-
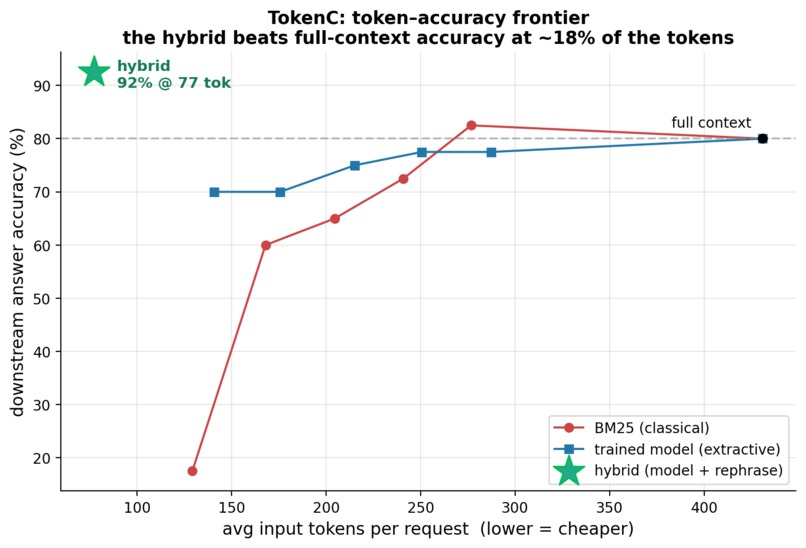
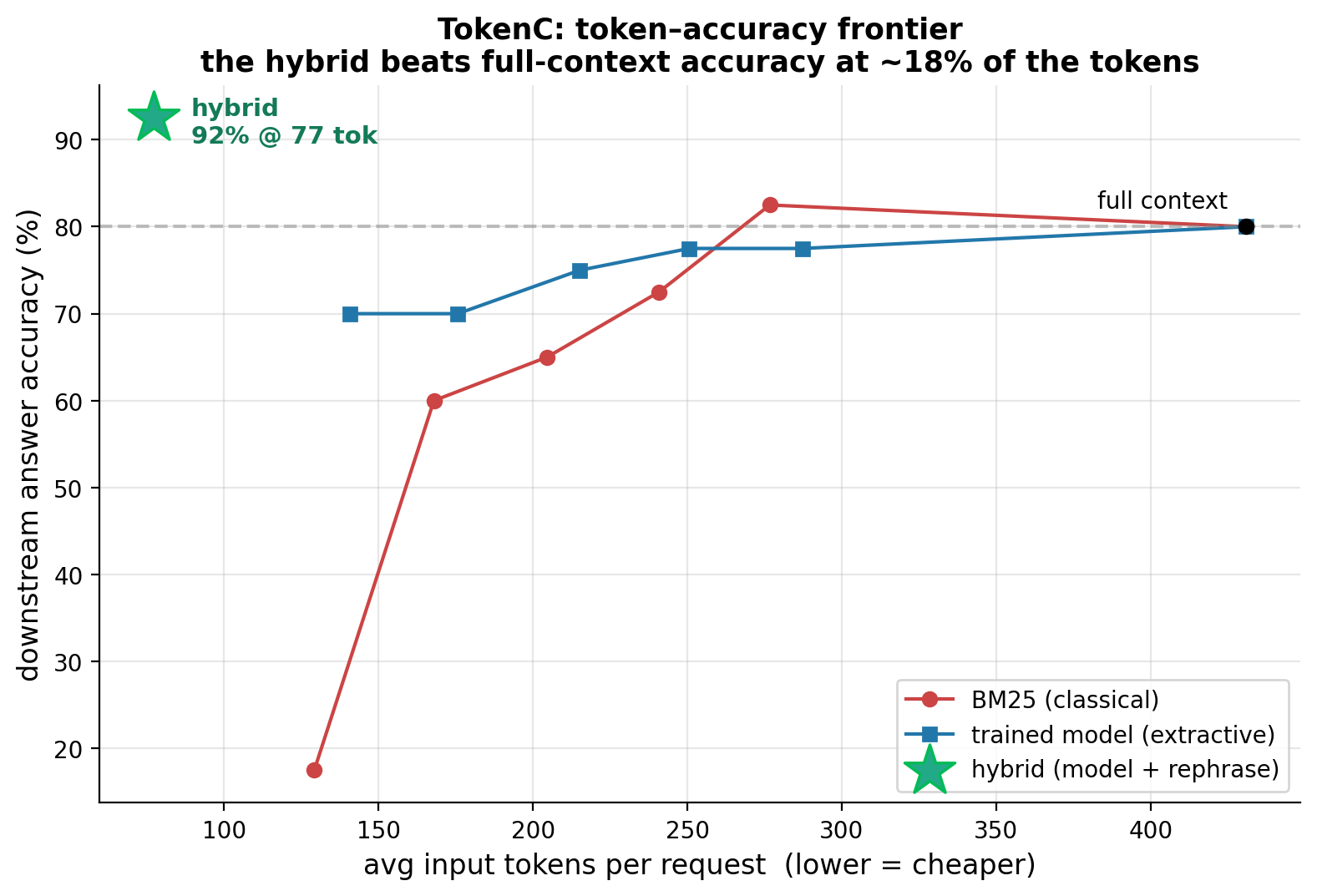
Graph of our results (green star is our model)
Inspiration
Most compression demos brag about cutting tokens and say nothing about whether the answer survived. Deleting tokens is easy; deleting the right ones is the problem. Right now, frontier LLM models seem to be the best at compressing inputs over classical models like TF-IDF or even lower scale transformer models. Since directly asking frontier LLM like Claude directly is too expensive, we fine tuned a smaller bidirectional encoder based model. Since you can't fine-tune Claude directly, we wanted to see if a small model could learn Claude's sense of what matters and run that compression locally, on every request, for free.
What it does Given a context and a question, a 66M-parameter model keeps only the sentences needed to answer, down to whatever token budget you set. It's wrapped in an eval that closes the loop (compress, ask Claude, grade the answer) and reports tokens, accuracy, and dollars against a classical baseline, so you see the trade-off instead of trusting it.
How we built it
We framed compression as per-token keep/drop classification instead of generative rewriting. Generation can mangle the exact tokens that matter and costs a decode per request; classification is one forward pass, can't hallucinate, and gives exact label alignment for distillation (no fuzzy-matching a teacher paraphrase back onto the source, which is the noisy step in LLMLingua-2's pipeline).
The backbone is a bidirectional encoder (DistilBERT), not a causal SLM like Qwen, because keeping a token depends on context on both sides of it, and a decoder only sees the left. The trainer is model-agnostic (AutoModelForTokenClassification), so the backbone is a one-line swap.
For labels, we show Claude the context as a numbered sentence list and ask which indices answer the query. That maps exactly to per-token labels and matches our inference granularity, so train and test agree. Input is Query: … Context: … with query tokens masked out, so relevance is learned conditioned on the question.
KEEP is only ~2% of tokens, so we don't threshold at 0.5; we use the model as a ranker (sort by keep-probability) and a separate budget controller fills to the target ratio. That same controller is shared by BM25 and the model, so the comparison changes one variable: the scorer.
Challenges we ran into
BM25 is far stronger than people give it credit for, and understanding why was most of the work. The rare entity name is an exact-match jackpot for a lexical scorer, so on plain retrieval it ties the model. To test semantic compression we built an adversarial slice: synonym queries the answer avoids, plus filler that echoes the query's keyword but carries no answer. Even then it didn't separate until we realized BM25 keeps the whole entity block as a unit, so the answer only gets dropped when the budget is smaller than that block. We tuned the benchmark into that regime. Separately, the class imbalance almost produced an all-DROP model, and our lost-in-the-middle chart came back flat (Haiku reads short contexts fine), so we cut it rather than ship a result that didn't hold.
Accomplishments that we're proud of
A model distilled from ~200 Claude-labeled examples that trains in about 10 seconds on a MacBook and produces a real, measured win: at 20% keep (~33% of the tokens) it holds 70% accuracy while BM25 falls to 18%, with full context at 80% and the same budget for both. We're nearly as proud of the restraint: every number comes from Anthropic's own token counter and real API usage, we report where the model only ties classical, and we deleted the chart that lied.
What we learned
Learned compression beats classical only in a specific regime: when relevance is semantic rather than lexical, and when the budget is tight enough to force a real choice. Being able to construct that case on purpose was as much of the work as the model. We also learned how cheap distilling a judgment can be, and that in compression the model is the easy half; proving the answer survived is the hard half, so build the eval first.
What's next for TokenC
A drop-in proxy: point your Anthropic base_url at TokenC and context gets compressed before it reaches the model, around half off your token bill with one line of config. After that, a stronger backbone and token-level keep/drop for finer control, real long-context benchmarks like HotpotQA and LongBench, and training on diverse multilingual text so it generalizes well past the demo.
Built With
- anthropic
- python



Log in or sign up for Devpost to join the conversation.