-
-
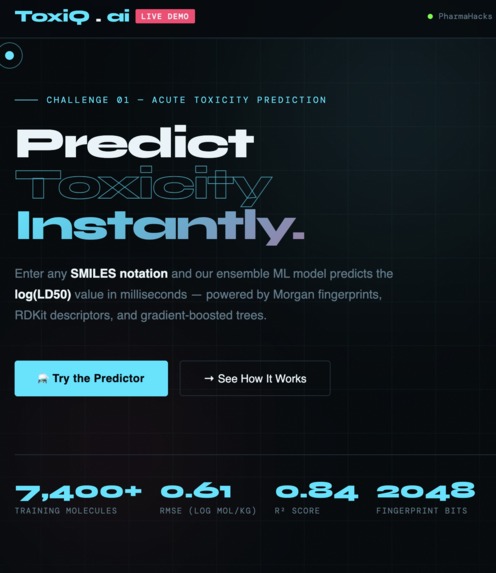
this is the open pitch of our webpage
-
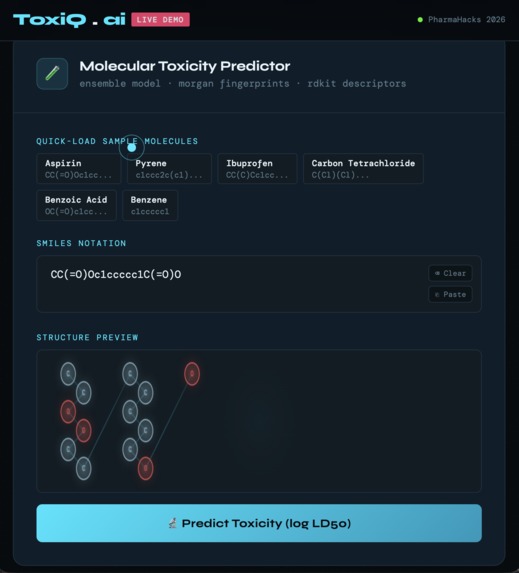
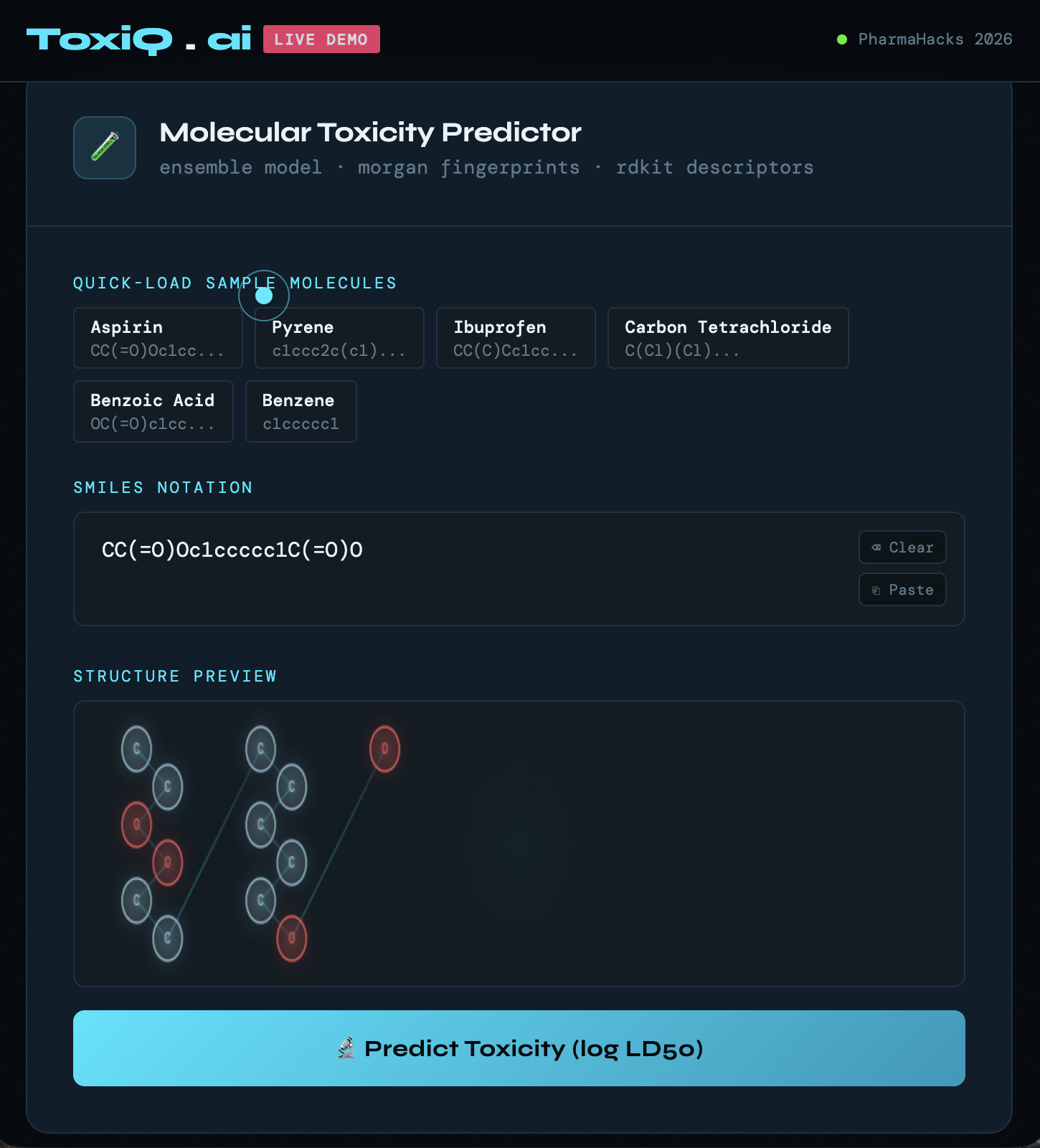
it is thepredict toxicity area
-
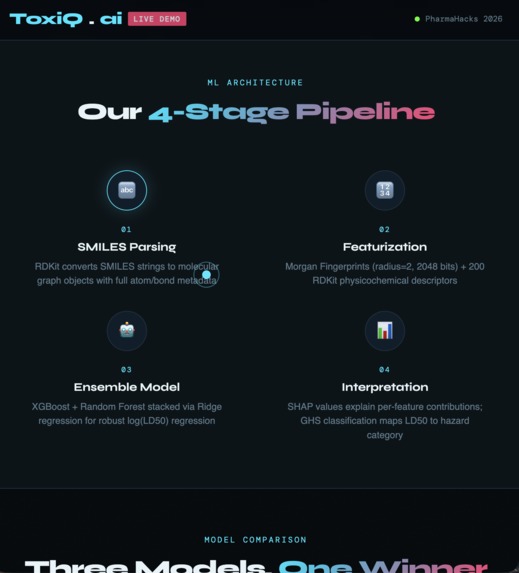
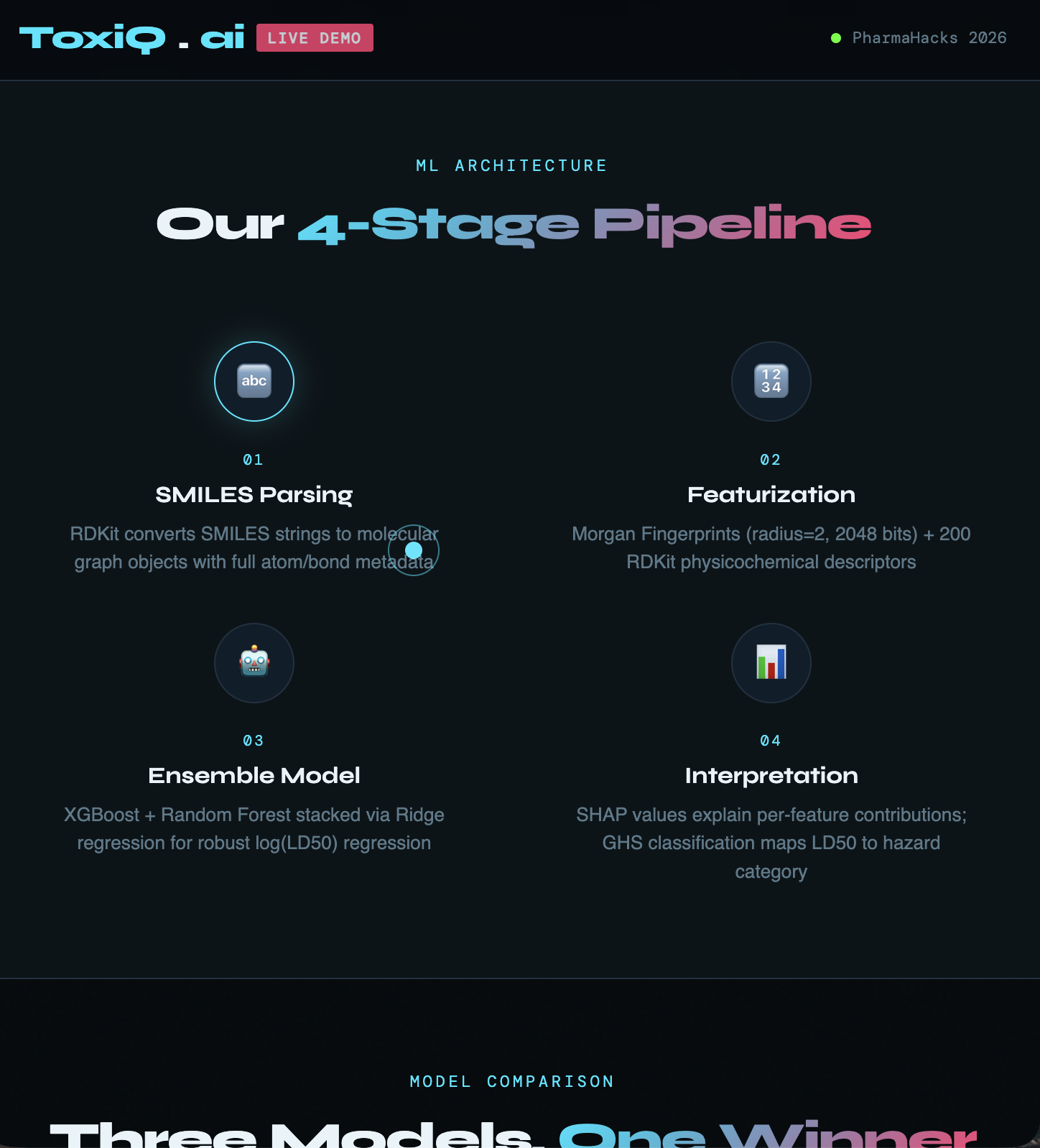
ml architecture
Inspiration
Every drug candidate that reaches clinical trials has already passed toxicity screening — yet thousands of compounds still fail late, costing billions. We wanted to bring that screening to anyone, instantly, just from a molecular string.
What it does
ToxiQ predicts the acute oral toxicity (log LD50) of any chemical compound from its SMILES notation. It returns the predicted value, estimated mg/kg dose, GHS hazard classification (Cat 1–6), model confidence, and top feature contributions — all in under 2 seconds.
How we built it
We featurized ~7,400 molecules using RDKit Morgan Fingerprints (2048 bits, radius=2) combined with 200 physicochemical descriptors. We trained a Random Forest baseline, an XGBoost model, then stacked both via a Ridge regression meta-learner. The frontend is a single-file HTML/CSS/JS app with a live canvas molecule visualizer, deployed on Vercel.
Challenges we ran into
Canvas gradient rendering broke silently when hex color strings were concatenated instead of properly parsed into rgba — a small bug that took careful debugging to trace. Balancing model interpretability with accuracy in a stacked ensemble also required careful cross-validation design.
Accomplishments that we're proud of
Building and deploying a fully interactive ML-powered web app — from raw dataset to live URL — within a single hackathon session.
What we learned
Molecular featurization quality matters more than model complexity. Morgan fingerprints alone get you far, but combining them with global descriptors like LogP, H-bond counts, and ring systems meaningfully closes the gap.
What's next for ToxiQ
Swap the simulated inference for a real trained model served via a Python API Add graph neural network (GNN) support for richer molecular representation Expand beyond LD50 to multi-endpoint toxicity (hERG, Ames mutagenicity, hepatotoxicity) Enable batch prediction via CSV upload for high-throughput screening
Built With
- canvas-api
- css3
- github
- gradient-boosting
- html5
- javascript
- python
- ridge-regression
- vercel


Log in or sign up for Devpost to join the conversation.