-
-

Logo
-
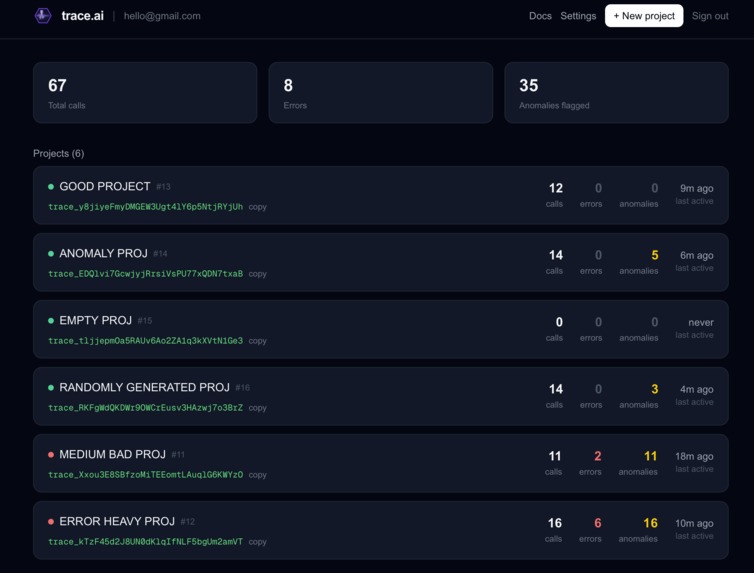
Projects Dashboard
-
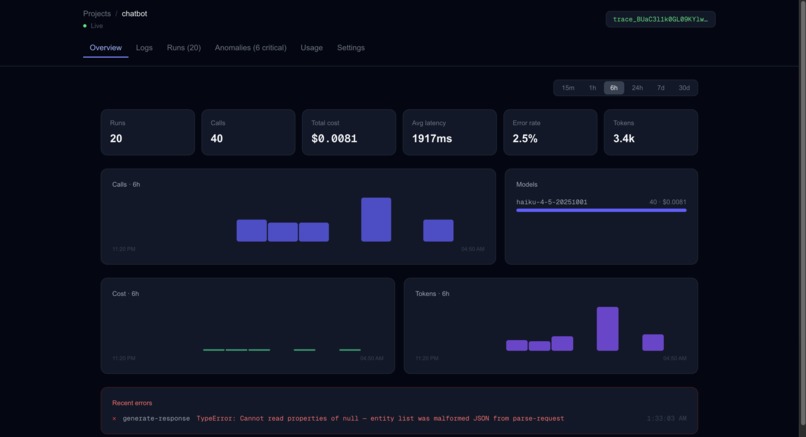
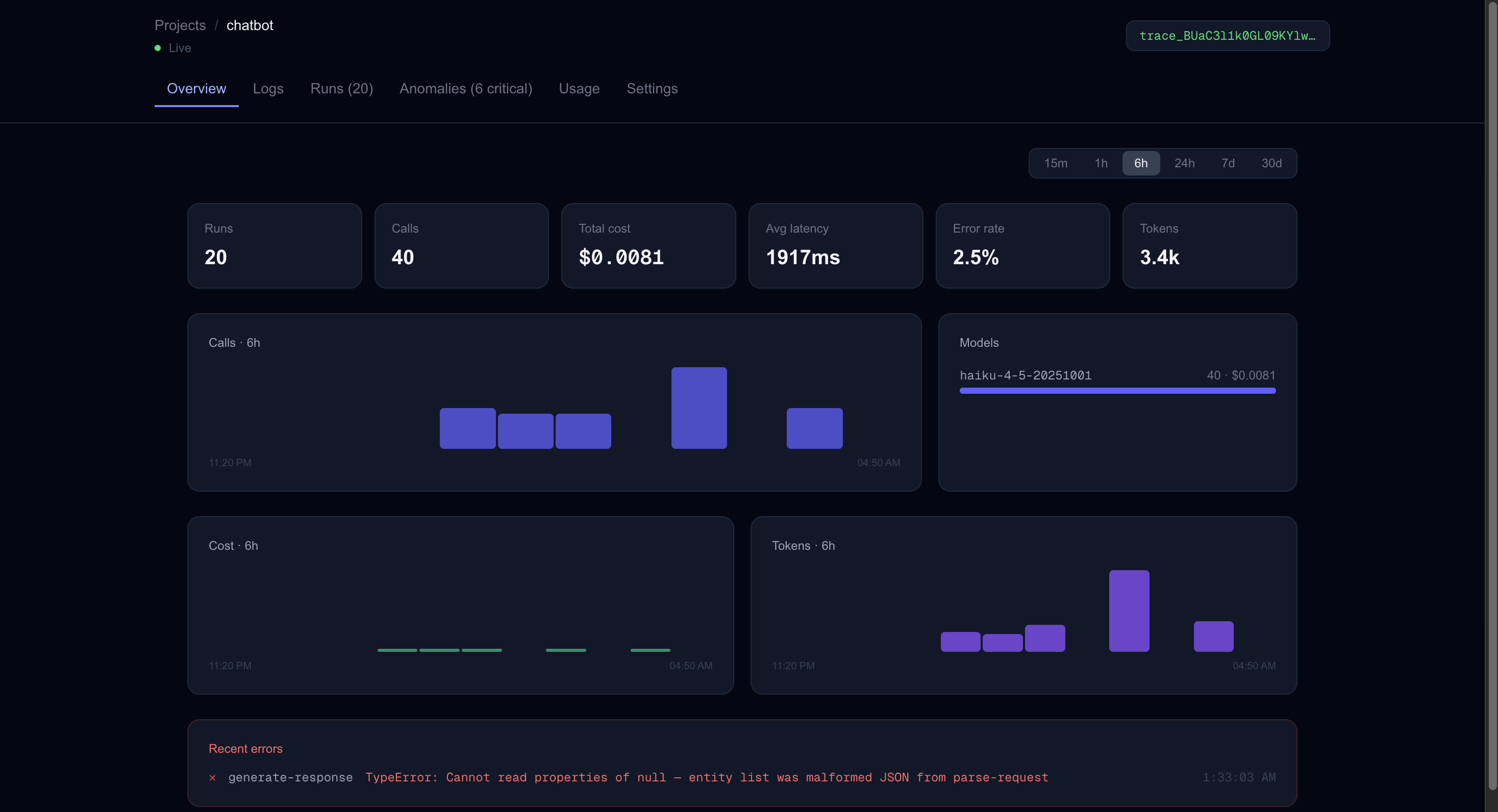
Dashboard Overview
-
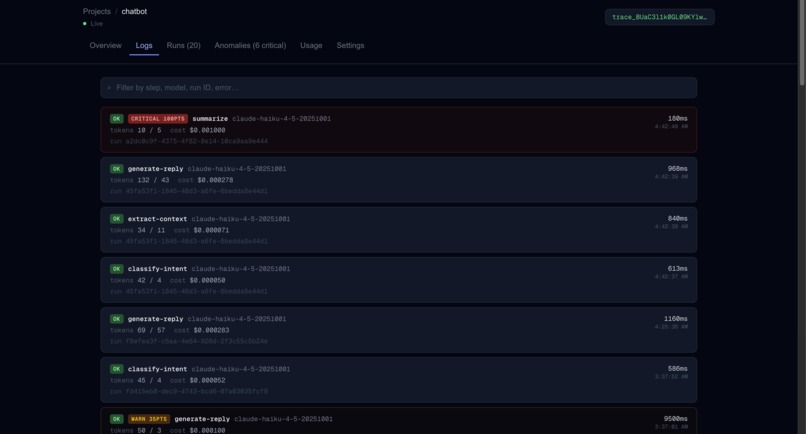
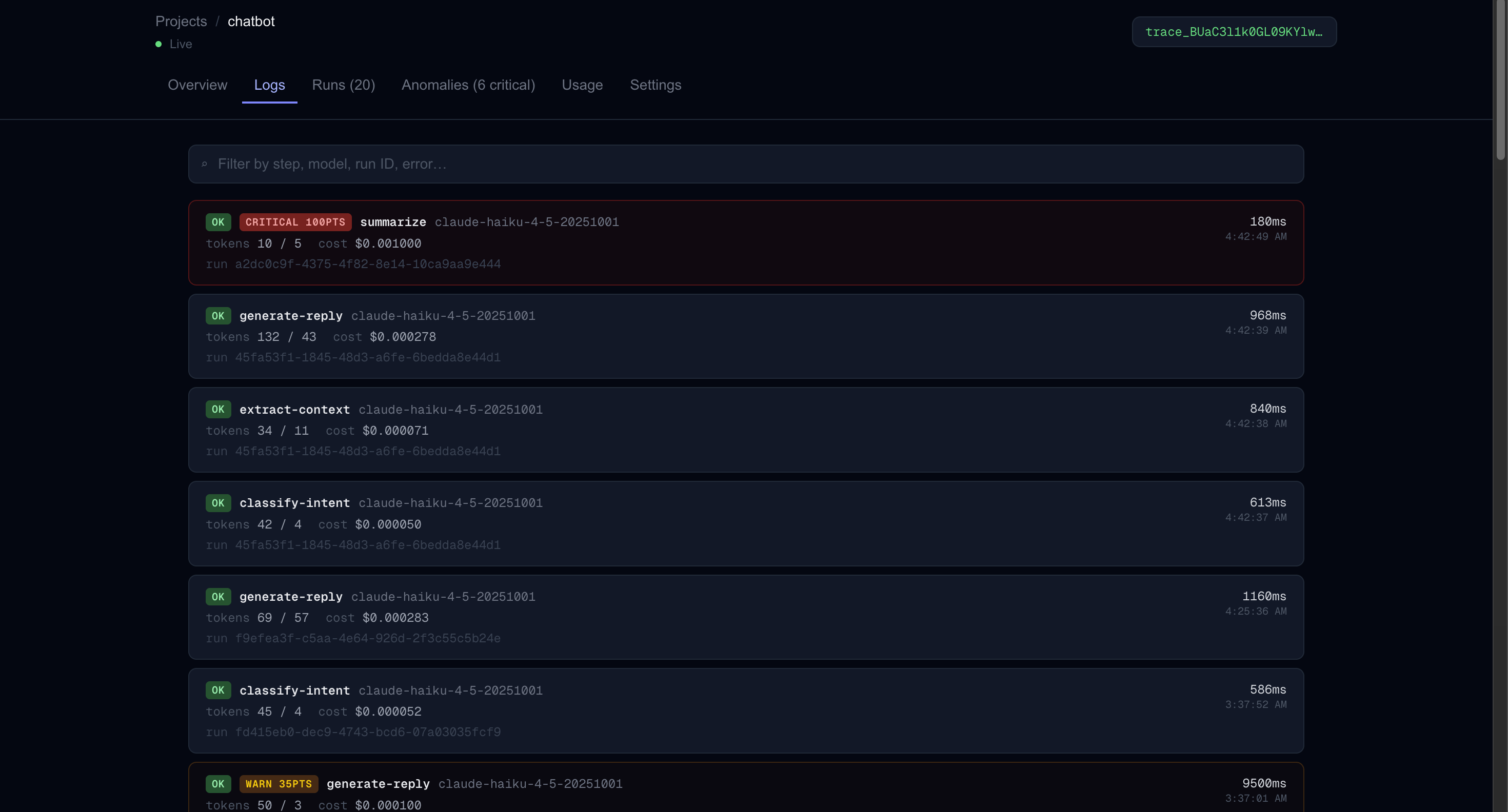
Dashboard Raw Logs
-
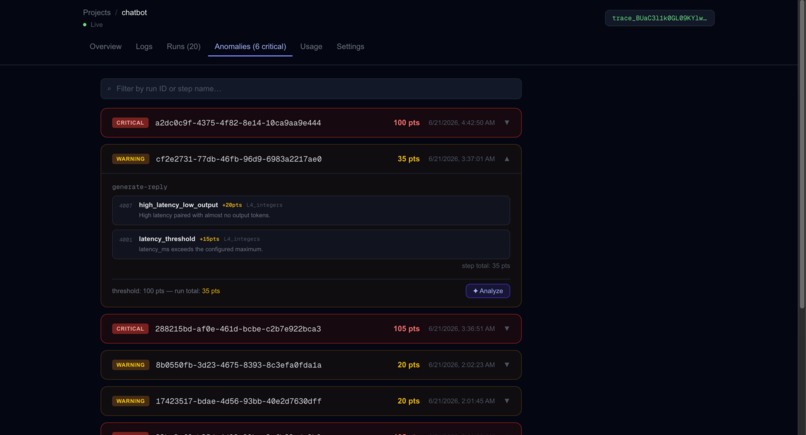
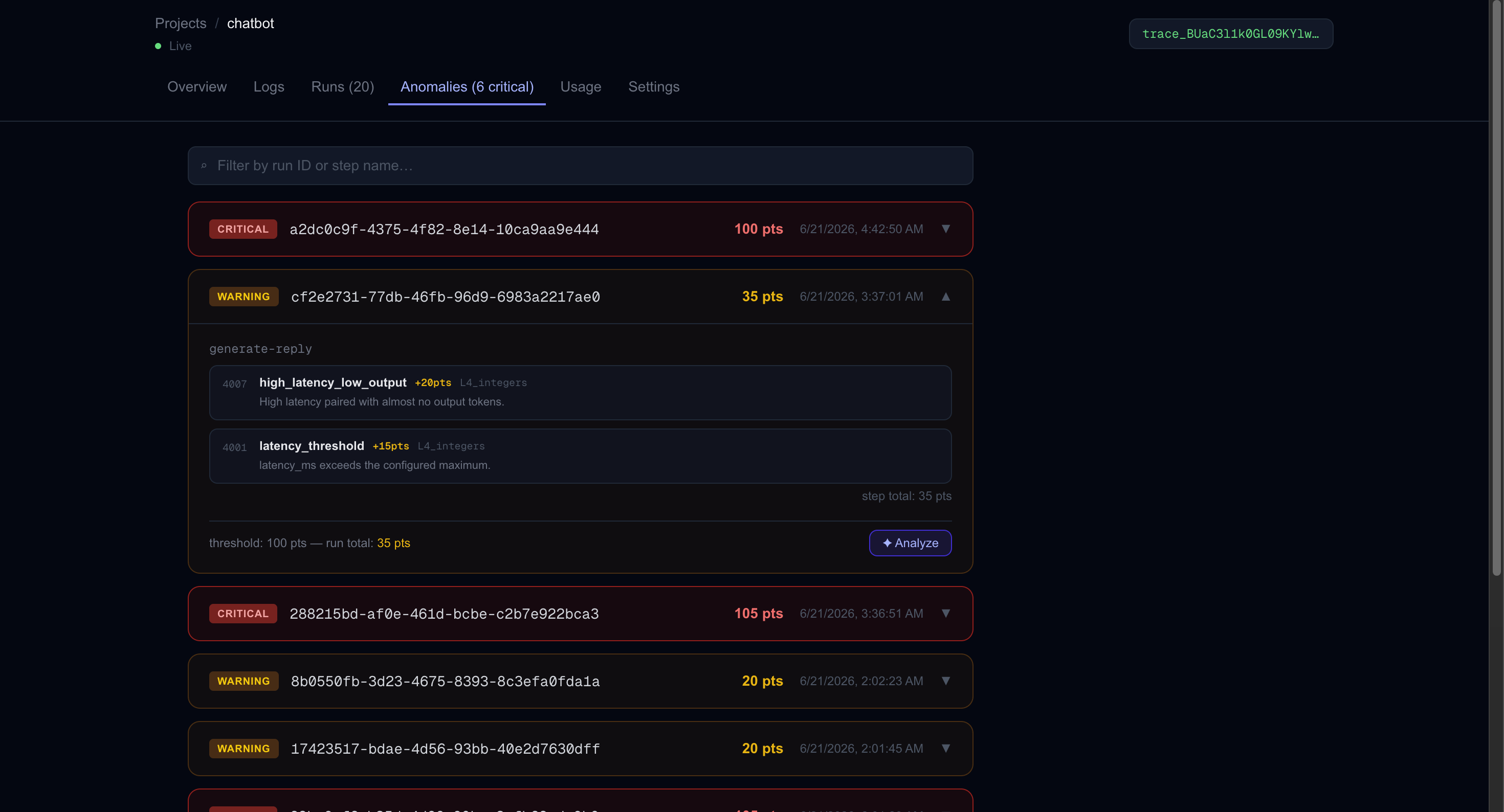
Dashboard Anomalies/Errors
-
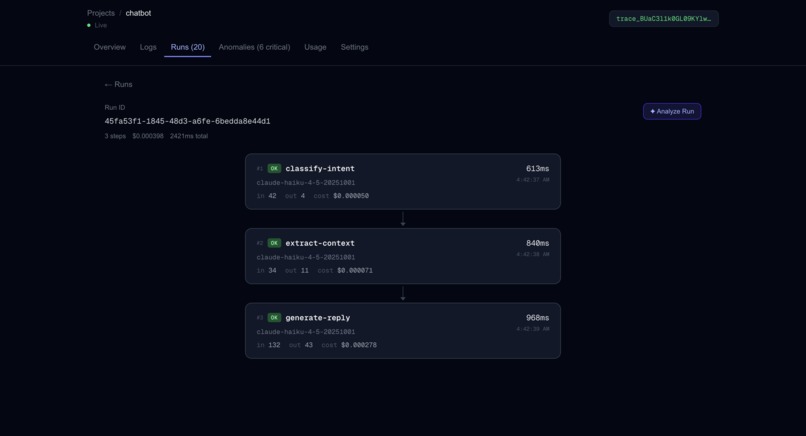
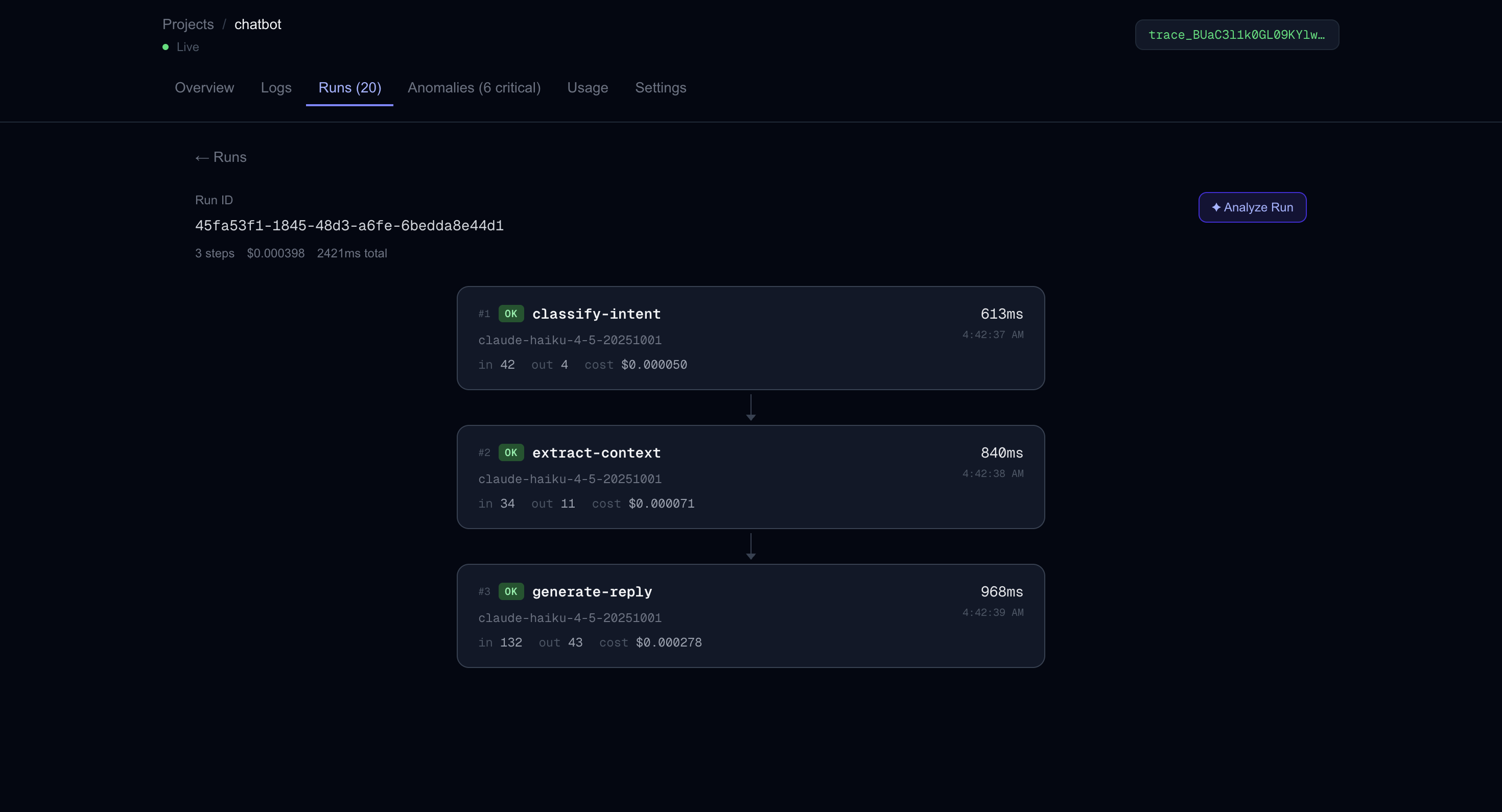
Run ID Graph
-
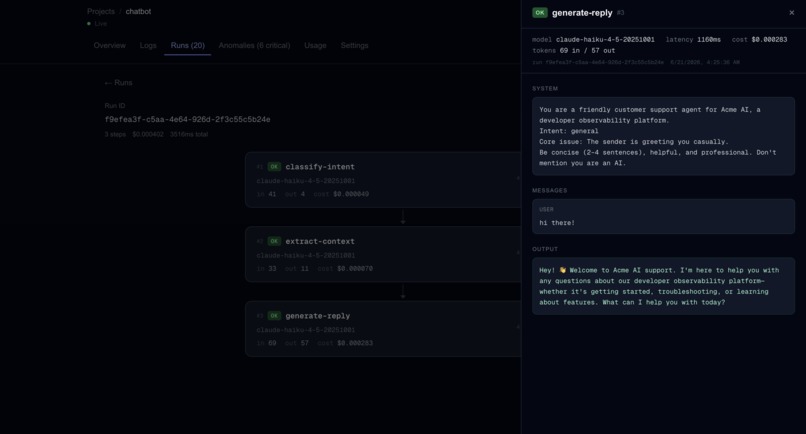
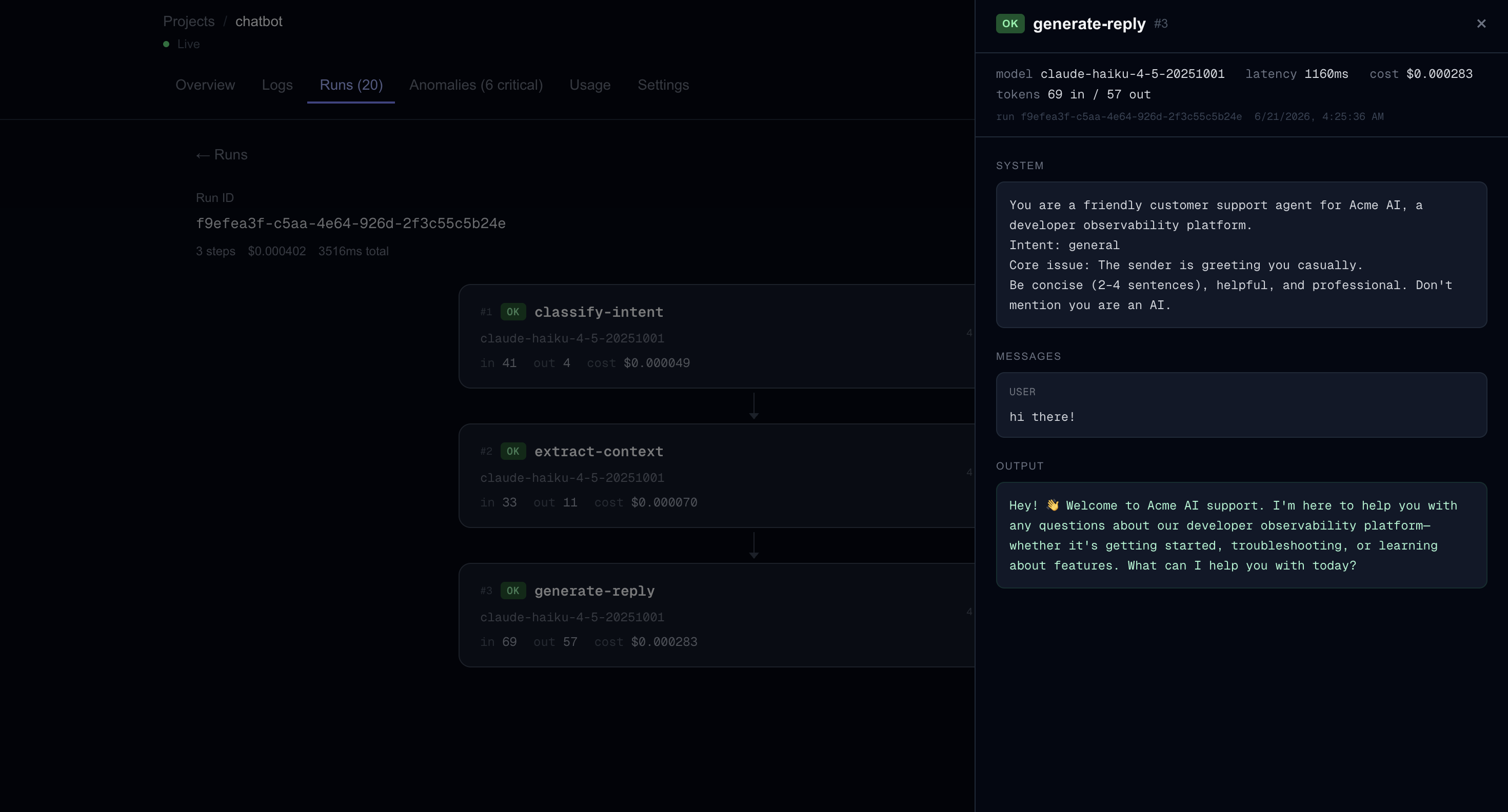
Insights into each call
-
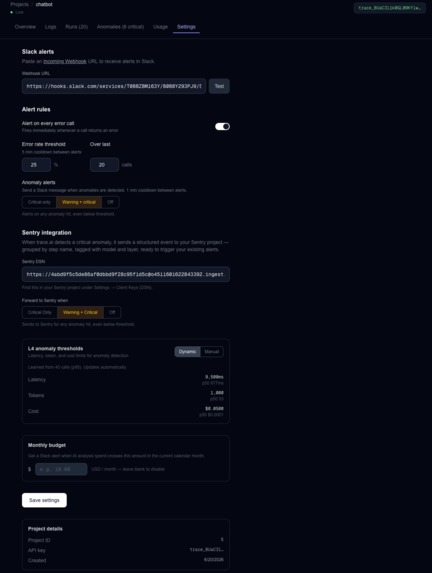
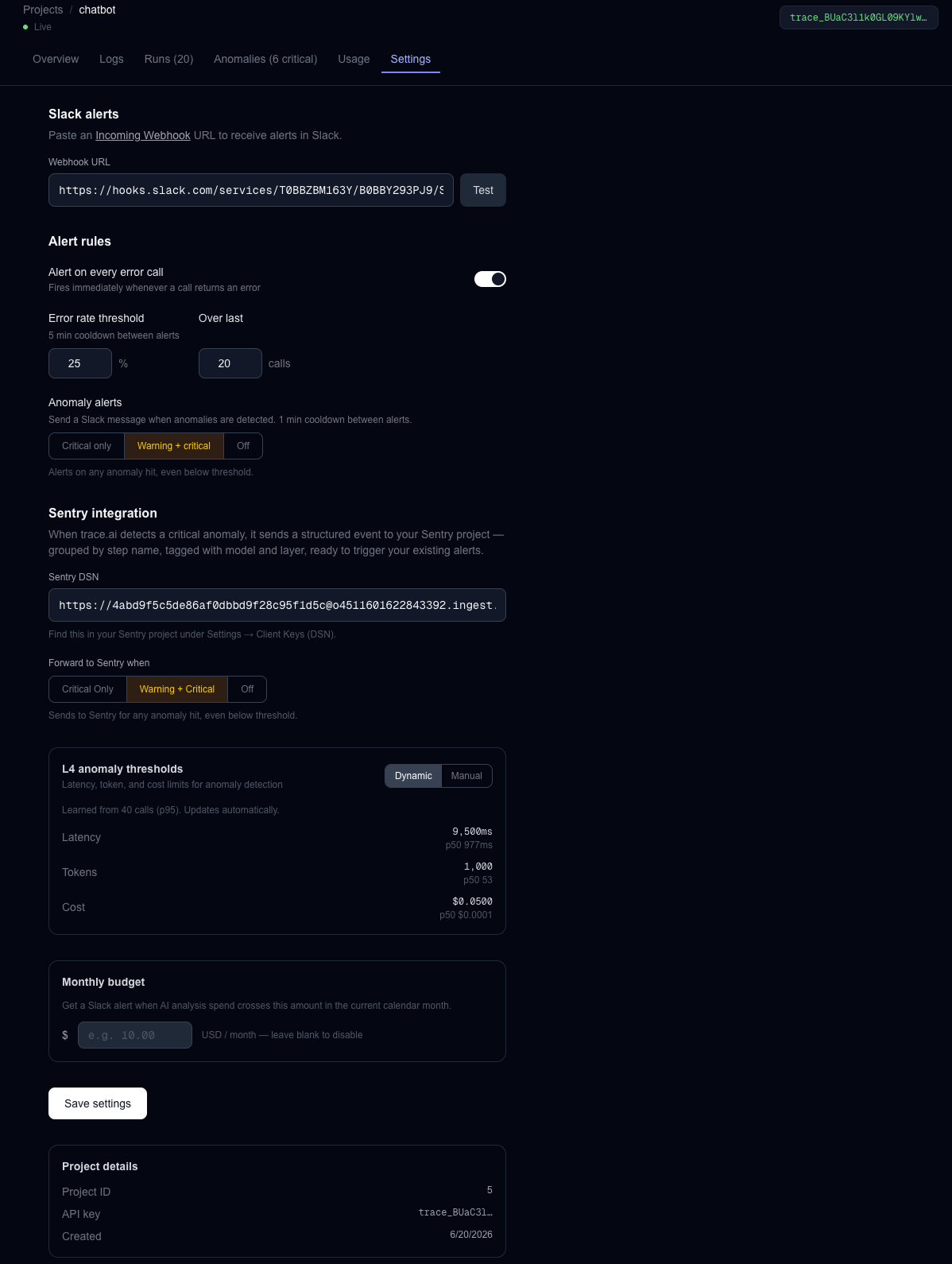
Integrations and Settings
-
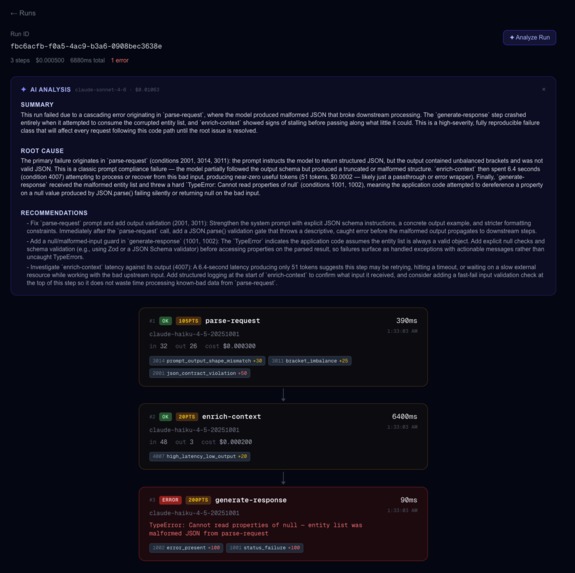
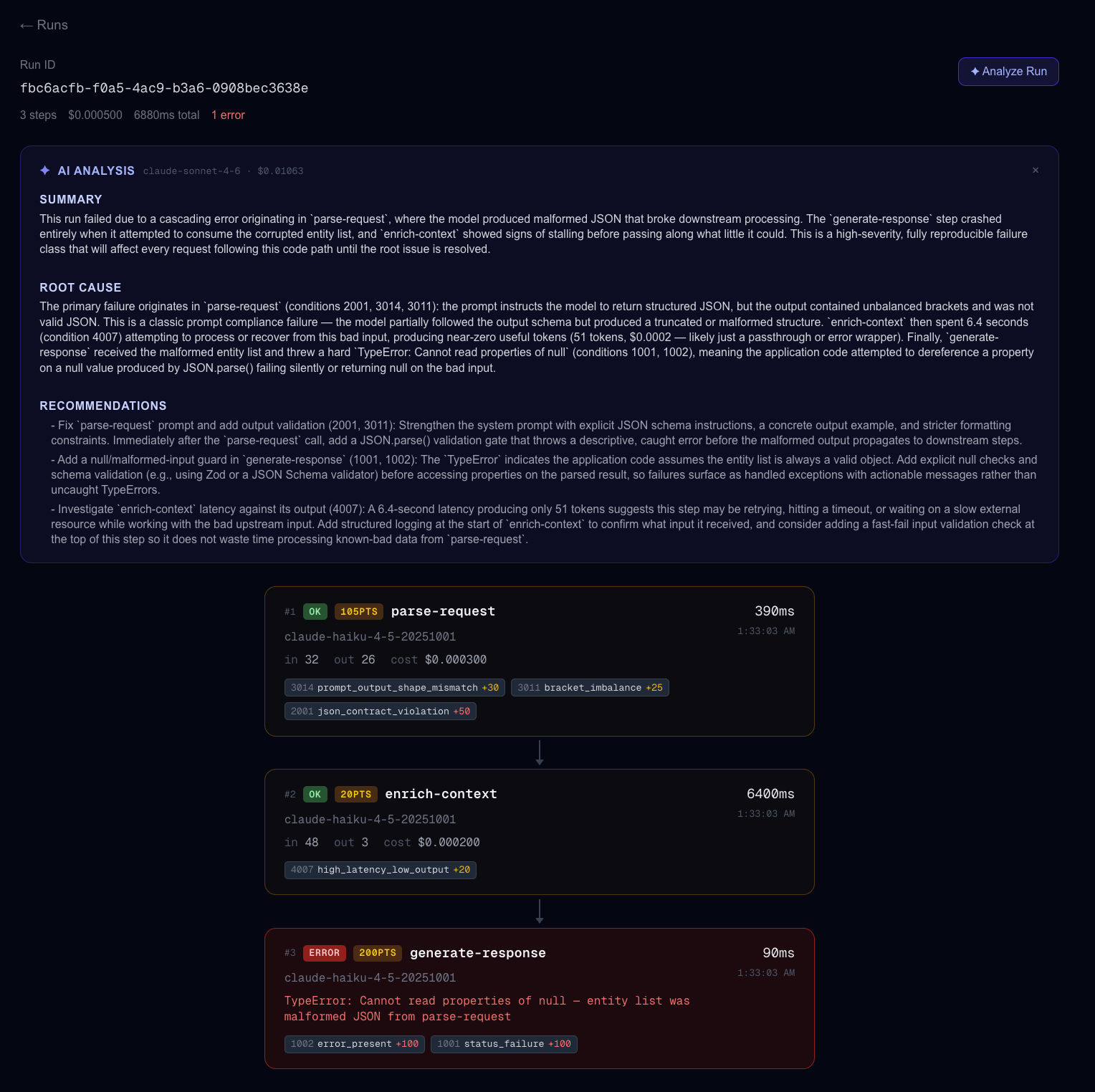
AI Analysis on a Chain Failure
-
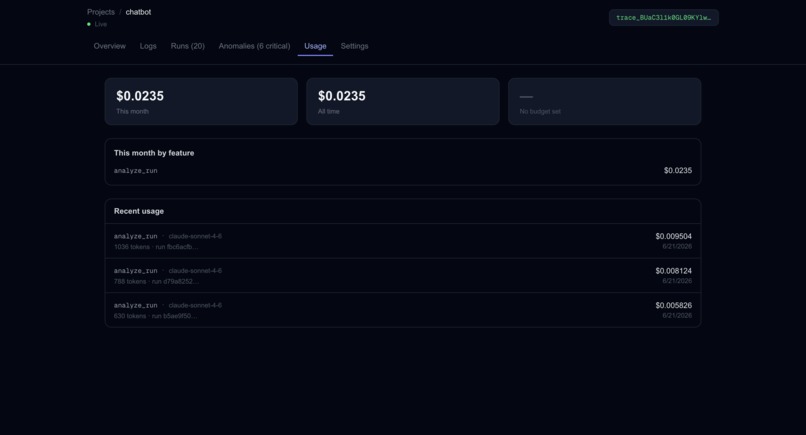
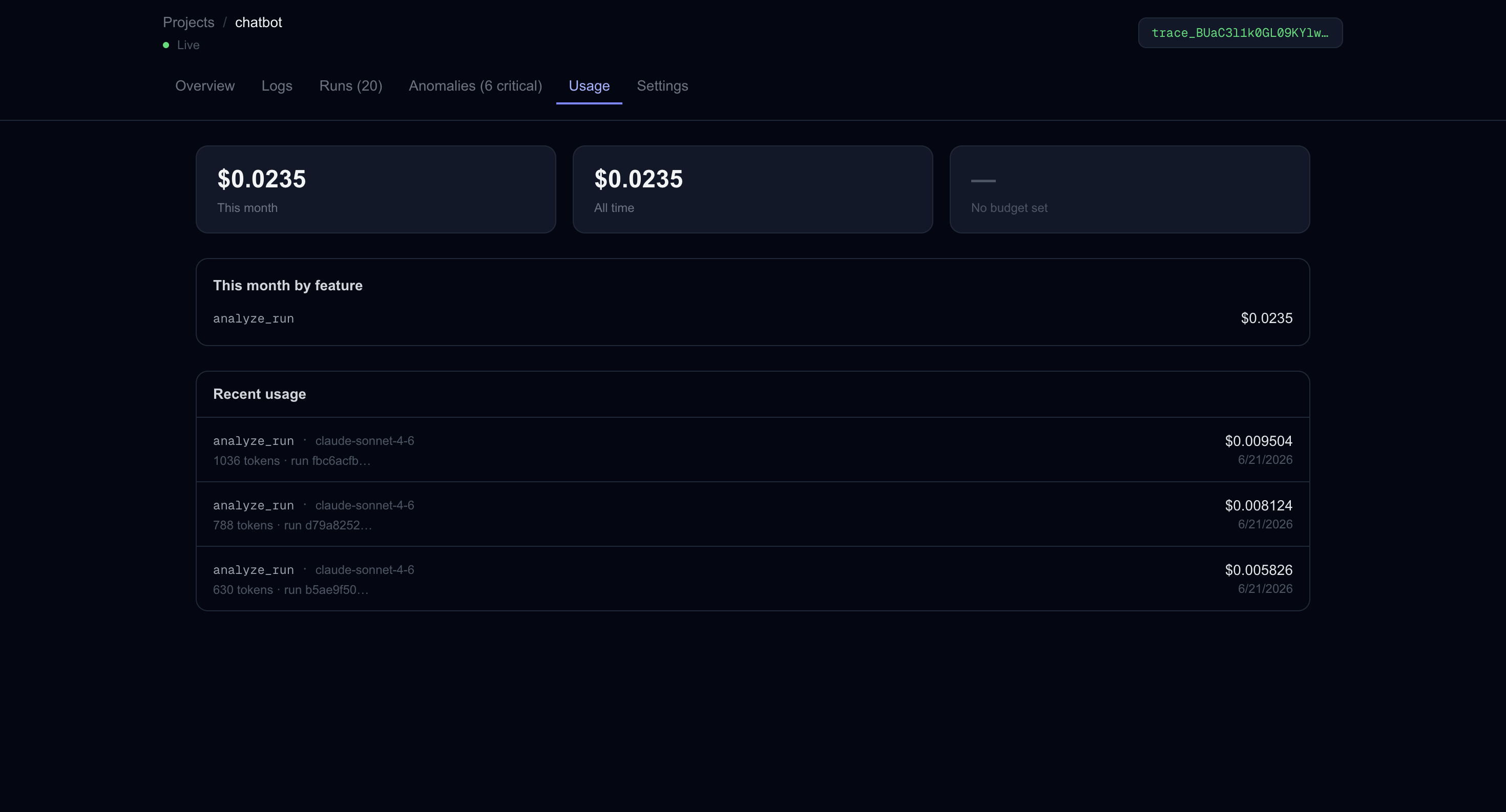
LLM Feature Usage

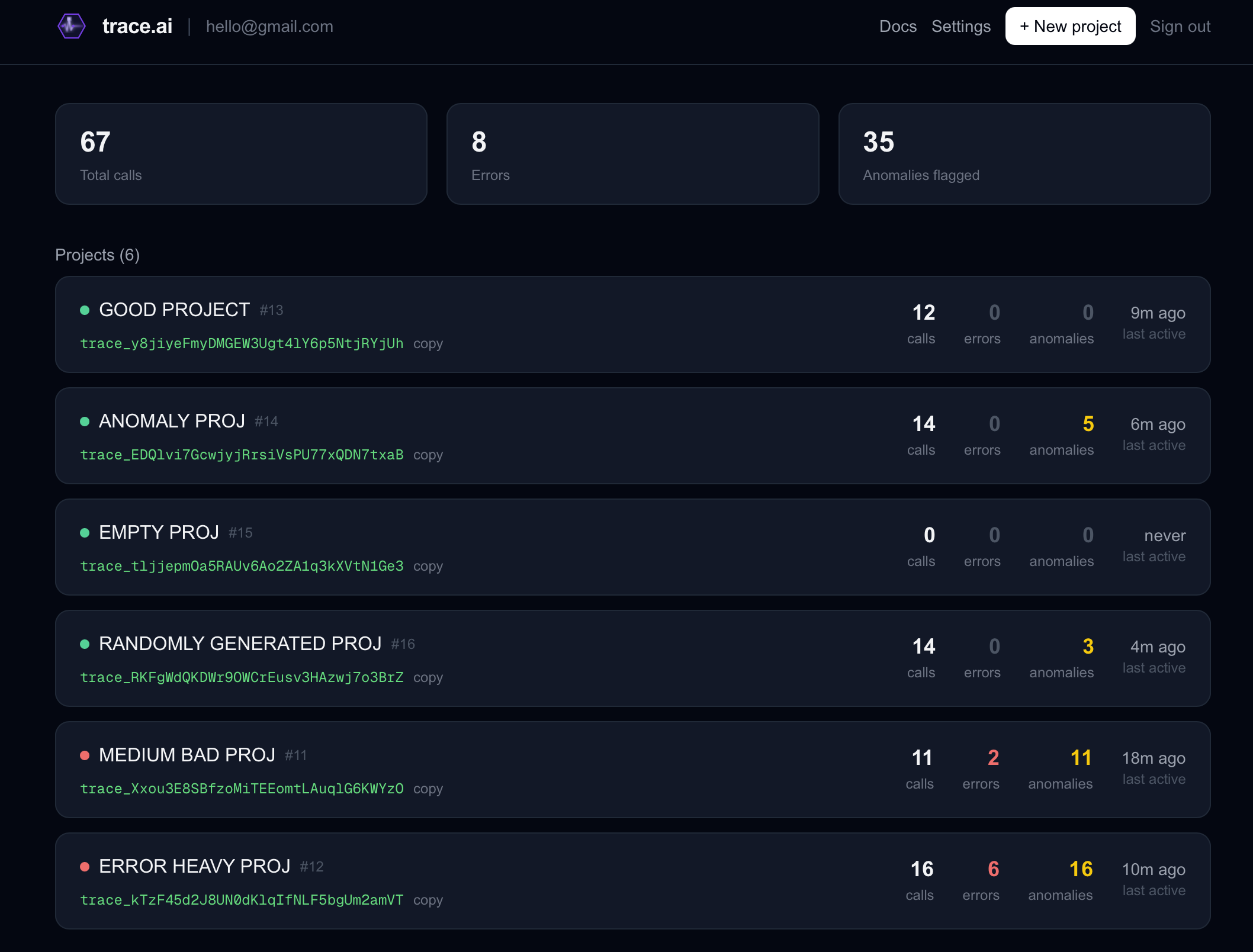
Inspiration
We kept running into the same problem building AI features: something breaks in production and you have no idea where. The model returned garbage, a step timed out, costs spiked — but your logs just show a 500. Datadog and Sentry are great for traditional software but have no concept of tokens, prompts, or multi-step LLM pipelines. We wanted to build the observability layer that AI teams actually need.
What we built
trace.ai wraps your Anthropic calls with one line of code and captures every step of your AI workflow — tokens, latency, cost, model, prompt, and output. A 4-layer anomaly detection engine scores each call in real time, fires Slack and Sentry alerts when something breaks, and an AI-powered analysis feature (built on Claude) traces cascade failures back to their root cause. Thresholds adapt automatically to each project's baseline using p95 statistics from recent call history.
How we built it
- SDK: TypeScript package (
@trace-ai/sdk) that wrapsmessages.createandmessages.stream, fire-and-forget ingestion to avoid adding latency - Backend: FastAPI on Railway with Supabase — anomaly scoring runs in a background thread on every ingest so it never blocks the response
- Anomaly engine: 4 layers (hard failures → format checks → output fingerprinting → numeric/performance), each with static penalties that accumulate into a total score checked against a dynamic p95 threshold learned from the project's history
- Sentry integration: every LLM step emits a Sentry Performance transaction using OpenTelemetry GenAI semantic conventions (
gen_ai.usage.input_tokens, etc.) — all steps in a run share atrace_idderived from therun_idso Sentry reconstructs the full pipeline in its distributed tracing view. Anomaly events are sent separately with fingerprinting so repeated failures group into a single Sentry issue. - Frontend: Next.js dashboard with run timelines, anomaly breakdowns, and a Claude-powered "Analyze Run" feature that reads all steps and explains what went wrong
Challenges
The hardest part was false positives. Early versions flagged constantly because a chat app stores the full message history in the prompt — so format checks were finding "json" in conversation history and triggering incorrectly. We solved it by parsing SDK-format prompts to extract just the instruction before scoring. Dynamic thresholds were the other big challenge: mean + 2σ breaks down for skewed distributions like latency, so we switched to p95 which handles mixed workloads correctly.
Built With
- anthropic
- fastapi
- nextjs
- postgresql
- python
- supabase
- typescript
- websockets

Log in or sign up for Devpost to join the conversation.