-
-

torchlayers project logo
-

torchlambda project logo
-

Example of shape inference and full torch.nn support
-
Visualization of unbuild neural network (notice "?")
-
Example of shape inference for user provided modules
-
ImageNet-like encoder with SoTA layers
-
torchlayers documentation styled like PyTorch
-
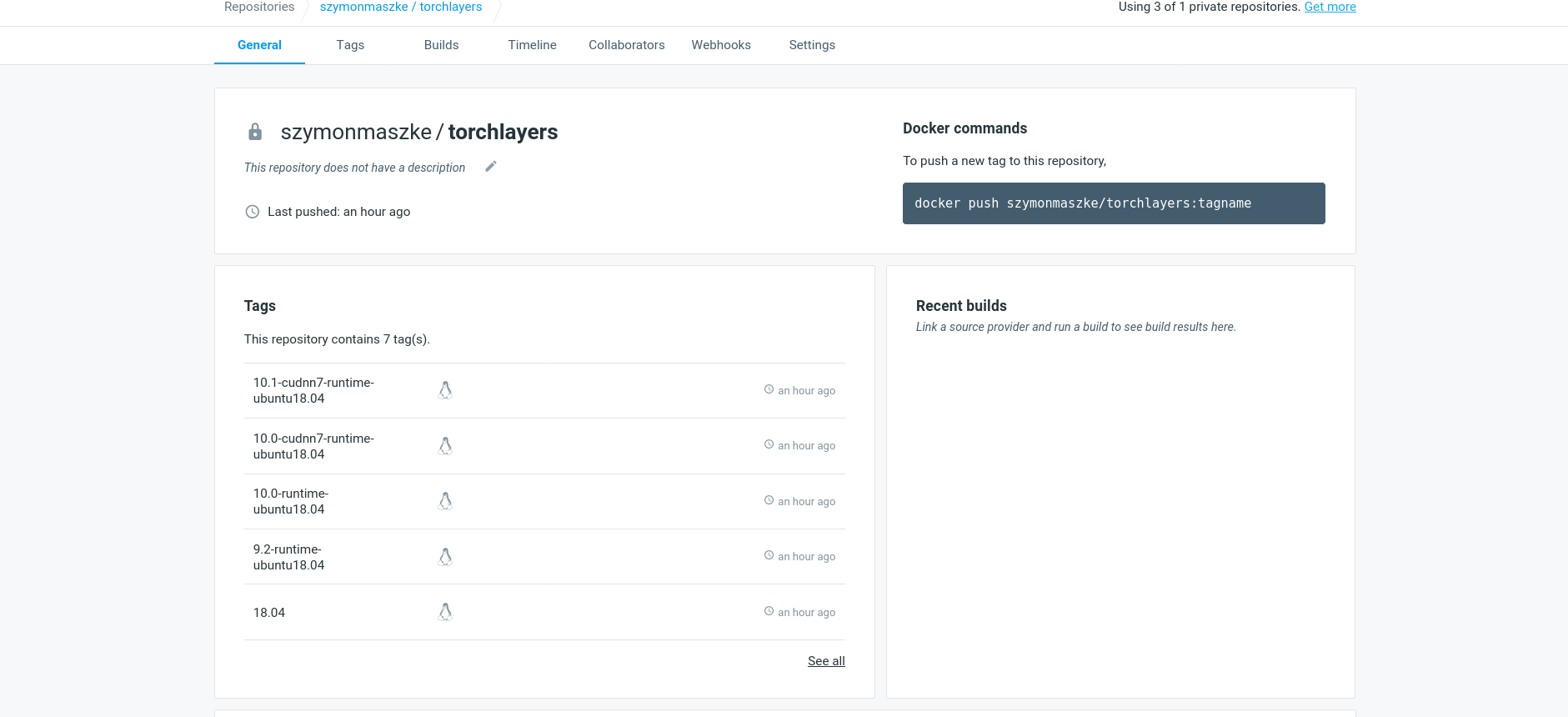
torchlayers Docker images with CUDA support
-
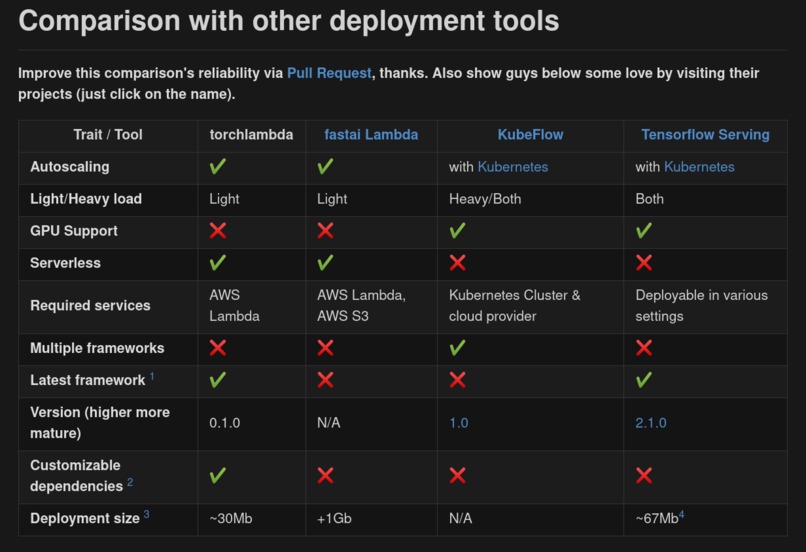
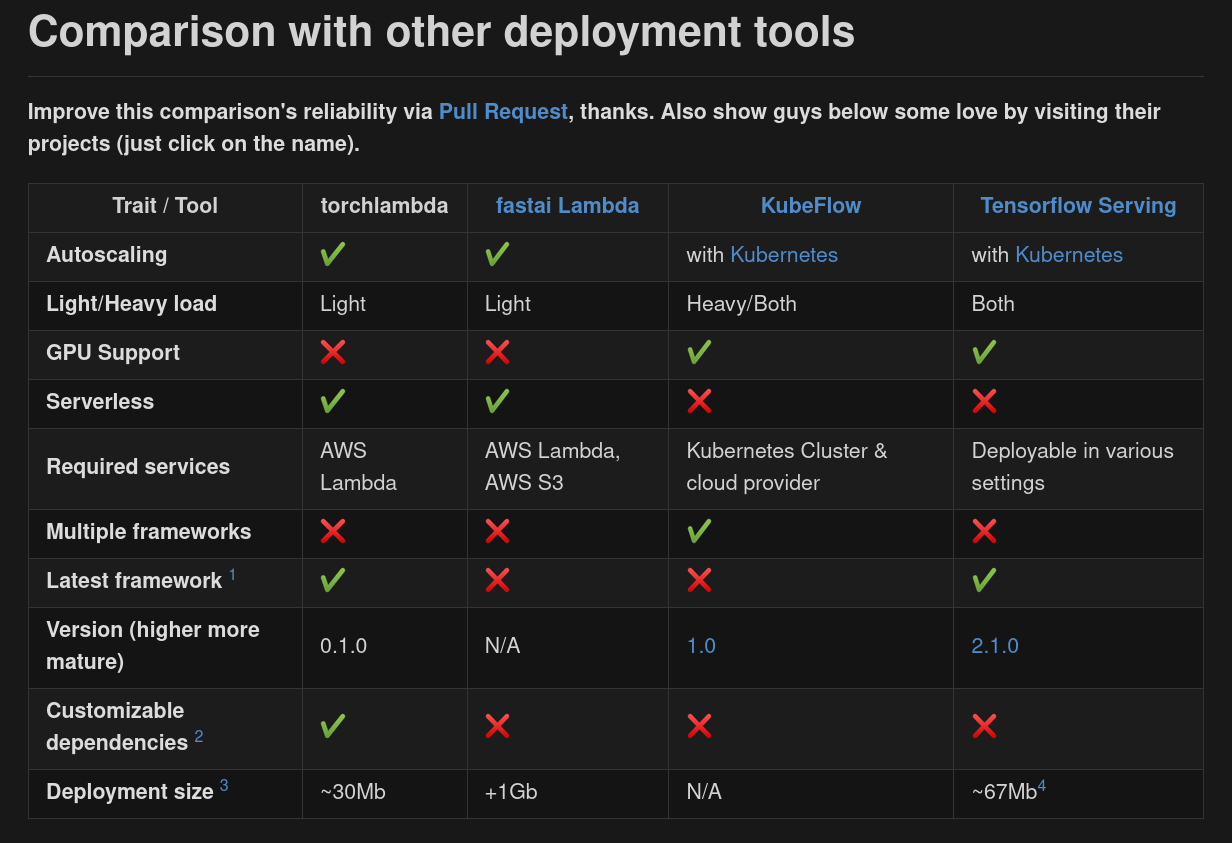
torchlambda compared with existing deployment approaches
-
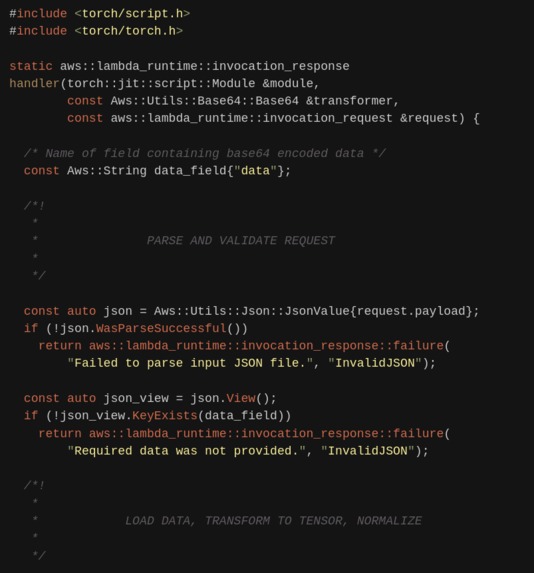
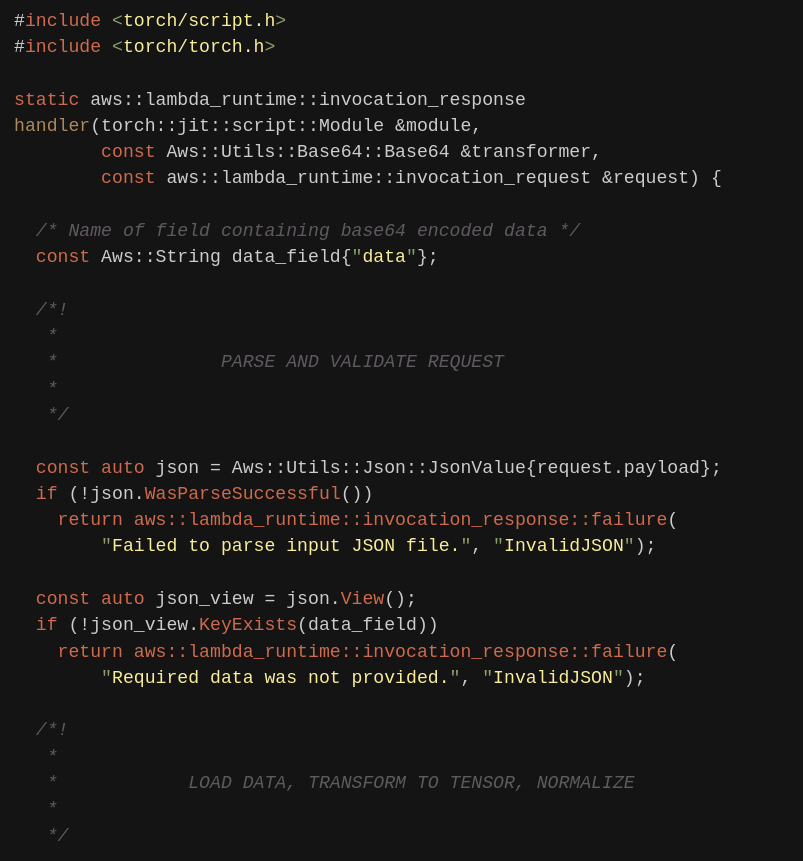
torchlambda generated C++ code (usually all you have to do is change shapes so don't worry)
-
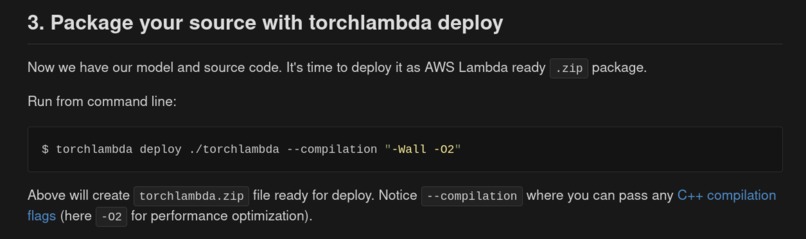
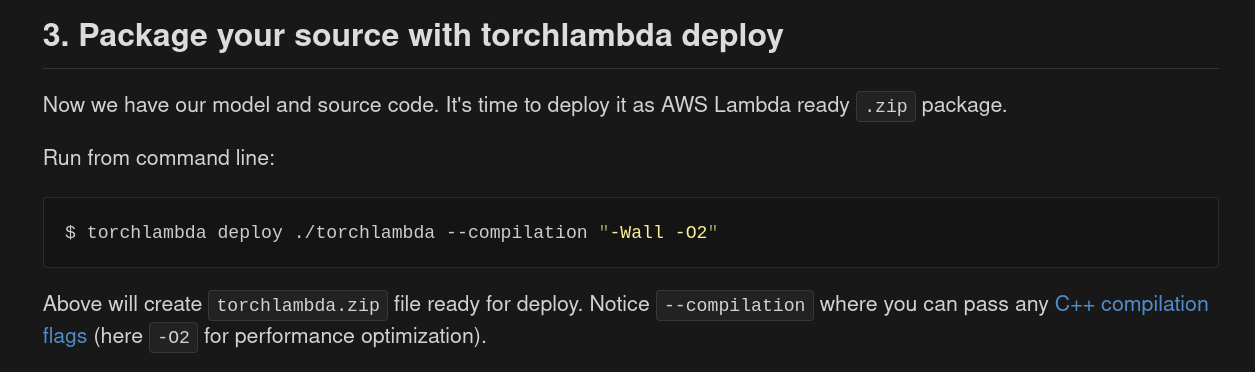
Optimization of created libtorch + AWS code via C++ flags
-
torchlambda default build image (with libtorch, AWS C++ SDK & AWS Lambda Runtime)




Introduction
Today I am pleased to present you two new Open Source projects:
- torchlayers
- torchlambda
torchlayers introduction
Project was created with the following goals in mind:
- Help newcomers join the field (by providing shape and dimension inference for all
torch.nn.Moduleobjects provided byPyTorch) - Increased developers/researchers productivity (more default values common in community, aforementioned shape inference)
- Easier experimentation with current State Of The Art architectures (building blocks known from PolyNet, Squeeze-And-Excitation or Efficient-Net
Please see whole project description (examples, installation etc.) after torchlambda introduction.
torchlambda introduction
Project was created with the following goals in mind:
- Easy and lightweight PyTorch model deployment using AWS Lambda
- Single dependency, no S3 needed hence less infrastructure to manage (PyTorch
torchscriptcompiled module can be provided as AWS Lambda Layer, see example deployment after torchlambda full description) - Easy yet close to bare metal when optimization needed using C++ and PyTorch C++ API
- Easy way to customize builder itself (
libtorchand AWS C++ SDK can be customized duringtorchlambda deploycommand) - Easily installable (just run
pip install torchlambda).
Please see whole project description (examples, installation etc.) after torchlayer full description.
torchlayers full description
| Version | Docs | Tests | Coverage | Style | PyPI | Python | PyTorch | Docker |
|---|---|---|---|---|---|---|---|---|
 |
torchlayers is a library based on PyTorch
providing automatic shape and dimensionality inference of torch.nn layers + additional
building blocks featured in current SOTA architectures (e.g. Efficient-Net).
Above requires no user intervention (except single call to torchlayers.build)
similarly to the one seen in Keras.
Main functionalities:
- Shape inference for most of
torch.nnmodule (convolutional, recurrent, transformer, attention and linear layers) - Dimensionality inference (e.g.
torchlayers.Convworking astorch.nn.Conv1d/2d/3dbased oninput shape) - Shape inference of custom modules (see examples section)
- Additional Keras-like layers (e.g.
torchlayers.Reshapeortorchlayers.StandardNormalNoise) - Additional SOTA layers mostly from ImageNet competitions (e.g. PolyNet, Squeeze-And-Excitation, StochasticDepth)
- Useful defaults (
"same"padding and defaultkernel_size=3forConv, dropout rates etc.) - Zero overhead and torchscript support
Examples
For full functionality please check torchlayers documentation. Below examples should introduce all necessary concepts you should know.
Simple convolutional image and text classifier
- We will use single "model" for both tasks.
Firstly let's define it using
torch.nnandtorchlayers:
import torch
import torchlayers
# torch.nn and torchlayers can be mixed easily
model = torch.nn.Sequential(
torchlayers.Conv(64), # specify ONLY out_channels
torch.nn.ReLU(), # use torch.nn wherever you wish
torchlayers.BatchNorm(), # BatchNormNd inferred from input
torchlayers.Conv(128), # Default kernel_size equal to 3
torchlayers.ReLU(),
torchlayers.Conv(256, kernel_size=11), # "same" padding as default
torchlayers.GlobalMaxPool(), # Known from Keras
torchlayers.Linear(10), # Output for 10 classes
)
print(model)
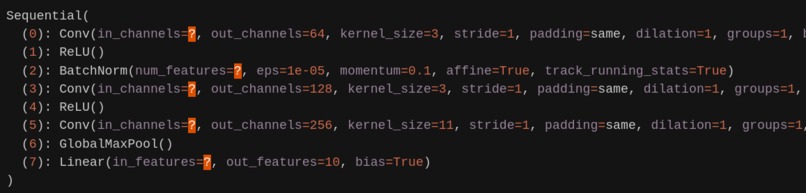
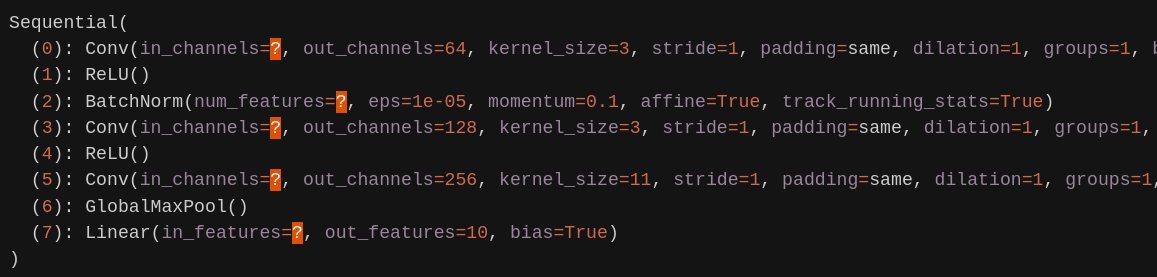
Above would give you model's summary like this (notice question marks for not yet inferred values):
Sequential(
(0): Conv(in_channels=?, out_channels=64, kernel_size=3, stride=1, padding=same, dilation=1, groups=1, bias=True, padding_mode=zeros)
(1): ReLU()
(2): BatchNorm(num_features=?, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): Conv(in_channels=?, out_channels=128, kernel_size=3, stride=1, padding=same, dilation=1, groups=1, bias=True, padding_mode=zeros)
(4): ReLU()
(5): Conv(in_channels=?, out_channels=256, kernel_size=11, stride=1, padding=same, dilation=1, groups=1, bias=True, padding_mode=zeros)
(6): GlobalMaxPool()
(7): Linear(in_features=?, out_features=10, bias=True)
)
- Now you can build/instantiate your model with example input (in this case MNIST-like):
mnist_model = torchlayers.build(model, torch.randn(1, 3, 28, 28))
- Or if it's text classification you are after, same model could be built with different
input shape(e.g. for text classification using300dimensional pretrained embedding):
# [batch, embedding, timesteps], first dimension > 1 for BatchNorm1d to work
text_model = torchlayers.build(model, torch.randn(2, 300, 1))
- Finally, you can
printboth models after instantiation, provided below side by-side for readability (notice different dimenstionality, e.g.Conv2dvsConv1daftertorchlayers.build):
# MNIST CLASSIFIER TEXT CLASSIFIER
Sequential( Sequential(
(0): Conv1d(300, 64) (0): Conv2d(3, 64)
(1): ReLU() (1): ReLU()
(2): BatchNorm1d(64) (2): BatchNorm2d(64)
(3): Conv1d(64, 128) (3): Conv2d(64, 128)
(4): ReLU() (4): ReLU()
(5): Conv1d(128, 256) (5): Conv2d(128, 256)
(6): GlobalMaxPool() (6): GlobalMaxPool()
(7): Linear(256, 10) (7): Linear(256, 10)
) )
As you can see both modules "compiled" into original pytorch layers.
Custom modules with shape inference capabilities
User can define any module and make it shape inferable with torchlayers.Infer
decorator class:
@torchlayers.Infer() # Remember to instantiate it
class MyLinear(torch.nn.Module):
def __init__(self, in_features: int, out_features: int):
self.weight = torch.nn.Parameter(torch.randn(in_features, out_features))
self.bias = torch.nn.Parameter(torch.randn(out_features))
def forward(self, inputs):
return torch.nn.functional.linear(inputs, self.weight, self.bias)
layer = MyLinear(out_features=32)
# build and just like before
By default inputs.shape[1] will be used as in_features value
during initial forward pass. If you wish to use different index (e.g. to infer using
inputs.shape[3]) use @torchlayers.Infer(index=3) as a decorator
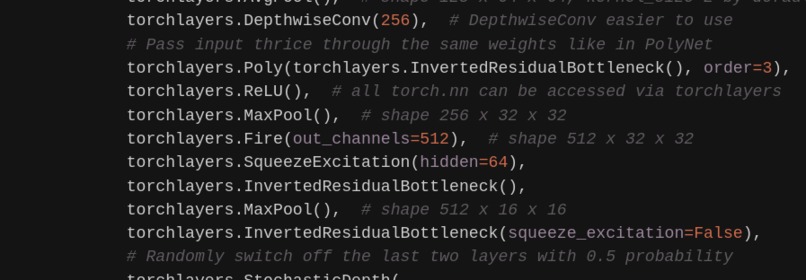
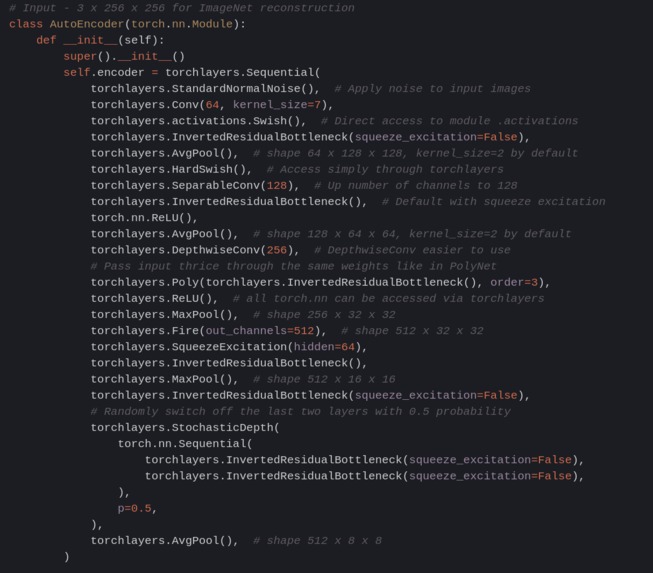
Autoencoder with inverted residual bottleneck and pixel shuffle
Please check code comments and documentation if needed. If you are unsure what autoencoder is you could see this example blog post.
Below is a convolutional denoising autoencoder example for ImageNet-like images.
Think of it like a demonstration of capabilities of different layers
and building blocks provided by torchlayers.
# Input - 3 x 256 x 256 for ImageNet reconstruction
class AutoEncoder(torch.nn.Module):
def __init__(self):
super().__init__()
self.encoder = torchlayers.Sequential(
torchlayers.StandardNormalNoise(), # Apply noise to input images
torchlayers.Conv(64, kernel_size=7),
torchlayers.activations.Swish(), # Direct access to module .activations
torchlayers.InvertedResidualBottleneck(squeeze_excitation=False),
torchlayers.AvgPool(), # shape 64 x 128 x 128, kernel_size=2 by default
torchlayers.HardSwish(), # Access simply through torchlayers
torchlayers.SeparableConv(128), # Up number of channels to 128
torchlayers.InvertedResidualBottleneck(), # Default with squeeze excitation
torch.nn.ReLU(),
torchlayers.AvgPool(), # shape 128 x 64 x 64, kernel_size=2 by default
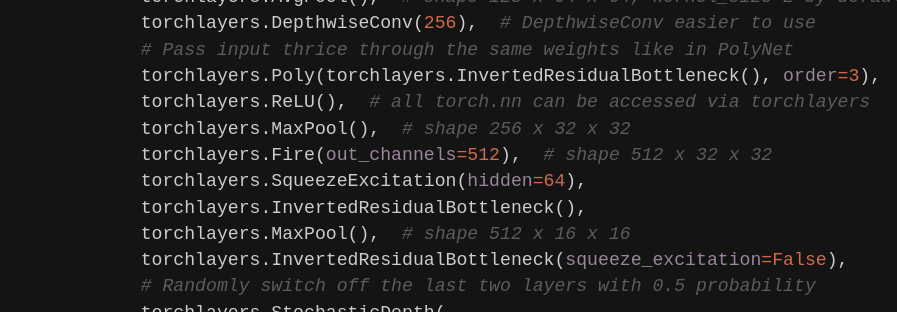
torchlayers.DepthwiseConv(256), # DepthwiseConv easier to use
# Pass input thrice through the same weights like in PolyNet
torchlayers.Poly(torchlayers.InvertedResidualBottleneck(), order=3),
torchlayers.ReLU(), # all torch.nn can be accessed via torchlayers
torchlayers.MaxPool(), # shape 256 x 32 x 32
torchlayers.Fire(out_channels=512), # shape 512 x 32 x 32
torchlayers.SqueezeExcitation(hidden=64),
torchlayers.InvertedResidualBottleneck(),
torchlayers.MaxPool(), # shape 512 x 16 x 16
torchlayers.InvertedResidualBottleneck(squeeze_excitation=False),
# Randomly switch off the last two layers with 0.5 probability
torchlayers.StochasticDepth(
torch.nn.Sequential(
torchlayers.InvertedResidualBottleneck(squeeze_excitation=False),
torchlayers.InvertedResidualBottleneck(squeeze_excitation=False),
),
p=0.5,
),
torchlayers.AvgPool(), # shape 512 x 8 x 8
)
# This one is more "standard"
self.decoder = torchlayers.Sequential(
torchlayers.Poly(torchlayers.InvertedResidualBottleneck(), order=2),
# Has ICNR initialization by default after calling `build`
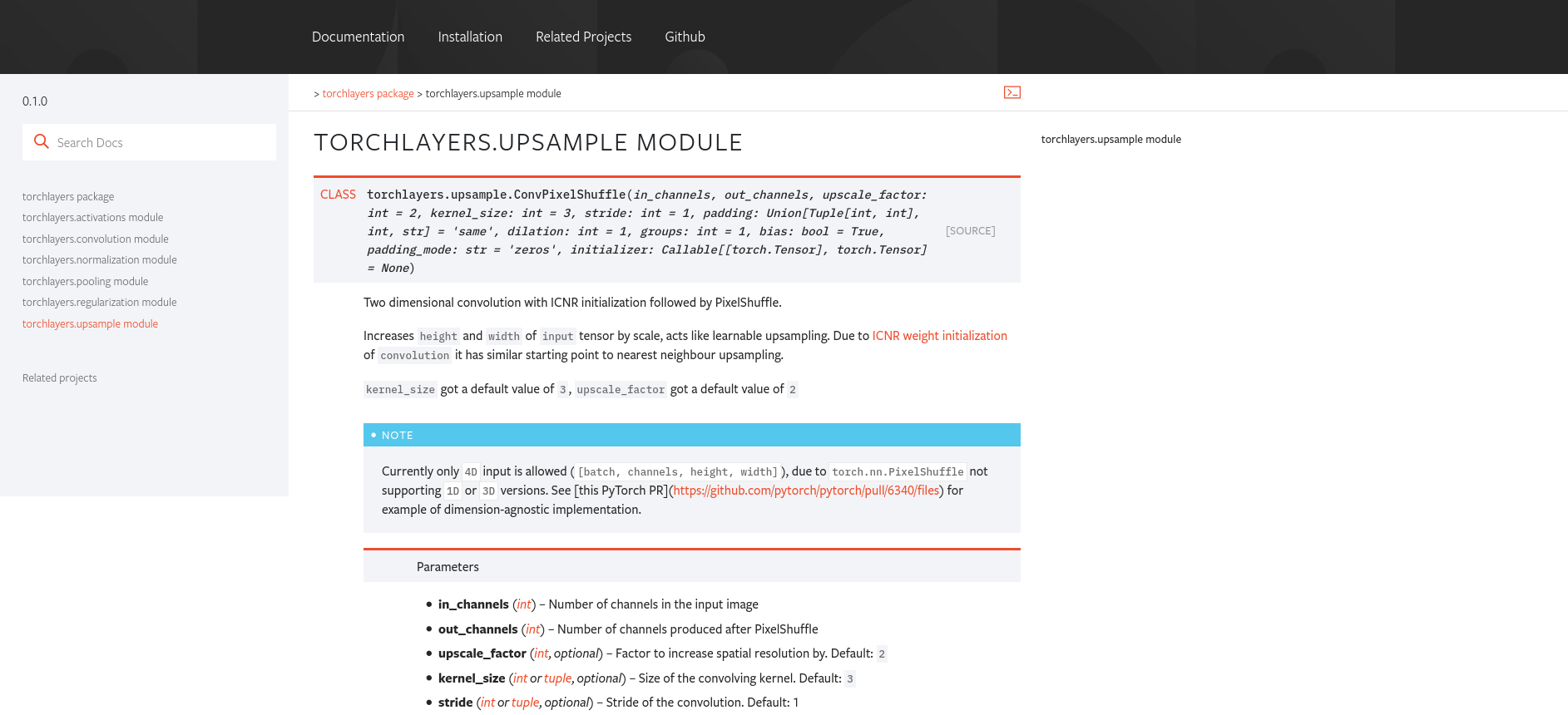
torchlayers.ConvPixelShuffle(out_channels=512, upscale_factor=2),
# Shape 512 x 16 x 16 after PixelShuffle
torchlayers.Poly(torchlayers.InvertedResidualBottleneck(), order=3),
torchlayers.ConvPixelShuffle(out_channels=256, upscale_factor=2),
# Shape 256 x 32 x 32
torchlayers.Poly(torchlayers.InvertedResidualBottleneck(), order=3),
torchlayers.ConvPixelShuffle(out_channels=128, upscale_factor=2),
# Shape 128 x 64 x 64
torchlayers.Poly(torchlayers.InvertedResidualBottleneck(), order=4),
torchlayers.ConvPixelShuffle(out_channels=64, upscale_factor=2),
# Shape 64 x 128 x 128
torchlayers.InvertedResidualBottleneck(),
torchlayers.Conv(256),
torchlayers.Dropout(), # Defaults to 0.5 and Dropout2d for images
torchlayers.Swish(),
torchlayers.InstanceNorm(),
torchlayers.ConvPixelShuffle(out_channels=32, upscale_factor=2),
# Shape 32 x 256 x 256
torchlayers.Conv(16),
torchlayers.Swish(),
torchlayers.Conv(3),
# Shape 3 x 256 x 256
)
def forward(self, inputs):
return self.decoder(self.encoder(inputs))
Now one can instantiate the module and use it with torch.nn.MSELoss as per usual.
autoencoder = torchlayers.build(AutoEncoder(), torch.randn(1, 3, 256, 256))
Installation
pip
Latest release:
pip install --user torchlayers
Nightly:
pip install --user torchlayers-nightly
Docker
CPU standalone and various versions of GPU enabled images are available at dockerhub.
For CPU quickstart, issue:
docker pull szymonmaszke/torchlayers:18.04
Nightly builds are also available, just prefix tag with nightly_. If you are going for GPU image make sure you have
nvidia/docker installed and it's runtime set.
torchlambda full description
| Version | PyPI | Python | PyTorch | Docker |
|---|---|---|---|---|
 |
torchlambda is a software designed to deploy PyTorch models on Amazon's AWS Lambda cloud service using AWS SDK for C++ and custom C++ runtime.
Using static compilation size of source code is only 30 Mb with all necessary dependencies.
This allows users to pass their models as AWS Lambda layers,
hence no other dependencies like Amazon S3 are required.
Comparison with other deployment tools
Improve this comparison's reliability via Pull Request, thanks. Also show guys below some love by visiting their projects (just click on the name).
| Trait / Tool | torchlambda | fastai Lambda | KubeFlow | Tensorflow Serving |
|---|---|---|---|---|
| Autoscaling | yes | yes | with Kubernetes | with Kubernetes |
| Light/Heavy load | Light | Light | Heavy/Both | Both |
| GPU Support | no | no | yes | yes |
| Serverless | yes | yes | no | no |
| Required services | AWS Lambda | AWS Lambda, AWS S3 | Kubernetes Cluster & cloud provider | Deployable in various settings |
| Multiple frameworks | no | no | yes | no |
| Latest framework 1 | :heavy_check_mark: | :x: | :x: | :heavy_check_mark: |
| Version (higher more mature) | 0.1.0 | N/A | 1.0 | 2.1.0 |
| Customizable dependencies 2 | yes | no | no | no |
| Deployment size 3 | ~30Mb | +1Gb | N/A | ~67Mb4 |
Installation
Docker (at least version
17.05) is required. See Official Docker's documentation for installation instruction for your operating system.Install
torchlambdathrough pip, Python version3.6or higher is needed. You could also install this software within conda or other virutal environment of your choice. Following command should be sufficient:$ pip install --user torchlambda
Example deploy
Here is an example of ResNet18 model deployment using torchlambda.
Run and create all necessary files in the same directory.
1. Create model to deploy
Below is a code (model.py) to load ResNet from torchvision
and compile is to torchscript:
import torch
import torchvision
model = torchvision.models.resnet18()
# Smaller example
example = torch.randn(1, 3, 64, 64)
script_model = torch.jit.trace(model, example)
script_model.save("model.ptc")
Invoke it from CLI:
$ python model.py
You should get model.ptc in your current working directory.
2. Create deployment code with torchlambda scheme
Writing C++ code might be hard, hence torchlambda provides you
a basic scheme where all one has to do is to input appropriate shapes for inference
(either passed during request or hard-coded).
Run following command:
$ torchlambda scheme
You should see a new folder called torchlambda in your current directory.
Contents of torchlambda/main.cpp are the ones you would usually modify.
Usually this code won't change too much, maybe additional fields parsing and aforementioned input shape.
If you wish to see the generated C++ scheme code (around 100 heavy-commented code) click below:
3. Package your source with torchlambda deploy
Now we have our model and source code. It's time to deploy it as AWS Lambda
ready .zip package.
Run from command line:
$ torchlambda deploy ./torchlambda --compilation "-Wall -O2"
Above will create torchlambda.zip file ready for deploy.
Notice --compilation where you can pass any C++ compilation flags (here -O2
for performance optimization).
There are many more things one could set during this step, check torchlambda deploy --help
for full list of available options (some, like --pytorch might trigger build of totally new Docker image, by default named torchlambda:custom. This takes a while and is quite CPU heavy so watch out and read --help).
4. Package your model as AWS Lambda Layer
As the above source code is roughly 30Mb in size (AWS Lambda has 250Mb limit),
we can put our model as additional layer. To create it run:
$ torchlambda model ./model.ptc --destination "model.zip"
You will receive model.zip layer in your current working directory (--destination is optional).
5. Deploy to AWS Lambda
From now on you could mostly follow tutorial from AWS Lambda's C++ Runtime. It is assumed you have AWS CLI configured, if not check Configuring the AWS CLI.
5.1 Create trust policy JSON file
First create the following trust policy JSON file:
$ cat trust-policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": ["lambda.amazonaws.com"]
},
"Action": "sts:AssumeRole"
}
]
}
5.2 Create IAM role trust policy JSON file
Run from your shell:
$ aws iam create-role --role-name demo --assume-role-policy-document file://trust-policy.json
Note down the role Arn returned to you after running that command, it will be needed during next step.
5.3 Create AWS Lambda function
Create deployment function with the script below:
$ aws lambda create-function --function-name demo \
--role <specify role arn from step 5.2 here> \
--runtime provided --timeout 30 --memory-size 1024 \
--handler torchlambda --zip-file fileb://torchlambda.zip
5.4 Create AWS Layer containing model
We already have our ResNet18 packed appropriately, run the following:
$ aws lambda publish-layer-version --layer-name model \
--description "Resnet18 neural network model" \
--license-info "MIT" \
--zip-file fileb://model.zip
Please save the LayerVersionArn similar to step 5.2 and insert it below to add this layer
to function from step 5.3:
$ aws lambda update-function-configuration \
--function-name demo \
--layers <specify layer arn from above here>
6. Encode image with base64 and request your function
Following script (save it as request.py) will send image-like tensor encoded using base64
via aws lambda invoke to test our function.
import base64
import shlex
import struct
import subprocess
import sys
import numpy as np
# Random image-like data
data = np.random.randint(low=0, high=255, size=(3, 64, 64)).flatten().tolist()
# Encode using bytes for AWS Lambda compatibility
image = struct.pack("<{}B".format(len(data)), *data)
encoded = base64.b64encode(image)
command = """aws lambda invoke --function-name %s --payload '{"data":"%s"}' %s""" % (
sys.argv[1],
encoded,
sys.argv[2],
)
subprocess.call(shlex.split(command))
Run above script:
$ python request.py demo output.txt
You should get the following response in output.txt (your label may vary as the image is just a random tensor):
cat output.txt
{"label": 40}
Congratulations, you have deployed ResNet18 classifier using only AWS Lambda in 6 steps!
Footnotes
1. Support for latest version of it's main DL framework or main frameworks if multiple supported
2. Project dependencies shape can be easily cutomized. In torchlambda case it is customizable
build of libtorch and AWS C++ SDK
3. Necessary size of code and dependencies to deploy model
4. Based on Dockerfile size

Log in or sign up for Devpost to join the conversation.