-

word cloud (of the non-toxic comments, of course :) )
-
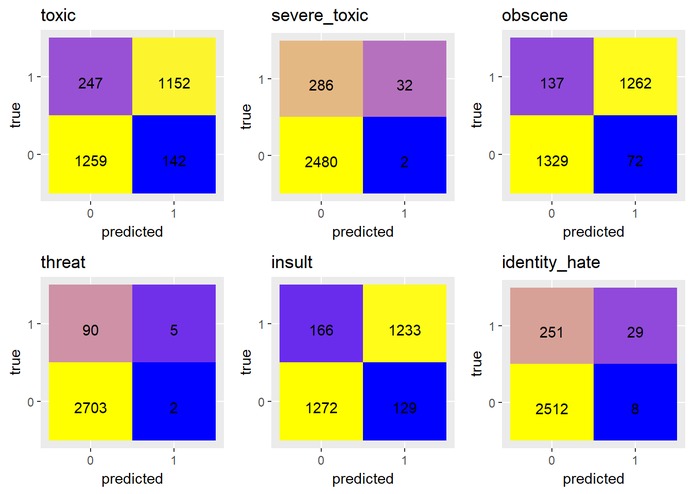
confusion matrix for SVM model


It is difficult to balance the desire to keep conversations safe while also ensuring freedom of speech. Online spaces are an especially tricky terrain to navigate, because people communicate without speaking face-to-face, and are therefore shielded by the mask of anonymity.
In this project, we trained machine learning models to suggest if a textual comment should be classified under one or more categories of "toxic." The dataset we used was a collection of crowd-labeled Wikipedia talk page comments from Kaggle. We were able to achieve an out-of-sample ROC AUC of around 0.95: this is quite good, although not competitive on the Kaggle leaderboard.
Despite the ample room for improvement, we still think our project can help improve society's ability to detect and respond to hurtful online comments. We used a different platform (R instead of python) and different algorithms (SVM and LogitBoost instead of LSTM and NB) than to many of the top-ranking kernels, so perhaps studying our differences will help elucidate the strengths and weaknesses of the top submissions. In addition, by documenting our work, we might be able to help beginners work on this dataset for educational growth.
Overall, this project has been a great learning experience for us! It was satisfying to build a working model within a day, and we hope to clean it up in the coming week or so :)
Nerdy stuff about the algorithms
We explored a few different models, specifically LDA, L-LDA, LSA, SVM, LogitBoost, and neural networks. Some of these did not perform well; others we were unable to implement. Our best result was an ensemble of out-of-the-box SVM and LogitBoost models, both with linear kernels, built separately for each type of toxic comment. These were taken from the rtexttools library. We combined them for the final ensemble method by taking the means of their prediction probabilities, except where LogitBoost returned a value of .5, which seemed to be a default value if it has no "opinion." For these observations, we simply used the SVM probability.
The solid performance of our out-of-the-box result is promising! Due to time restraint, we trained on only a small subset of our data, and did not bother with hyperparameter tuning. In addition, we did hardly any text cleaning or cross-validation. Implementing these in our model-building process should definitely result in stronger future performance.
Built With
- r
- rstudio
Log in or sign up for Devpost to join the conversation.