-
-
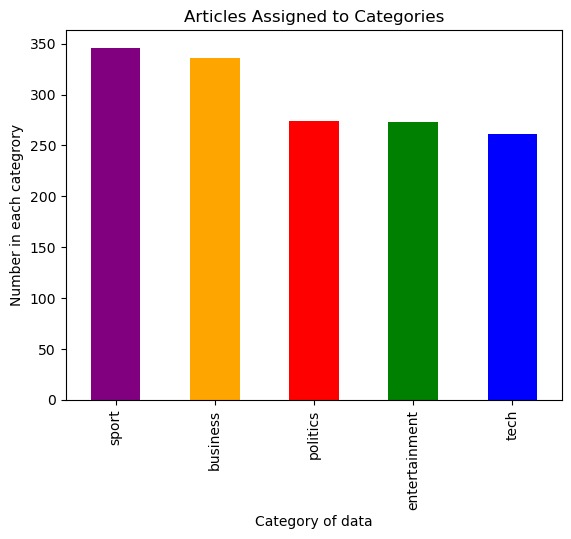
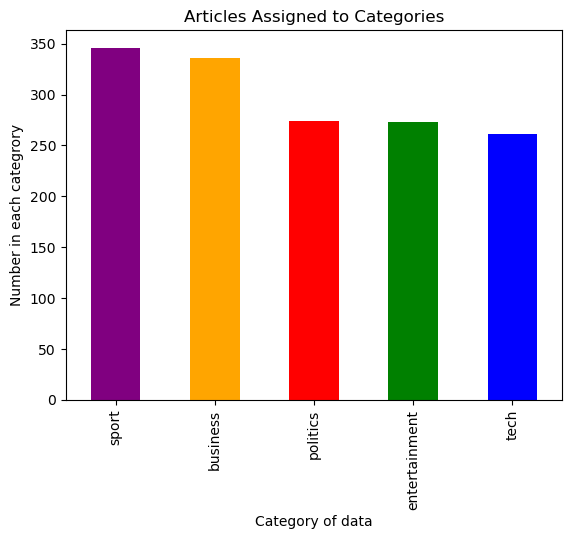
Article Categories
-
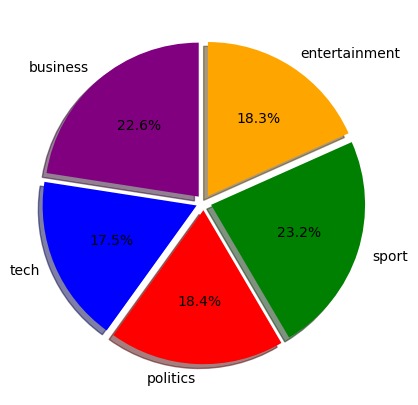
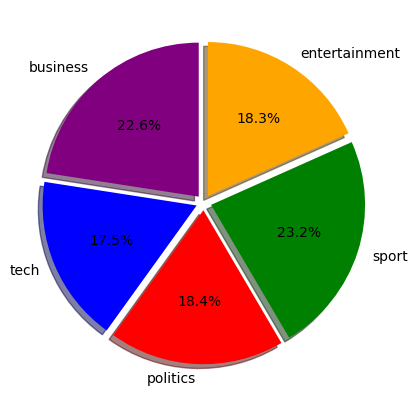
Pie chart of data categories' percentages
-
Business word cloud
-

Tech word cloud
-
Politics word cloud
-

Sport word cloud
-
Entertainment word cloud
-

Poster



Title: Summarizes the main idea of your project.
Classifying newspapers and compares the accuracy of different models.
- Base Goal: Given news article, find classification using one model
- Reach Goal: Given news article, find classification; compare results for different models
- Stretch Goal: Given news article, find classification; compare results for different models and them with deep learning models that we worked with in class (e.g. MLP, neural networks, etc.)
Who: Names and logins of all your group members.
- Names: Allen Dufort, Michelle Liu, Jitpuwapat Mokkamakkul, Zuhal Saljooki
- Logins: adufort1, mliu107, jmokkama, zsaljook
Introduction: What problem are you trying to solve and why?
If you are doing something new, detail how you arrived at this topic and what motivated you.
Newspapers from many sources are often classified into categories – business, sports, politics, and so on. We were inspired by online news article recommendations and classifications: and wanted to better understand how such a widely used feature could be modeled. In particular, we wanted to automate this classification process by implementing a program that classifies newspapers based solely on the text and article title of newspapers. There are many different classification models that can be applied to such a problem, so rather than choosing one implementation, we compared the performance of many models in order to find the best. As a bonus, we thought it would be helpful post-training to use this model to classify any long text into news article categories as well.
Related Work: Are you aware of any, or is there any prior work that you drew on to do your project?
We drew our work mainly from one source which aligned closely to our goals while introducing several new classification models not covered in class [1]. Our other sources allowed us to better understand models such as Multilayer Perceptron [2], Natural Language Processing with Naive Bayes [3], K-means clustering [4], and general classification models [5] [6].
Please read and briefly summarize (no more than one paragraph) at least one paper/article/blog relevant to your topic beyond the paper you are re-implementing/novel idea you are researching.
We drew our work primarily from our primary source [1]. This article is relevant to our project because it had a public implementation for classifying news articles into one of 5 categories (business, tech, politics, sport, entertainment). The goal of this article was to find the most accurate classification model.
In this section, also include URLs to any public implementations you find of the paper you’re trying to implement. Please keep this as a “living list”--if you stumble across a new implementation later down the line, add it to this list.
- Text Classification of News Articles (Primary Source)
- MLP model
- NLP with Naive Bayes
- K-means clustering
- Classification Model
- Intro to Text Classification Model
Data: What data are you using (if any)?
If you’re using a standard dataset (e.g. MNIST), you can just mention that briefly. Otherwise, say something more about where your data come from (especially if there’s anything interesting about how you will gather it).
We are using a dataset from Kaggle, which contains news articles, including their headlines and categories. The data fields are:
- Article Id – An ID uniquely assigned to each record
- Text – Text of the header and article
- Category – Category of the article (tech, business, sport, entertainment, politics)
News articles dataset download link
How big is it? Will you need to do significant preprocessing?
This is a medium-sized dataset, with 1490 news articles, so we do need significant preprocessing (removing stop words, tags, lemmatization, converting words to lowercase).
Methodology: What is the architecture of your model?
How are you training the model?
We design the architecture of our model in a function called run_model(). The function compares 9 different classifiers for natural language processing models: Logistic Regression, Random Forest, Multinomial Naive Bayes, Support Vector Classifer, Decision Tree Classifier, Gaussian Naive Bayes, 2 different K Nearest Neighbor classifiers, Multilayer Perceptron Classifier, and Sequential Neural Network. Most of the models are done with scikit-learn's models, with the Sequential Neural Network done with a TensorFlow sequential model.
If you are implementing an existing paper, detail what you think will be the hardest part about implementing the model here.
N/A
If you are doing something new, justify your design. Also note some backup ideas you may have to experiment with if you run into issues.
Because this is a classification task, we are approaching this using many classification models. If we run into issues, we may have to figure out whether the issue lies with the models themselves. Some experimentation could be just trying to classify words with a clear category, such as "football" or "film" or "technology".
Metrics: What constitutes “success?”
What experiments do you plan to run?
Success would be having a classification accuracy of over 60% for all of our models, like in Homework 3. We plan to train on 70% of the newspapers and test on 30% for each of the models. We will compare the results of the outputs using accuracy (percentage correct), precision, recall, and F1 score.
For most of our assignments, we have looked at the accuracy of the model. Does the notion of “accuracy” apply for your project, or is some other metric more appropriate?
Yes, accuracy in terms of percentage correct is appropriate for our project because we are tackling a classification problem.
If you are implementing an existing project, detail what the authors of that paper were hoping to find and how they quantified the results of their model.
N/A
Ethics
What is your dataset? Are there any concerns about how it was collected, or labeled? Is it representative? What kind of underlying historical or societal biases might it contain?
Our dataset is a csv file from BBC with various news articles and their corresponding categories. Hence, each article has three components, the article ID, that allows us to distinguish different articles quickly, the article text, which is the body of the article, and the article category, which is the category the article falls into (ie. tech, business, politics, etc.)
One potential issue we see with this data is we have no clue how BBC decided to classify their articles. Some topics, such as an article about a politician endorsing a new technological development could potentially be classified as both tech and politics, so we do not have a measure of how "true" the "ground truth" classifiers are.
Additionally, bias from the author can be incorporated into the neural network as well, since the algorithms don't have debiasing, and we did not filter any of the BBC news data. This can be especially problematic if an article mentioning a serious historical event like the holocaust was categorized as fiction. Furthermore, racial and societal biases of the author, such as racism or sexism can filter into the neural network and become associated with certain classifications. This will be especially problematic if we expand our neural network to generate news articles in given categories. If the network learns biases from authors writing articles (especially if they were written longer ago*), then it could generate articles with the same biases.
*BBC is a very old media company, hence they may have older newspaper articles, in which very racist or sexist comments may have been more commonplace.
How are you planning to quantify or measure error or success? What implications does your quantification have?
Our measure of error or success is the percentage of test articles the algorithm is able to classify correctly ("correct" means the category the algorithm outputs is the same as the actual category of the article). As mentioned previously, this can be a problem because we do not know the BBC's method of classifying these articles, and it's possible that the classification methods can contain unwanted biases or stereotypes.
Potentially, a better metric of accuracy could be one that not just blindly relies on the classification of the articles given, but also takes into account the biases of words within the article. However, such a measure of accuracy would require a more complex model, such as a neural network with word encodings that can classify different words and their potential biases.
Division of labor: Briefly outline who will be responsible for which part(s) of the project.
| Steps | Person |
|---|---|
| Dataset search | Michelle and Jitpuwapat |
| Methodology search | Zuhal |
| Training and Testing | Allen |
| Write-Ups + Poster | All |
Results
| Index | Model | Test Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|
| 0 | Logistic Regression | 97.09% | 0.97 | 0.97 | 0.97 |
| 1 | Random Forest | 97.99% | 0.98 | 0.98 | 0.98 |
| 2 | Multinomial Naive Bayes | 97.09% | 0.97 | 0.97 | 0.97 |
| 3 | Support Vector Classifier | 96.64% | 0.97 | 0.97 | 0.97 |
| 4 | Decision Tree Classifier | 82.10% | 0.82 | 0.82 | 0.82 |
| 5 | Gaussian Naive Bayes | 76.06% | 0.76 | 0.76 | 0.76 |
| 6 | K Nearest Neighbor k=3 | 79.64% | 0.80 | 0.80 | 0.80 |
| 7 | K Nearest Neighbor k=7 | 77.63% | 0.78 | 0.78 | 0.78 |
| 8 | Multilayer Perceptron Classifier | 97.76% | 0.98 | 0.98 | 0.98 |
| 9 | Sequential | 97.54% | 0.98 | 0.98 | 0.98 |
Links
Github Github link
Project Check in #2 (Week of 12/1 - 12/4) Check-In #2
Final Project Report Final Project Report
Poster Link Poster
Video Teaser Video Teaser



Log in or sign up for Devpost to join the conversation.