-
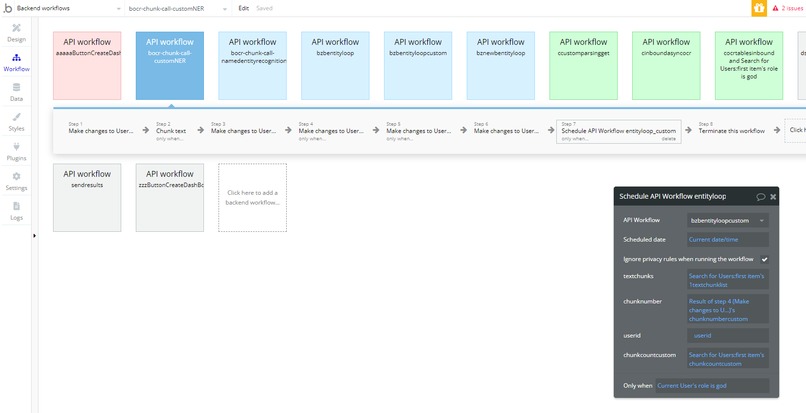
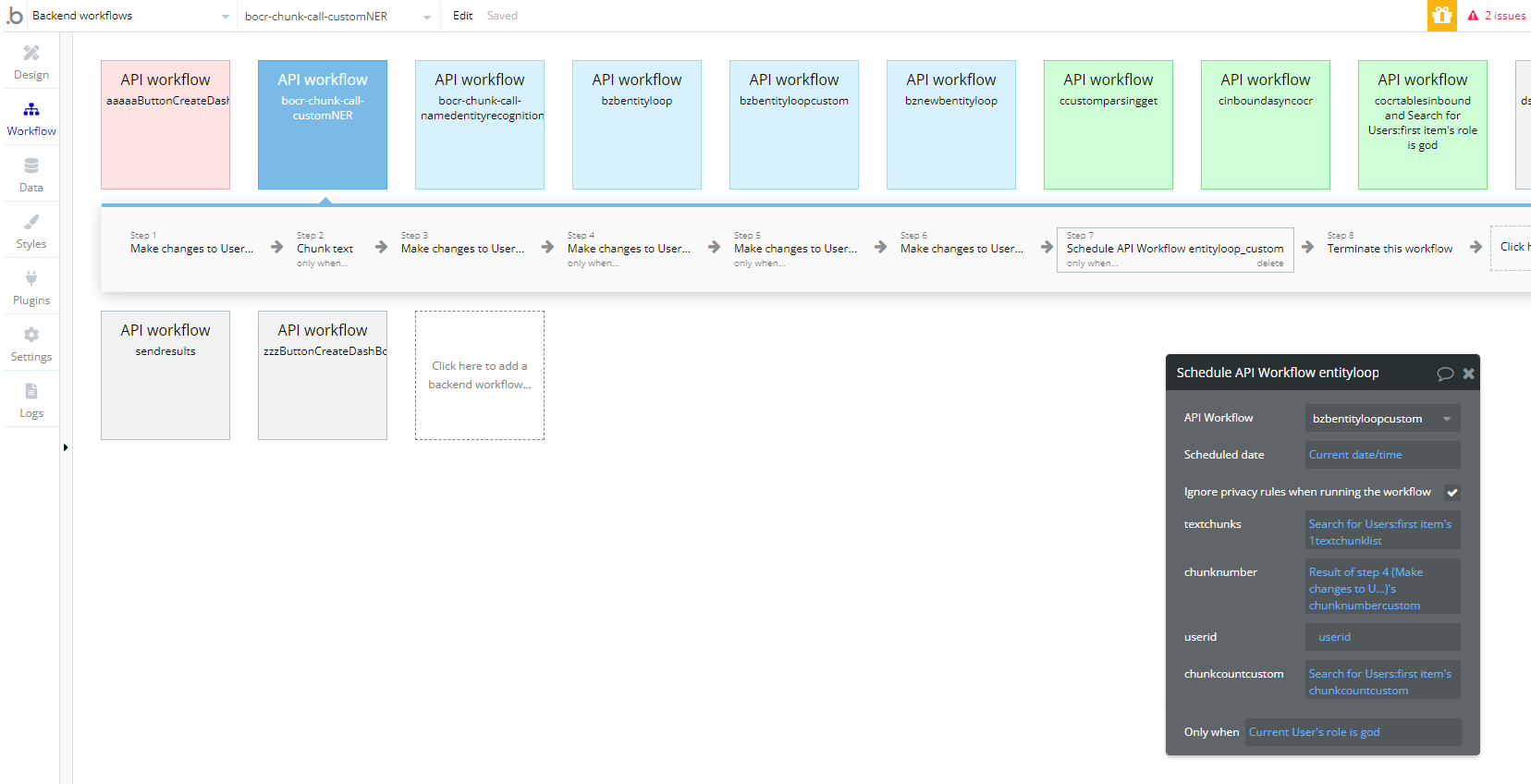
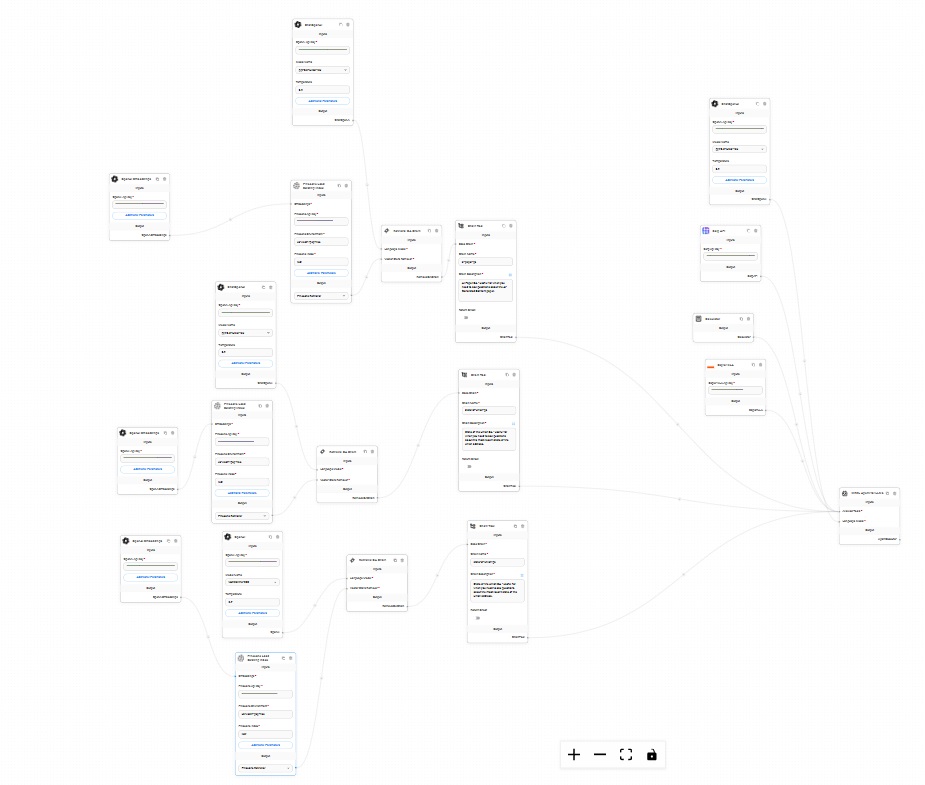
this is a picture of the bubble backend workflow where i use amazon & google OCR with OpenAI and Amazon Entity Detection
-
Day 2 : Nothing is quite working right
-
Day 3 : Stopped using 3rd party plugins and now getting inits
-
Day 3 : Stopped using 3rd party plugins and now getting inits (with variability)
-
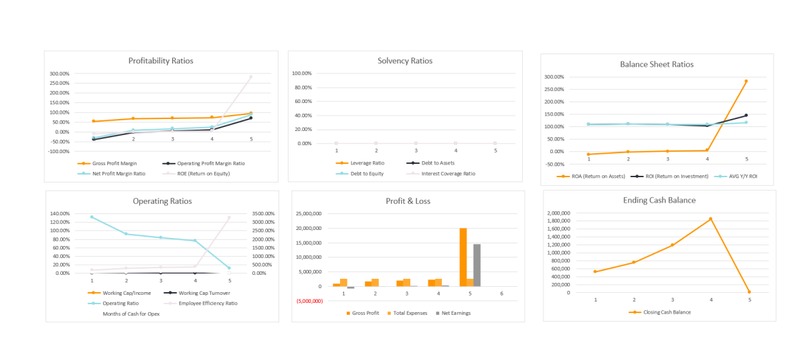
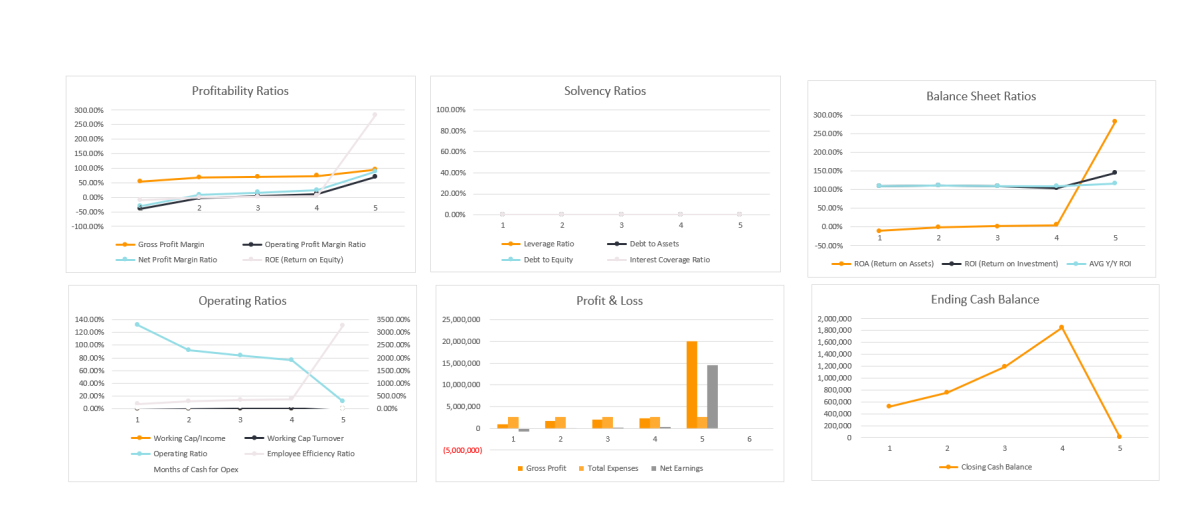
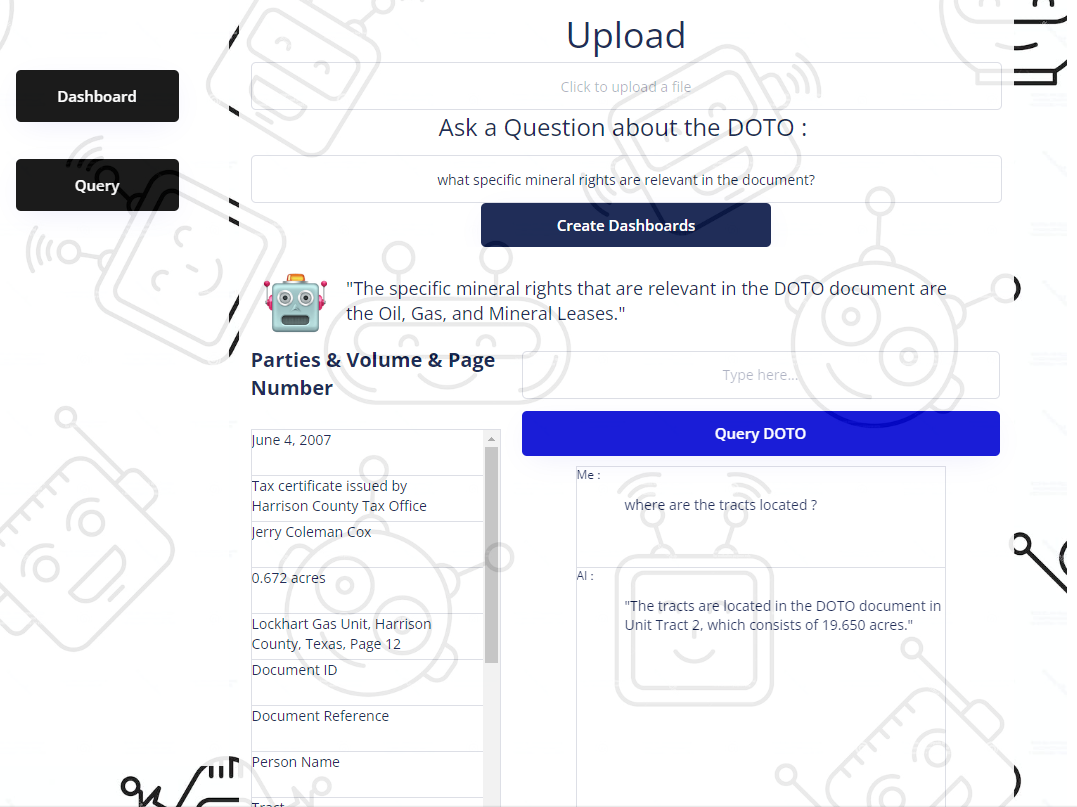
Eventually we will use pinecone data to produce such dashboards as this
-
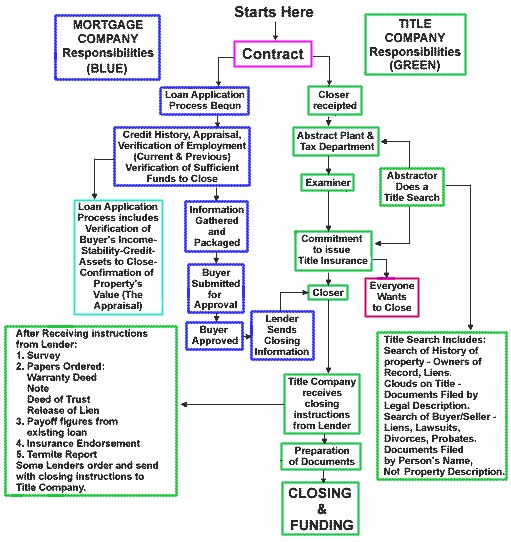
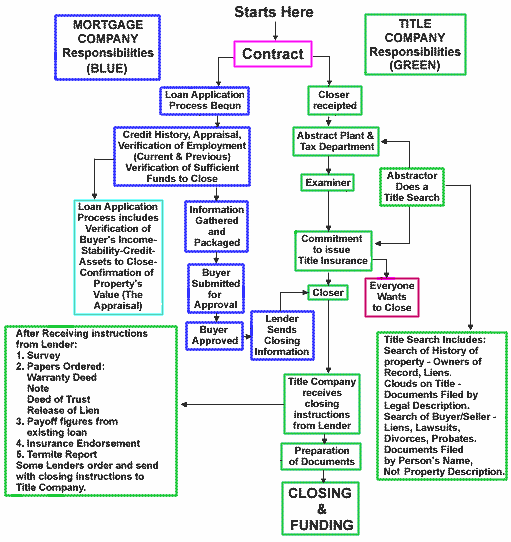
simplified view of the information process
-
Eventually we will use pinecone data to produce such dashboards as this
-
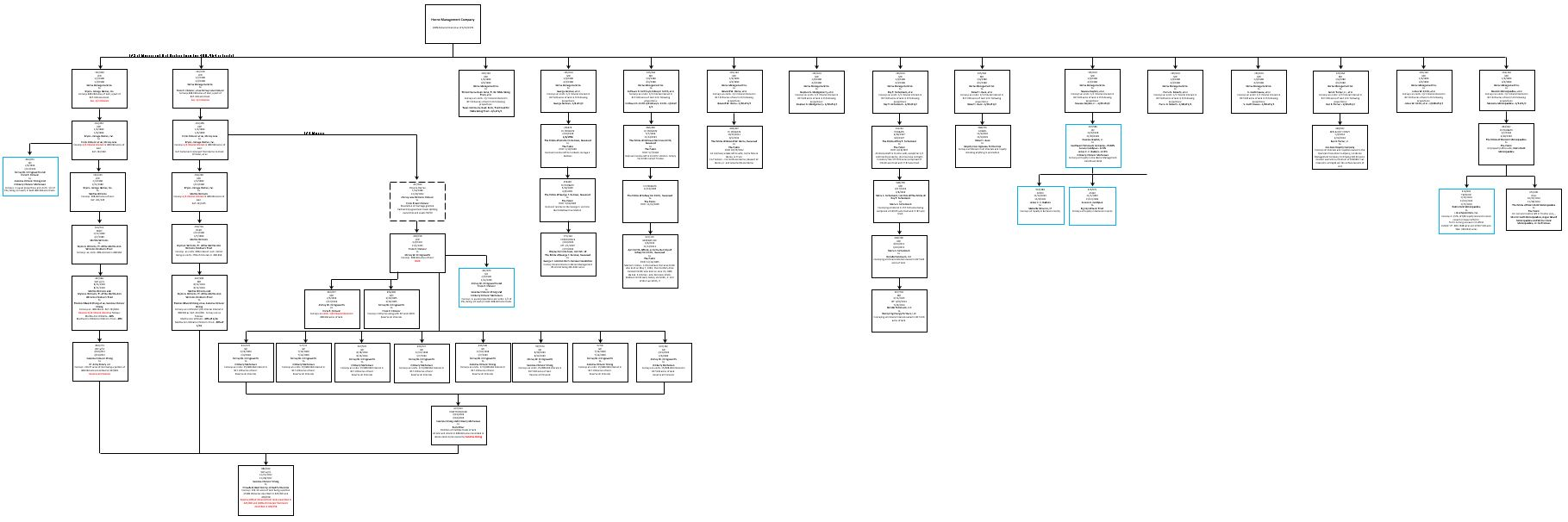
flowchart of information process
-
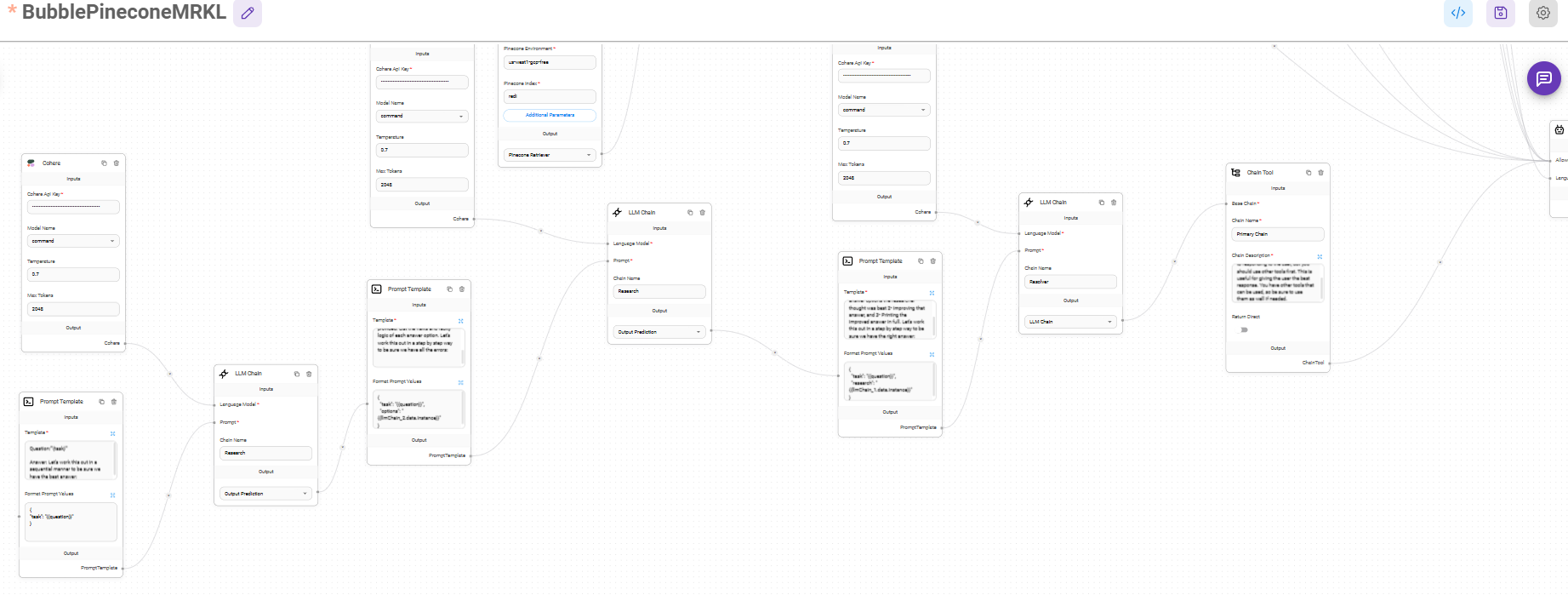
some of what i'm using in langchain
-
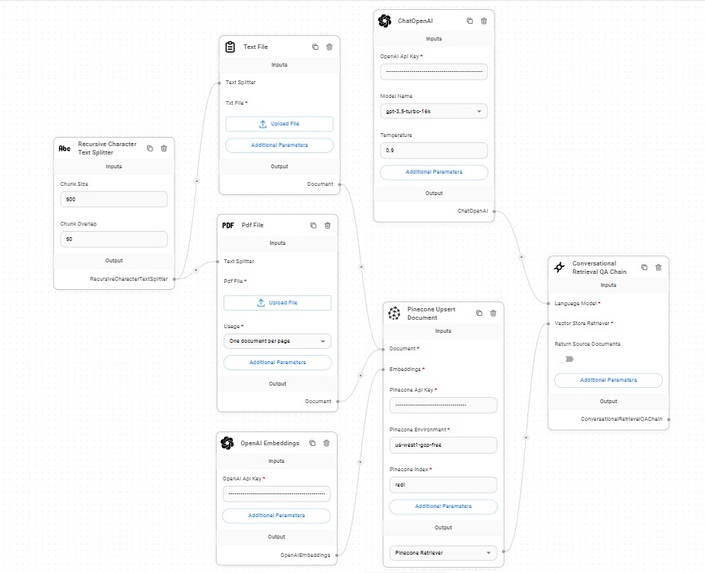
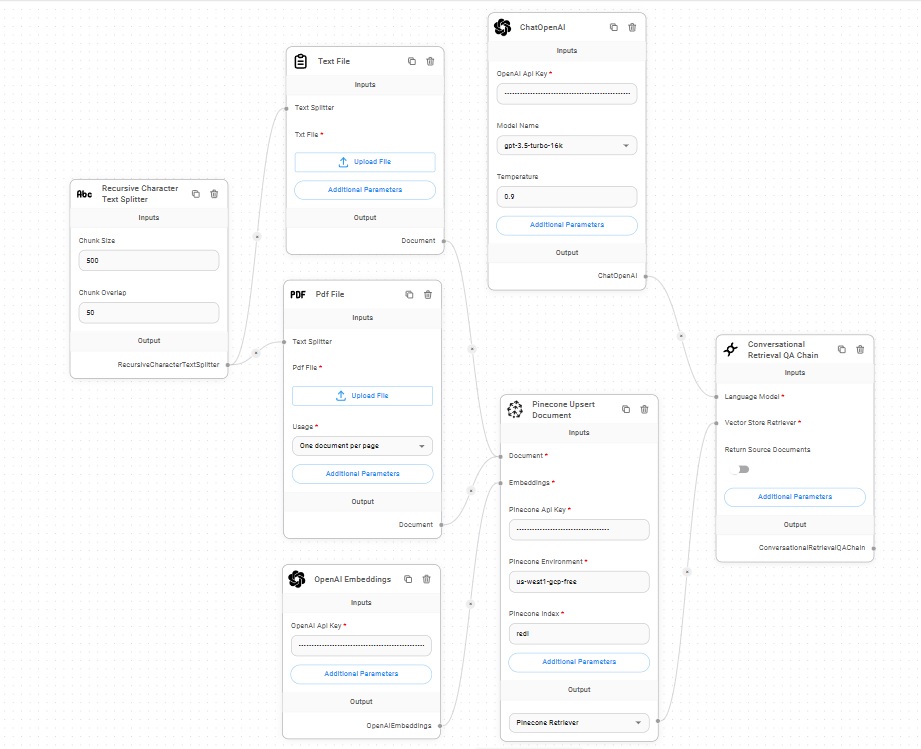
Upsert Bot with retrieval
-
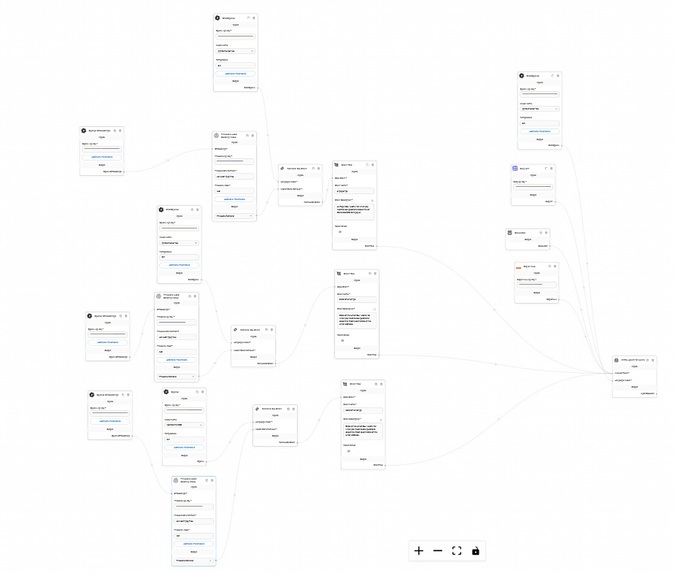
Langchain Retrieval Flow
-
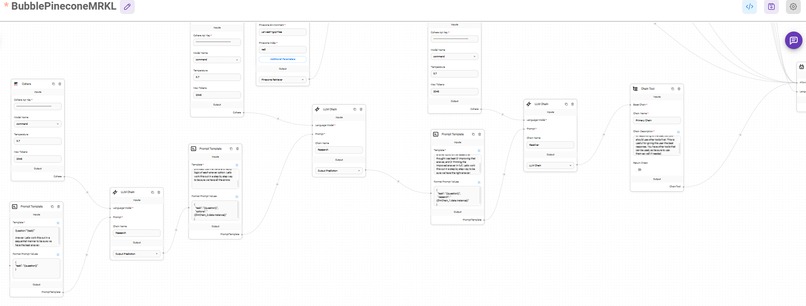
"Smart GPT" flow using langchain built on flowise using cohere
-
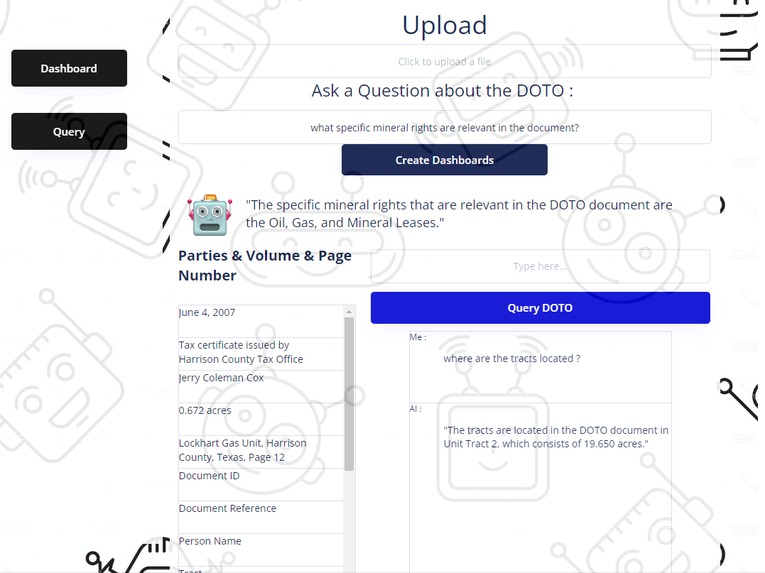
functioning prototype with a heck of a lot of work to do
No Code AI
You can prototype things quickly with no code , including the most advanced langchain agents and using all the latest technology from cloud services.
Inspiration
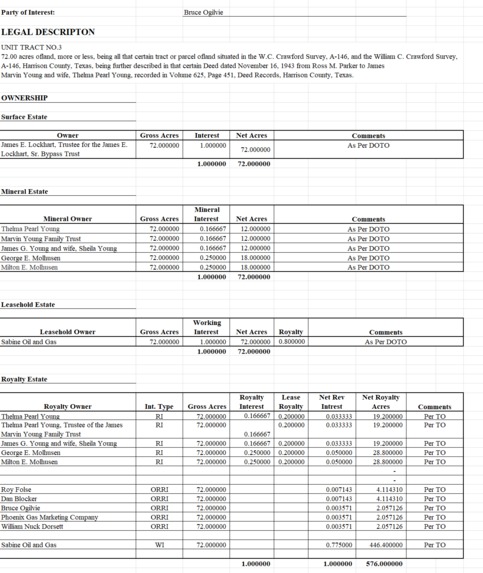
WHAT IS A CHAIN OF TITLE?
A chain of title is a comprehensive document that traces the historical transfer of ownership of mineral rights for a specific tract of land, starting from its original sovereignty.
WHY IS IT IMPORTANT?
The chain of title is required to begin any exploitation of minerals, and is critical to prevent future land disputes, unexpected costs, or total loss of investment associated with the minerals in question.
What it does
Title research made lightning-fast and accurate
How I built it
Explanations of functions
MRKL Agent
beta_MRKL agent is here : https://drive.google.com/file/d/1SkD-8eeg6xn2kVAWQZwGYl5EirtchFUv/view?usp=sharing
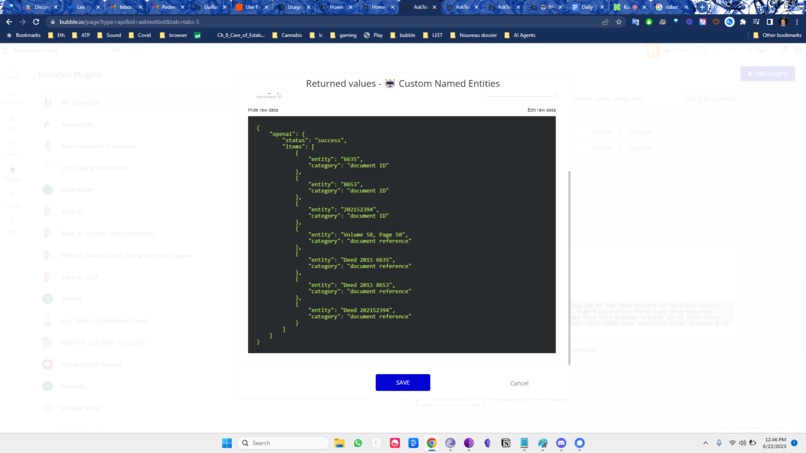
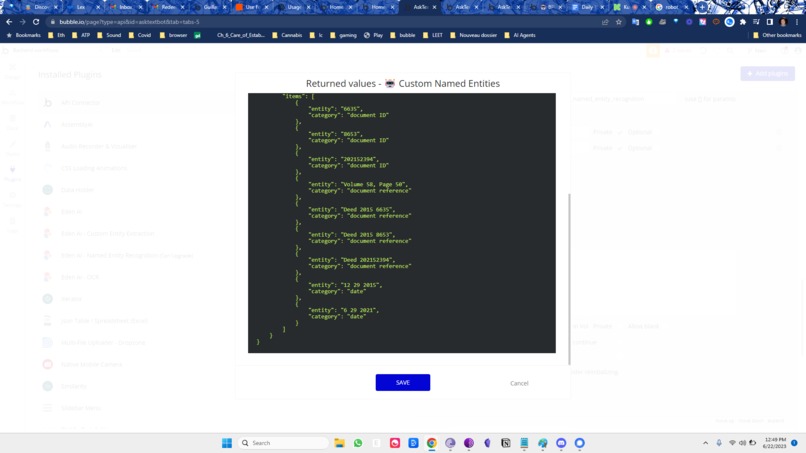
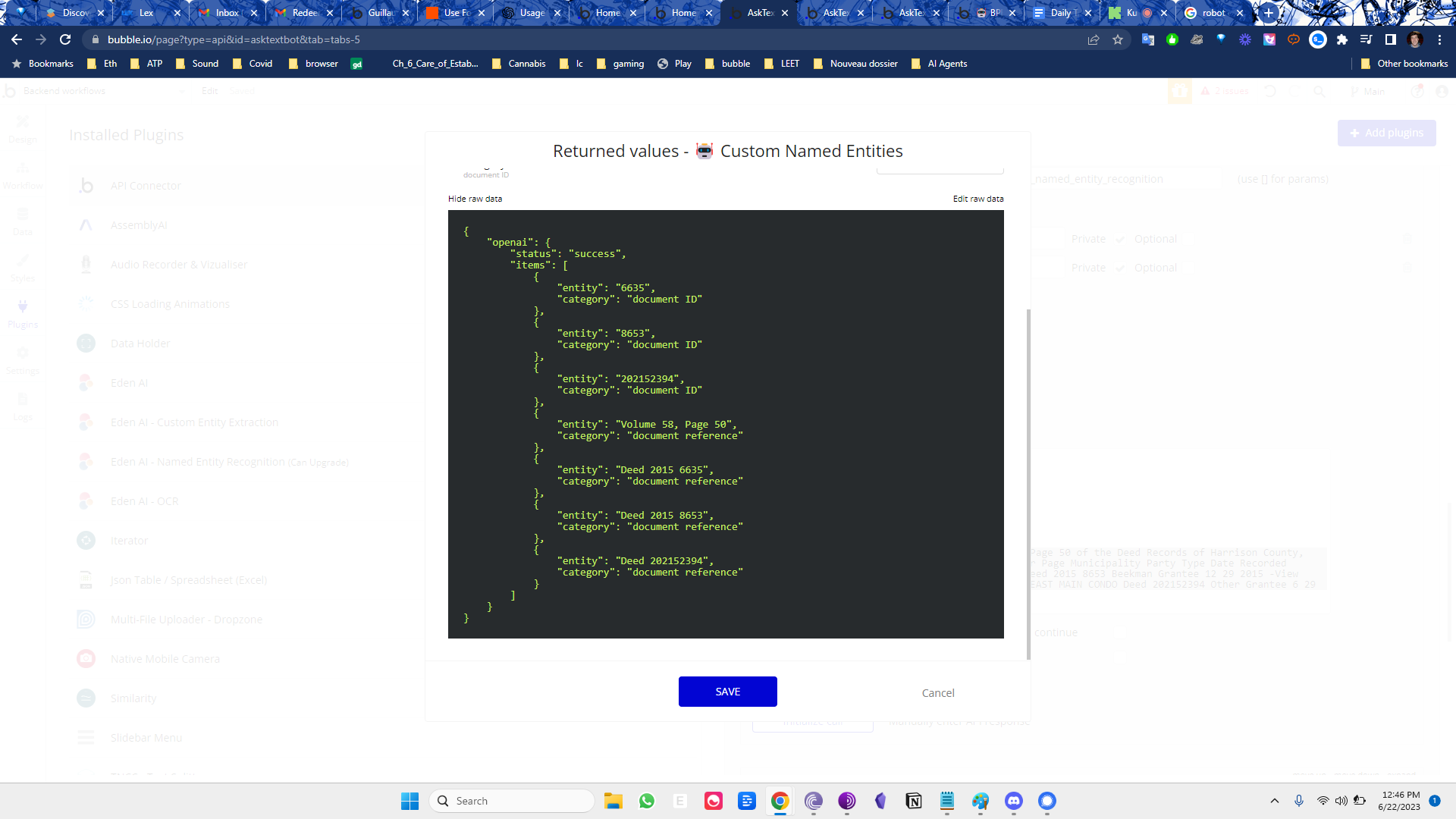
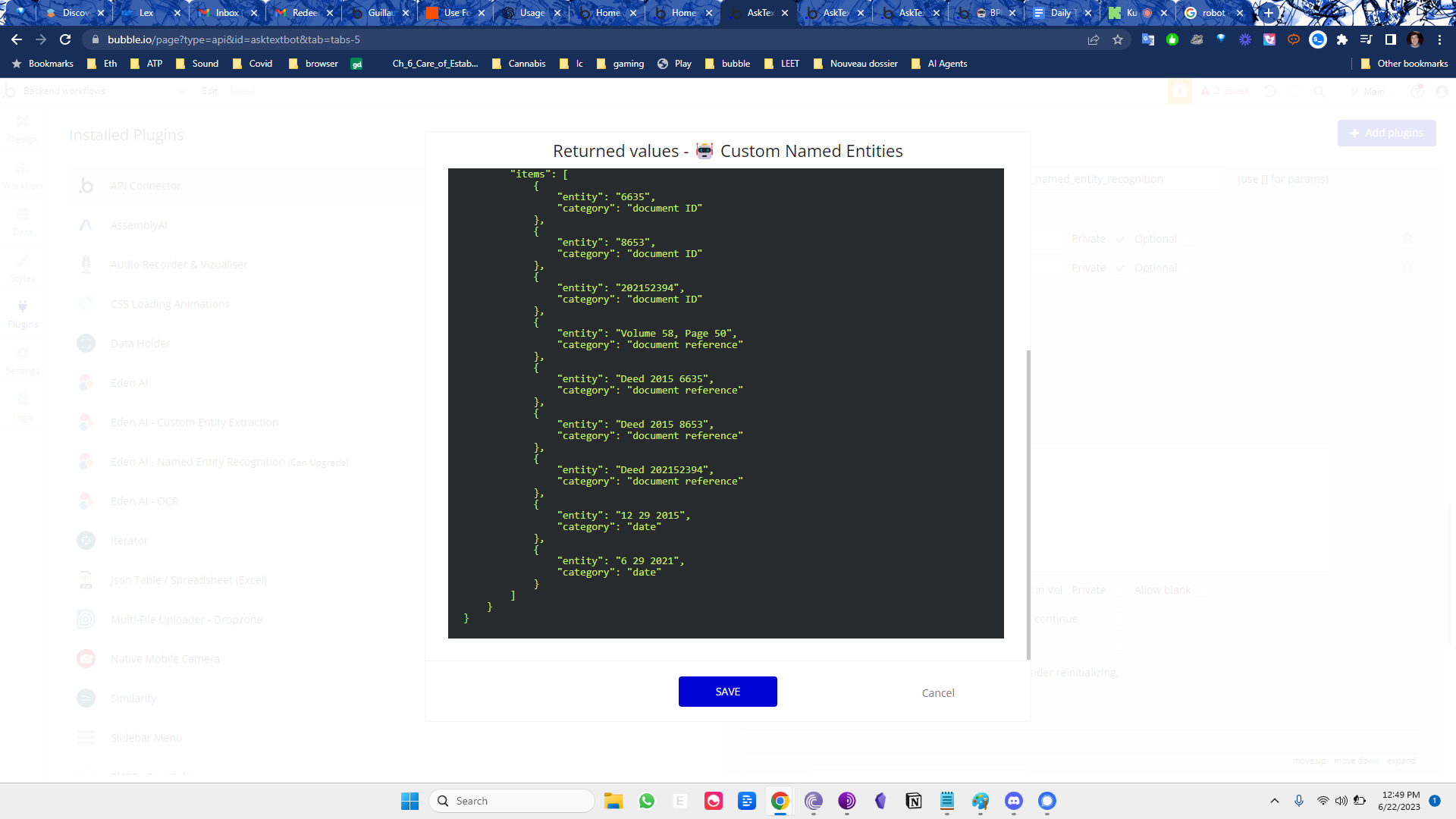
Entity Extraction
basically for enterprise , entity extraction is important, but only if it's fully comprehensive. so:
- I chunk the text accounting for punctuation and words
- pass each chunk through openai entity extraction api
{ "response_as_dict": true, "attributes_as_list": false, "show_original_response": false, "entities": [ "Document ID", "Document Reference", "Entity", "Person Name", "Tract", "Volume and Page Number" ], "providers": "openai", "text": "<text > " } - filter for unique elements
OCR
- I use two OCRs then compare results for quality control
- another for "tables OCR"
Upsert and Retrieval
I use langchain via flowise and pinecone namespaces to give users a chance to get their own data and conversations.
Day 1 :
I'm using bubble as a quarterback node where i allow for document upload , with one button available so far , everything will be here : also pinecone upsert. Keeping the interface very simple.
Using Eden AI to centralize all my AI providers on bubble , not the greatest but it's nice to have a single point where i make a lot of calls.
I'm using five different AI-based OCRs , google generic; amazon tables ,amazon optical , amazon custom entity , open AI custom entity. Then i compare results across providers to assure quality.
I'm looking for names, volume and page numbers, other entities and shares of mineral rights. I'll put those in a filtered list , then work on the pinecone retrieval angle .
Day 2 :
Write Off , 9 hours with support , turns out there was a problem with the supplier's software actually (Cohere, AWS, and Google)
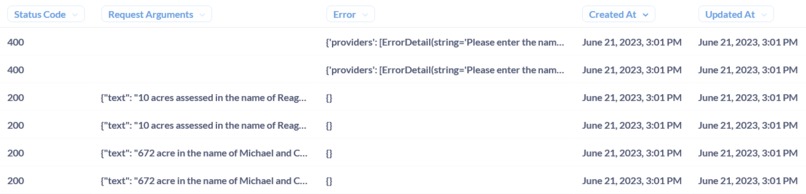
Day 3 :
Eschewed convenient plugins for a custom solution of my making. Cohere entity extraction still doesnt work. Using AWS & Open AI .
Day 4 :
accidently destroyed my database, as you do. Tried to fix it , made a Pinecone retrieval bot as a test.
Day 5 :
created a much more unique and interesting approach to retrieval, need to test it . Made the upsert bot built on Flowise using Langchain. Added some bells and whistles. Ended up enjoying the beach instead of working as much as i should have.
Day 6 :
Last Day to fix things, it's not going well, but should be okay.
Day 7 :
Need to make the entire interface tomorrow. Gonna be a fun sunday xD
Fixed the entity detection and database.
Made advanced MRKL agents using cohere and multiple pinecone retrievals.
Started fixing the interface, need to make the interface for the conversational retrieval and retrieval.
Threw something together for the interface and chat , using a simple pinecone namespace and upsert bot, not my ore advanced solution
Challenges I ran into
Day 1 :
- turns out bubble is kinda a pain for example to secure information
- small context window for retrieval
- comprehensive retrieval requires some backend magics
Day 2 :
Huge headache all day trying to get the basics up and running
Day 3 :
"prompt": "You act as a named entities recognition model. Extract the specified entities (document ID,Document Reference) from the text enclosed in hash symbols (#) and return a JSON List of dictionaries with two keys: \"entity\" and \"category\". The \"entity\" key represents the detected entity and the \"category\" key represents the category of the entity.\n\nIf no entities are found, return an empty list.\n\nExample :\n\n\n\nText: \n1905 and recorded in Volume 58, Page 50 of the Deed Records of Harrison County, Texas.arty Name Sat EC Type Year Doc # Liber Page Municipality Party Type Date Recorded Comment Complement Name - Deed 2015 6635 Deed 2015 8653 Beekman Grantee 12 29 2015 -View Document Information View Document Image 1 EAST MAIN CONDO Deed 202152394 Other Grantee 6 29 2021 PA SMITH KRISTEN\n\nAnswer:\n",
hope this prompt helps folks basically do entity extraction.
what i ended up doing is eschewing third party services and making my own prompt/calls , works fine now, but a bit more annoying to run, in general ... users cant really tell though.
Day 4 :
- Using Bubble is quite frustrating at times
Day 5 :
- it's been tough to make the decision to hackathon instead of the beach.
Day 6 :
- Figuring out comprehensive retrievals has been a challenge , but i got great help from participants in the hackathon
Day 7 :
- Figuring out Langchain has been a challenge
- I havent been able to make the MRKL agent that calls all the namespaces work out - yet !
Accomplishments that I'm proud of
Day 1
- gonna test it now and revert here
Day 2
- made a heck of a lot of bug reports for cohere services , openai api services, neuralspace ai , eden...
Day 3
- made my own entity extraction, worked on the new functions...
Day 5
- got an idea how to fix the database
Day 6
- figured out pinecone and langchain retrieval agents finally
Day 7
- Made some more advanced agents
- figured out how to use namespaces correctly , high performance without paid accounts on pinecone
What I learned
Lesson 1 : Dont Spend More Time On Experimental Tech
- if you know you're all set and still get an error , it's not you
Lesson 2 : Dont Spend Too Much Time on Security During a Hackathon
- If you're a beach holiday , it's not the right time for you to be securing something if that's not the central activity of said thing
Lesson 3 : Talk to Participants
- i leaned a lot talking to folks inside the hackathon
- will probably use their systems later , awesome thing to get early access to raiden.ai etc.
What's next for Tonic's Pinecone Hackathon Submission
Search
We make it easy to search for what you are looking for.
Search by:
- Name of grantor or grantee
- Abstract no.
- Block
- County
- Date range
- Lat/long
- Well
- Lease
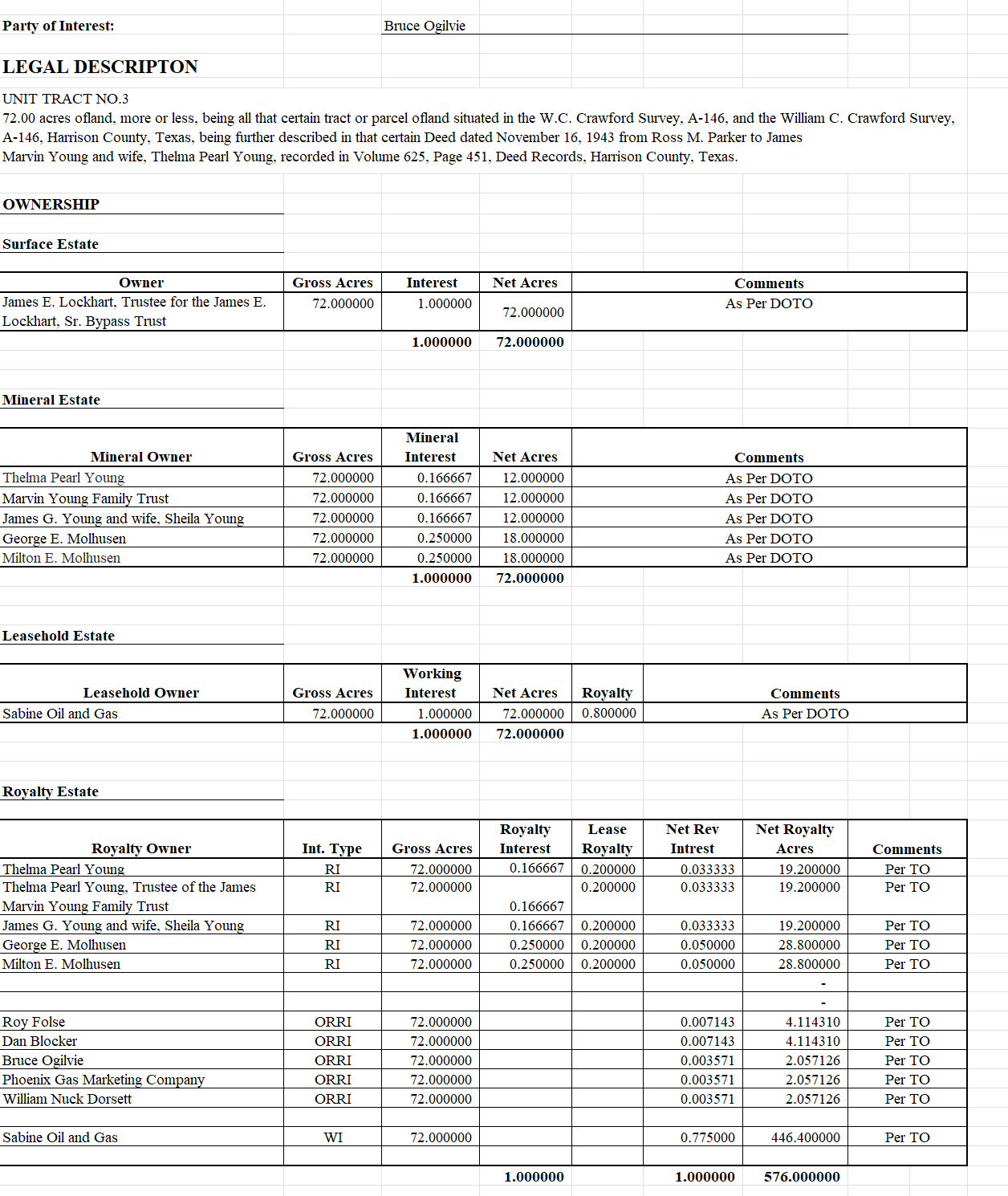
Full Chain of Title
Delivered in our standardized format, so all you have to do is review.
It includes all the necessary back-up documentation used to establish the chain of title.
Runsheet
We provide you with a complete picture starting from the initial grant of minerals by the US government up to the present day.
Includes key information such as:
- Document type
- Reception number
- Record date
- Grantor
- Grantee
- Legal description
- Comments
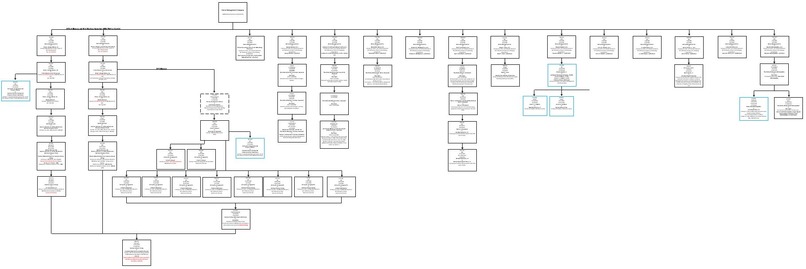
Flowchart
We show you a map of the division of interests calculated since inception. We make it easy to follow the history.
Interest table
We calculate the division of interests for you in a tabular format with each party’s current ownership. Told you we made it easy.
Abstract
We provide a pdf of the abstract. We are your one stop shop!
Roadmap
- filter entities into people and document references (two lists) using zapier's new data processing function
- add a radio button to select relevant entities and document references
- pass those references to the user queries
- Create a "log in to Zapier" so folks can use NLA on their own Zaps
- fix the MRKL agent
- replace it for chat
- create dashboards
- raise a fund to acquire mineral rights
Built With
- amazon-web-services
- azure
- bubble
- cohere
- flowise
- gcs
- huggingface
- langchain
- openai
- pinecone
- render





Log in or sign up for Devpost to join the conversation.