-
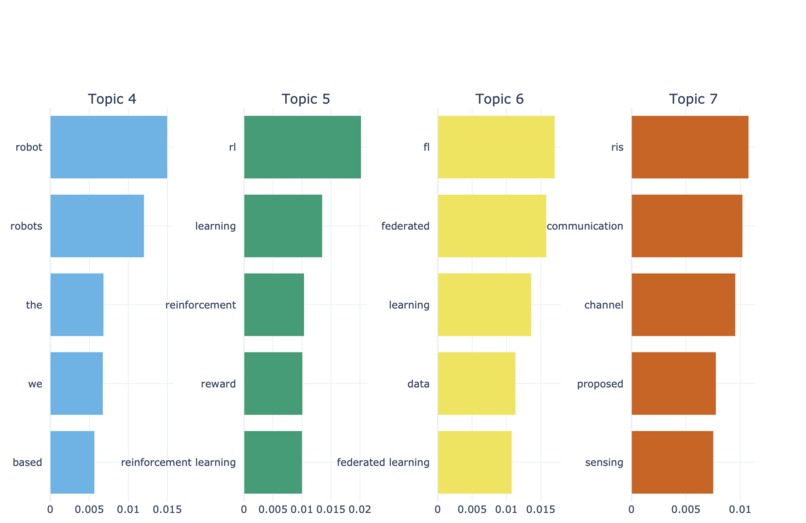
Bar graph
-
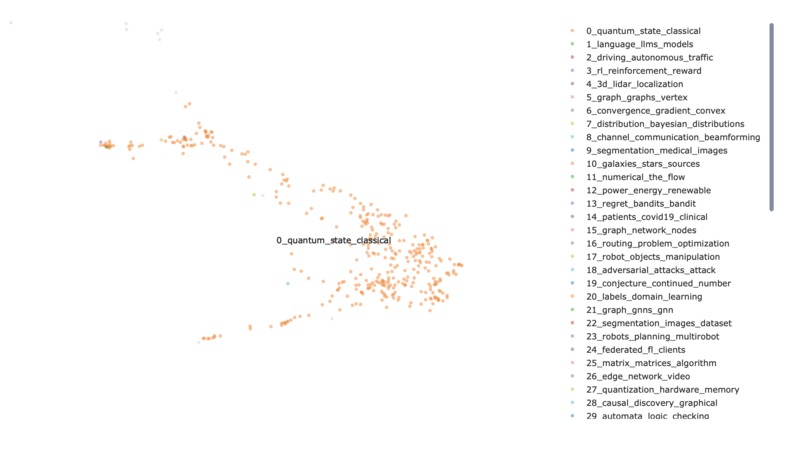
Subsection of BERTopic model
-
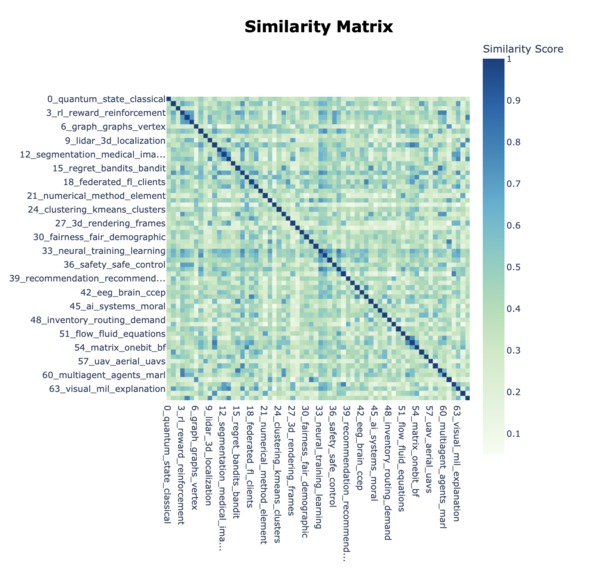
Relation graph with colour-gradient
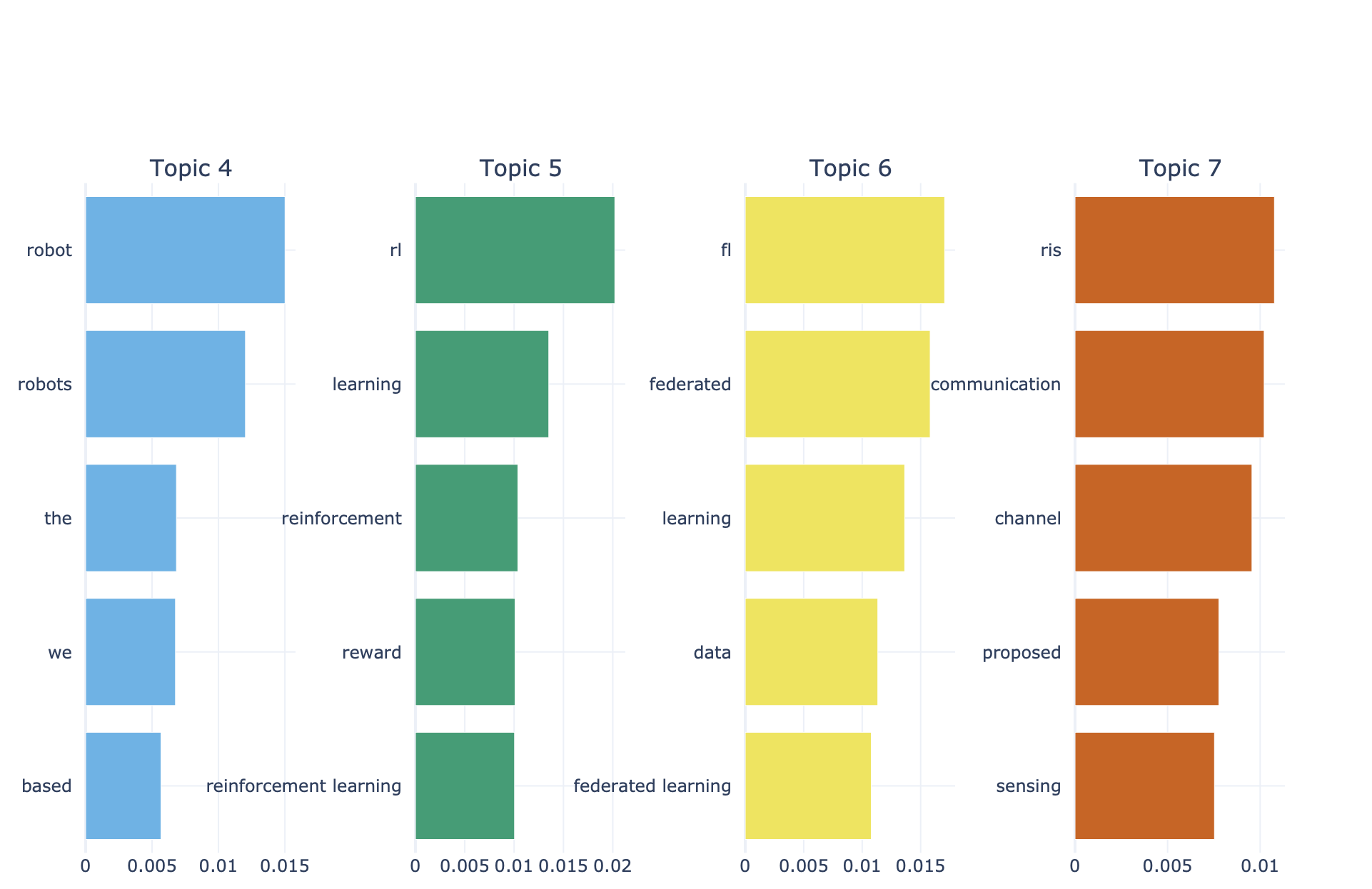
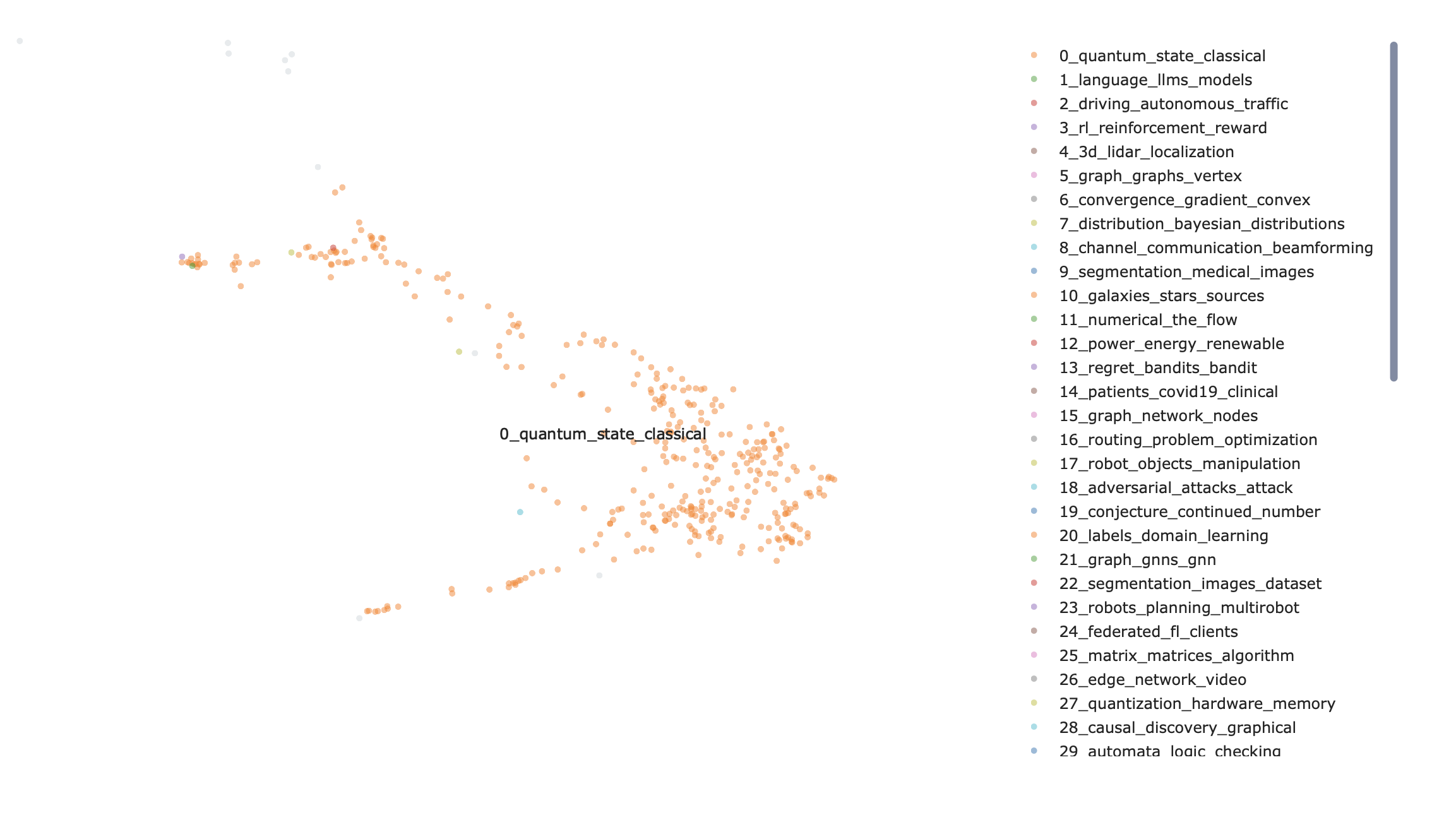
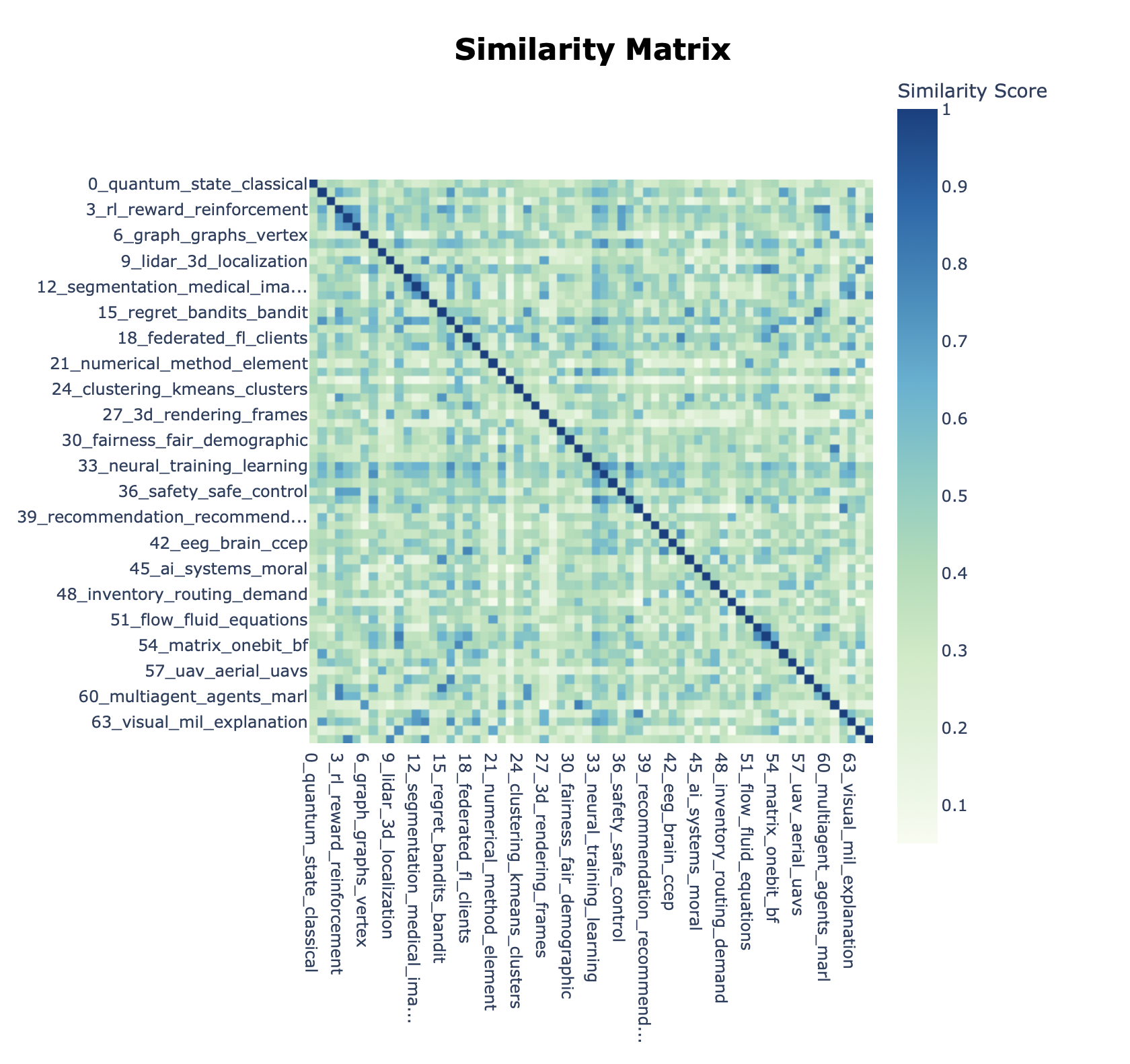
We were interested gaps in knowledge, as we realise that there can sometimes be an oversaturation research in certain topics. This was the inspiration for our use of a BERTopic model. Our application pulls research papers from the internet. It scrapes data before cleaning it, and then graphs them by using a BERTopic model. Its sorts the papers based on research areas and then it looks at keywords. The more keywords that two papers share the closer they are together on the graph. We pulled data from the web by using the Open AI API and cleaned it to normalise the characters and to remove as many filler words as possible, for example “as” or “would”. Next the keywords are extracted and compared to the keywords of other papers. The application then produces a BERTopic model. An BERTopic model has no values along the axis, instead the articles are placed on the graph based on how similar they are to the all the other articles. Learned manim animations, modelling with BERTopic, and embedding interactive graphs onto the website. Many challenges were faced, but the biggest ones were overcoming the long computation times for the BERTopic model, and integrating the front end and the back end of the project.

Log in or sign up for Devpost to join the conversation.