-
-
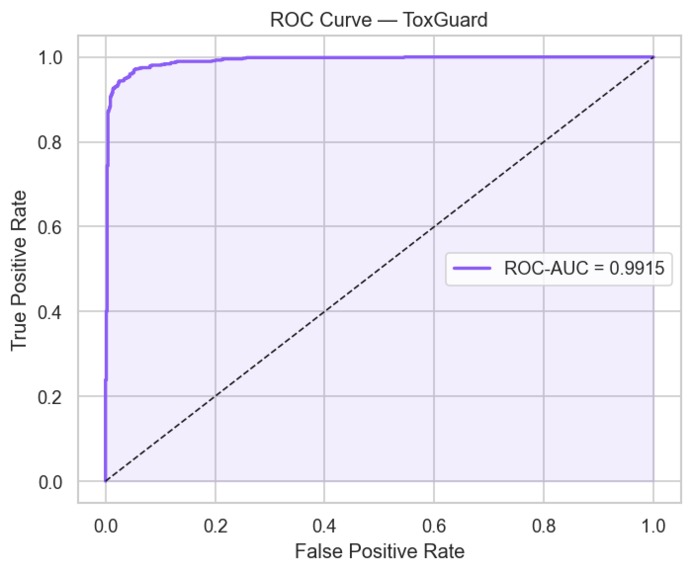
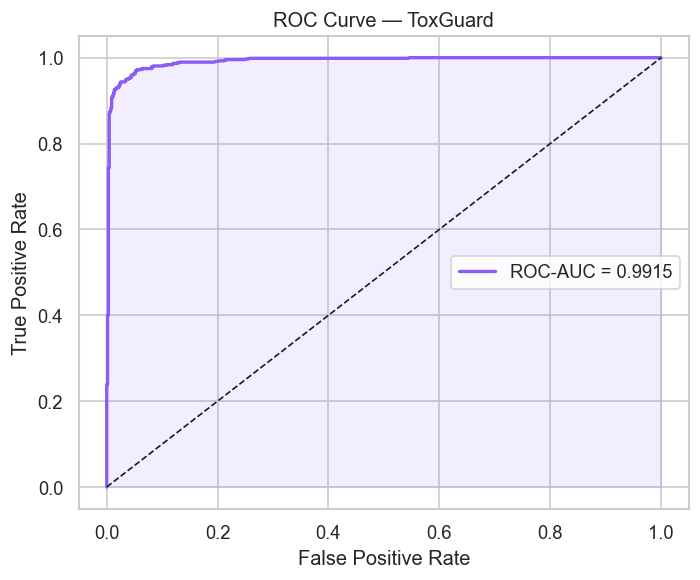
(ROC Curve): Precision Mastery: 0.9915 ROC-AUC Score
-
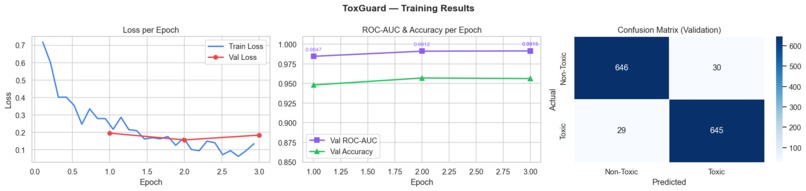
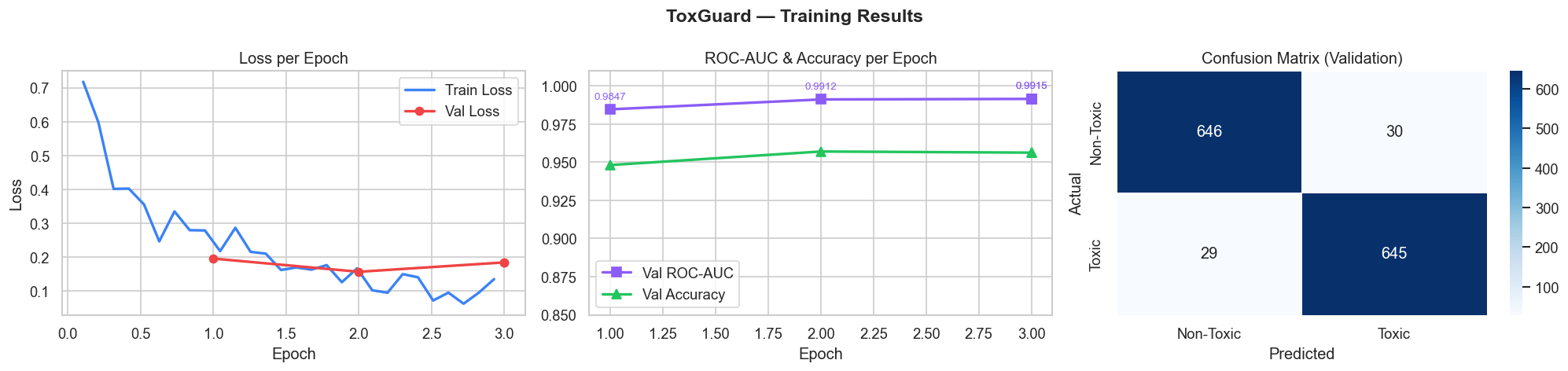
(Training Results): ToxGuard Training Stability & Validation
-
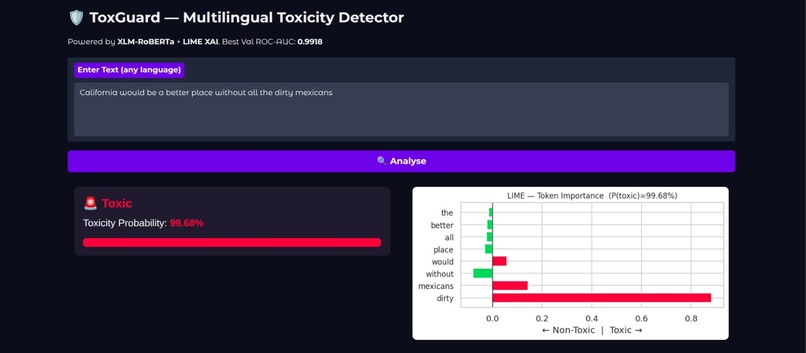
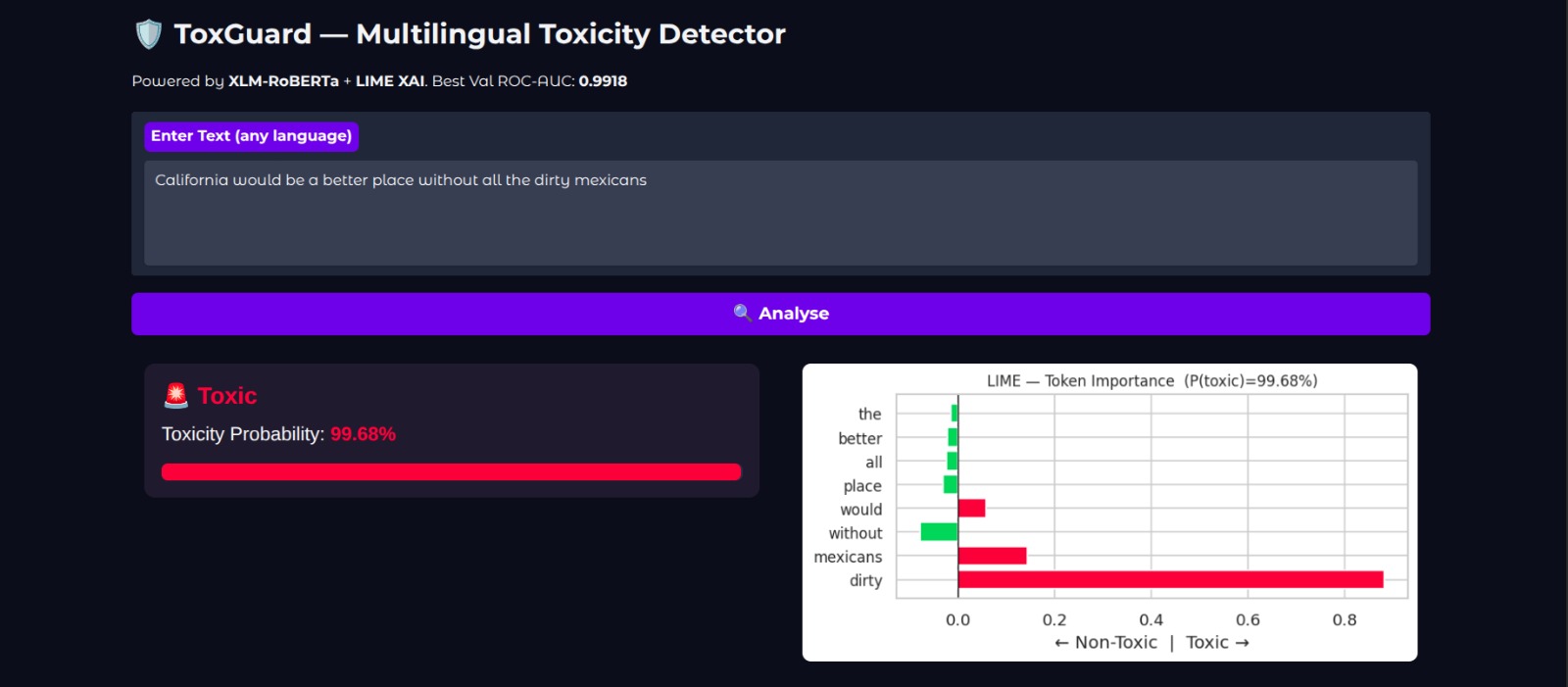
Toxic 99.68% ToxGuard — Racial Hate Speech Detection with LIME XAI (99.68% Toxic)
-
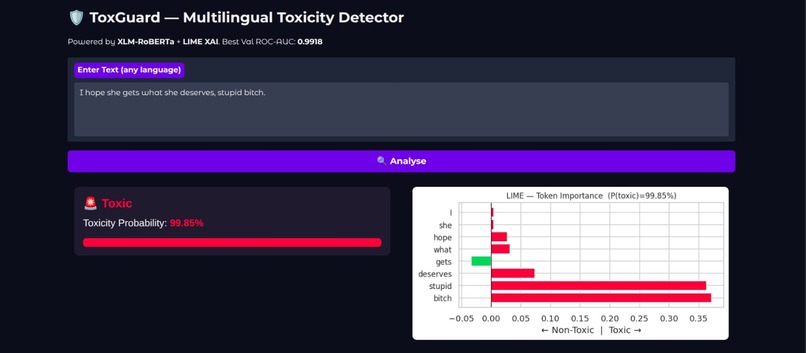
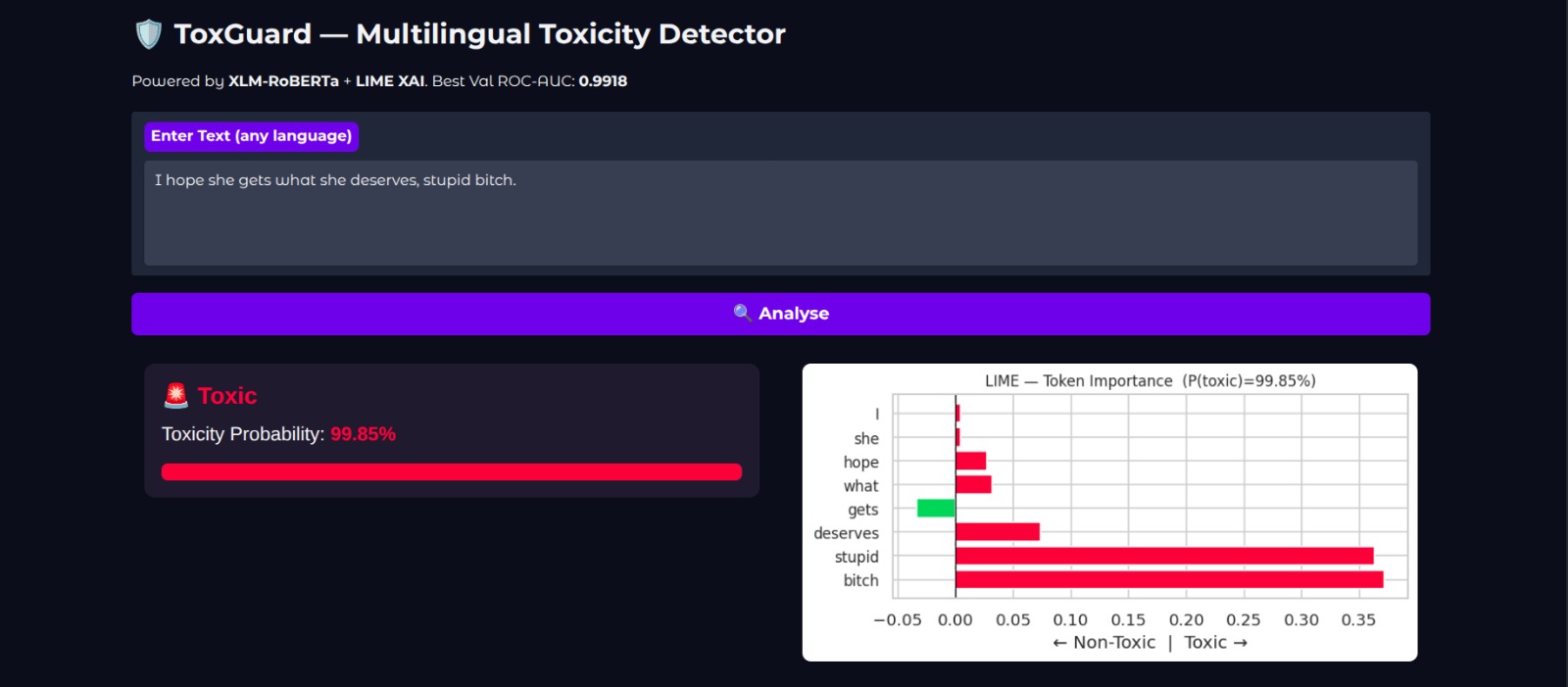
Toxic 99.85% ToxGuard — Gendered Toxic Comment Detected (99.85% Toxic, LIME XAI)_
-
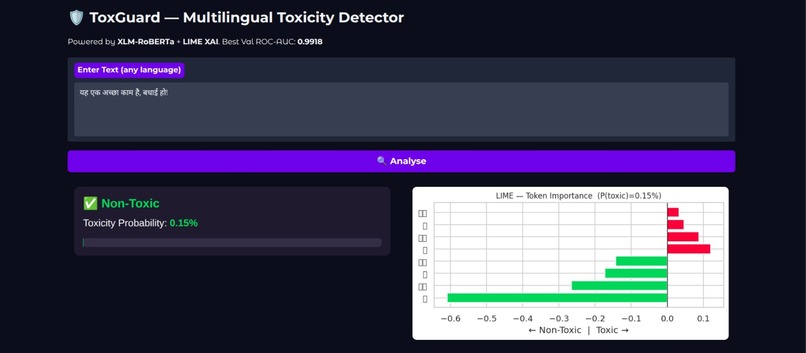
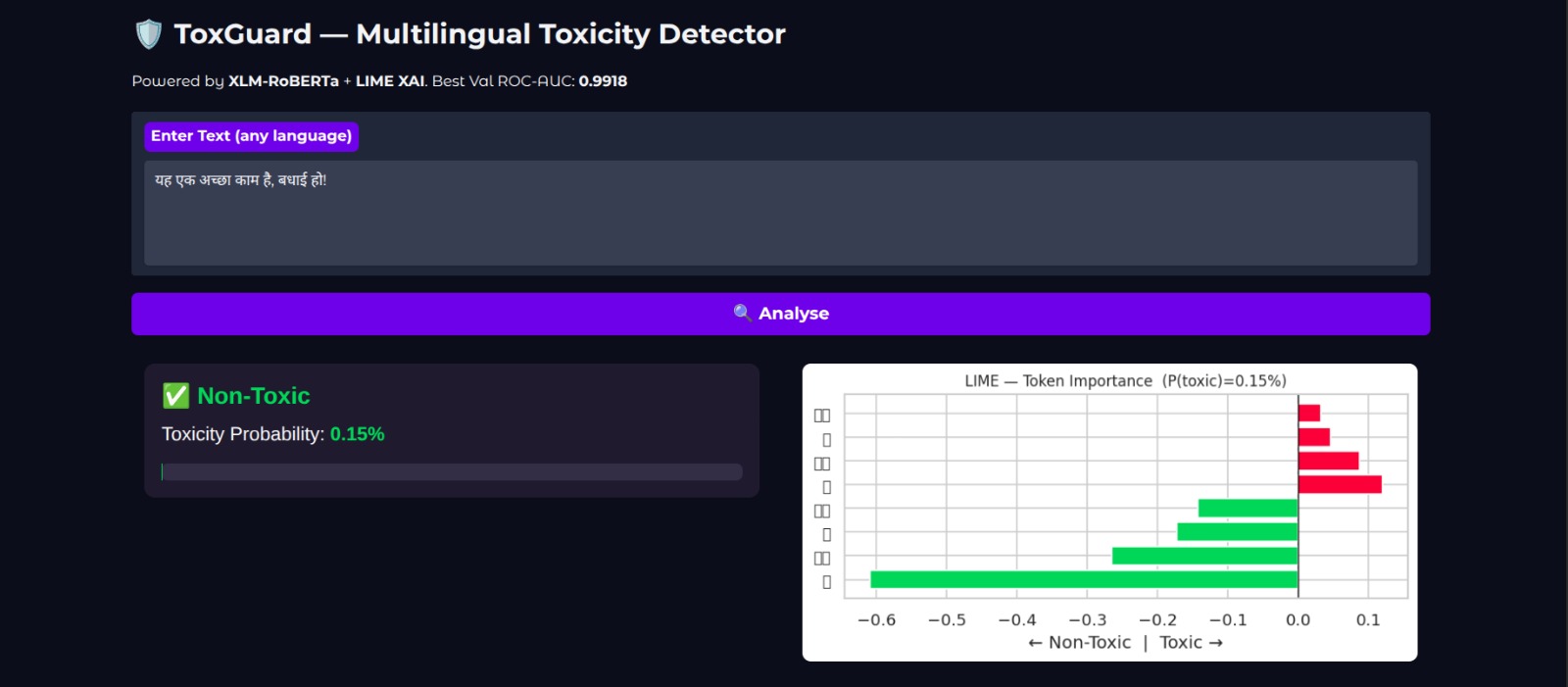
Non-Toxic 0.15% ToxGuard — Hindi Text Classified as Non-Toxic with LIME Explanation
ToxGuard — Multilingual Toxic Comment Detection
Inspiration
Online hate speech and toxic comments represent a growing challenge for digital platforms worldwide. The majority of existing content moderation systems are designed primarily for English, leaving significant gaps in protection for users communicating in other languages.
ToxGuard was developed to address this limitation by building a single unified model capable of detecting toxic content across multiple languages — eliminating the need for separate, language-specific moderation systems and enabling more inclusive content safety at scale.
What We Built
ToxGuard is a multilingual toxic comment classification system fine-tuned on XLM-RoBERTa Base. The system classifies user-generated text as Toxic or Non-Toxic and incorporates Explainable AI techniques — specifically LIME and transformer attention heatmaps — to provide interpretable, auditable predictions suitable for real-world moderation pipelines.
Results
| Epoch | Train Loss | Val Loss | ROC-AUC | Accuracy |
|---|---|---|---|---|
| 1 | 0.5420 | 0.4736 | 0.9805 | 91.48% |
| 2 | 0.3216 | 0.2758 | 0.9901 | 95.19% |
| 3 | 0.2124 | 0.3445 | 0.9918 | 95.26% |
- Best Validation Mean ROC-AUC: 0.9918
- Best Accuracy: 95.26%
- Training Samples: 7,646 | Test Samples: 999
Links
System Architecture and Pipeline
The end-to-end pipeline was structured as follows:
- Dataset Ingestion — Automatic detection and loading of
.csvand.xlsxfiles from Kaggle input directories - Preprocessing — Null value removal, whitespace normalization, and label column standardization
- Data Splitting — Stratified 85/15 train-validation split to preserve class distribution
- Tokenization — XLM-RoBERTa SentencePiece tokenizer with a maximum sequence length of 128 tokens
- Model Fine-Tuning — Hugging Face Trainer API with AdamW optimizer, learning rate of 2e-5, warmup ratio of 0.1, and weight decay of 0.01
- Checkpoint Selection — Best model selected based on highest validation Mean ROC-AUC score
- Evaluation — Confusion matrix, ROC curve, precision-recall analysis, and full classification report
- Explainability Integration — LIME token importance and last-layer attention heatmap visualization
- Deployment — Interactive Gradio application with real-time inference and live explanation output
Explainable AI
A core design goal of ToxGuard was transparency. The system incorporates two complementary explainability methods:
LIME (Local Interpretable Model-Agnostic Explanations)
Identifies the contribution of individual tokens toward the final classification decision, highlighting which words drive the model toward a Toxic or Non-Toxic prediction.
Attention Heatmaps
Visualizes token-level attention weights from the final transformer layer, providing a secondary view of where the model focuses during inference.
These features make ToxGuard suitable for deployment contexts where predictions must be explainable, auditable, and defensible — not just accurate.
Interactive Demo
The Gradio-based application provides the following capabilities:
- Text input in any of the multiple supported languages
- Real-time binary classification with probability scores
- Visual toxicity probability indicator
- Live LIME explanation chart generated per prediction
🔗 Try it live: https://huggingface.co/spaces/ayushtiwari18/toxgaurd
Challenges
Multilingual Text Handling
Processing text across different scripts, linguistic structures, and code-mixed inputs required careful tokenization strategy and preprocessing design.
Environment-Specific File Handling
Kaggle input paths reference directories rather than individual files. This required implementing glob-based auto-detection to correctly identify dataset files at runtime.
Library Compatibility
Recent updates to the Hugging Face Transformers and Hub libraries introduced parameter
deprecations — specifically evaluation_strategy and use_auth_token — which required
targeted fixes during development.
Subword Tokenization and Explainability
Generating word-level LIME explanations from SentencePiece subword tokens required additional post-processing to produce human-readable output.
Key Learnings
- Cross-lingual transfer learning via XLM-RoBERTa generalizes effectively across languages, including code-mixed inputs such as Hindi-English
- ROC-AUC is a significantly more informative metric than accuracy for imbalanced classification tasks
- Explainability tools such as LIME serve both as a debugging mechanism and a validation layer for model behavior
- Preprocessing quality and evaluation strategy have a measurable impact on final model performance
Future Work
- Extend classification to a multi-label schema covering threat, insult, identity-based hate, and obscenity categories
- Deploy as a production-grade REST API for real-time platform integration
- Improve performance on low-resource languages through targeted language-specific fine-tuning
- Integrate multilingual SHAP for deeper, gradient-based explainability
Built With
- face
- gradio
- hugging
- jupyter
- kaggle
- lime
- pandas
- python
- pytorch
- scikit-learn
- transformers
- xlm-roberta












Log in or sign up for Devpost to join the conversation.