-
-
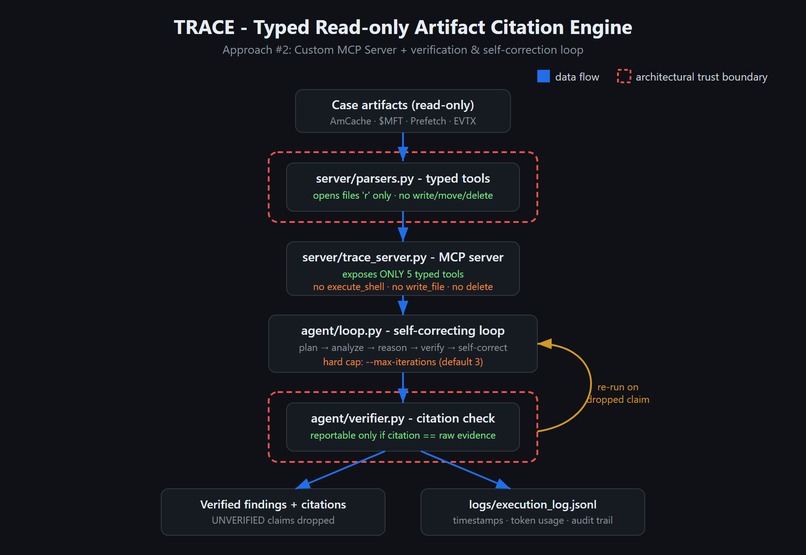
Architecture
-

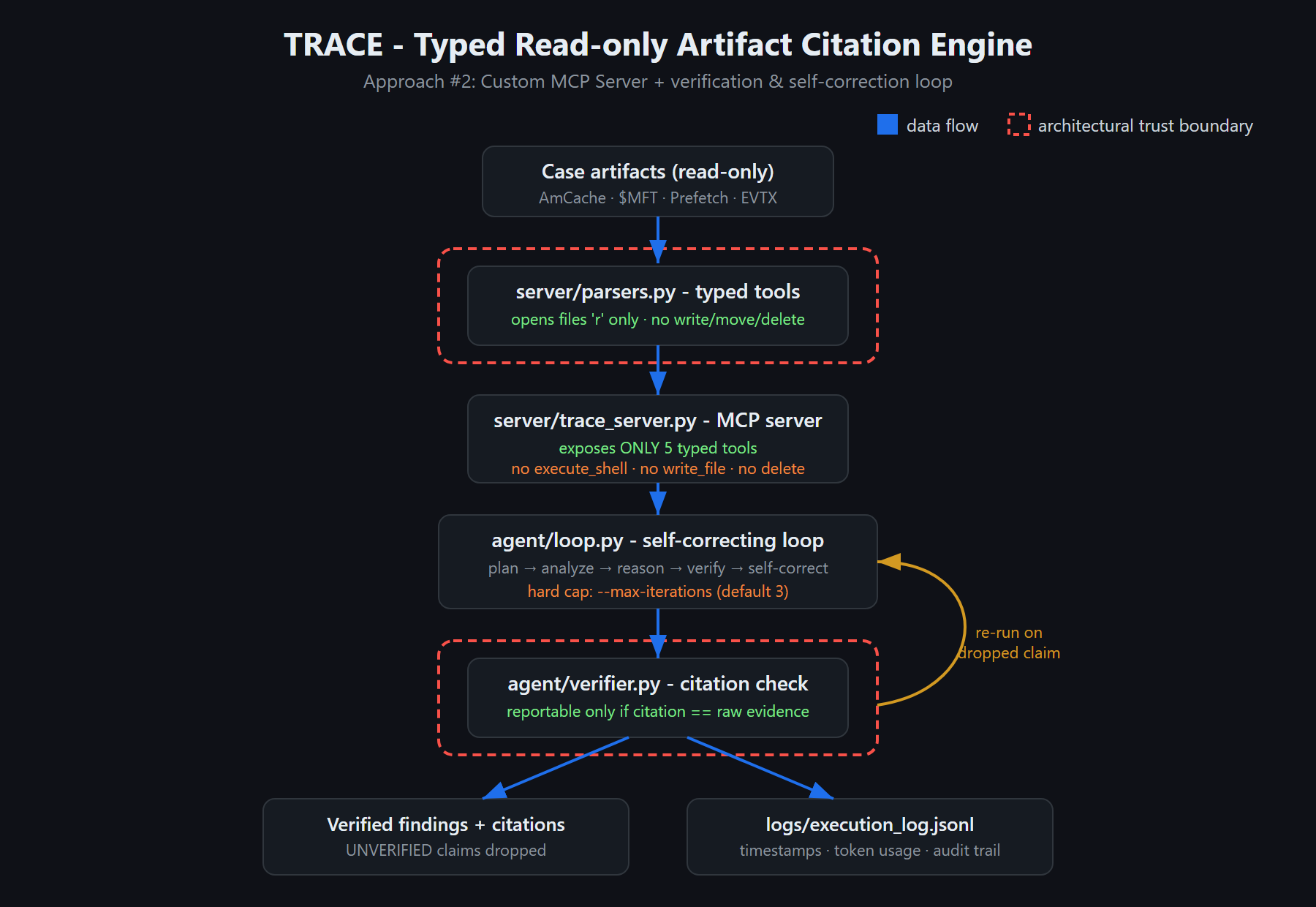

Inspiration
The brief is unusually honest: "Protocol SIFT works. It also hallucinates more than we'd like." The judges are working DFIR practitioners and CISOs. They will not be impressed by an agent that sounds like a senior analyst. They will ask the question they ask every junior analyst: "show me the evidence." TRACE is built around that single question.
What it does
TRACE is a custom MCP server plus a self-correcting agent loop that makes an incident-response agent unable to fabricate findings or damage evidence, and then measures the result against ground truth.
- Typed read-only tools. Instead of
execute_shell, the agent gets five typed functions (get_amcache,extract_mft_timeline,analyze_prefetch,parse_evtx_logons,list_artifacts). It physically cannot run a destructive command, because the server doesn't expose one. - Citations on every finding. Each finding points to the exact line of raw tool output that produced it. A judge can trace any claim back to its source.
- A verifier that catches hallucinations. Any claim whose citation doesn't match real evidence is flagged
UNVERIFIEDand dropped. - Self-correction. When the verifier drops claims, the loop re-runs with a tightened instruction, capped by
--max-iterations(default 3); on our demo case it converges in 2. - A benchmark. TRACE is scored against ground truth vs. an unverified baseline, reporting true positives, misses, false positives, and hallucination rate.
A note on our setup
We built and tested TRACE on a laptop with 8GB of RAM, which is not enough to comfortably run the full SIFT Workstation VM alongside a model. Rather than treat that as a blocker, we made it a design constraint: TRACE runs in pure Python with zero dependencies for the demo path, and our live LLM test uses a local Ollama llama3.2:1b model small enough to run on the same machine, with no API key and no data leaving the device. The architecture is deliberately pluggable, so the exact same citation, verifier, loop, and benchmark code drops onto the full SIFT Workstation by swapping in regipy / python-evtx / analyzeMFT / prefetch. The constraint shaped the engineering; it did not limit the thesis.
How we built it
Pure-Python, zero external dependencies for the demo path, so judges can run it in seconds. Evidence parsing lives behind a single read-only accessor (_read_lines), which is the only code that touches disk. The MCP server (FastMCP) advertises only the typed tools. The verifier re-reads the cited bytes and compares them to the recorded raw_line. A fabricated or drifted citation fails. Everything is logged to JSONL with timestamps and token usage.
To prove the verifier against real hallucinations rather than a scripted one, we added a provider-agnostic live agent (--live): a real LLM (Google Gemini, OpenAI, Anthropic, or any OpenAI-compatible endpoint, no SDK, stdlib urllib only) reads the raw artifact lines and writes findings with its own citations. The verifier then checks each citation against the real bytes, so anything the model fabricates or mis-quotes is caught and dropped.
Live result (real LLM, not scripted)
We ran the live agent on a local Ollama llama3.2:1b model, small enough to run on a laptop, no API key, nothing leaving the machine:
| Mode | Findings reported | Outcome |
|---|---|---|
| Baseline (verifier off, Protocol-SIFT-like) | 8 | All 8 pass through as fact, including a [HIGH] Malicious activity detected finding with no evidence at all. |
| TRACE (verifier on) | 0 | All 8 caught: 3 fabricated citations (real text attributed to the wrong line, an off-by-one a human reviewer would miss) and 5 uncited claims. |
A real model produced real hallucinations, and the verifier rejected every one against the raw bytes.
Challenges we ran into
- Distinguishing fabrication from judgment. The verifier should remove made-up facts, not legitimate analyst inference. We solved this with a
confidencefield: inferred findings are reported but labelled, while uncited claims are dropped entirely. - Proving the guardrail, not asserting it. We made the shell-absence testable: asking the dispatch for a capability that doesn't exist raises, and we document that test in the accuracy report.
- Making it runnable without the SIFT VM so it could be built and benchmarked on day one, with a clean swap path to real parsers.
What we learned
The defensible edge in agentic IR isn't a smarter prompt, because prompts can be ignored. It's architecture: constrain what the agent can do, and verify what it claims against raw evidence.
What's next
Swap the demo parsers for regipy / python-evtx / analyzeMFT / prefetch and run on real SANS sample images; expand the typed toolset across more of SIFT's 200+ tools; add cross-artifact correlation (disk vs. memory discrepancy detection) on top of the same citation/verifier contract.


Log in or sign up for Devpost to join the conversation.