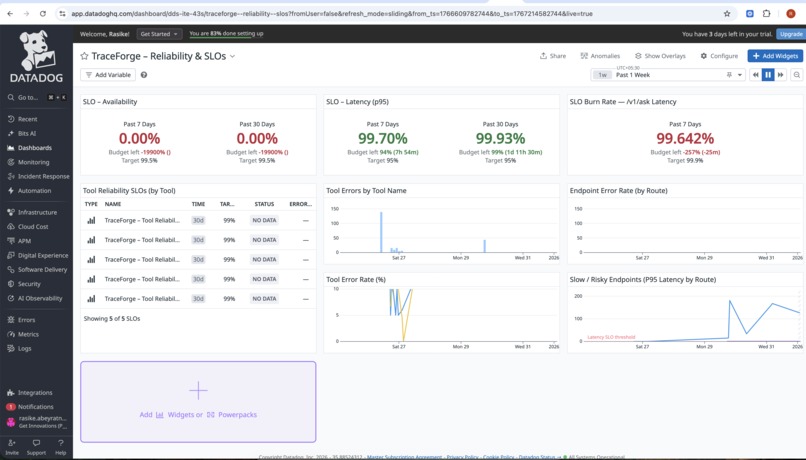
dashboard-3
-
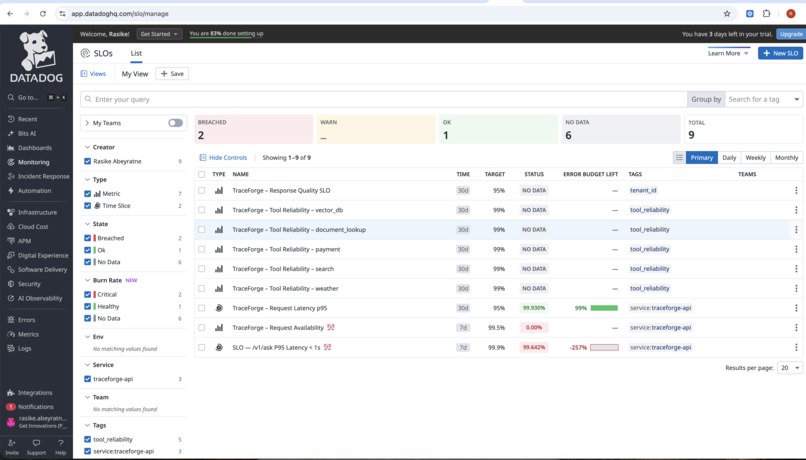
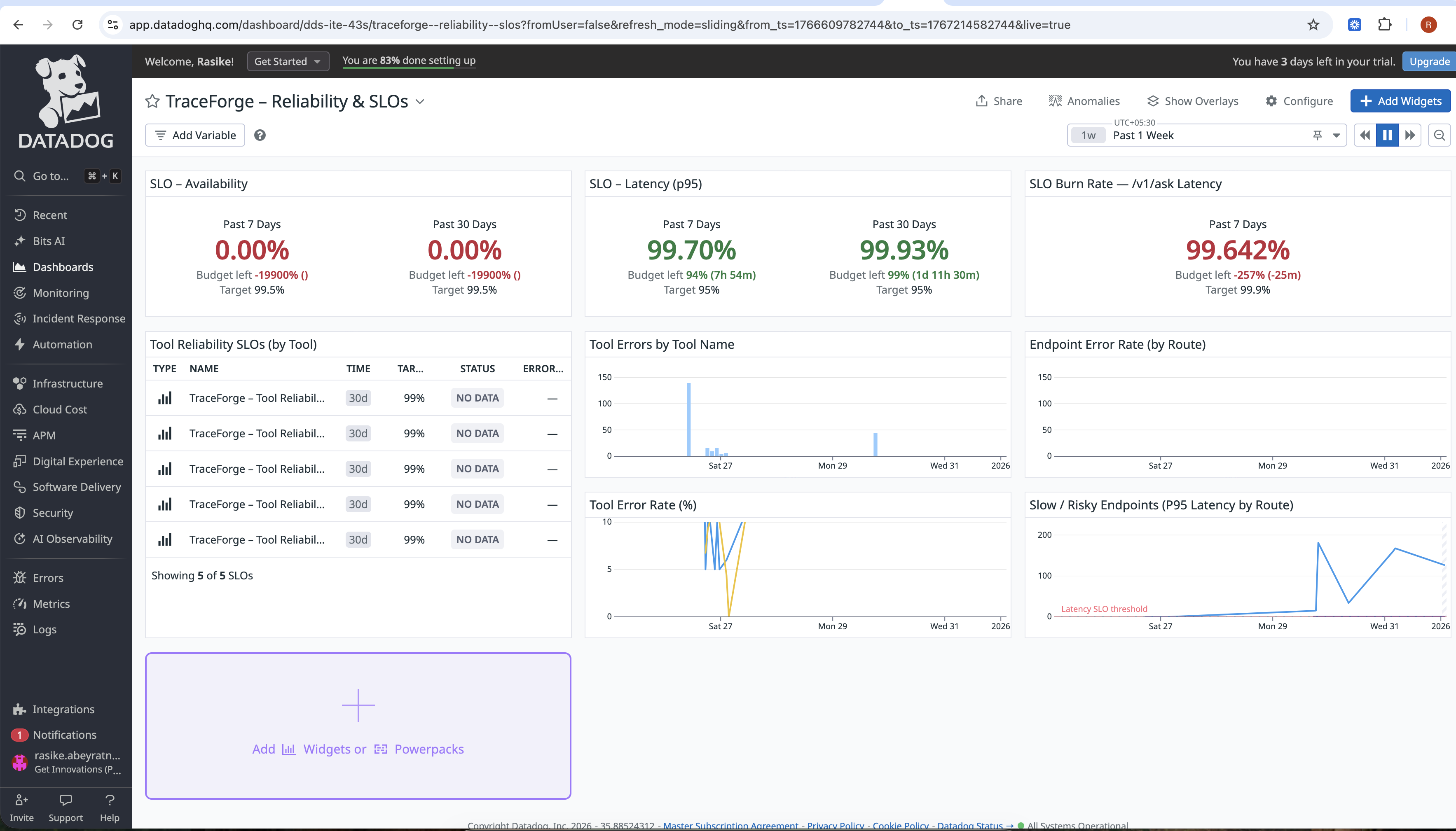
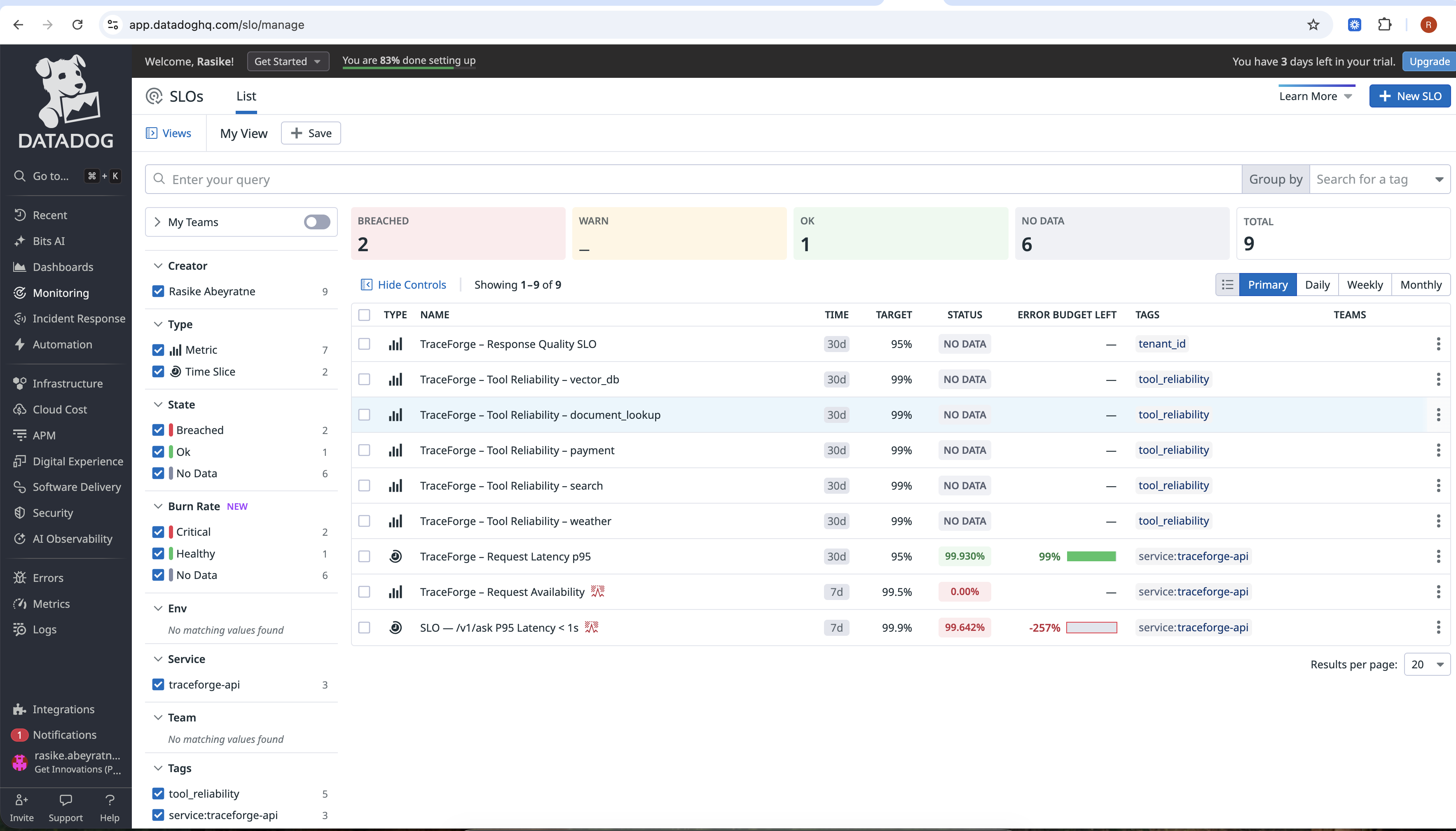
slos
-
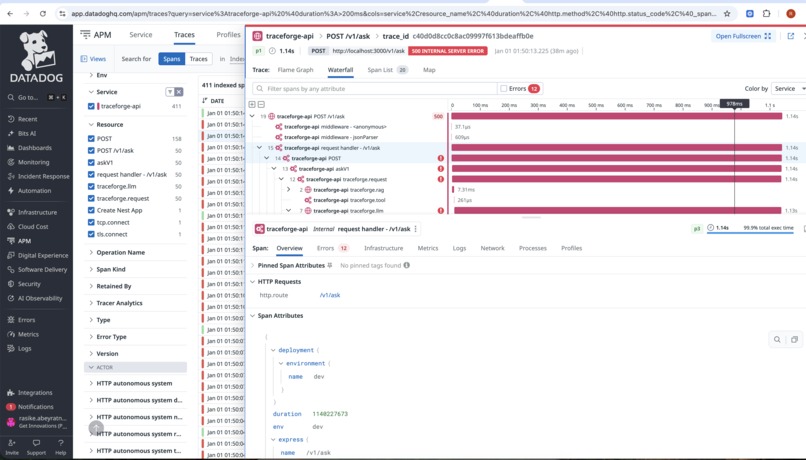
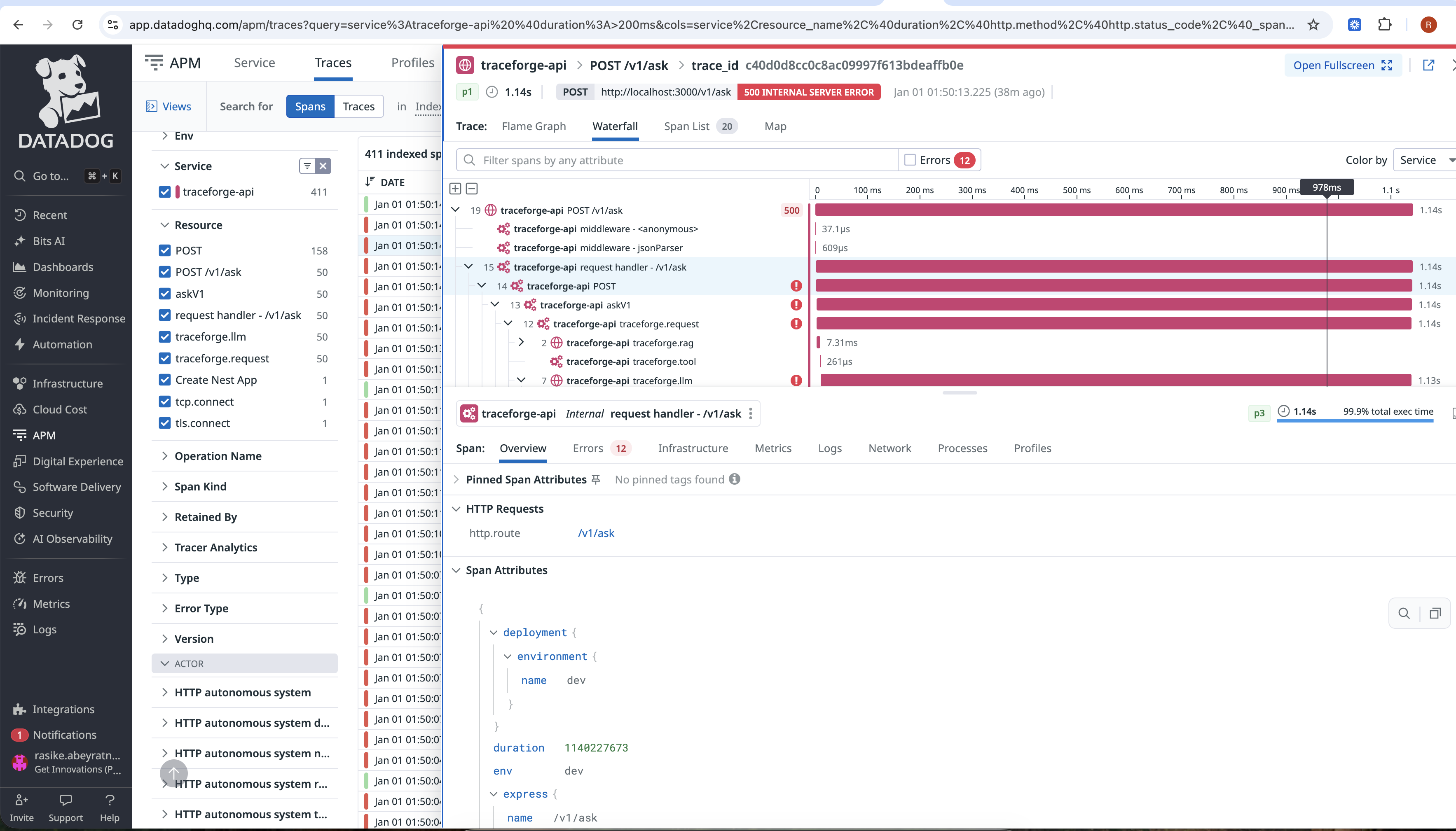
span-details
-
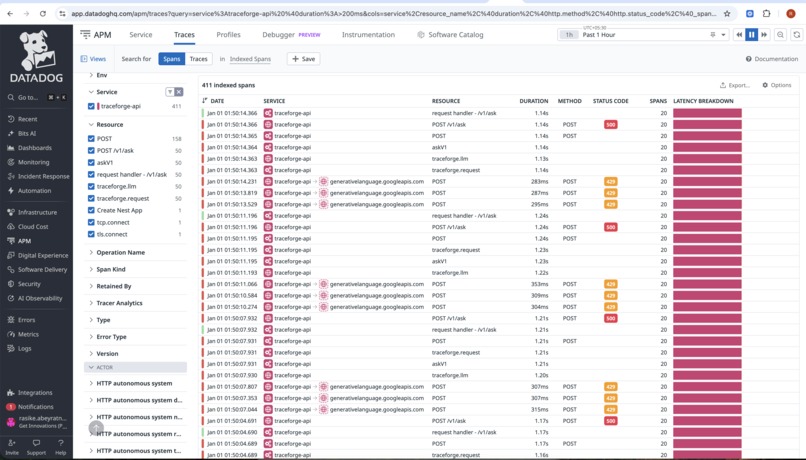
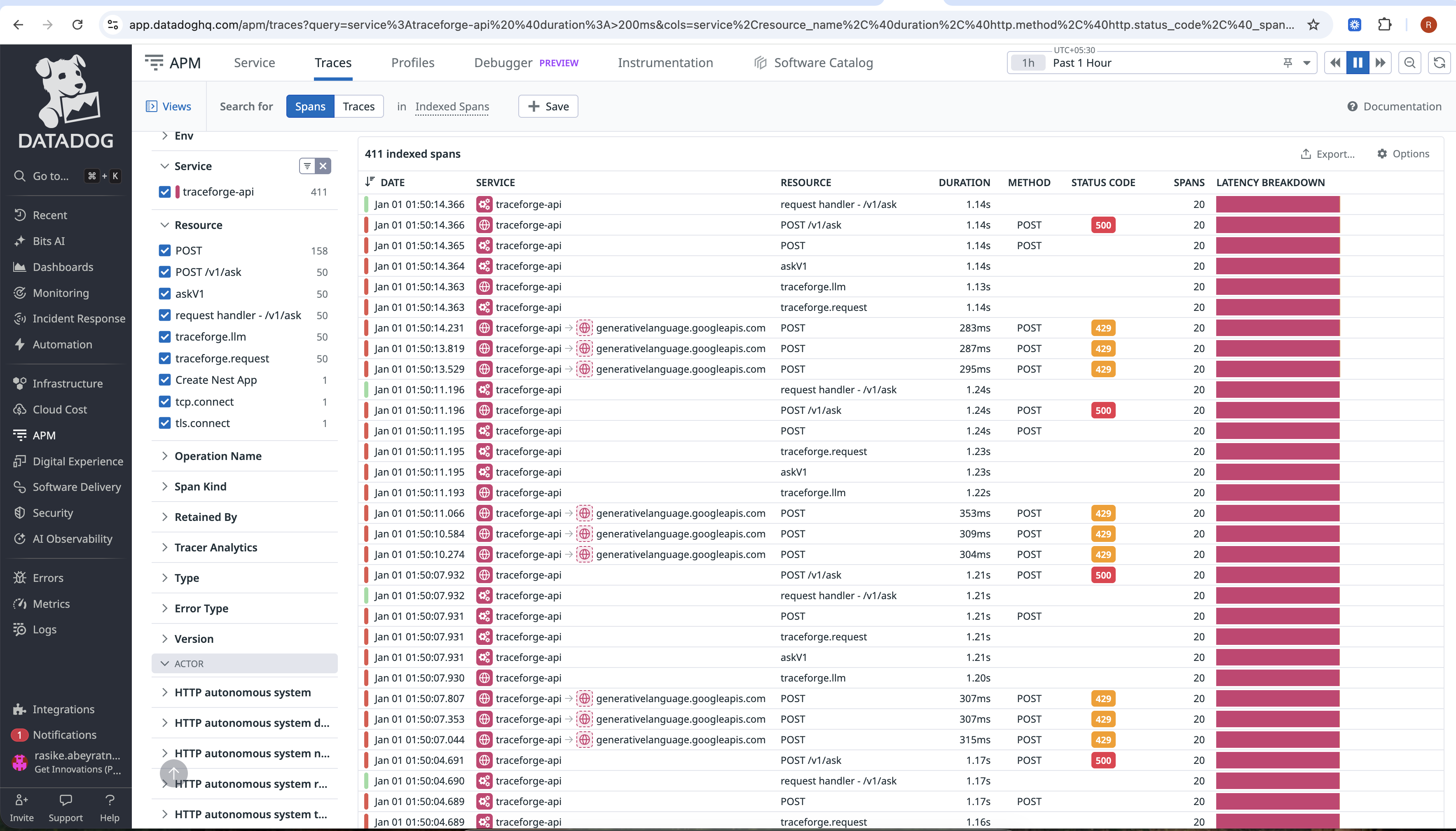
spans
-
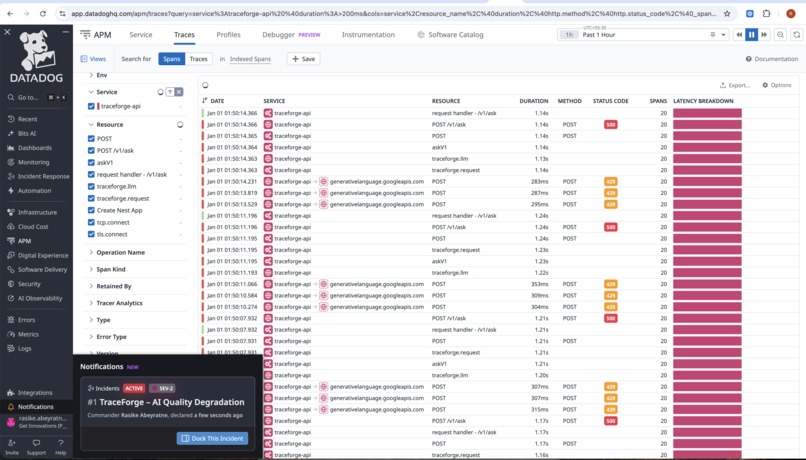
traces
-
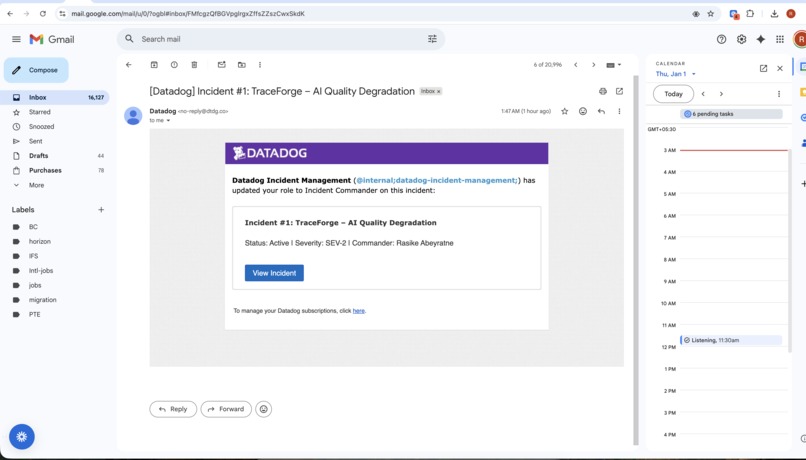
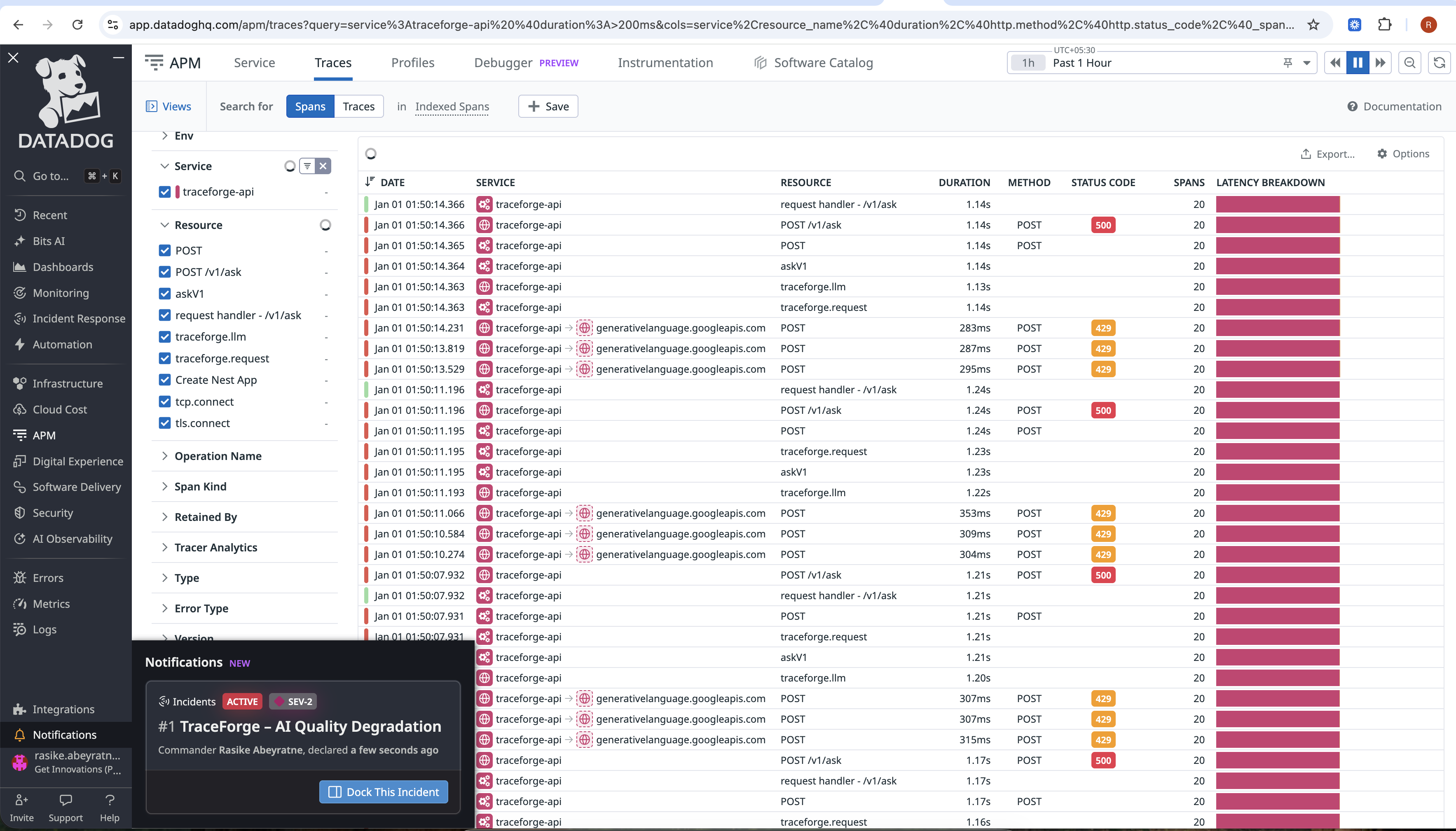
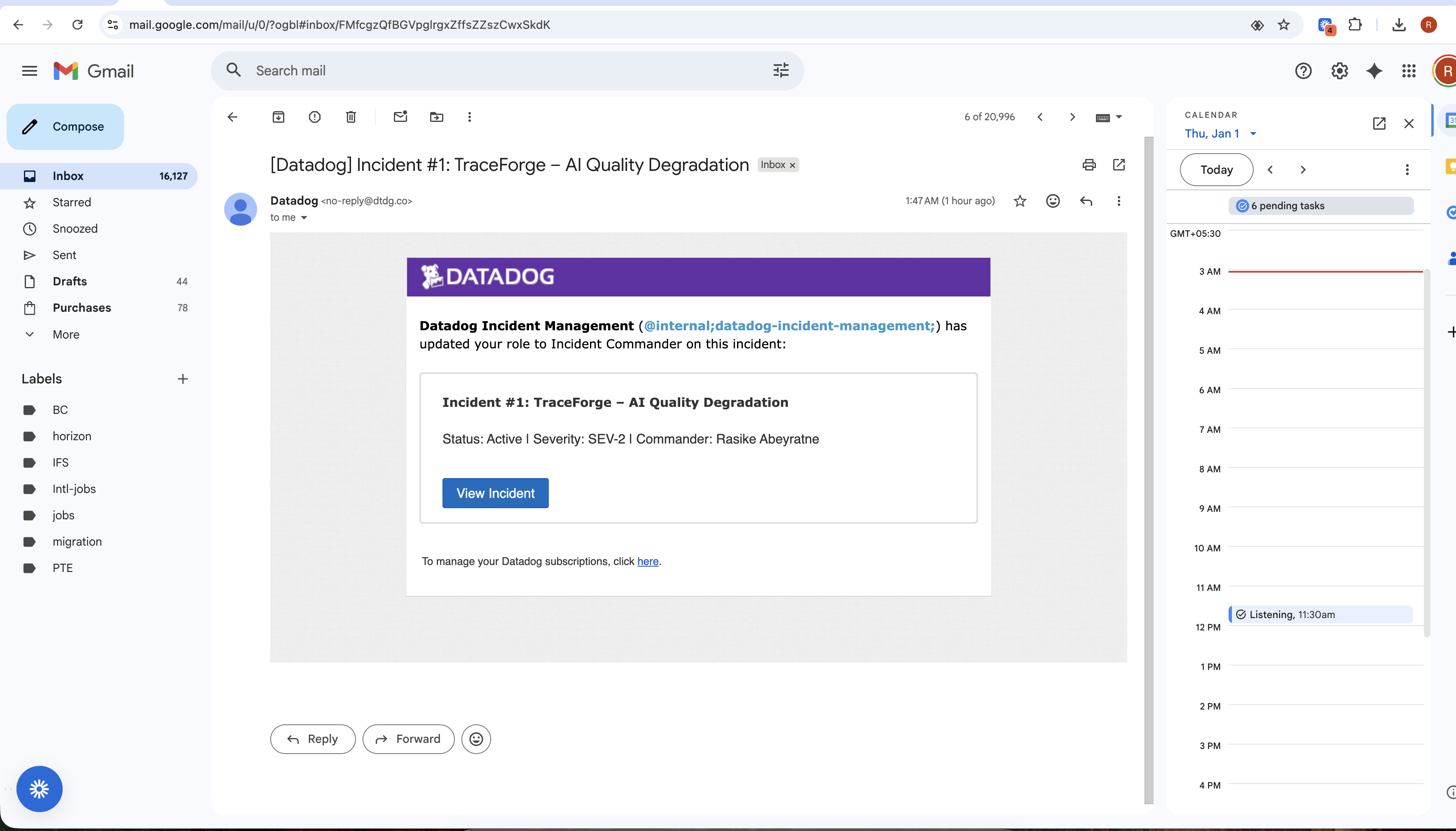
Incident #1
-
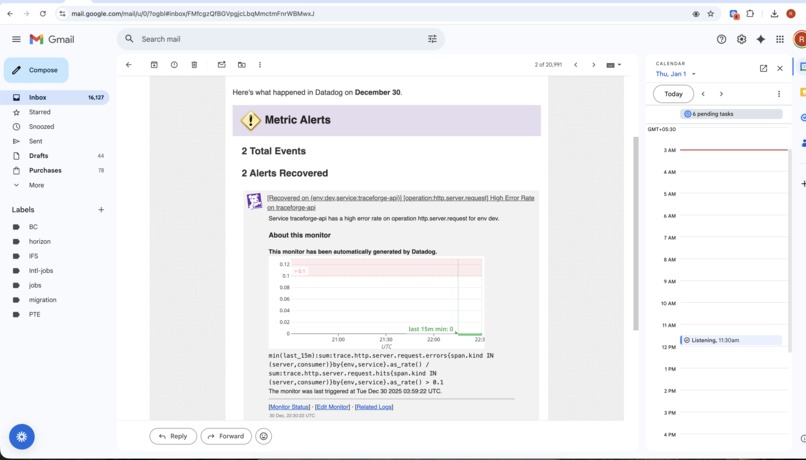
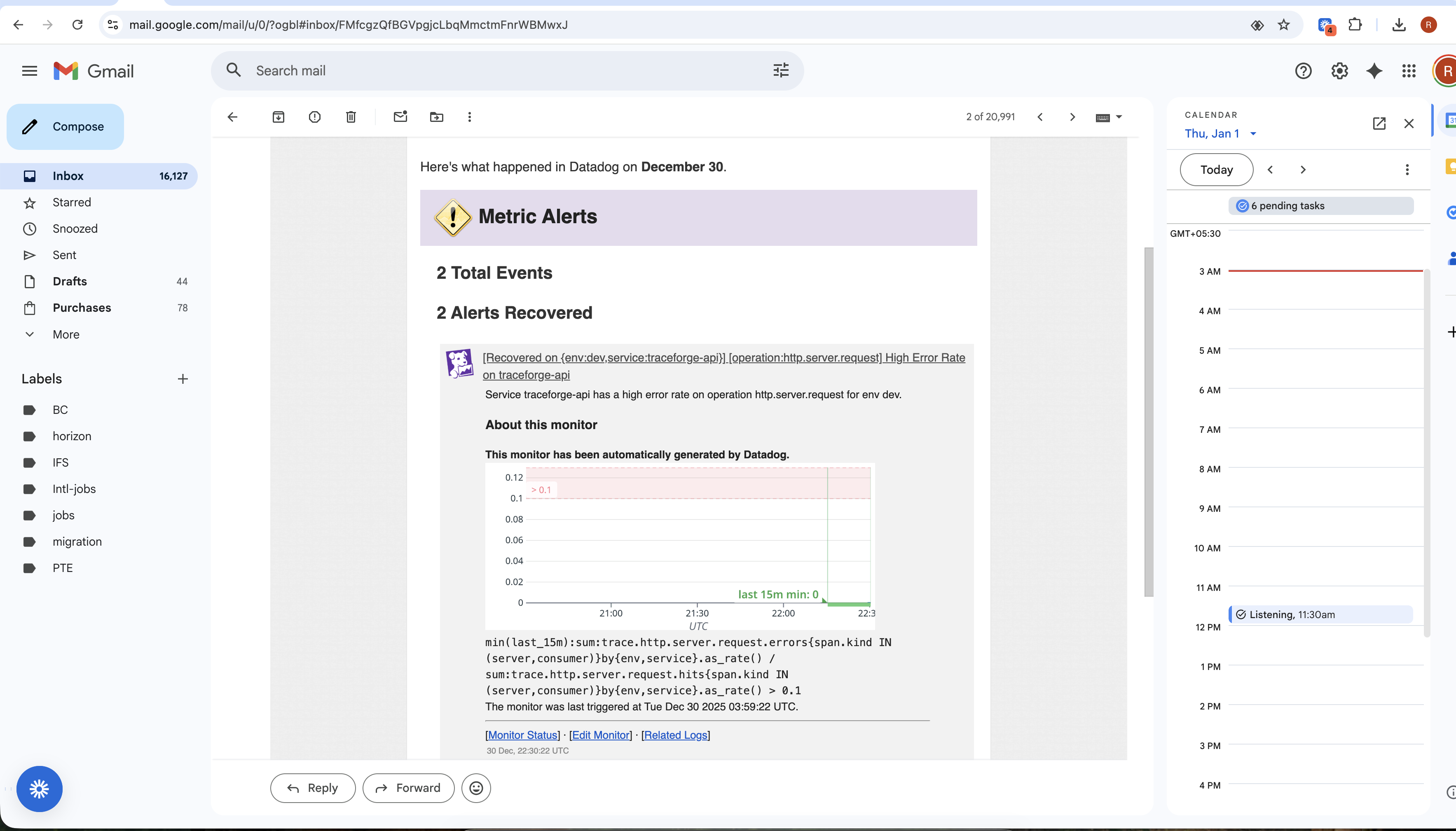
metric-alerts
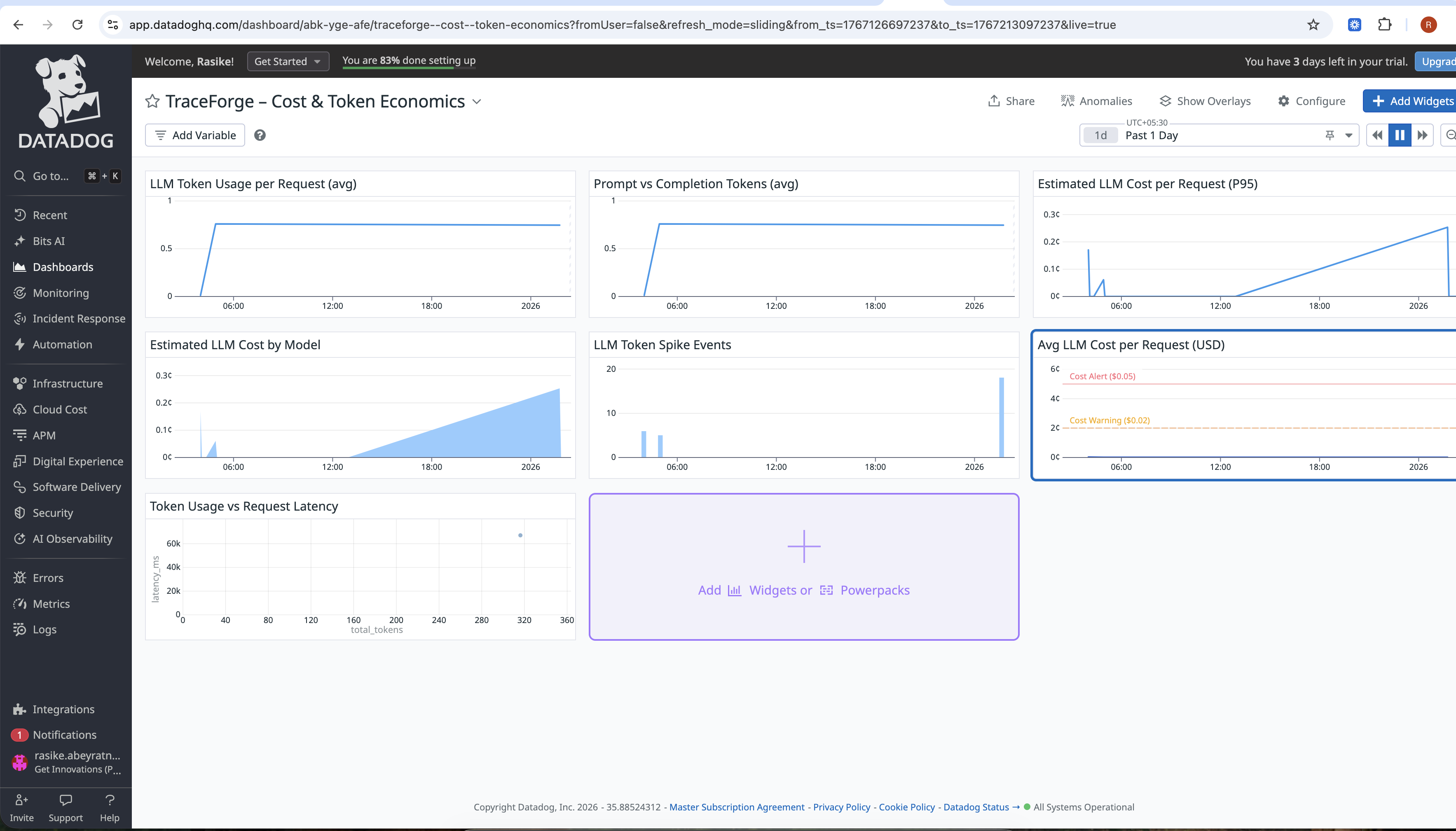
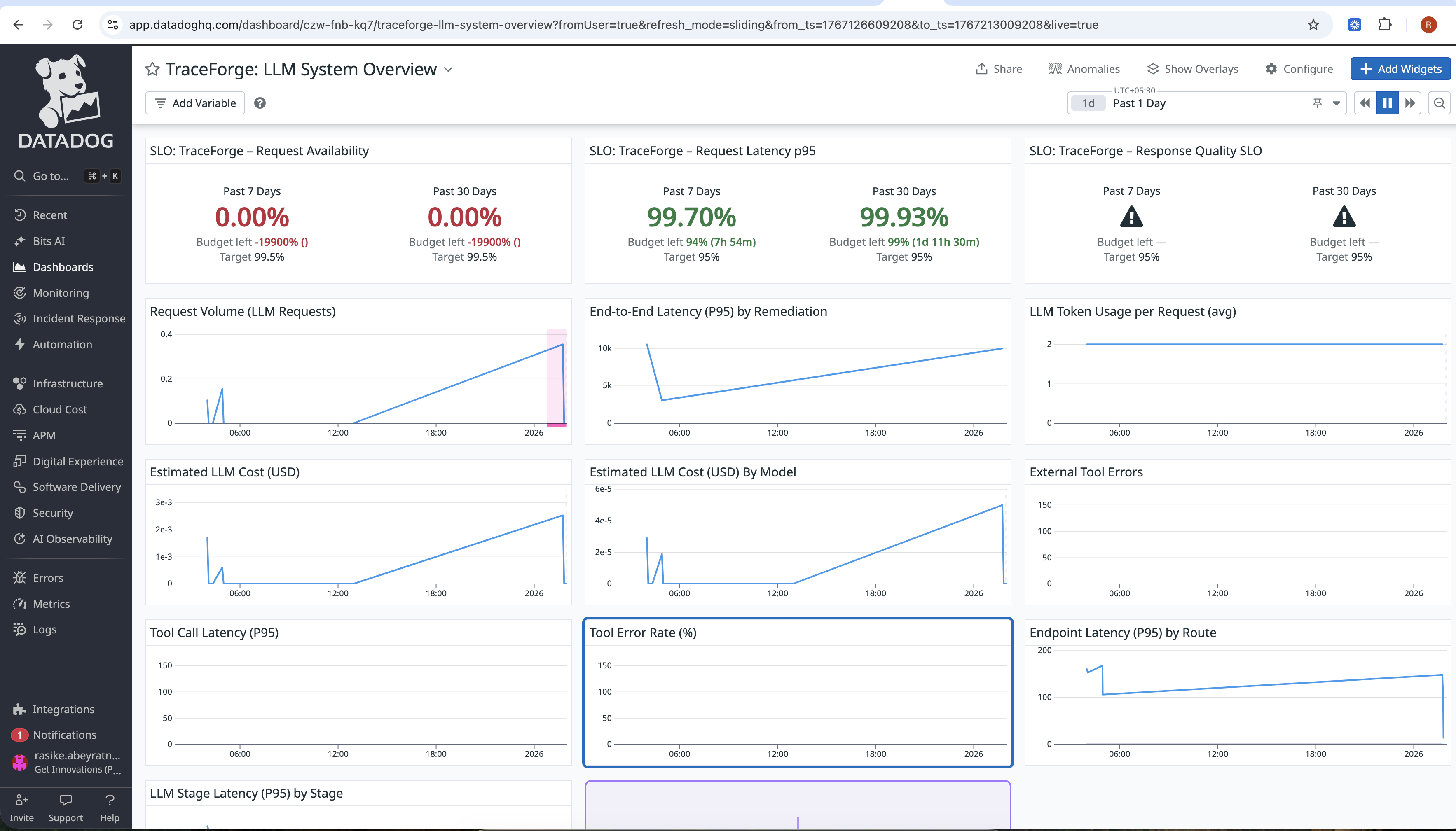
TraceForge — Observable & Self-Healing AI Orchestration Inspiration
As AI systems move from demos to production, teams are discovering a hard truth: AI fails silently.
Modern orchestration frameworks can execute RAG pipelines and LLM calls, but when something goes wrong, teams struggle to answer basic questions:
Why did this response become incorrect?
Where did hallucination enter the pipeline?
Why did costs spike on certain requests?
What actually happens when quality degrades?
In traditional software, observability, SLOs, and automated recovery are standard practice. In AI systems, they are often an afterthought. TraceForge was inspired by this gap — the need to treat AI not as a black box, but as a production system that can be observed, evaluated, and automatically remediated.
What it does
TraceForge is an observability-first AI orchestration platform that makes AI systems reliable by default.
For every request, TraceForge:
Traces the entire pipeline (RAG → LLM → Evaluation → Remediation)
Measures token usage, latency, and real USD cost
Scores response quality across multiple dimensions:
Faithfulness
Relevance
Hallucination risk
Policy risk
Overall quality
Automatically triggers remediation when quality degrades
Exposes AI-specific SLOs, burn rates, and dashboards
Instead of simply running AI workflows, TraceForge continuously monitors, evaluates, and fixes them — in real time.
How we built it
TraceForge was designed from the ground up with production observability principles.
Architecture overview
Each request flows through a standardized pipeline:
User Request ↓ RAG Retrieval ↓ Gemini LLM (real provider) ↓ Quality Evaluation (5 dimensions) ↓ Automatic Remediation (if needed) ↓ Response (OK or DEGRADED)
Key technical decisions
OpenTelemetry-first design Every stage emits standardized spans, attributes, and metrics. Observability is not optional or bolted on.
Real LLM integration The demo uses Google Gemini with real token counts, latency, and cost estimation — no mocks in the critical path.
Quality as a first-class signal Evaluation is not external or manual. Every response is scored automatically on multiple quality dimensions.
Self-healing behavior When quality drops below a threshold, TraceForge triggers remediation (clarification in this phase), marks the request as DEGRADED, and still serves a safe response.
SRE-aligned metrics and SLOs AI systems are monitored using the same discipline as distributed systems — with SLOs, error budgets, and burn rates.
All telemetry is exported via OpenTelemetry and visualized in Datadog using traces, custom metrics, dashboards, and saved forensic views.
Challenges we ran into
AI observability is not standardized Unlike HTTP or databases, there is no widely accepted model for tracing AI pipelines. We had to design a consistent span and metric taxonomy from scratch.
Balancing realism and demo reliability We needed real LLM behavior (tokens, cost, latency) while ensuring the demo reliably showed both success and failure scenarios.
Making quality measurable “Quality” is subjective, but production systems need deterministic signals. We designed evaluation logic that is repeatable, explainable, and actionable.
Avoiding overengineering It was tempting to build many advanced features. We intentionally focused on one clear, end-to-end story that judges could immediately understand.
Accomplishments that we're proud of
Built a fully observable AI pipeline, not just a functional one
Demonstrated automatic detection and recovery from low-quality AI output
Implemented real cost tracking per request
Created AI-specific SLOs and burn rate dashboards
Designed a system where AI failures are visible, explainable, and fixable
Most importantly, TraceForge proves that AI systems can be operated with the same rigor as traditional production systems.
What we learned
AI reliability is an engineering problem, not just a model problem
Observability must be designed in from day one
Quality signals are most powerful when they directly trigger action
Treating AI outputs as “best effort” is unacceptable in production
Judges (and real users) value clarity and proof over feature count
What's next for TraceForge — Observable & Self-Healing AI Orchestration
This project represents Phase 1 of TraceForge.
Next steps include:
Real vector embeddings and semantic retrieval
Advanced evaluators (LLM-as-judge, embedding-based scoring)
Additional remediation strategies (safe mode, retries, tool fallbacks)
Alerting and notifications for quality degradation
Cost optimization recommendations
A/B testing for prompts, models, and retrieval strategies
Our long-term vision is to make AI reliability engineering a standard discipline — just like SRE is today.
Built With
- ai-observability
- and-cost-analysis-opentelemetry-?-end-to-end-distributed-tracing-and-custom-metrics-for-ai-pipelines-datadog-?-observability-platform-used-for-traces
- dashboards
- datadog
- gemini
- metrics
- nestjs
- node.js
- opentelemetry
- production-grade-development-node.js-?-runtime-for-high-performance-backend-services-nestjs-?-structured-framework-for-building-scalable-apis-and-orchestration-logic-google-gemini-api-?-real-llm-provider-for-text-generation
- rag
- slos
- sre
- token-usage
- typescript

Log in or sign up for Devpost to join the conversation.