-
-

Torchmeta
-

Data-loaders - Omniglot
-

Datasets available
-
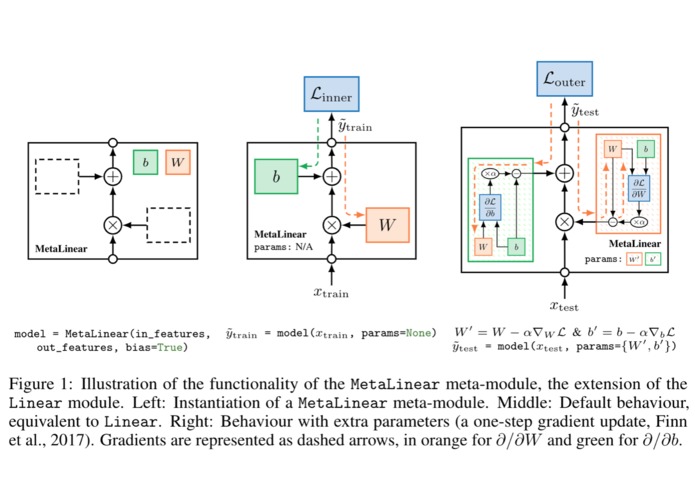
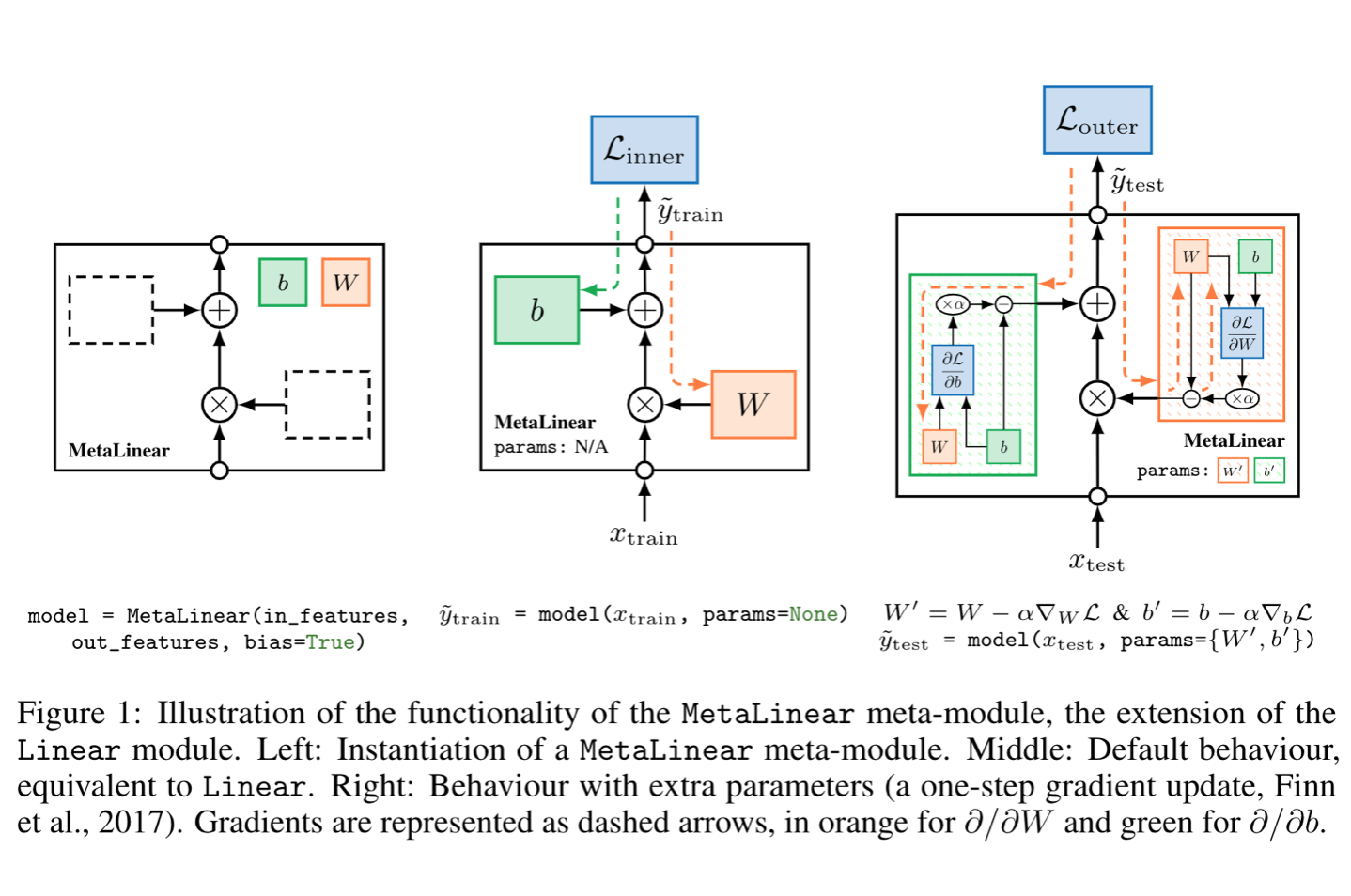
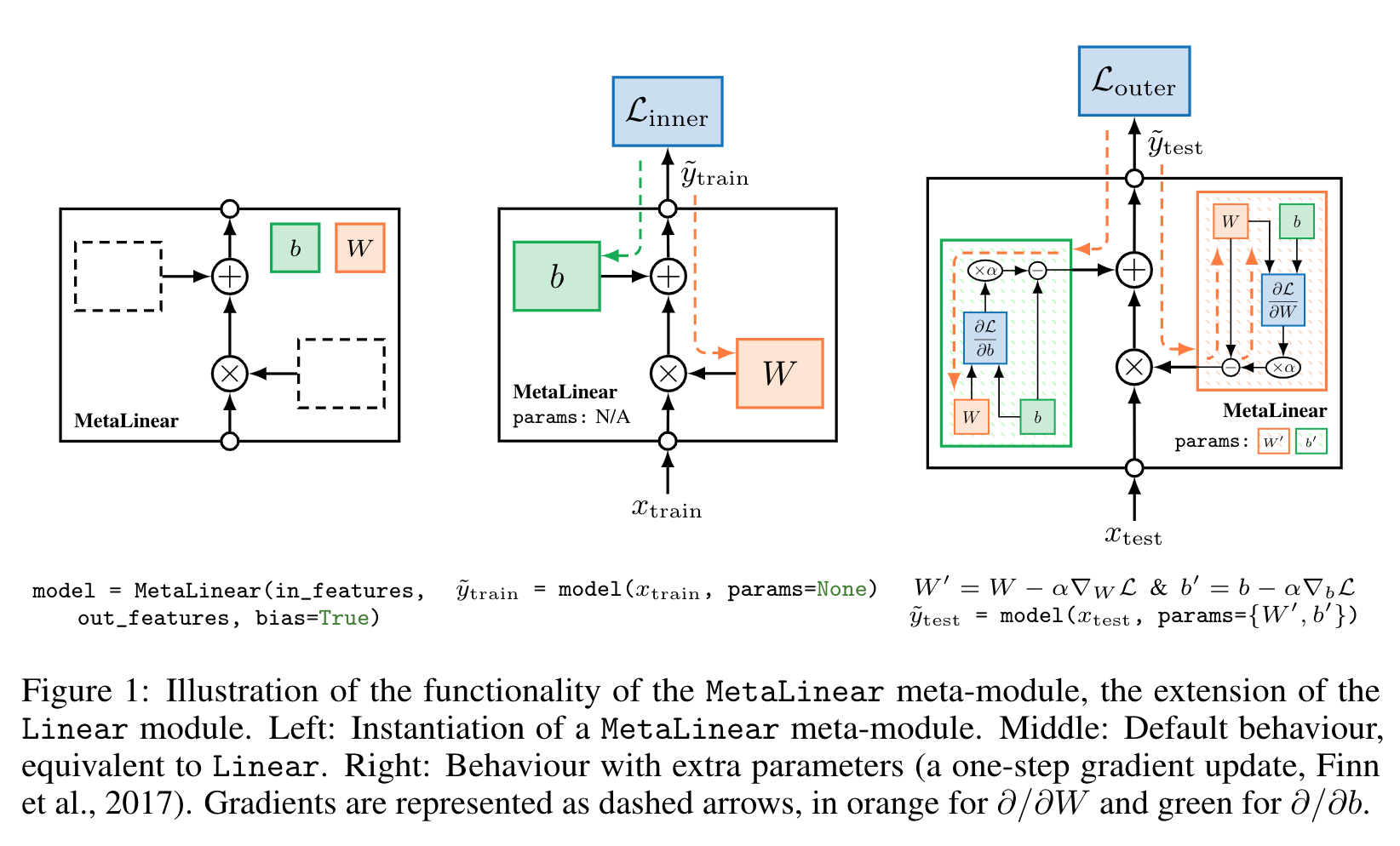
MetaModule
-

Creating models with MetaModule
-

Installation





Inspiration
The problem with data-loading in meta-learning is that usually we need not only to have a batch of example, but a batch of tasks, themselves containing multiple examples. This shift in paradigm makes it hard to build data pipelines for meta-learning in vanilla PyTorch. The goal of the data-loaders in Torchmeta was to have an equivalent to the usual Dataset and DataLoader from PyTorch, but at a "meta" level.
A huge inspiration comes from OpenAI Gym, and how it made it much easier to use reinforcement learning. I wanted to have something similar for meta-learning, something that allowed fast development of meta-learning algorithms. One aspect of Gym that I think helped a lot was its unified interface for all environments; it makes it very easy to switch environments. This is an issue I saw with meta-learning code available online, where almost all of them are tested on a single dataset (and usually it's Omniglot, sometimes Mini-ImageNet). Evaluation on other benchmarks requires major rework of these codes. I wanted to have something as simple as Gym to switch between meta-learning benchmarks.
Another issue I saw was the lack of standard for some of the datasets in meta-learning. A canonical example is how Mini-ImageNet was originally introduced in (Vinyals et al., 2016), but the split that is considered standard now is the one used in (Ravi et al., 2017). This situation still exists for some datasets (e.g. CUB). It is hard to keep track of the "correct" version the algorithms should be evaluated on. Having all of them at hand, with standard meta-train/meta-validation/meta-test, in a library like Torchmeta is a step forward for reproducibility in meta-learning.
What it does
Torchmeta provides extensions for PyTorch to simplify the development of meta-learning algorithms in PyTorch. It features:
A unified interface inspired by Torchvision for both few-shot classification and regression problems, to allow easy benchmarks on multiple datasets and reproducibility. Here is a list of the datasets available in Torchmeta:
- Few-shot regression (toy problems):
- Sine waves (Finn et al., 2017)
- Harmonic functions (Lacoste et al., 2018)
- Sinusoid & lines (Finn et al., 2018)
- Few-shot classification (image classification):
- Omniglot (Lake et al., 2015, 2019)
- Mini-ImageNet (Vinyals et al., 2016, Ravi et al., 2017)
- Tiered-ImageNet (Ren et al., 2018)
- CIFAR-FS (Bertinetto et al., 2018)
- Fewshot-CIFAR100 (Oreshkin et al., 2018)
- Few-shot regression (toy problems):
A thin extension of PyTorch's Module, called MetaModule, that simplifies the creation of certain meta-learning models (e.g. gradient based meta-learning methods).
To try Torchmeta, you can install it with pip install torchmeta.
How I built it
I gathered the links to the datasets and possible splits (in torchmeta.datasets.assets) from code available online, and processed it with HDF5. I built it following very closely the design of Torchvision and PyTorch. For example, all datasets have transform and target_transform arguments, similar to the datasets in Torchvision (these accept transforms from Torchvision as well), and the data-loader for Torchmeta BatchMetaDataLoader is available in torchmeta.utils.data (following torch.utils.data for DataLoader).
Challenges I ran into
Most of the challenges I ran into were related to versioning of the datasets; as I was modifying the processing for the datasets, previously processed data was not working anymore. This caused a lot of headaches.
Another challenge was the processing of Mini-Imagenet and Tiered-Imagenet. In the version made available by the original authors of these datasets, they were given as large Pickle files, which would have made data loading very difficult. I overcame this by using HDF5 instead.
Accomplishments that I'm proud of
I spent a lot of time thinking about an interface that is flexible enough for meta-learning problems, but also simple enough to use so that it's easy to include a new dataset. That's how I settled on this "3-layer" design, with CombinationMetaDataset responsible for creating the tasks, a ClassDataset that downloads the data and generates a pool of classes, and Task which is a PyTorch dataset. I am happy with how this turned out. I'm also proud of how I used HDF5 for datasets in a way which is compatible with DataLoader (which was an unsolved issue on Torchvision).
Another thing I am proud of is the MetaModule. The main focus of the library originally was on the data-loaders, but I'm glad I added the MetaModule. This was inspired by a previous project of mine pytorch-maml-rl, where I used this idea of an extra parameter for the model. MetaModule takes it a step further and makes it as easy to create a model ready for meta-learning (especially gradient-based methods) as a vanilla PyTorch model. I'm really proud of this, seeing how easy it is to create meta-learning algorithms with that.
What I learned
To make it as integrated as possible with PyTorch and Torchvision, I learned a lot about the inner workings of these two libraries, especially how the DataLoader works (with multiprocessing).
What's next for Torchmeta
The next step is to get more datasets available through Torchmeta. One notable missing dataset at the moment is the Meta-Dataset (Triantafillou et al., 2019) . Unfortunately this one is particularly challenging for two reasons:
- Downloading & processing the data is long (12 to 24 hours, only for processing), which would be very impractical for the auto-download and processing feature in Torchmeta. One solution might be to allow Torchmeta to copy the dataset from a local folder if it exists, so that processing & download only happens once (even when launching jobs on a cluster).
- The processing code of Meta-Dataset is in Tensorflow. This is unfortunately a big requirement to have in Torchmeta, which I am not comfortable adding for only this feature.
Another dataset I would like to include is CUB (Hilliard et al., 2018), but unfortunately this lacks any fixed split meta-train/meta-validation/meta-test, which is an issue for reproducibility.








Log in or sign up for Devpost to join the conversation.