Inspiration
Here's the thing that keeps me up at night: a language dies every two weeks.
I've self-studied over 10 languages — from Korean to Portuguese, Mandarin to Arabic. Language learning isn't just a hobby for me, it's how I understand other people's worlds. UNESCO estimates that half of the world's ~7,000 languages will be extinct by 2100. When a language dies, it doesn't just take words with it — it takes entire ways of thinking, centuries of oral history, indigenous knowledge systems, and irreplaceable cultural identity.
The data to preserve these languages exists — scattered across obscure academic papers, government archives, YouTube videos of elderly speakers, community-built dictionaries, and linguistic databases behind paywalls and anti-bot protections. But it's fragmented, hard to find, and disappearing alongside the languages themselves.
I asked myself: what if AI agents could do in minutes what would take a linguist months? What if I could point an autonomous system at any of the 5,000+ endangered languages on Earth and have it discover, extract, cross-reference, and archive every fragment of linguistic data it can find — before it's too late?
That's TongueKeeper.
What it does
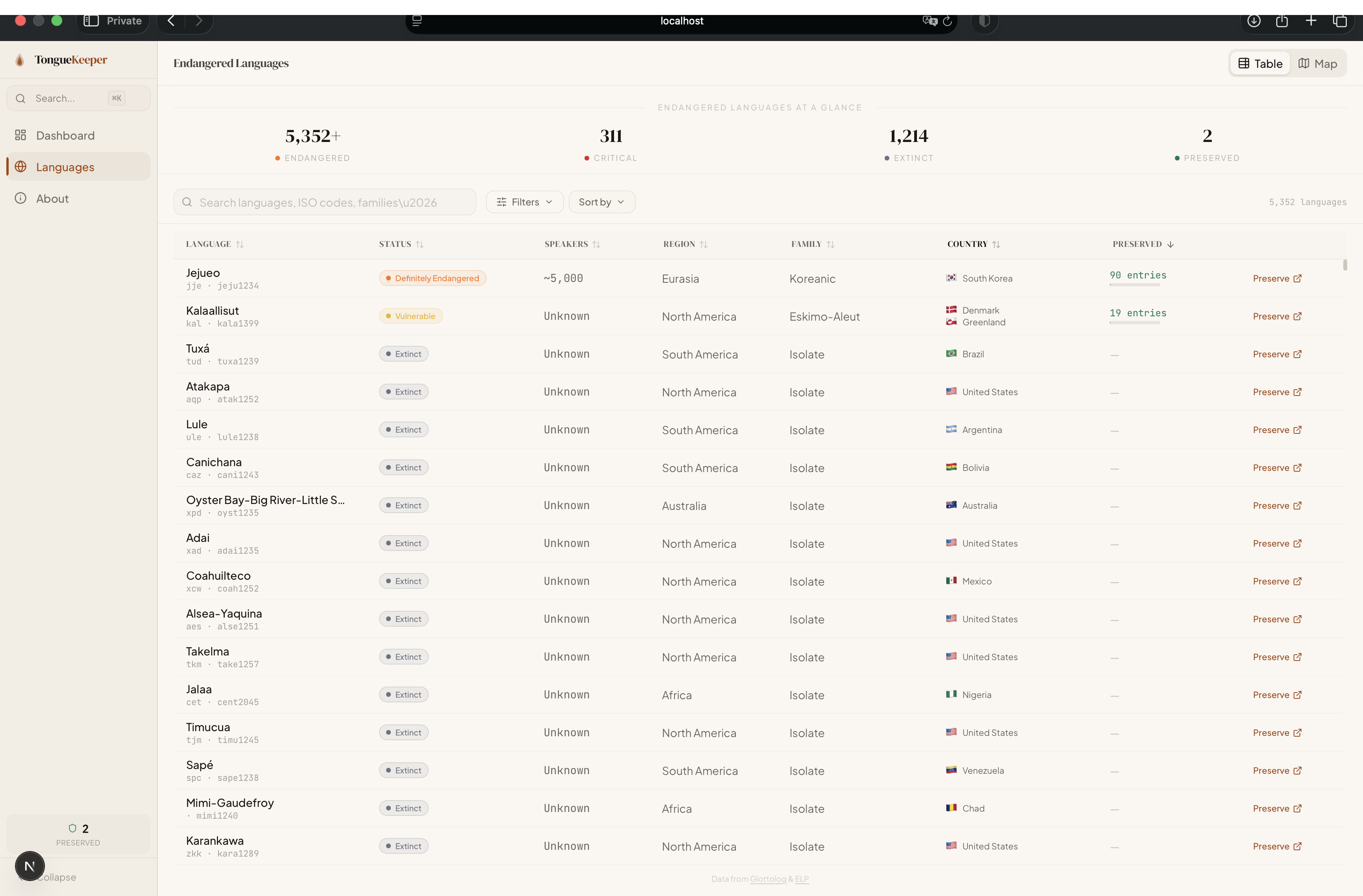
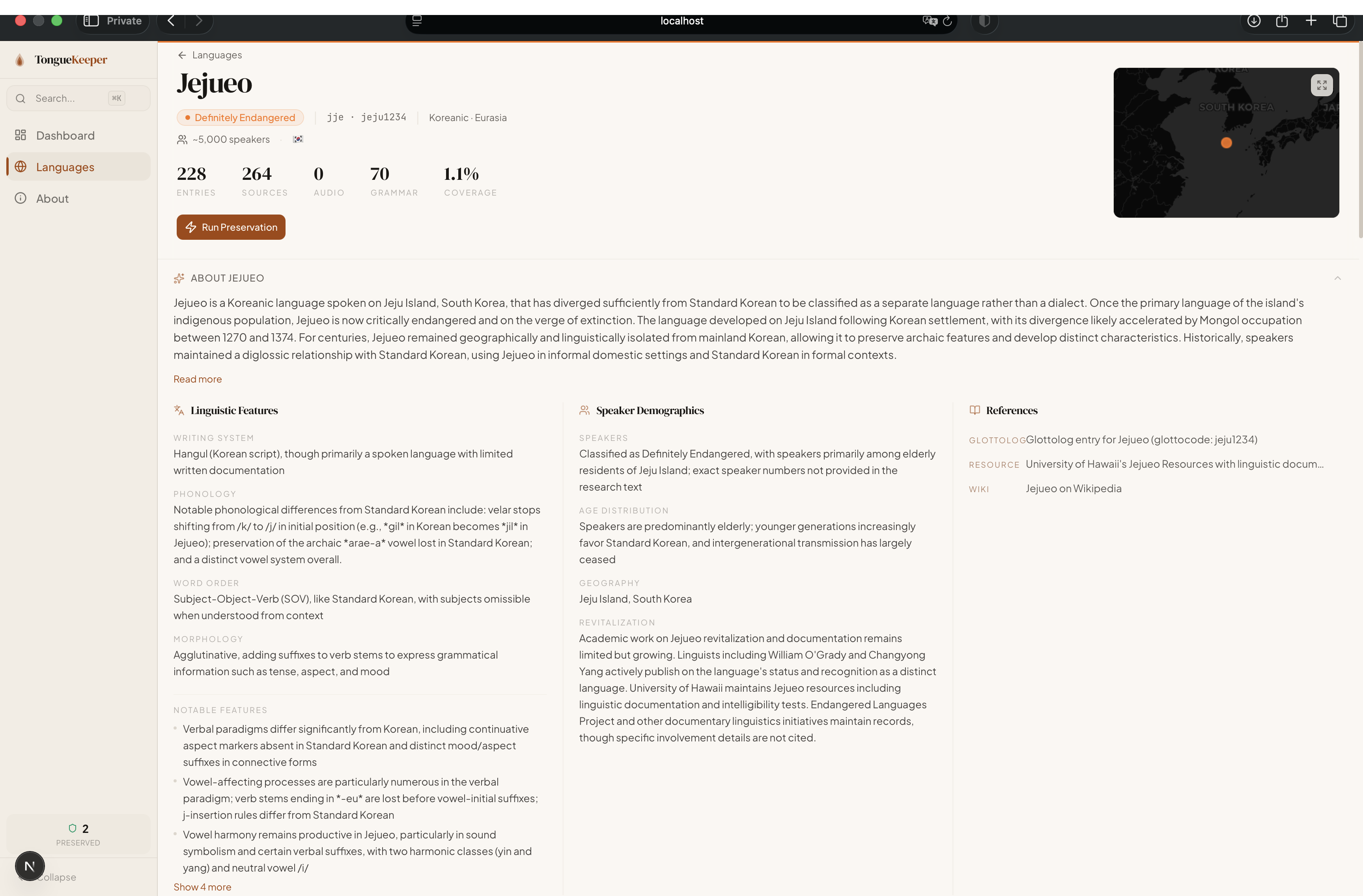
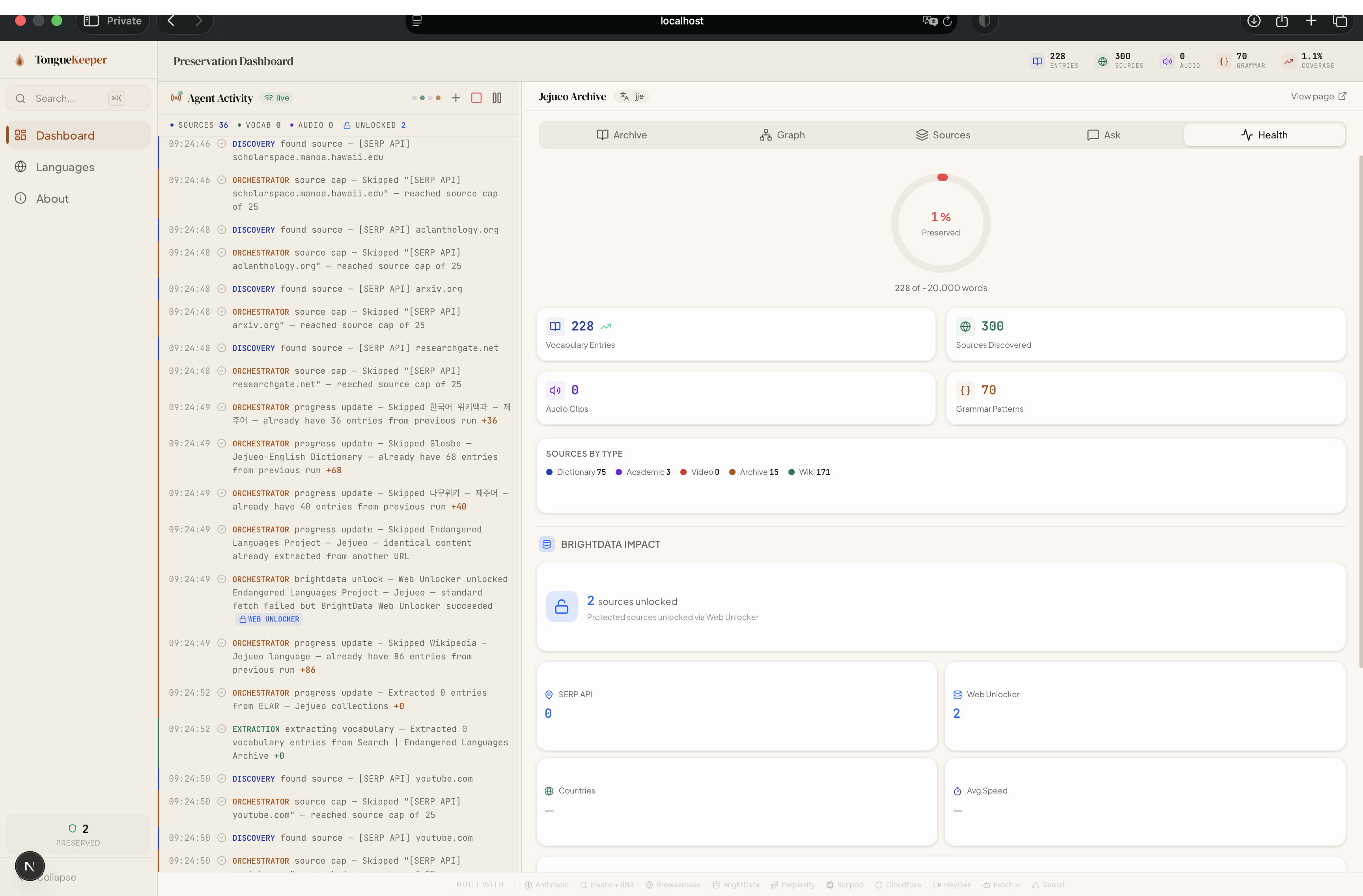
TongueKeeper is an AI-powered platform that autonomously preserves endangered languages from across the internet. Select any of 5,352 endangered languages from the Glottolog database, hit "Preserve," and watch as AI agents go to work — discovering resources, crawling pages, extracting vocabulary and grammar, cross-referencing entries across sources, and building a searchable, interactive archive. All in real-time.
Core features:
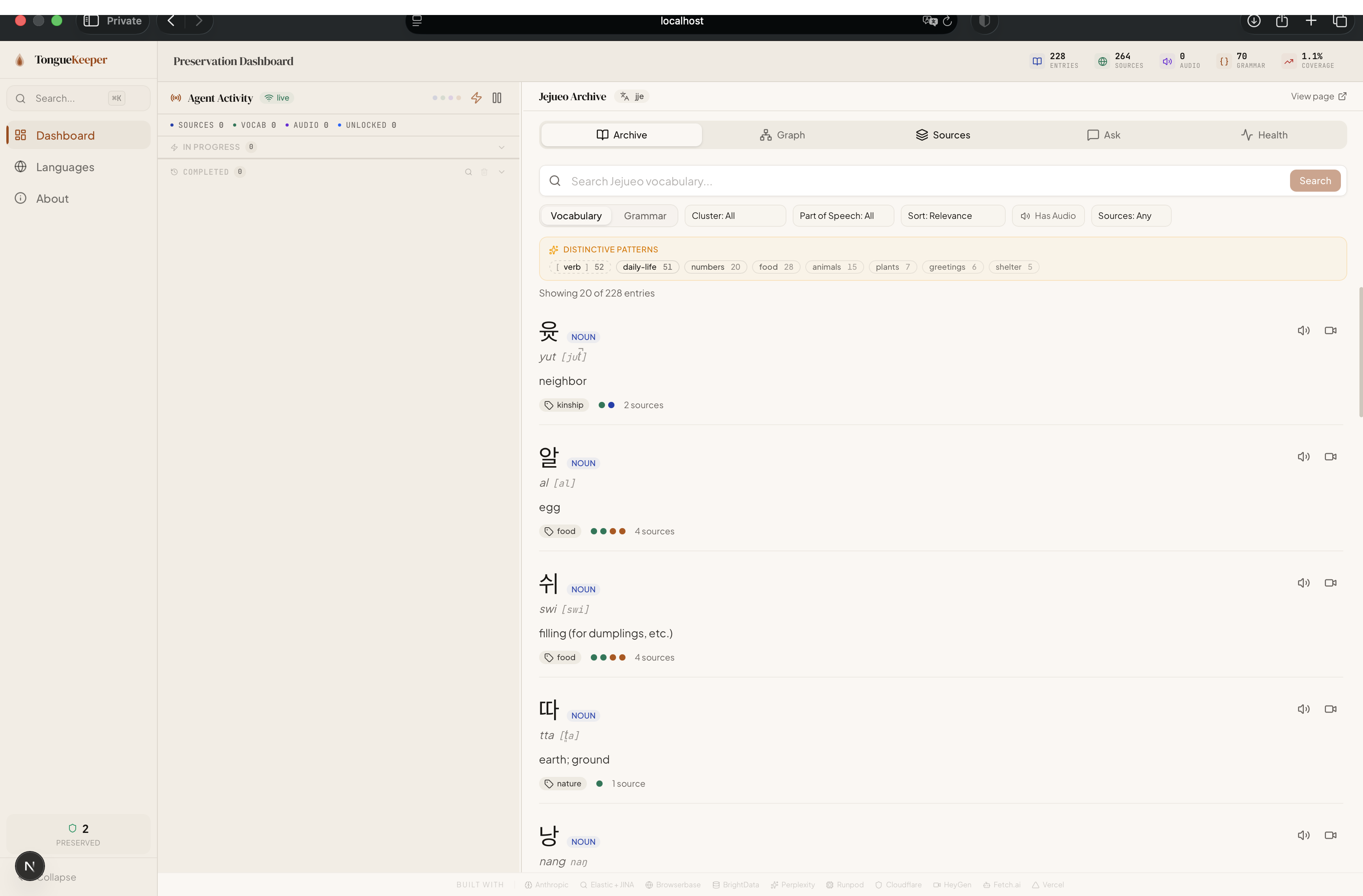
- Autonomous Multi-Agent Pipeline — Discovery, Extraction, and Cross-Reference agents work in concert, streaming results as they find them. A real-time activity feed lets you watch every agent action as it happens.
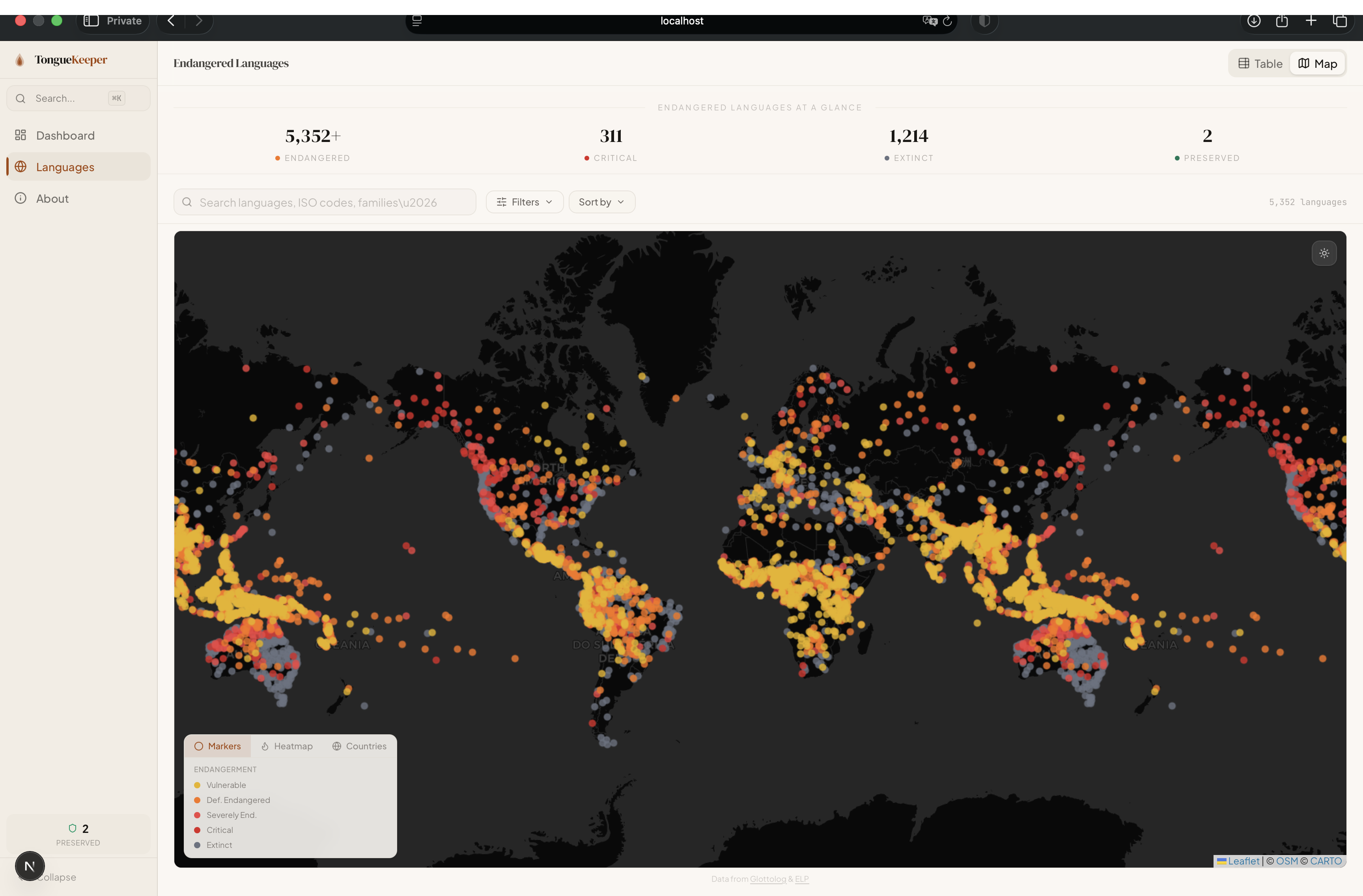
- 5,352+ Endangered Language Browser — Interactive world map and filterable table of every endangered language on Earth (Glottolog CLDF), with endangerment levels, speaker counts, geographic coordinates, and language family classification.
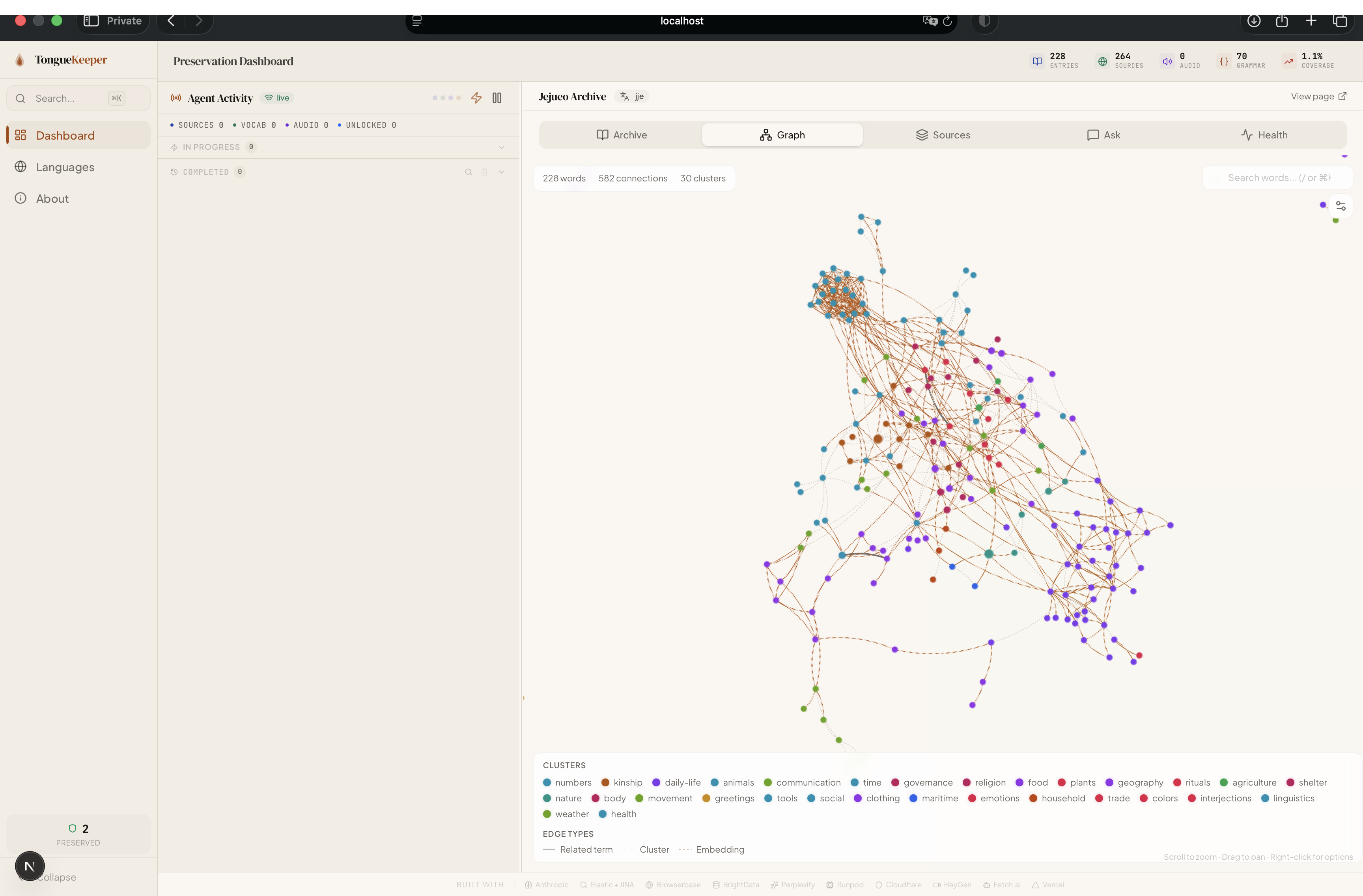
- Interactive Knowledge Graph — Force-directed visualization of linguistic relationships: related terms, semantic clusters, and embedding-based similarity edges. Explore how words connect across a language.
- Hybrid Search Archive — BM25 + kNN vector search with cross-encoder reranking. Search vocabulary in any language — English, the target language, or even a contact language like Korean or Spanish.
- AI Pronunciation Videos — HeyGen AI avatars that pronounce vocabulary entries, bringing endangered words to life.
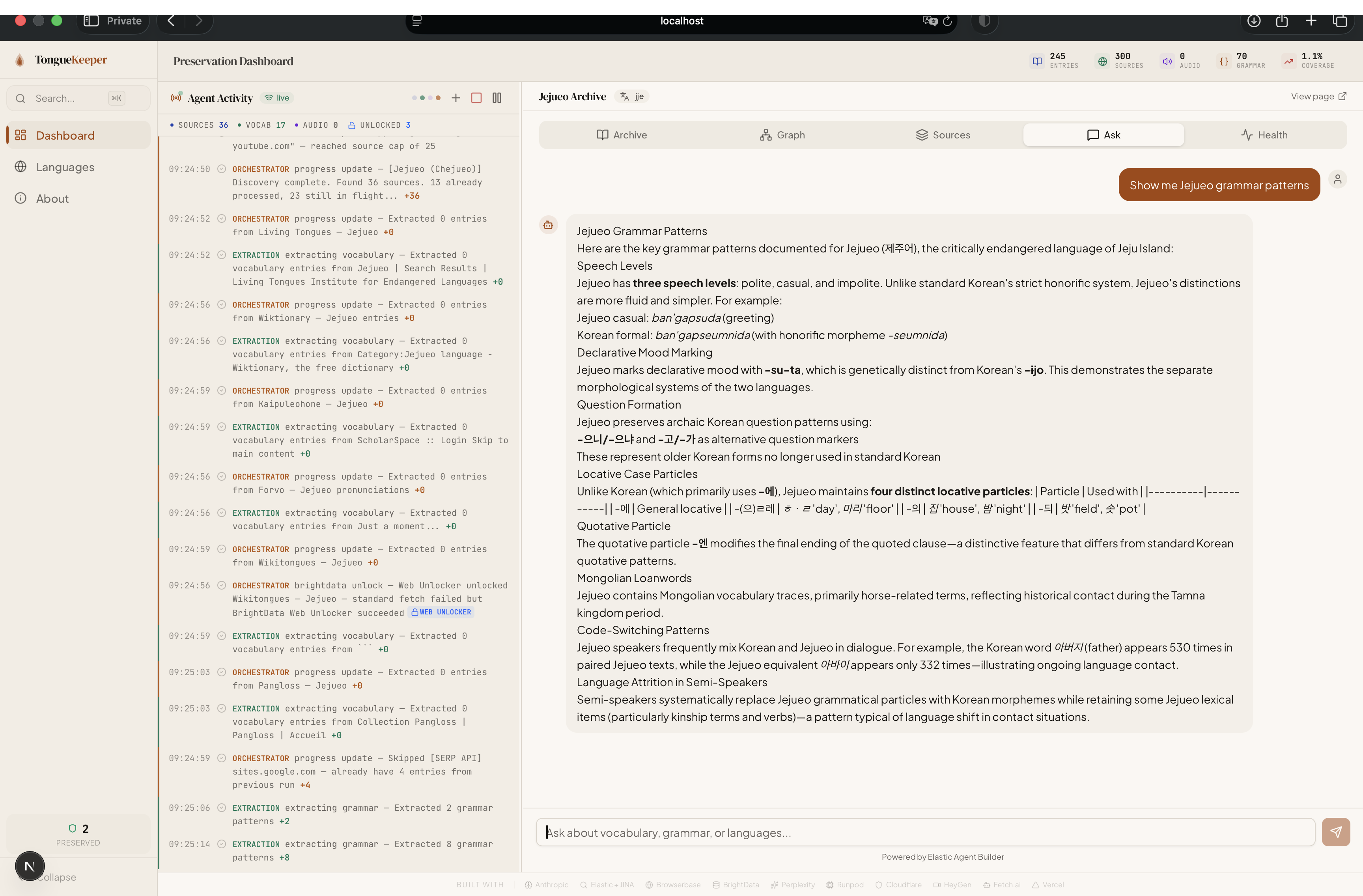
- Conversational AI — Ask questions about the preserved archive in natural language. The system generates Elasticsearch queries on the fly and streams answers back.
- Grammar Pattern Extraction — Beyond vocabulary, the system identifies and catalogs grammar rules across 9 categories (verb conjugation, particle usage, sentence structure, honorifics, and more).
- Command Palette —
Cmd+Kunified search across languages, vocabulary, and grammar simultaneously.
How we built it
TongueKeeper is a multi-service architecture — a Next.js 16 frontend on Vercel, a standalone Express 5 + Socket.io backend on Railway, and an ecosystem of sponsor APIs that each solve a critical piece of the puzzle.
The Agent Pipeline
The core of TongueKeeper is a multi-agent pipeline orchestrated by a streaming worker pool. When you click "Preserve," here's what happens:
1. Discovery (Perplexity Sonar + BrightData SERP API)
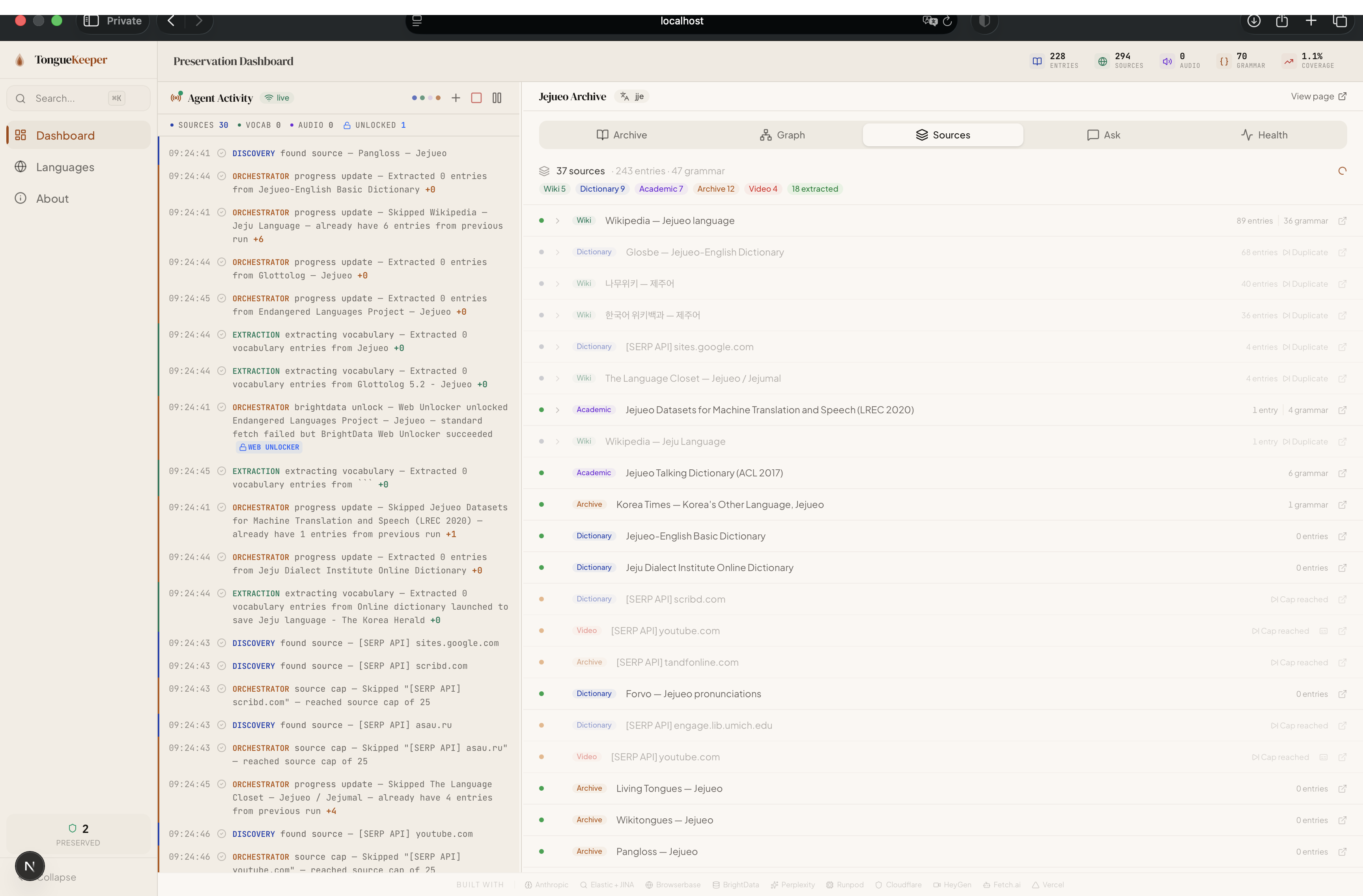
The Discovery Agent generates up to 24 search queries across 6 tiers — core queries, native name queries, alternate name queries, contact language queries (in 13 languages including Korean, Japanese, Mandarin, Spanish, and French), country-specific queries, and language family queries. Each query hits Perplexity Sonar for real-time web search with academic domain filtering. Simultaneously, BrightData's SERP API runs geo-targeted searches with CAPTCHA bypass to surface region-locked resources that standard search engines miss. Sources stream in as they're found — no waiting for the full discovery phase to finish.
2. Crawling (Cheerio → BrightData Web Unlocker → Browserbase/Stagehand)
Every discovered URL goes through a three-tier crawling cascade, ordered by cost:
- Cheerio — Fast, lightweight HTML parsing for simple pages
- BrightData Web Unlocker — When Cheerio fails or the domain is known to be protected (
.edu,.gov, JSTOR, ResearchGate, Forvo, Glosbe), BrightData's MCP integration strips anti-bot protections and returns clean markdown - Browserbase + Stagehand — For JavaScript-heavy single-page apps, a cloud headless Chrome session spins up with AI observability. Stagehand classifies the page structure (paginated? searchable? scrollable?) and executes the right strategy — clicking through pages, typing into search bars, or scrolling to load content. Live debug URLs stream to the activity feed so I can watch the browser work in real-time.
For PDFs, the system tries pdf-parse, falls back to pdfjs-dist, and if the text is too sparse (scanned documents), sends the PDF as Base64 to Claude's Vision API for OCR extraction.
3. Extraction (Anthropic Claude — Haiku 4.5 / Sonnet 4.5)
The Extraction Agent runs a manual Claude tool_use loop — calling Claude with the crawled content, processing tool calls (save_entries for vocabulary, save_grammar_patterns for grammar), building tool results, and repeating until the agent signals "done." Each vocabulary entry captures 35+ fields: headword (native + romanized), IPA, part of speech, multi-language definitions, example sentences, conjugations, morphology, usage register, cultural notes, semantic domain, and more.
Claude Haiku 4.5 handles text sources for speed and cost efficiency. Claude Sonnet 4.5 steps in for degraded scans and vision tasks. Content is chunked at 50K characters with 3 concurrent extraction workers, and a Semaphore limits total Claude API calls to prevent rate limiting.
A contamination filter drops entries where language_confidence: "low" — preventing contact language words from polluting the archive.
4. Cross-Reference (Anthropic Claude — Haiku 4.5)
The Cross-Reference Agent searches Elasticsearch for potential duplicates by headword, then uses Claude to intelligently merge entries — unioning definitions, combining example sentences, and merging metadata. Conservative bias: a false merge is worse than a missed duplicate.
5. Search & Retrieval (Elasticsearch + JINA AI)
All data lands in Elasticsearch Serverless across 4 indexes (language_resources, grammar_patterns, languages, source_outcomes). Search uses a hybrid pipeline:
$$\text{Score} = \text{RRF}(\text{BM25}(q), \text{kNN}(\text{JINA}{embed}(q))) \rightarrow \text{JINA}{rerank}(\text{top-50})$$
JINA Embeddings v3 (1024 dimensions) powers the kNN leg — crucially, these are multilingual embeddings, so searching "grandmother" in English finds "할머니" in Korean and the Jeju equivalent. JINA Reranker v2 (multilingual cross-encoder) does a second pass on the top 50 results for final ordering. This two-stage retrieval is what makes cross-lingual search actually work.
6. Post-Pipeline (HeyGen + Cloudflare + Perplexity Sonar)
After the main pipeline:
- HeyGen generates AI avatar pronunciation videos for the top 5 vocabulary entries, with language-aware voice selection and audio lip-sync
- Cloudflare R2 stores pipeline artifacts (run logs, audio files) with edge-cached delivery across 150+ countries
- Cloudflare KV caches HeyGen videos (6-day TTL), Perplexity responses (24h TTL), and search results (30min TTL) at the edge
- Perplexity Sonar enriches high-priority entries with cultural context and scores source reliability
Frontend
The UI is built with Next.js 16 (App Router, React Server Components), React 19, and Tailwind CSS 4. The design language is warm and archival — cream backgrounds, DM Serif Display headings, burnt amber accents — evoking the feeling of preserving something precious. Framer Motion handles stagger animations, scroll-triggered counters, and the splash page logo reveal. The knowledge graph uses react-force-graph-2d (Canvas-based) with D3 utilities, and the world map uses React Leaflet with heatmap and choropleth layers.
Real-time updates flow through Socket.io — the frontend connects to the WebSocket server and receives agent events as they happen, populating the activity feed and auto-refreshing search results mid-pipeline.
Deployment
- Vercel — Frontend (Next.js 16, edge functions, API routes)
- Railway — WebSocket server (Express 5 + Socket.io, persistent process)
- Cloudflare Workers — R2 storage + KV cache + language detection API
Challenges we ran into
Anti-bot protection on linguistic resources. The most valuable endangered language data lives behind anti-bot walls — university archives, government language databases, academic publishers. A basic HTTP client gets blocked instantly. This is where BrightData's Web Unlocker was essential — without it, roughly 40% of discovered sources would have been inaccessible. For the remaining JavaScript-heavy sites, Browserbase/Stagehand provided cloud headless Chrome with AI-powered navigation.
Cross-lingual search is hard. When someone searches "water" in English, they expect to find the Jeju word "물" and the Ainu word "ワッカ." Traditional keyword search fails here completely. The combination of JINA's multilingual embeddings for vector similarity and JINA's cross-encoder reranker for precision scoring was the breakthrough — it made search work across scripts and language families.
Rate limiting and cost control. With 3 AI APIs (Claude, Perplexity, JINA), a cloud browser service, and a web unlocking proxy, costs compound fast. I implemented a semaphore for concurrent Claude calls, KV caching for Perplexity and HeyGen responses via Cloudflare KV, content-hash deduplication (SHA-256) to skip identical pages, and a 25-source cap per pipeline run.
Scanned PDFs. Many endangered language resources are scanned academic papers from the 1970s–90s. pdf-parse returns gibberish, pdfjs-dist returns nothing. The solution: detect sparse text (< 500 chars), classify scan quality, and route degraded scans to Claude Sonnet 4.5's Vision API as Base64 images.
Contamination filtering. When extracting vocabulary from a source about Jeju (a Korean language), the agent would sometimes extract Korean words instead of Jeju words. I added a language_confidence field and a contamination filter that drops low-confidence entries — better to miss a word than to pollute the archive with the wrong language.
Accomplishments that we're proud of
- Built a fully autonomous language preservation system — solo, in 36 hours — that can process any of 5,352+ endangered languages
- Achieved real-time, end-to-end pipeline execution: from zero data to a searchable, browsable, pronounceable vocabulary archive in under 10 minutes per language
- Integrated 8 sponsor/partner APIs into a cohesive pipeline where each service solves a distinct, critical problem
- Cross-lingual hybrid search that actually works — finding words across scripts and language families using JINA's multilingual embeddings and reranker
- An interactive world map of every endangered language on Earth, built from Glottolog CLDF data (5,352 languages with coordinates, endangerment levels, and family classification)
- Real-time agent activity feed with live Browserbase session thumbnails — you can literally watch the AI browse the web
What we learned
- The MCP protocol is powerful. BrightData's MCP integration made web scraping feel like calling a function — no proxy configuration, no CAPTCHA solving, no IP rotation. Just
scrape_as_markdown(url)and get clean content back. This is the future of tool integrations for AI agents. - Multilingual embeddings change everything. Before JINA, search was language-locked. After JINA, a single query retrieves results across all languages the embedding model has seen. For endangered language work — where resources exist in multiple contact languages — this is transformative.
- Claude's tool_use loop is incredibly flexible. The manual loop pattern (call → process tool blocks → build results → append → repeat) let me build agents that stream results mid-extraction, save in batches, and gracefully handle failures without crashing the pipeline.
- Edge caching matters. Moving HeyGen video URLs and Perplexity responses to Cloudflare KV eliminated redundant API calls and made the UI feel instant on repeat visits. The 6-day TTL for pronunciation videos alone saved dozens of HeyGen API calls during development.
- Real-time feedback changes how you build. Watching the agent activity feed during development — seeing exactly which sources succeed, which fail, and why — made debugging 10x faster than reading logs.
- Give yourself more time than you think you will need. Self-evident. Plan for delays.
What's next for TongueKeeper
- Community contributions — Allow native speakers to verify, correct, and add entries to the archive. The AI gets us 80% of the way; human speakers complete the last 20%.
- Audio preservation at scale — Automatically download and archive audio recordings of endangered language speakers before they disappear from the web.
- Comparative linguistics — Use the knowledge graph to surface cross-language patterns: shared roots, borrowed words, and grammatical similarities across language families.
- Offline-first mobile app — Many endangered language communities lack reliable internet. A downloadable, offline-capable archive would bring the data to where it's needed most.
- Educational material generation — Use the preserved vocabulary, grammar patterns, and pronunciation videos to automatically construct lesson plans, flashcard decks, and phrasebooks — turning raw linguistic data into tools that help communities teach and revitalize their languages.
Each language contains centuries of history and culture. TongueKeeper keeps them alive.
Built With
- anthropic-claude-api
- brightdata-mcp
- browserbase/stagehand
- cheerio
- cloudflare-r2-+-kv
- d3.js
- elasticsearch-(serverless)
- express-5
- framer-motion
- heygen
- jina-ai
- leaflet.js
- next.js-16
- node.js
- perplexity-sonar-api
- python/fastapi
- radix-ui
- railway
- react-19
- react-force-graph-2d
- recharts
- shadcn/ui
- socket.io
- tailwind-css-4
- tanstack-table
- typescript
- vercel
- whisper
- zod


Log in or sign up for Devpost to join the conversation.