-

Rendered STL of a scatterplot
-

Rendered STL of a line graph
-
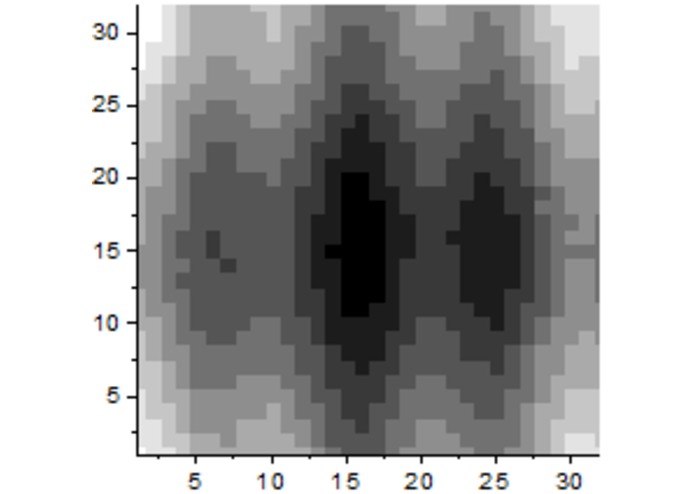
Example heatmap, downloaded from web
-

Rendered STL of downloaded heatmap
-
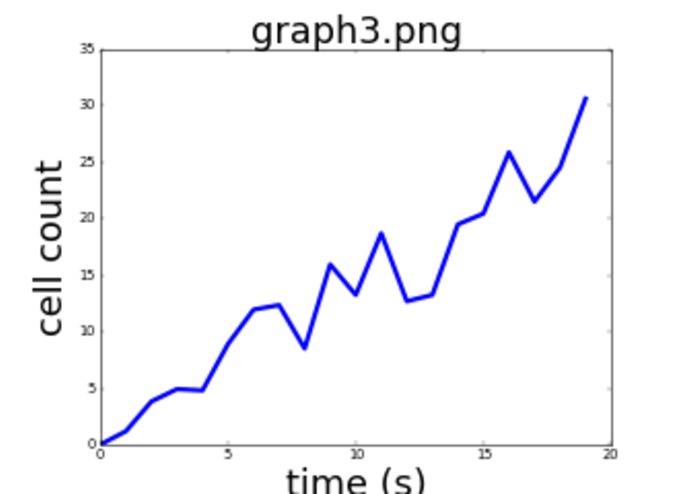
Example linegraph PNG
-
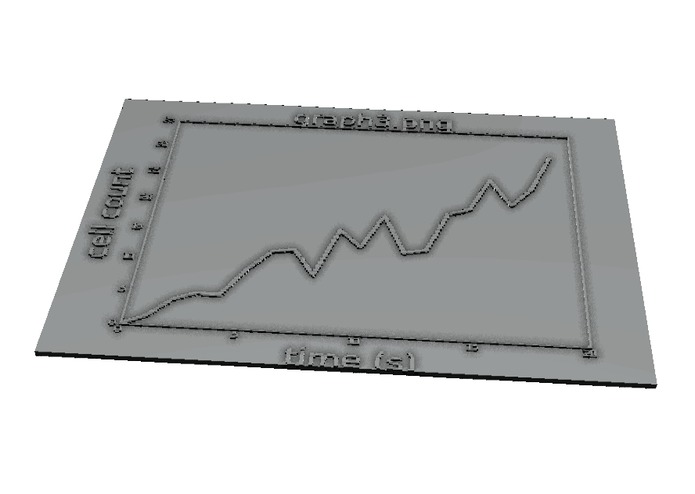
Rendered STL from the linegraph picture




Getting in Touch With Data
Intro
We have designed a pair of systems to create 3D printed graphs out of either existing graphs, or data sets that a developer might have access to. Modern 3D printers are both cheap to operate, and quite fast at printing, allowing a user to get a literal "feel" for the size and shape of a dataset, that would usually only be accessible visually.
Generating from Images
To turn an image into a printable 3-D model, we first convert the image to grayscale, and then parse the image to create an array of pixel "values" between 0 and 5, based on the inverted lightness of each pixel or region. We then traverse through this array. To keep the geometry simple and the render times down, we "skip" pixels with values of zero, and overwrite values on-the-fly when we can create large blocks of similar "pixels" at once (e.g., creating a 10-unit-long block instead of 10 one-unit-long blocks). We merge these into a print-able base, and then export an STL ready for rendering or printing.
Examples:




Generating from Data
It isn't especially fast to turn images into STLs based on pixel values - the computer has to quickly add and merge dozens, if not hundreds of shapes. If you need a graph of a dataset that you already possess, it is easier to generate and merge a small set of shapes from the data itself. To allow someone do to that, we created two example functions to generate both a scatter-plot, and a line graph, from a set of points.
The following two STL files were generated in less than 10 seconds each, from a set of example data.


User Scenarios
Imagine you're at work. You've got to review some network usage logs, and read through a report by a coworker. Unfortunately, the report's figures and the network logs are images; there's only boilerplate alt-text, so your screen-reader can't tell you what the images say. You can kind of improvise - reading through the hundreds of columns and rows of data in plaintext - but that's simply an untenable amount of information.
Or, say you're a college student in a class. The professor has a textbook, and uses powerpoints in their course. They send the materials to you, so that you can run them through your preferred accessibility software - but, they include images (say, contour maps or bar charts) that screen-readers can't interpret, leaving you with the options of either getting help from others or roughly guessing based on context.
Enter TouchPoint. While physical models have a bit more turnaround time than, say, text-to-speech, they can also convey a wealth of information about relative amounts and locations. Plus, by making thin, high-communication models, printing becomes - while not instant - nonetheless incredibly quick and cheap.
With a few keypresses, you can turn the tables and graphs in, say, a textbook (or a professor's powerpoint, or a system monitor, or an Excel Spreadsheet, or anything else) into a physical version.
So, before leaving work for the night or taking a break, just queue up some TouchPoint prints for anything you might need later, and when you get back, the thin plastic graphs will be ready and waiting. When the screenreader tells you, "As you can see here, the data shows a trend. [Table Four.jpeg]", you can consult the plastic table and follow along without breaking stride.
User Input
What did we do to veryfy that this project could be useful? There were several steps. We asked Chris to help us make sure that we understood the context of the challenge - how quickly do we need the graphs, and what is the most important? As it turns out, it is most important to get a general sense for the data as a whole, and we don't need the graphs that quickly.
As part of one of the talks given last night, we created models of our project and asked people to use them, trying to interpret information. We used them to test various questions we had about the project. For example, we verified that it was possible to feel both the lines in line graphs, and edges of textures for heatmaps.
One other important piece of feedback was that it was difficult to feel back from a graph to one of the axes, to estimate where different data is located - this resulted in the gridlines visible on our graphs generated from data.
Finally, we gave our paper prototypes and our first print to Chris for examination, and found that he liked the extra information that it could give him.
Built With
- freecad
- python

Log in or sign up for Devpost to join the conversation.