-
-
Dashboard
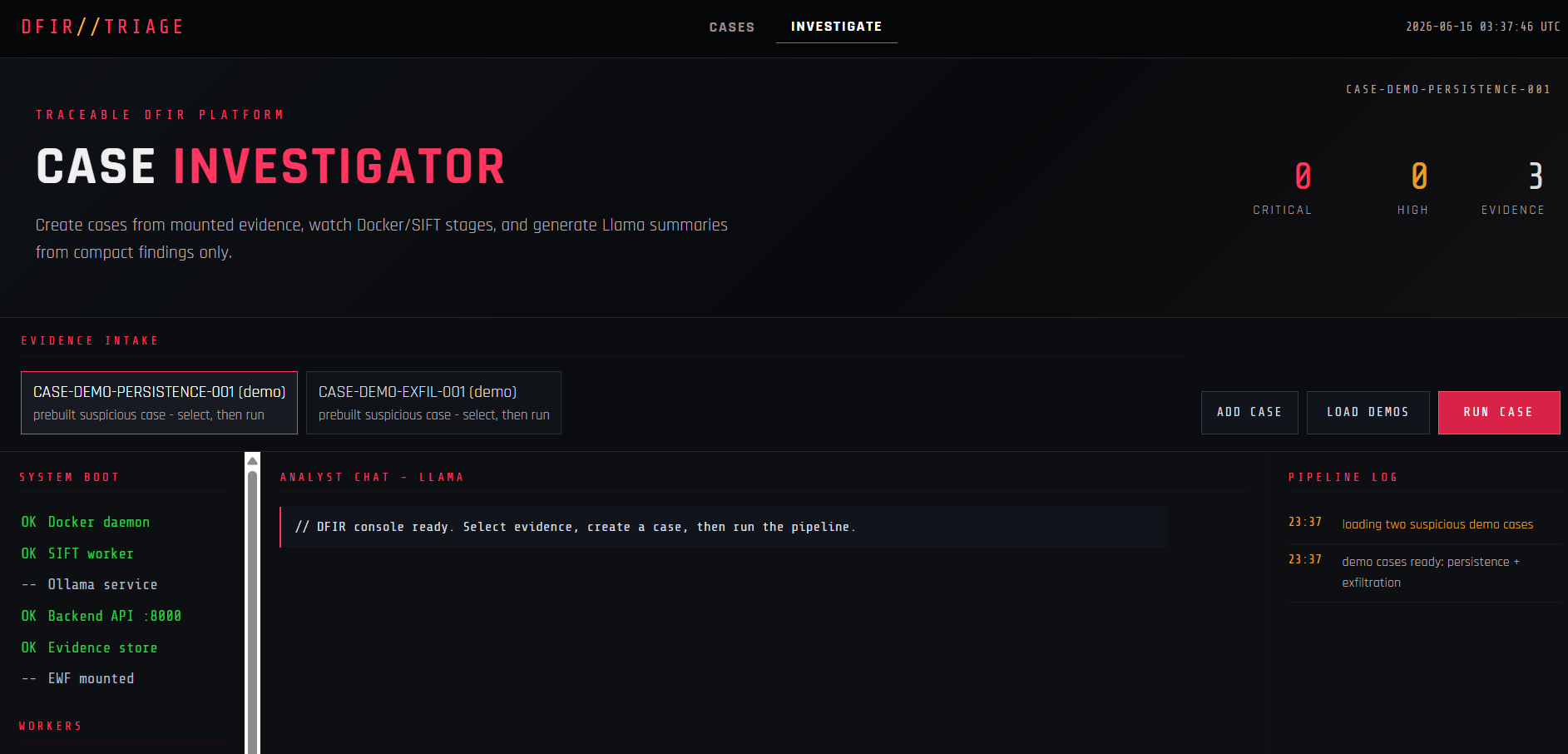
Traceable DFIR Investigator
Short Description
Traceable DFIR Investigator is a reproducible, agent-ready DFIR platform that runs deterministic SIFT tooling in case-specific Docker workers, validates every finding against evidence and trace records, and uses Llama only as a constrained conversational/reporting layer.
Inspiration
Incident response tools can produce useful output, but it is often hard to prove exactly where a finding came from or reproduce the same workflow across cases. I wanted to build a DFIR platform where:
- Each case runs in an isolated SIFT worker container.
- Every result is traceable.
- Every finding can be validated.
- The LLM helps explain findings without becoming a black box.
What It Does
Traceable DFIR Investigator lets an analyst:
- Add forensic evidence such as
.e01and.ex01files. - Create a case with a dedicated SIFT worker container.
- Run an agentic investigation controller through
agent_run_case. - Generate records for evidence, traces, and findings.
- Validate links from findings back to artifacts, paths, trace IDs, and tool outputs.
- Query Llama about the case using only compact, validated findings.
- Generate narratives without sending raw, massive artifacts to the LLM.
Agentic Workflow
The primary execution path follows this logic:
agent_run_case(case_id)
└── The controller performs:
├── load case
├── start worker
├── check tools
├── mount evidence
├── run deterministic investigation
├── build report
├── validate traceability
├── self-correct if needed
└── send compact brief to Llama
Claude Code, OpenClaw, or any other MCP-capable agent can call these backend tools.
Important Boundary: Llama is not the decision-maker. Llama functions strictly as the conversational and reporting layer.
Architecture
Frontend Dashboard
│
▼
FastAPI + MCP Backend
│
▼
agent_run_case Controller
│
▼
Case-Specific SIFT Worker Container
│
▼
Evidence / Trace / Finding Stores
│
▼
Compact Llama Brief
│
▼
Narrative Report + Chat
Each case maps to its own worker container. Ollama/Llama is shared across cases.
Self-Correction
The demo includes a visible self-correction loop. For built-in demo cases, the agent performs a draft-report self-check:
- It detects an intentionally incomplete draft missing a trace link.
- It discards that draft automatically.
- It rebuilds the report from durable evidence and trace stores.
- It validates the final report.
This successfully demonstrates error detection, autonomous correction, source evidence preservation, and pre-generation validation.
Accuracy & Validation
Every finding must explicitly link to evidence and trace records. Validation checks verify:
finding_id/evidence_id/trace_id- Artifact path & tool name
- Trace status & source path or artifact location
The goal is to allow a judge or analyst to effortlessly trace backwards: Finding ➔ Evidence ➔ Trace ➔ Artifact/Tool/Source Path
Hallucination Controls
The LLM is intentionally constrained. Llama is strictly forbidden from:
- Creating findings or deciding what is suspicious.
- Approving findings or modifying evidence/trace records.
- Running forensic tools directly or receiving raw artifacts by default.
Instead, Llama receives a compact case brief containing finding IDs, short artifact locations, severity/confidence metrics, UI links, and deterministic summaries. LLM output is clearly marked as non-evidence commentary. If the brief cannot support an answer, the chatbot states what is missing and suggests the correct tool for verification.
Tech Stack
- Backend: Python 3.12, FastAPI, MCP Server Tools
- Containerization: Docker Compose, SIFT worker containers
- AI/LLM: Ollama / Llama
- Frontend: React, Vite, TypeScript
- Forensic Tooling: YARA, Hayabusa, Plaso/log2timeline support
- Storage: JSONL evidence, trace, and finding stores
What It Was Tested Against
- Built-in suspicious persistence and exfiltration demo cases.
- Uploaded
.e01/.ex01evidence intake flows. - Docker Compose local backend startup and case-specific SIFT worker creation.
- Shared Ollama/Llama service and MCP tool exposure.
- FastAPI endpoints and React/Vite dashboard flows.
Validation Commands Used:
npx tsc -b
python -m py_compile dfir_backend/server.py dfir_backend/api.py
docker compose config
API Connection Checks:
curl http://localhost:8000/api/health
curl -X POST http://localhost:8000/api/cases/CASE-DEMO-PERSISTENCE-001/agent-run
Reproducibility
The platform is built Docker-first. A judge can easily spin it up by running:
docker compose build sift-worker-image
docker compose up -d --build ollama mcp
cd frontend
npm install
npm run dev
Or simply use the provided helper script:
./scripts/start-all.sh
- Dashboard URL:
http://localhost:5174 - Backend API Health:
http://localhost:8000/api/health
Railway / Hosted Preview
Railway can host a lightweight frontend/backend preview. However, because the full forensic workflow requires Docker socket access to spin up case-specific SIFT worker containers, the best split deployment is:
- Railway Frontend: Dashboard UI preview.
- Railway Backend: API and demo fixture preview.
- Docker Compose Local Host: Full forensic execution with active worker containers.
Limitations
- Full worker orchestration requires a host machine with active Docker socket access.
- Large
.e01files take time to upload and process. - Timeline generation can fail on incomplete or damaged image files.
- Llama performance and speed depend entirely on local hardware and model size.
Accomplishments I'm Proud Of
I successfully built:
- A highly reproducible DFIR backend architecture.
- Isolated, per-case SIFT worker containers.
- Durable, validation-ready evidence, trace, and finding stores.
- An agentic controller featuring autonomous self-correction.
- A complete React dashboard displaying cases, workers, findings, reports, and real-time chat.
- Deterministic demo cases optimized for immediate judging evaluation.
What's Next for Traceable DFIR Investigator
- Richer frontend trace drill-down pages.
- Interactive timeline visualization graphs.
- Memory capture (
.raw,.vmem) analysis support. - Log and network capture ingestion workflows.
- Exportable PDF/HTML formal investigation reports.
- Deeper integration scripts for Claude Code and OpenClaw.
- Additional evaluation cases for testing hallucination resistance.
Built With
- https://github.com/pinklamb/findevil

Log in or sign up for Devpost to join the conversation.