-
-

Slide 1
-

Slide 2
-

Slide 3
-
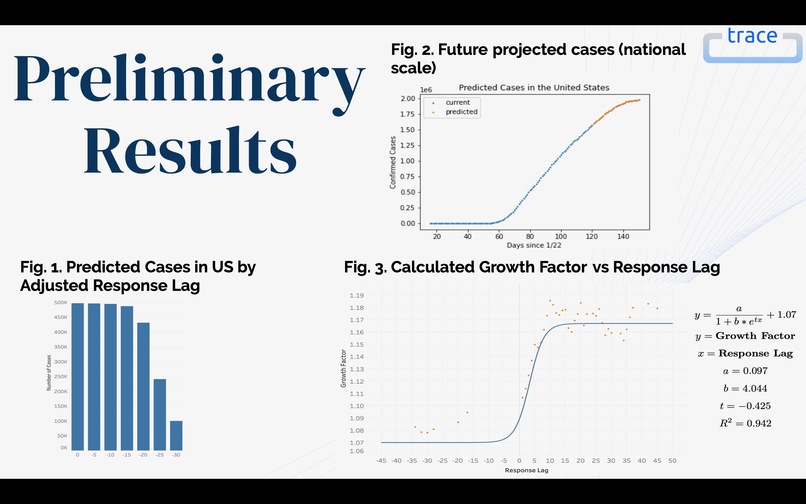
Slide 4
-

Slide 5
-
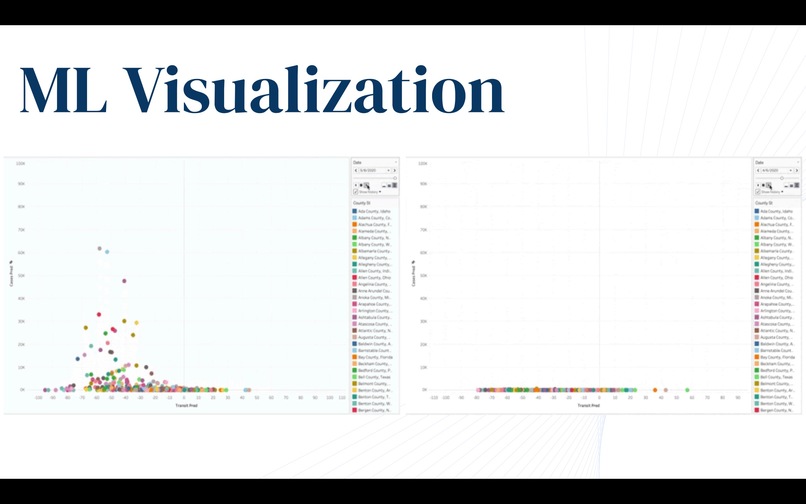
Slide 6
-

Slide 7
-
Login Screen
-
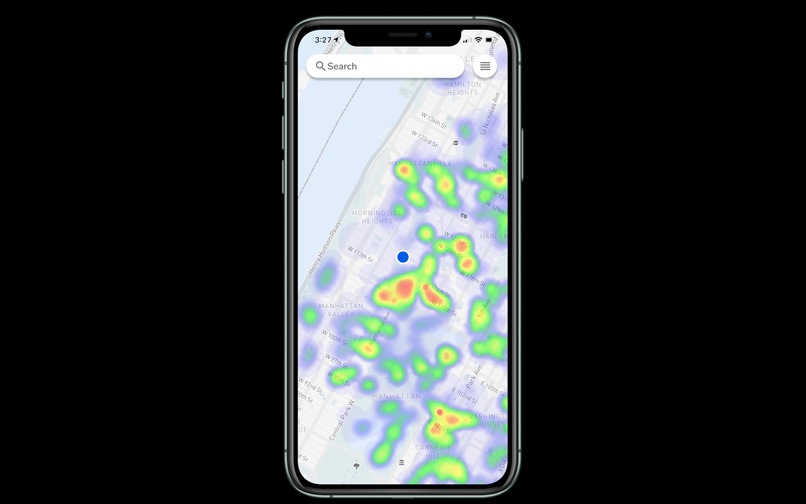
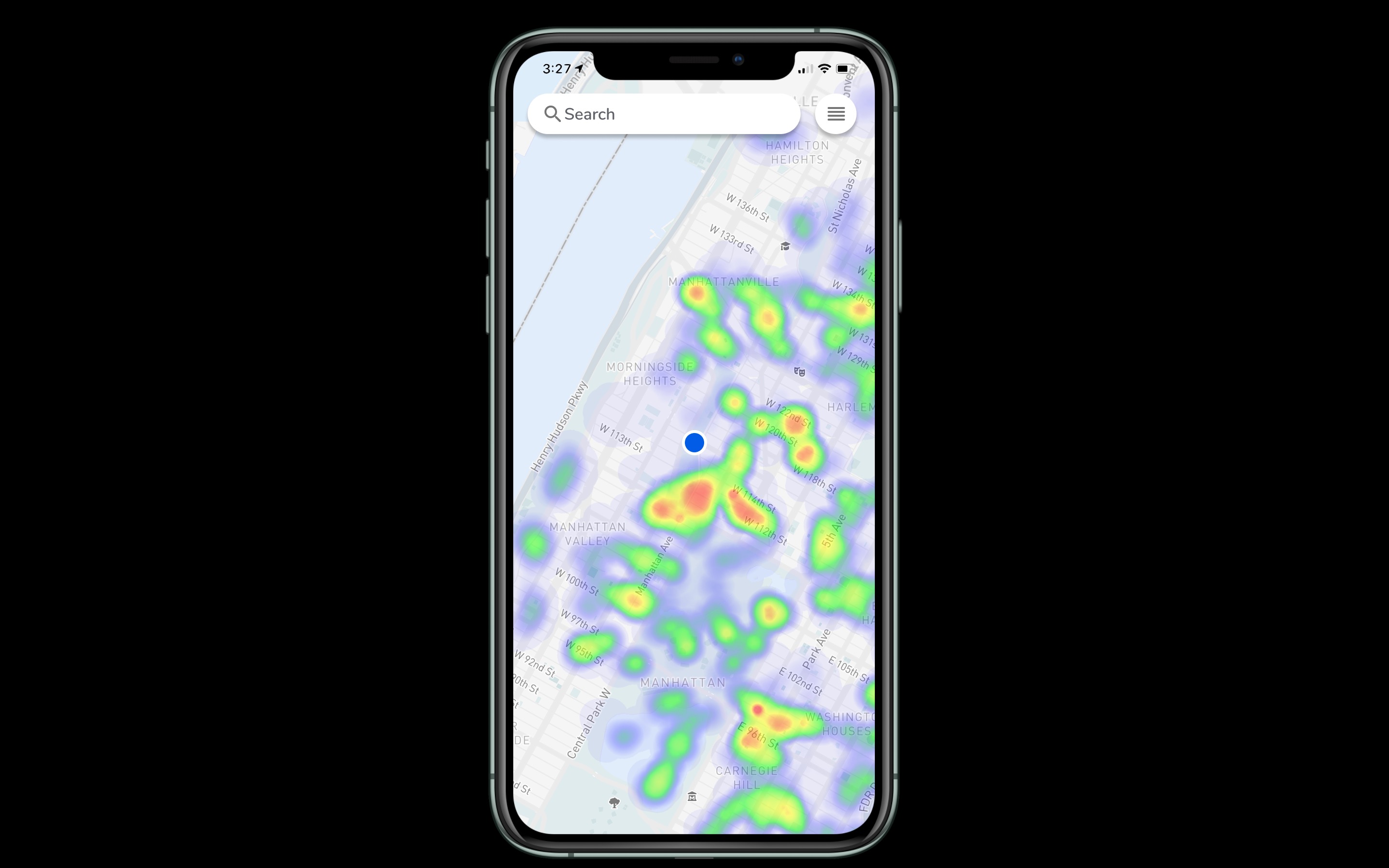
Population Density Heat Map
-
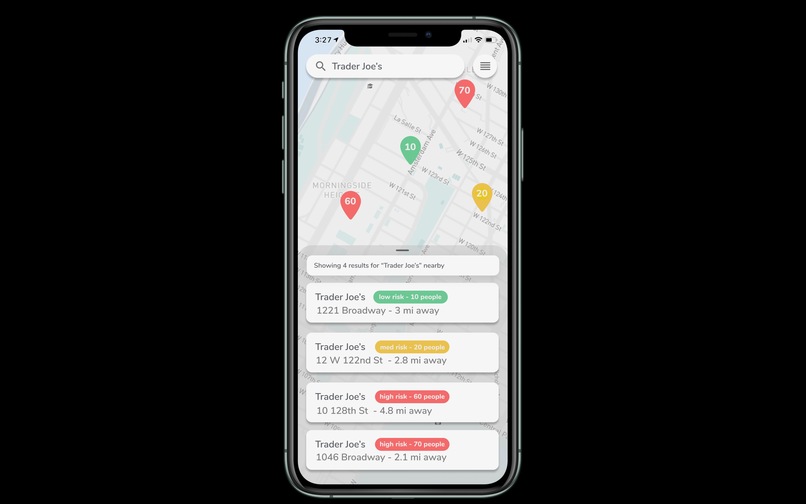
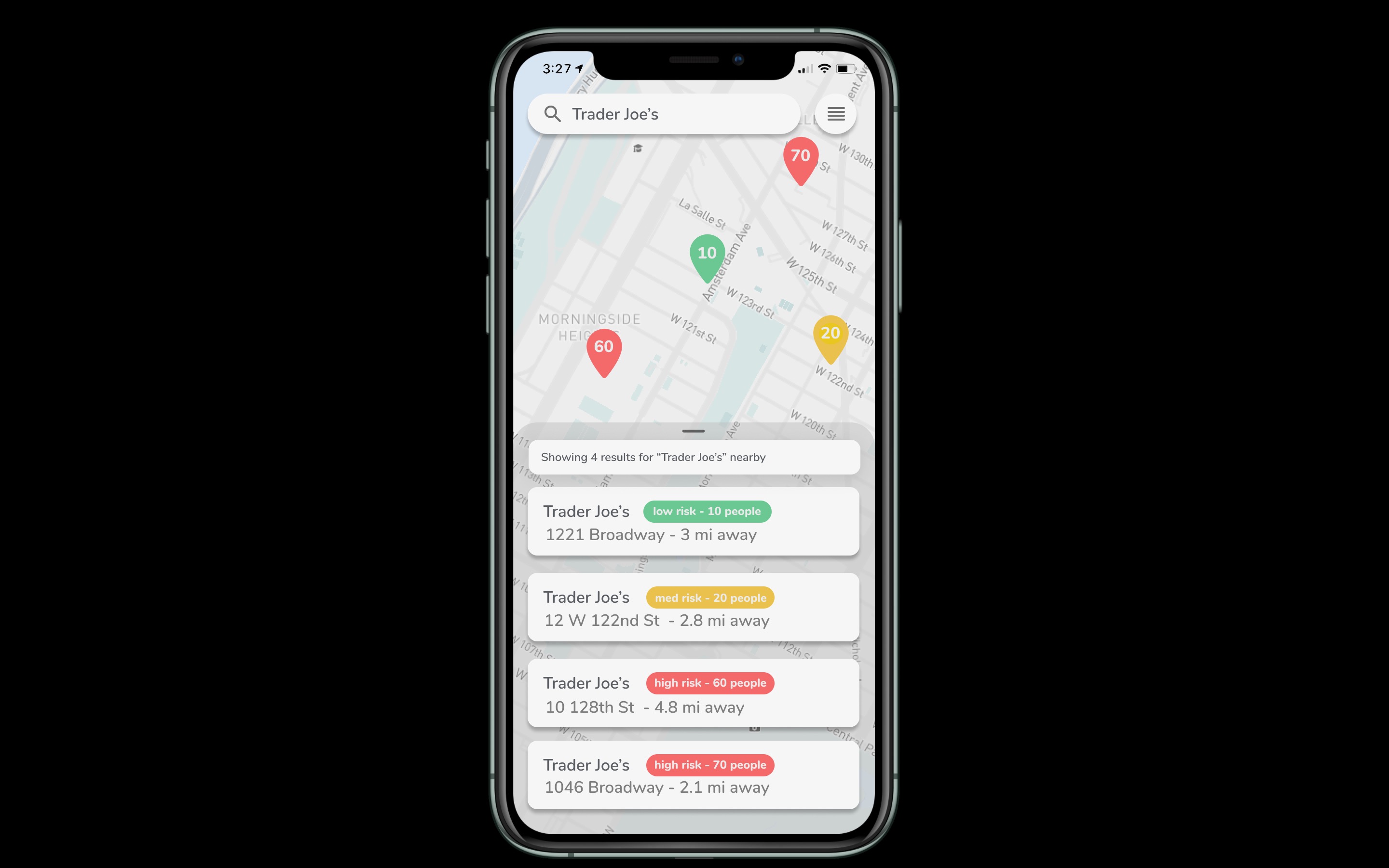
Destination Map
-
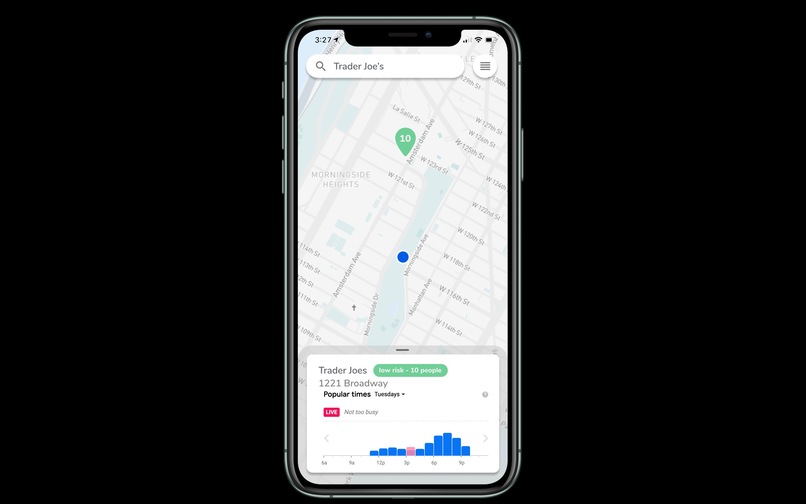
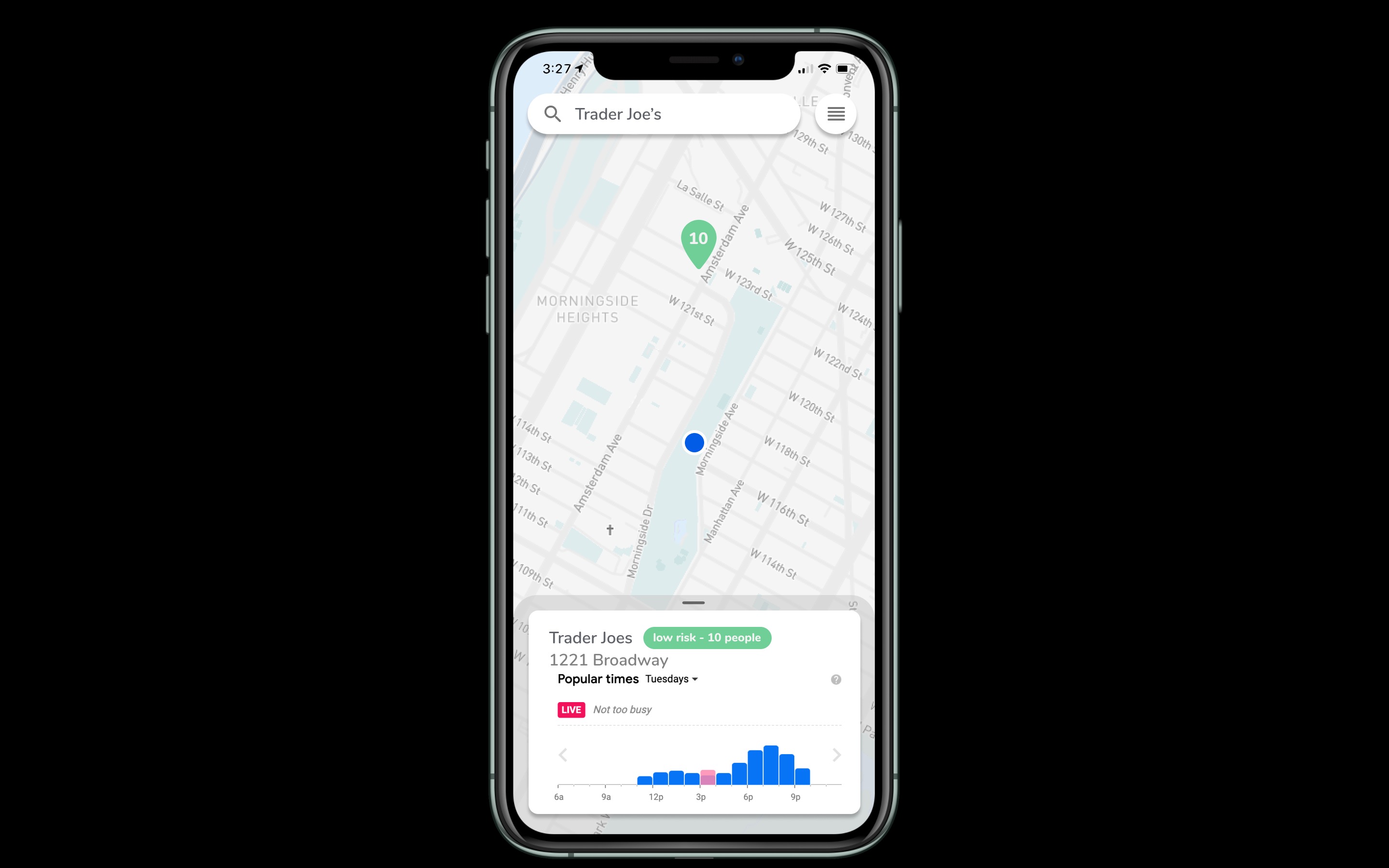
Single Destination
-
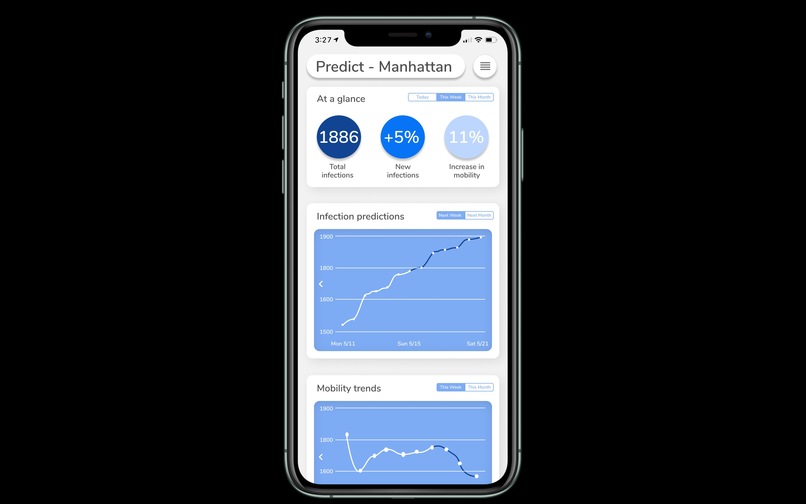
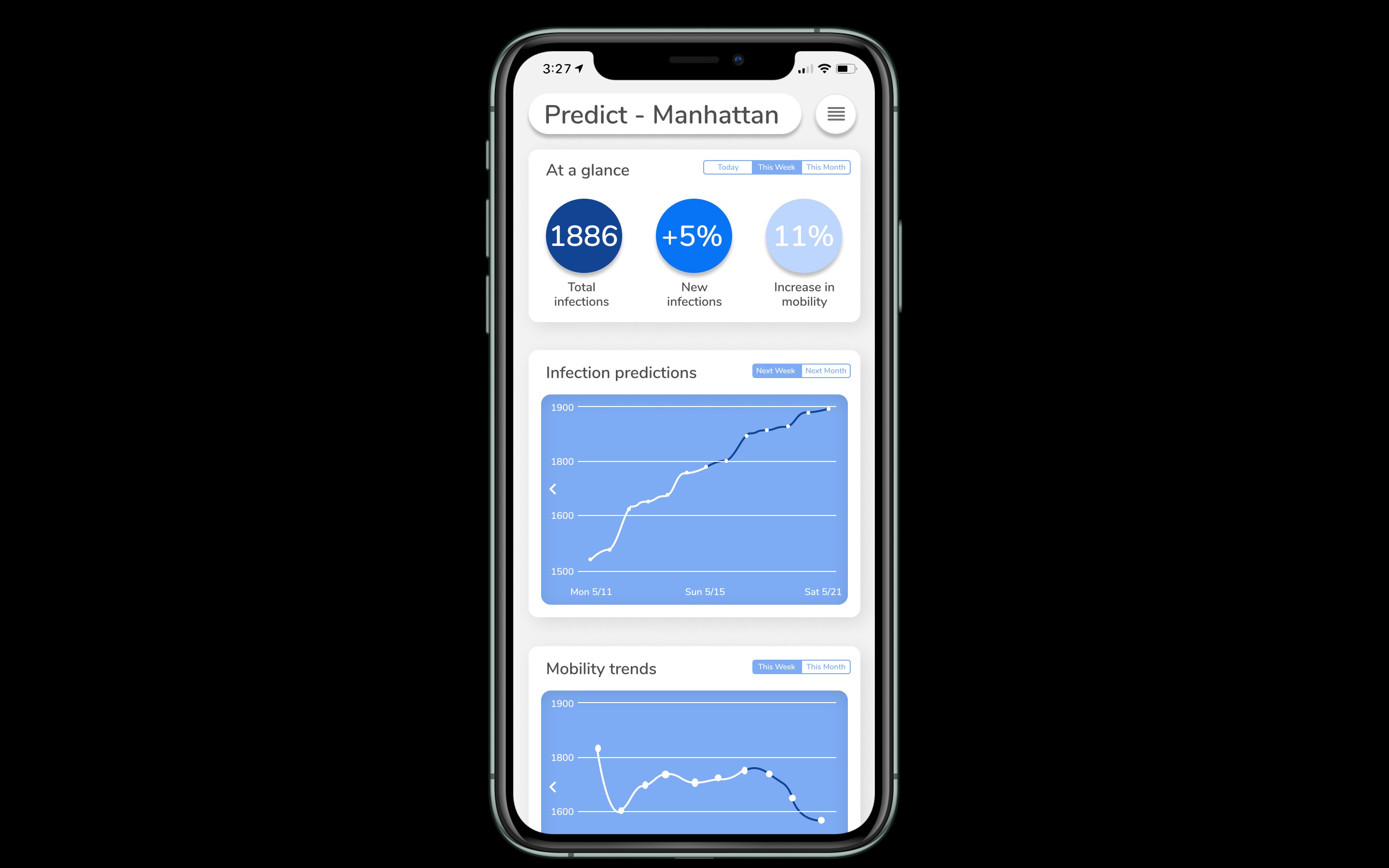
Statistics
-
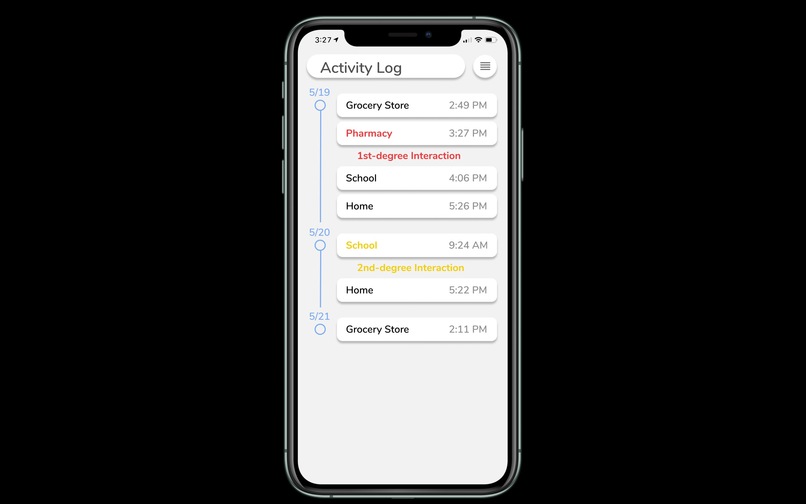
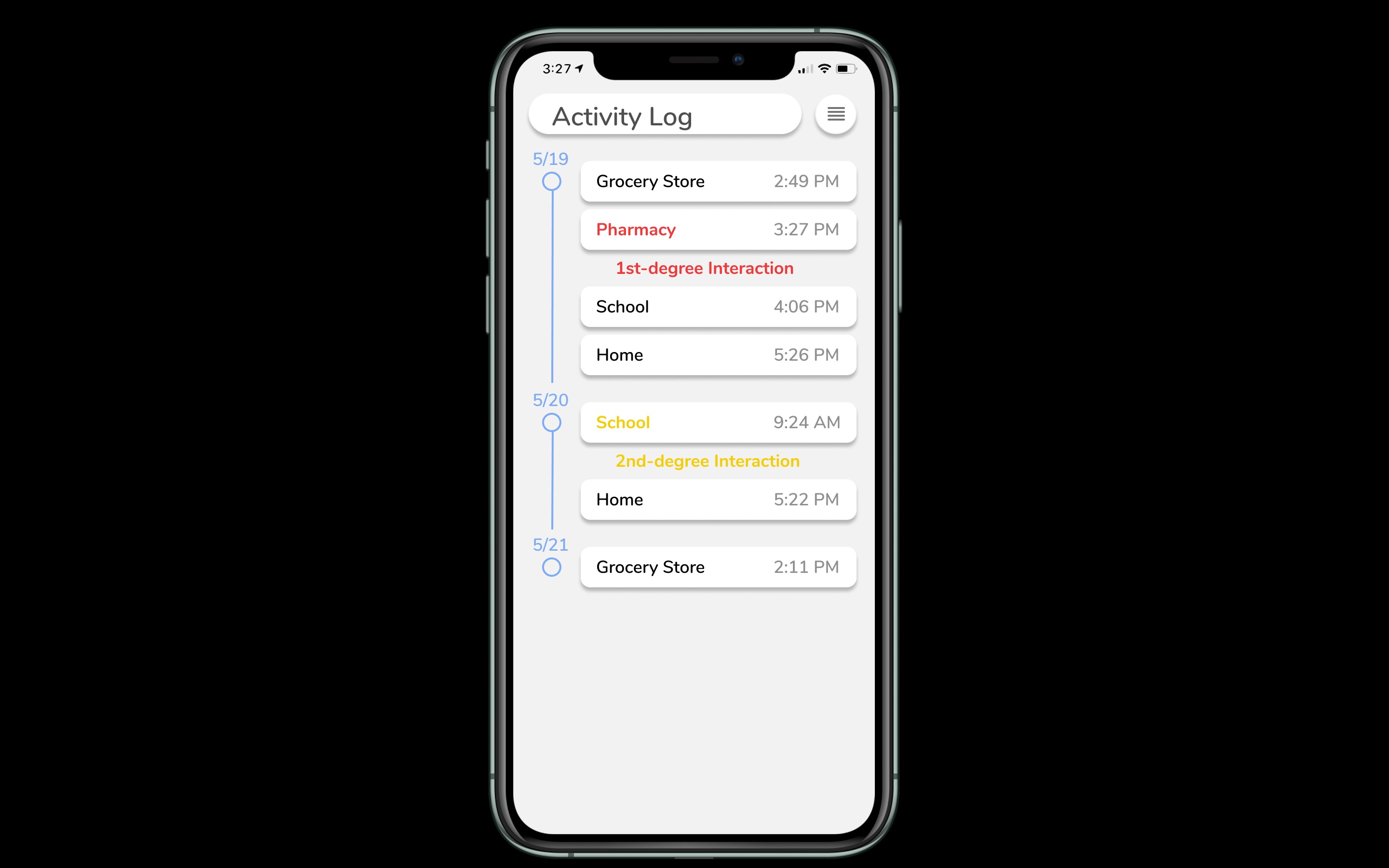
Activity Log
-
Menu





Inspiration
COVID-19 is presenting a challenge in how societies can reopen the economy in a safe manner. Our team was inspired by the technological efficiency shown by other countries, such as South Korea, that has provided mechanisms to preserve a lifestyle that more closely resembles pre-pandemic life. Our app strives to provide a data-driven solution that can be easily implemented in daily life to ensure safety and free mobility in the presence of a pandemic.
What it does
Our app provides solutions for the issue of mobility in the presence of an infectious virus:
A solution to avoid crowded areas and a means to de-densify crowds. Users can use the heatmap function to discover crowded areas. These places would be avoided, reducing interaction and preventing rapid spread of the virus. Users can search for places (i.e. grocery stores, pharmacies, etc.) nearby and check the popularity by hour. If a location currently exhibits high popularity, users can choose to go at a less popular time.
A solution to assess personal risk for infection. Users will be alerted if they have come into contact with someone who has COVID-19. By checking their activity log, users can check if they crossed paths with a person with COVID-19 (1st-degree interaction) or if they crossed paths with someone who had a 1st-degree interaction.
- Note: All interactions within the past 14 days of a self-reported infection will be notified.
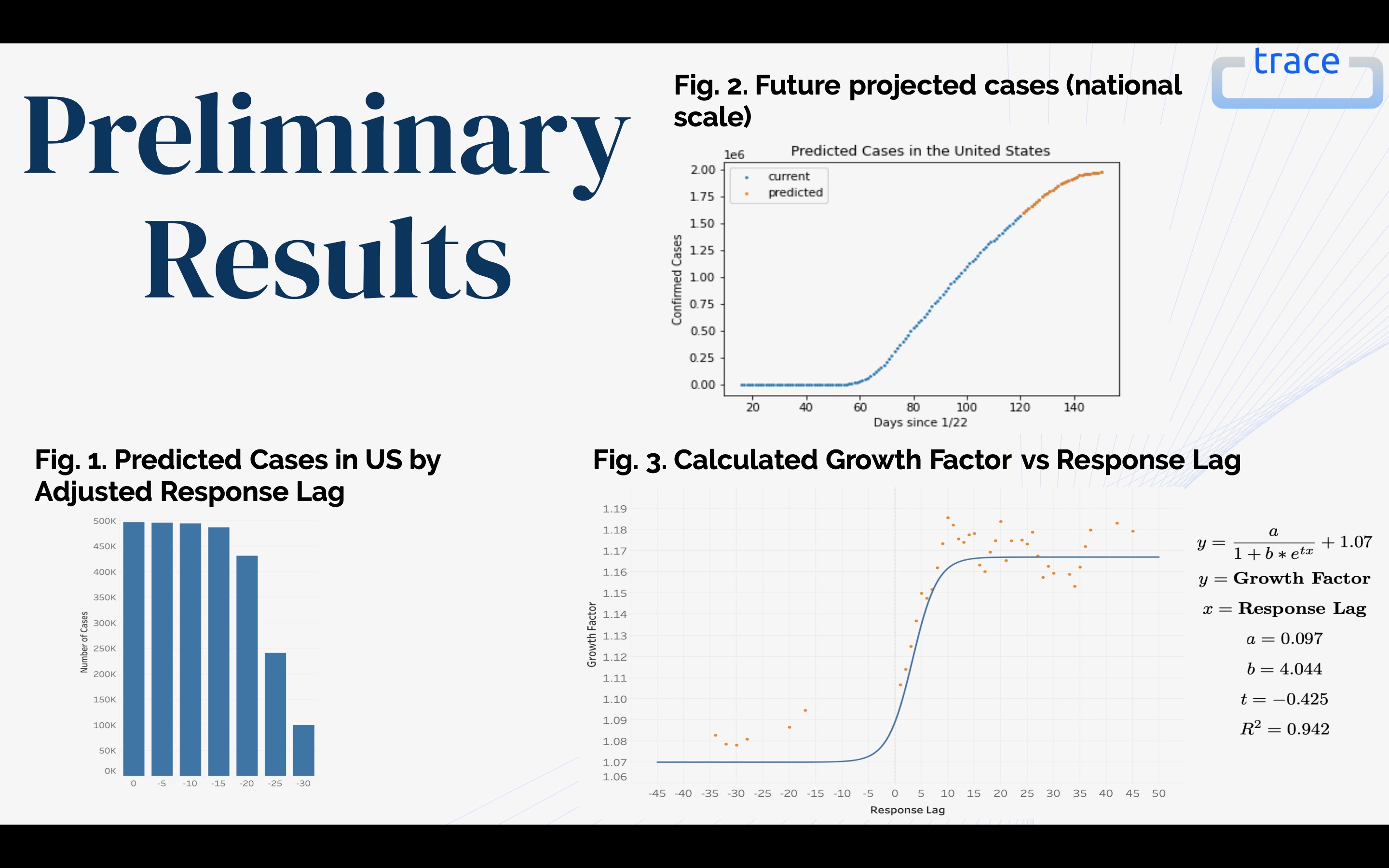
- A solution to assess virus-related trends and predictions Users will have access to statistics on total infections, changes in infections, and changes in local mobility. By representing time-series data in a graphical fashion, users can see how infections and mobility has changed over the past week and month. Our machine learning algorithm can effectively predict into the future the number of infections over the course of a week up to a month, giving users tools to make well-informed decisions regarding their safety.
How we built it
Contact Tracing
The contact tracing feature of our application is based not only on location data, but also on Bluetooth connectivity between Trace users. This enables our application to track user activity and user interaction on a granular scale while preserving user privacy. User contact and distance of interaction can be determined by Bluetooth signaling, and as these signal strengths will be determined in the back-end of the application, Bluetooth signals will remain anonymous to Trace users. Although contact tracing is necessary to help keep communities safe from the spread of viruses, we also believe that it is important to preserve user privacy, and this methodology helps us achieve this function.
Statistical Analysis
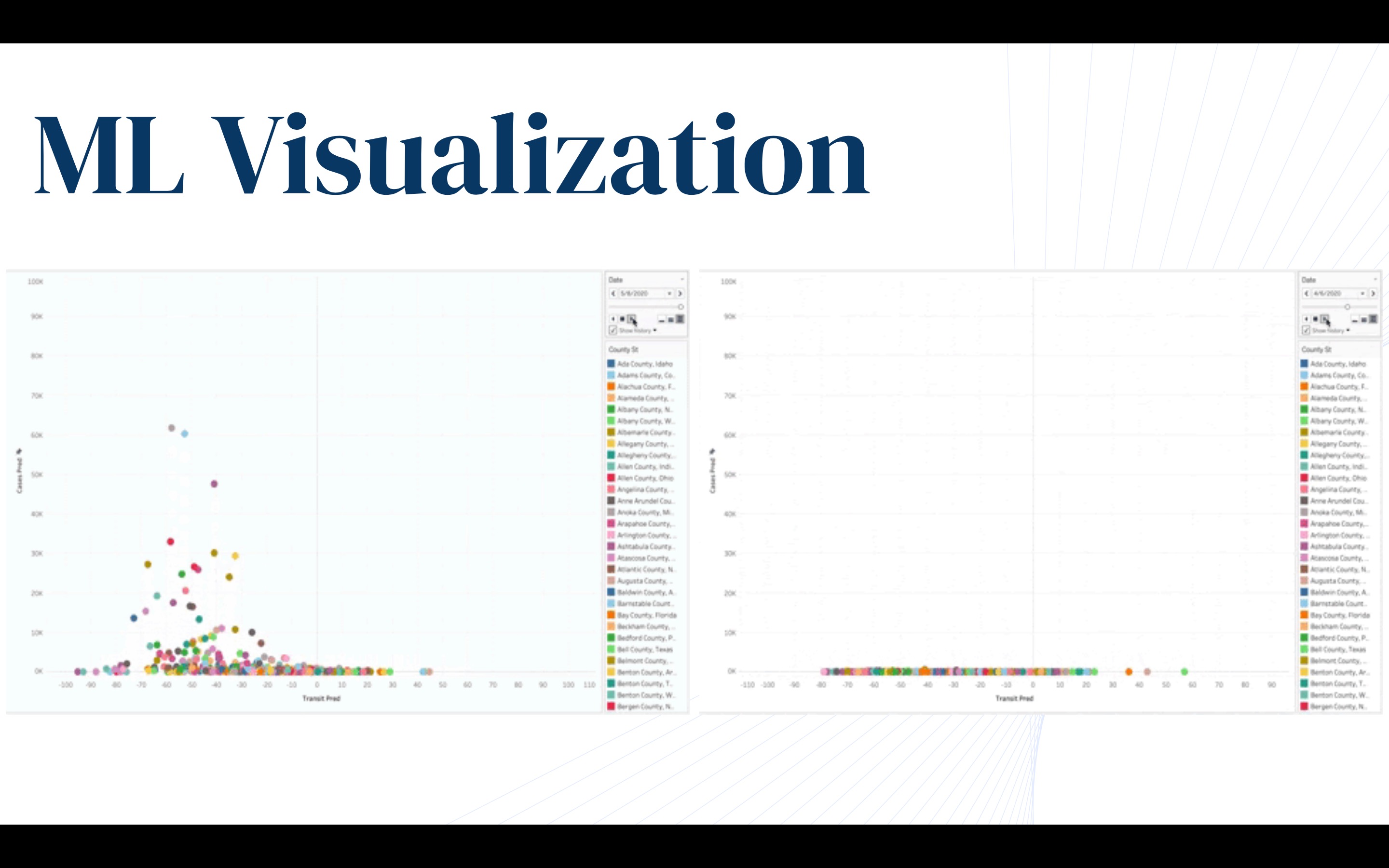
Using data gathered by our application and open-source data, we are able to apply a number of statistical methods and models to provide an in-depth, yet digestible, analysis. Currently, we apply machine learning on Google mobility data to model population movement on a county scale, enabling us to analyze how transit trends directly affect infection rates. By implementing user data, we are able to track and analyze trends in communities on a refined scale. In doing so, Trace is able to provide robust models that understand how populations respond to coronavirus and public policies, providing insight on the effectiveness of social distancing. Furthermore, we apply parametric and nonparametric regressions to predict future cases on a local, state, and national scale using transit trends, assisting the development of public policies and helping users assess the risks involved.
Crowd Tracking
Our map will be implemented using MapBox as our main graphical interface and Google Maps API for search and backend location functions. Using a combination of Google Popular Times data and our own location data generated through the app, we can inform users how many people are populating any searchable location and the best (least popular) times at which to visit. By using our own data, we can direct groups of users to different locations in an effort to minimize crowds at a singular place of interest.
Challenges we ran into
We ran into a number of challenges when creating our machine learning models. The Google data associated with mobility trends for each county had many missing values, with many missing values occurring in blocks. To remedy this, we assumed a linear trend between the start and the end of each missing datapoint block, and interpolated these values accordingly. In addition, matching this county level data with confirmed cases was surprisingly a challenge. We used the New York Times open source data, and cleaned both datasets to correspond with one another. In addition, we tested various models, which was quite computationally expensive; this was due to applying time series cross validation techniques, such as nested cross validation and rolling windows. In the end, we were able to build a more robust and accurate model which could not only predict cases in the future, but model various changes in mobility and how these modifications in social distancing affect cases of coronavirus. We also experienced challenges in gathering Google popular times data, which was not available through the Google Maps API. Our solution meant writing a web scraper which could process large queries.
Accomplishments that we’re proud of
As a team, we brought to the table different skill sets and experiences, as each team member contributed their strengths to the project. We are proud of our collaborative efforts to create an application that emphasizes and fulfills the multidisciplinary nature that a solution for COVID-19 requires. Through the span of this project, we were exposed to various challenges as a result of working with real-time data. However, our ability to work with missing values and to validate the datasets allowed us to create a more robust application that is less dependent on user error and incomplete data.
What we learned
We learned that using Bluetooth to detect close interactions is more accurate than GPS especially when users are inside or in the presence of skyscrapers where GPS location estimates can have a margin of error of around 20 meters. Bluetooth, on the other hand, has an accuracy level on the order of feet. While Google’s Popular Time data provides useful insights into a location's popularity over the course of the day, their figures have yet to take into account massive changes in behavior resulting from the pandemic. We believe that with enough users, our own data will give us a more accurate picture of how many people are frequenting specific locations during the pandemic. We also learned how to develop and test accurate generative machine learning models using various regression methods and cross validation techniques. We learned how to use cross validation techniques and regression metrics to ensure our models were not overfitting, and used ensemble learning to build a robust and scalable model using our unique datasets.
What’s next for Trace
We would like to finetune our bluetooth technology such that we improve our accuracy for calculating interaction distance. In addition, we would like to refine our statistical analysis and machine learning models to achieve higher efficiency. We hope to build a robust backend and remove the need to scrape any public data, as well as build a scalable system for many users to operate on. Our goal is to upload the app to the Apple App Store and Google Play Store to allow all mobile users access to this analysis.
Additional Links
Tableau https://public.tableau.com/profile/alexander.liebeskind#!/
Github https://github.com/thomasundo2/trace_ml
Sources
Google Mobility Data: https://www.google.com/covid19/mobility/
Johns Hopkins Coronavirus Data: https://github.com/CSSEGISandData/COVID-19
The New York Times Coronavirus Data: https://github.com/nytimes/covid-19-data





Log in or sign up for Devpost to join the conversation.