Inspiration
Vast amount of information is available online that can be utilized for national security use cases. According to the Pew research 30% of U.S. adults say they regularly get news there. Torch makes it easy to extract insights from social media and other OSInt sources.
What it does
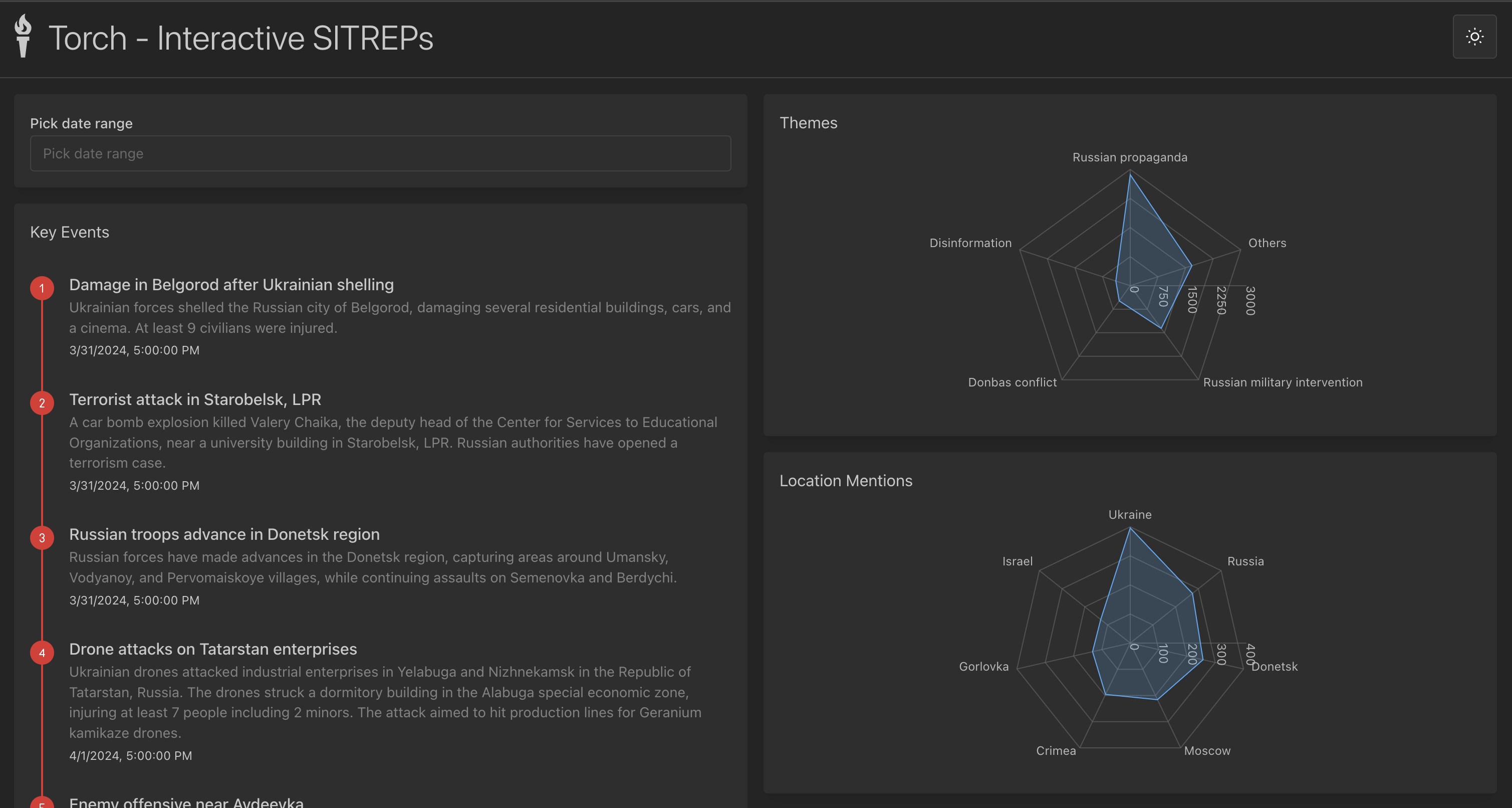
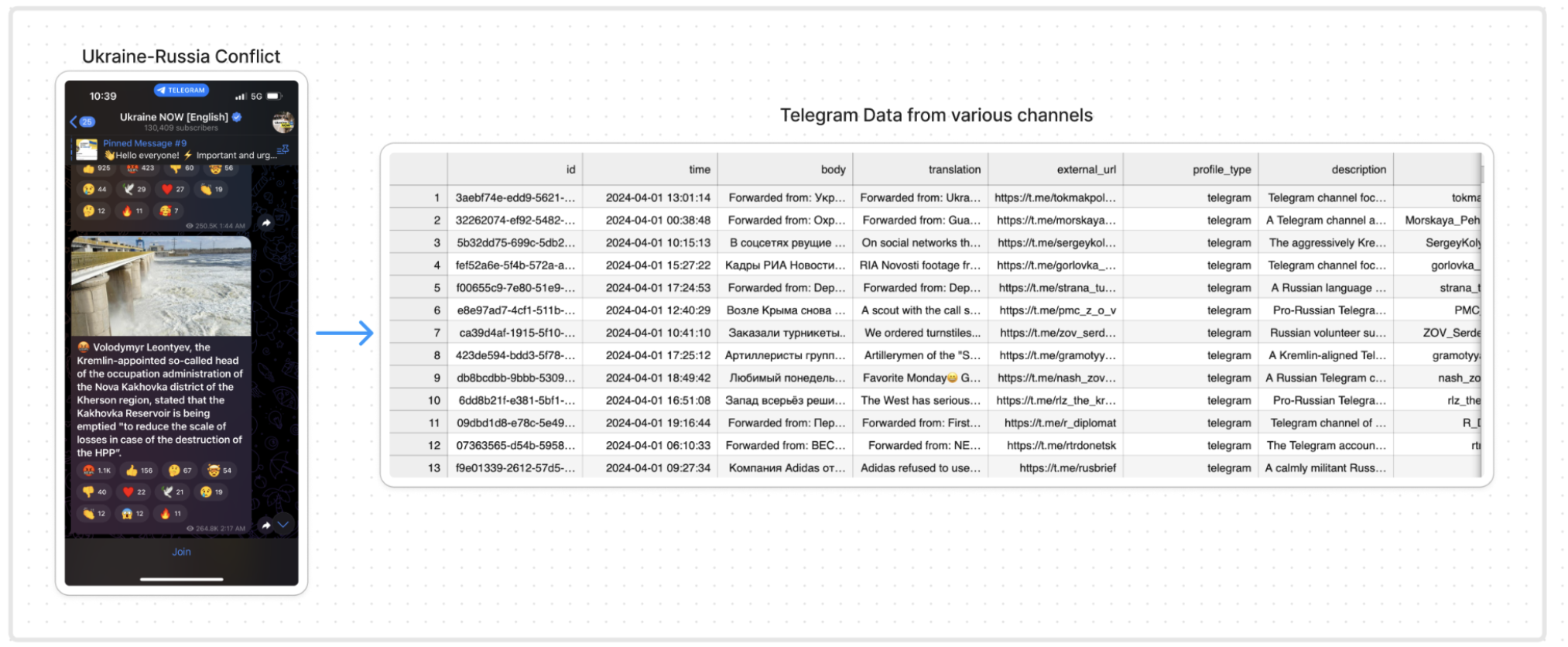
We've used Telegram messages to generate an interactive SITREP using LLMs.
How we built it
Dataset
For this Hackathon we utilized one month of social media posts from the Russian and Ukrainian social media. They were provided by Vannevar Labs.
Artificial Intelligence
We used Anthropic’s Claude Sonnet through Google Vertex. We used various data processing frameworks such as Pandas, Spark etc. in the backend. We've used https://autoevaluator.langchain.com/ for testing.
Fullstack
We used NodeJS and React with popular visualization libraries.
Challenges we ran into
Scalability
LLMs have a limited context window for processing input text. As a result, we had to cluster the raw posts based on their semantic meanings so that similar posts can be batched together.
Quality
Getting a high quality summary out of a group of posts require finetuning the LLM for that particular task. Since we did not have the time and the necessary data for the training job, we applied in-context learning to guide the LLM.
Hallucination
We noticed that around 1% of the time LLM generated in-accurate or inappropriate content. Although the probabilistic nature of LLMs makes it almost impossible to eliminate hallucination, we believe that it can be reduced through further training and validation against reputed sources.
What we learned
We've learned about SITREPs!
What's next for Torch
- Connect with the users and collect feedback.
- We want to use the past events to predict the future.
- Finetune the model to produce more accurate results.
- Use reputed external sources to detect hallucination and misinformation.
- Address various scalable issues.



Log in or sign up for Devpost to join the conversation.