-
-

TooLegalDidntRead
-

Tech Stack
-

NLP

Inspiration
We were inspired to create TooLegalDidntRead because in our current era of expanding privacy laws, privacy policies and terms of conditions get more and more complex to comply with the hundreds of regulations from all over the country. Every time we skipped through all the terms of service and privacy policy we were setting ourselves up for trouble in the future so we created an application that would tell us exactly what we needed without any of the legal jargon that plagues most privacy policies
What it does
TooLegalDidntRead is a transformative and groundbreaking app to solve the growing problem of long and complex legally binding documents by using NLP and keyword extraction to create a shortened version of a legal document that outlines your rights, as well as your legal limitations. This makes sure the company can not make you agree to anything you didn’t want to agree to. The software also analyzes US Federal law, Case Law, and State law to find relevant law that applies to your terms of service
How we built it
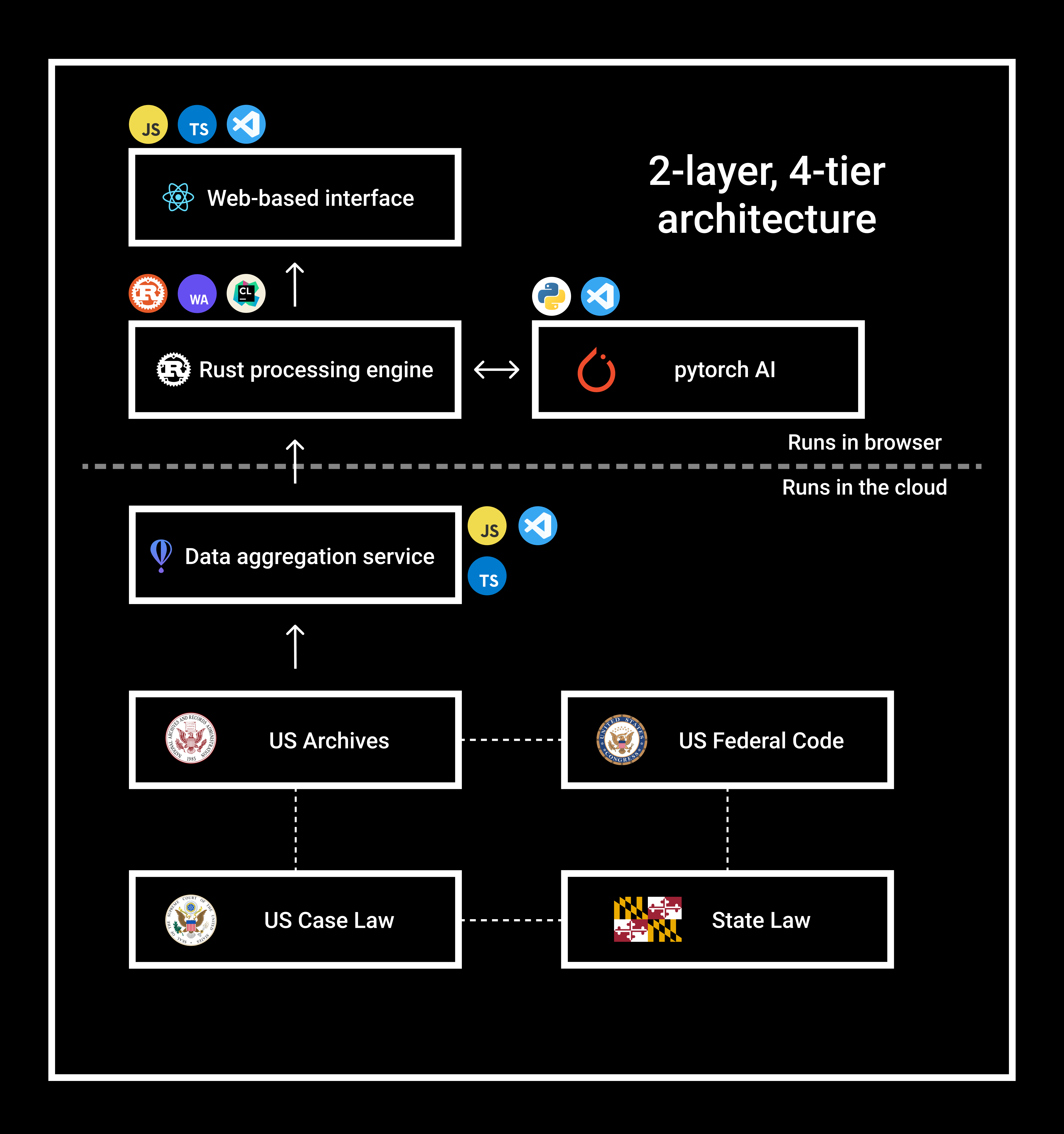
Our application uses a novel 2 layer, 4 tier architecture. The user interacts with an intuitive and user-friendly web-based interface that follows Material UI guidelines and is powered by React. The data is sourced from a Rust processing engine, which connects to the data aggregation service via an efficient network protocol. The Rust processing engine is compiled to WebAssembly and is thus able to efficiently run entirely in-browser, for the optimal user experience.
Challenges we ran into
During the creation of TooLegalDidntRead we faced many challenges. One challenge was that using just Federal Law was insufficient for our needs. To rectify this we incorporated US case and state law. Another issue was that Case law used historic english, to solve this problem we normalized the case text to modern English.
Our sophisticated Pytorch Learn deep learning model performs natural language processing to analyze thousands of legal documents, including US federal code, case law, and state law to determine the user’s rights and limitations by extracting keywords within the document to find information about the document, as well as relevant legal information.
Accomplishments that we're proud of
We are proud to have created a fully functioning web application with a real world purpose that could help other people. We are also proud to have successfully integrated our NLP algorithm with a database of court cases to make the necessary connections between the legal document and the users rights.
What we learned
We learned a lot about the interaction between Javascript and Rust using WebAssembly. This was also our first time using a vast amount of data that is the US Code, Case law, and State law.
What's next for TooLegalDidntRead
We plan on training our model even further to improve its accuracy and we plan on creating a chrome extension for easy access to our application.
Built With
- ai
- clion
- javascript
- legal
- ml
- node.js
- python
- pytorch
- react.js
- rust
- typescript
- vscode
- webassembly











Log in or sign up for Devpost to join the conversation.