-
-

Landing Page, not logged in
-
Home page, login
-
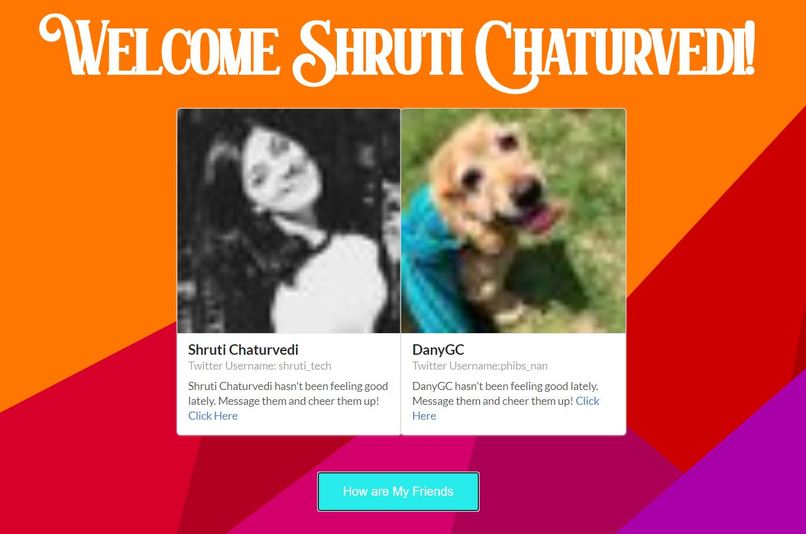
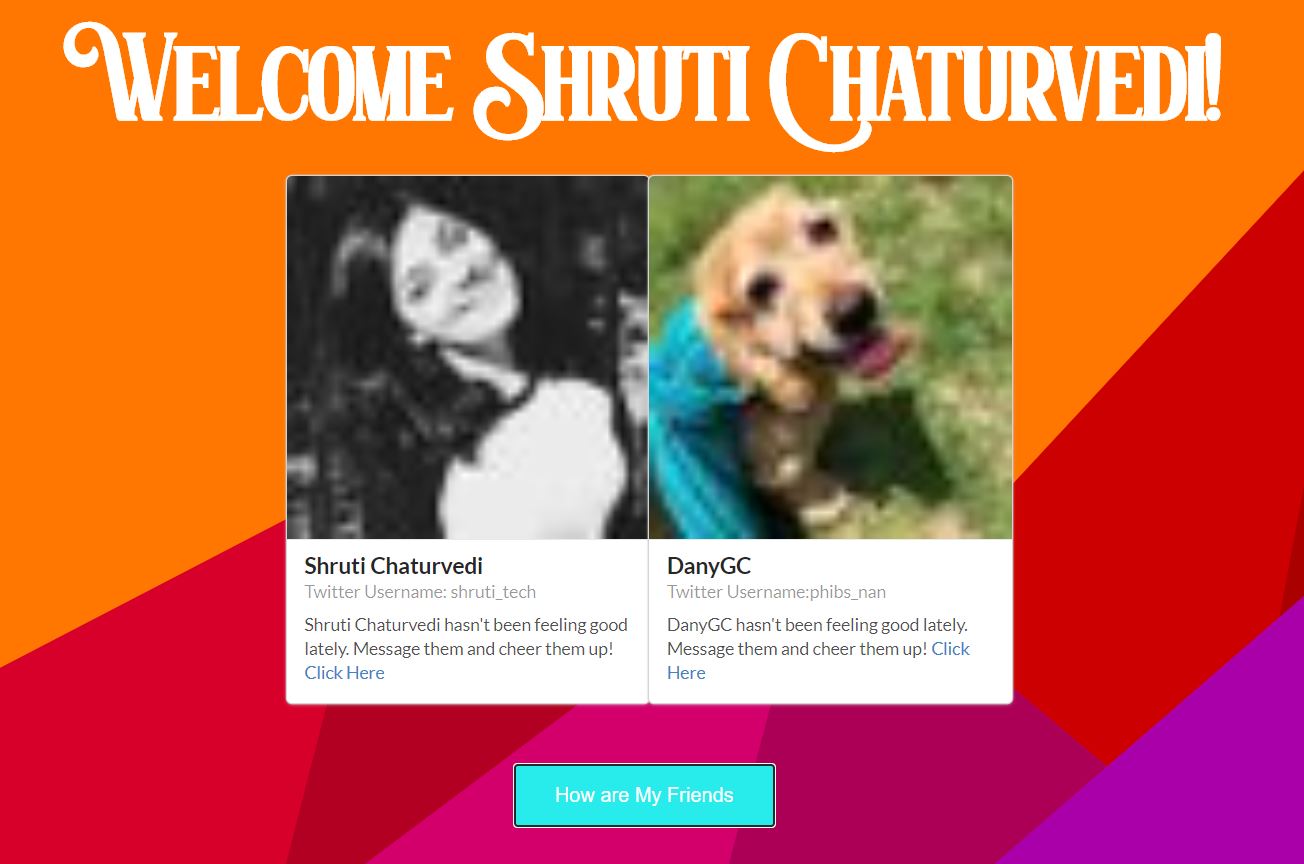
Check up the mental health of my friends
-
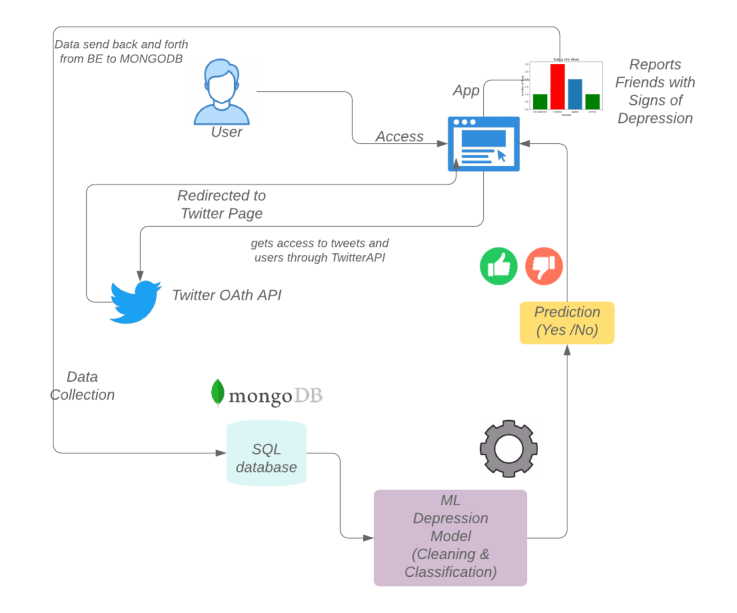
Flow Diagram
-
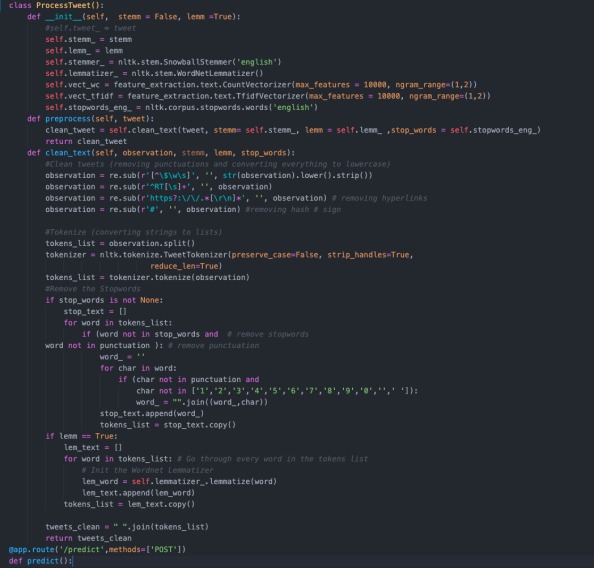
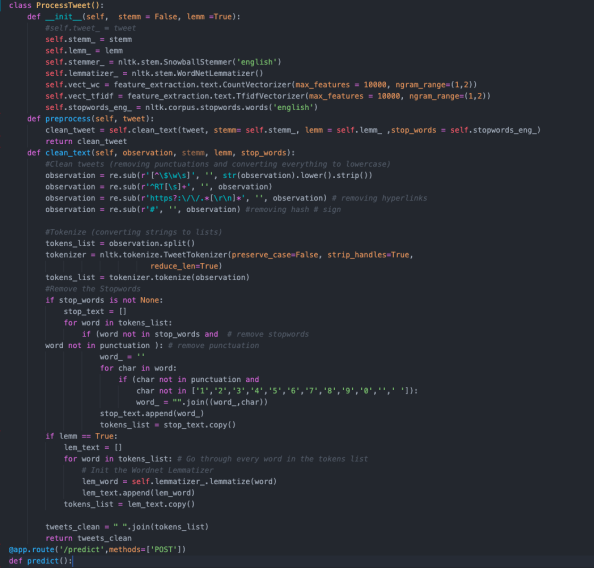
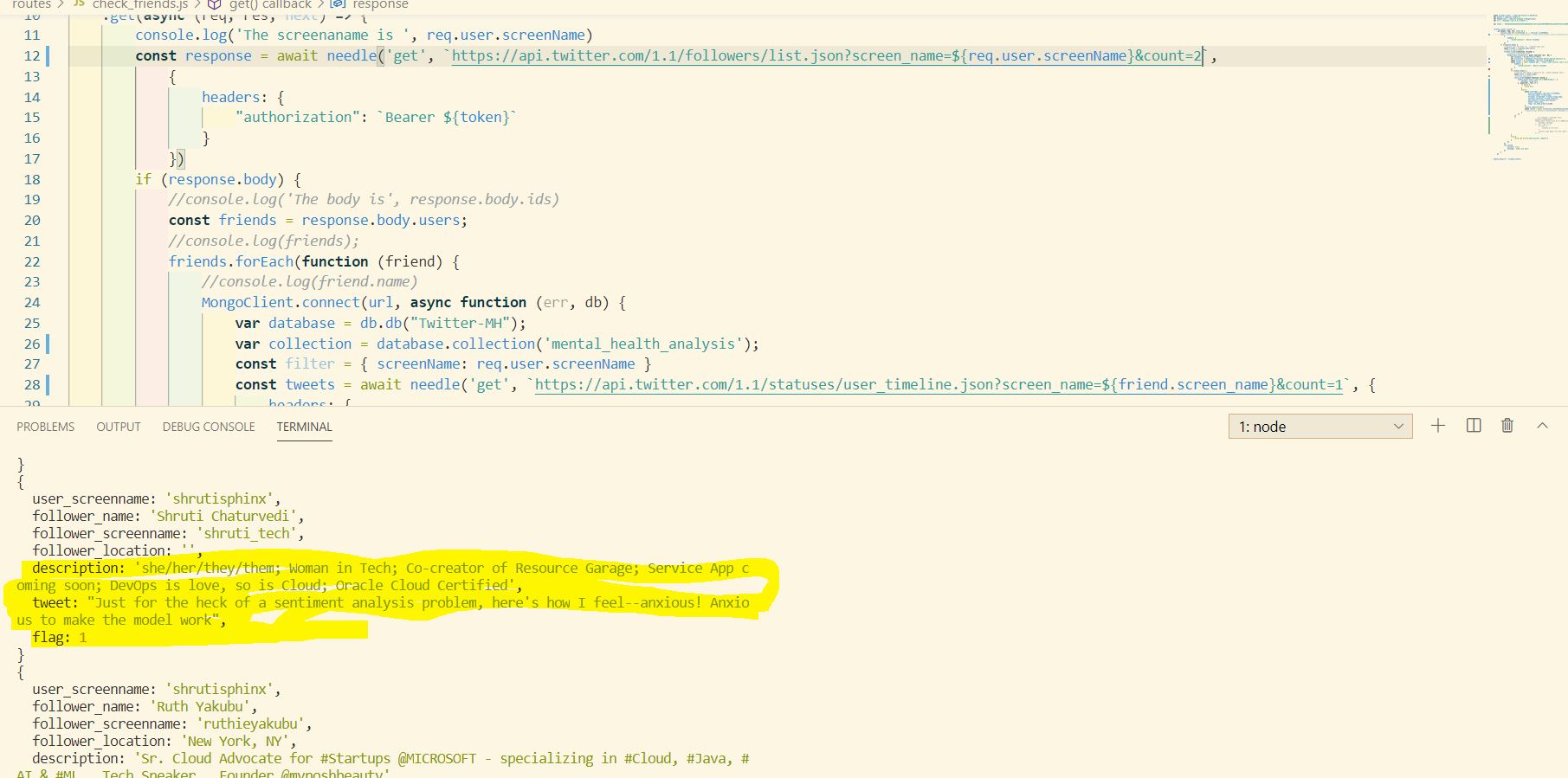
Process the tweets
-
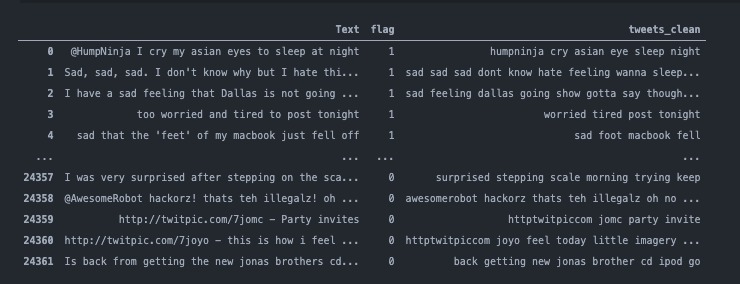
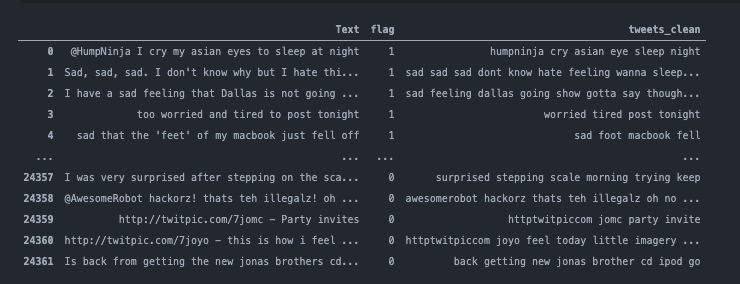
Processed tweets/text example
-
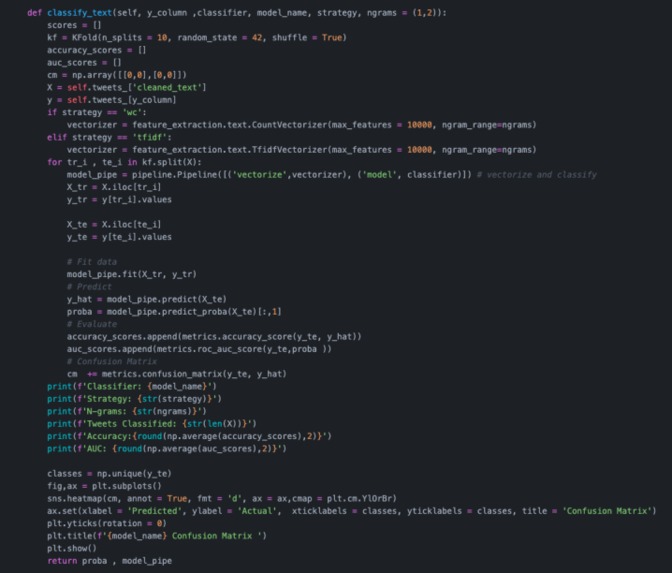
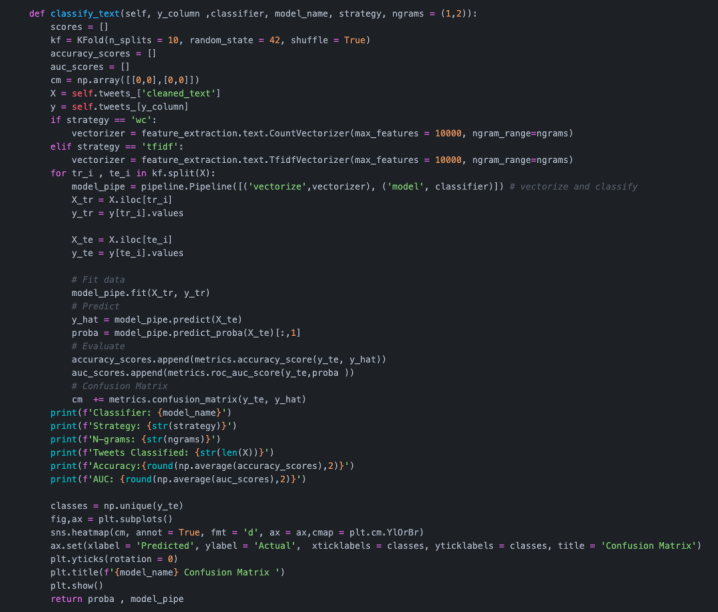
Classify the tweets and label them
-
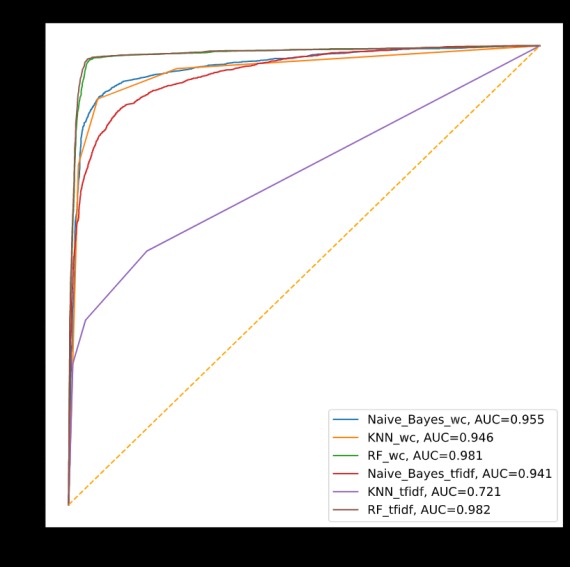
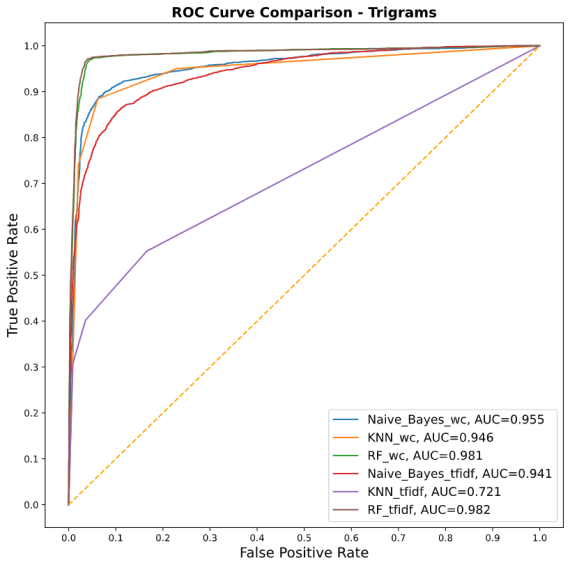
Comparison of different models used
-
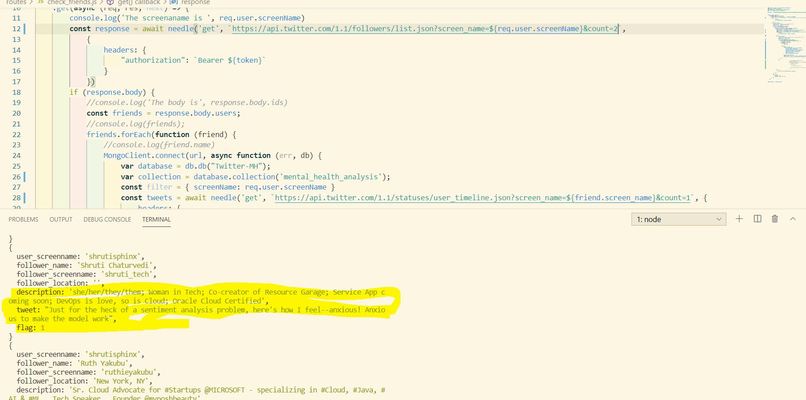
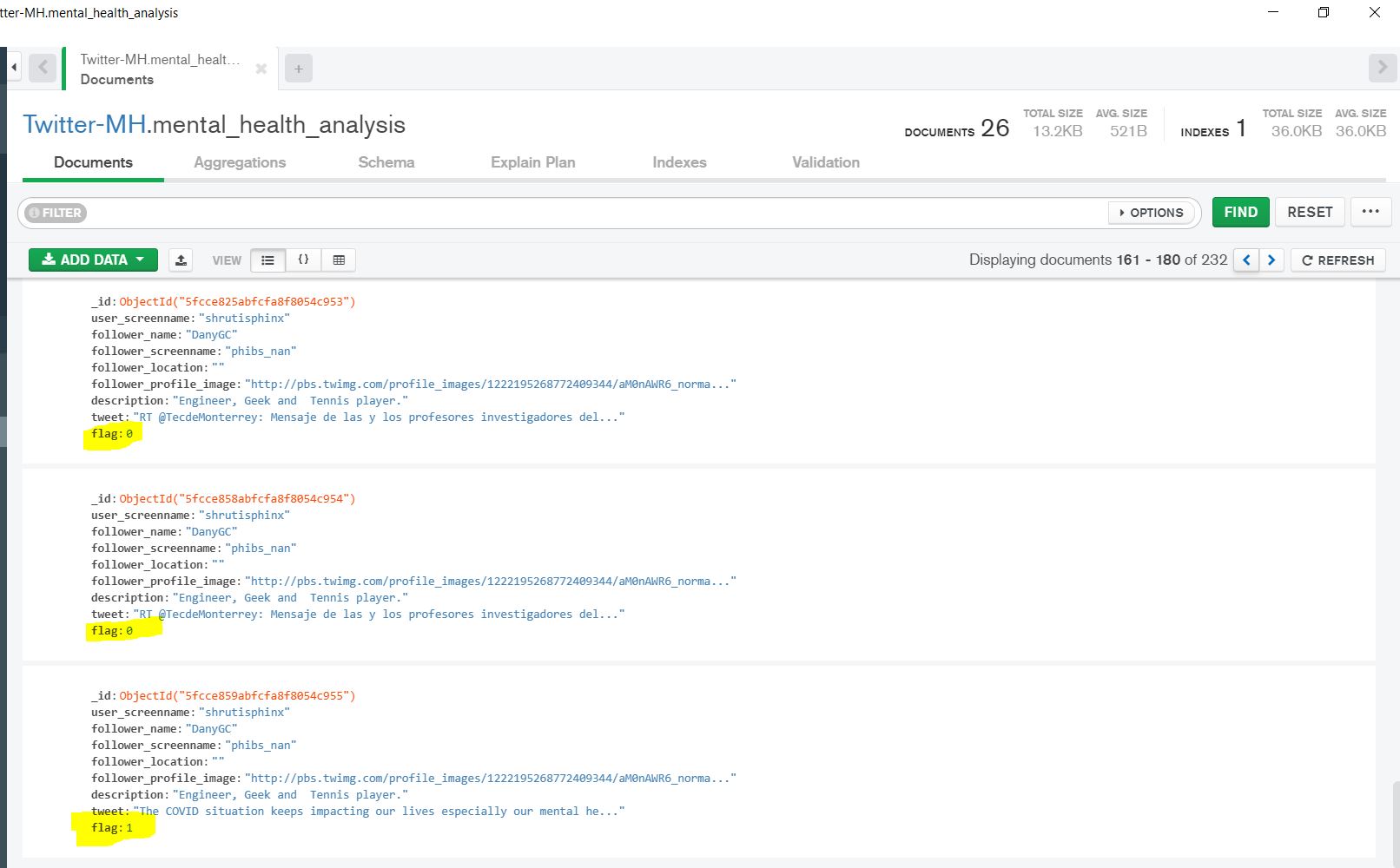
BE nodejs communication with mongodb
-
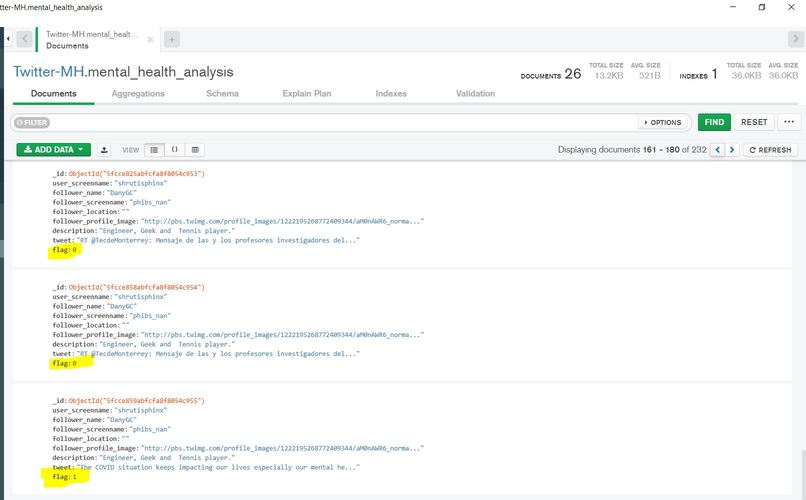
MongoDB docs
-

TogetherAlways


Inspiration
Depression is one of the most prevailing mental issues faced in the 21st century[1]. Moreover, according to the World Health Organization (WHO), depression may lead to suicide, which is the second leading cause of death for 15-29 year-olds [2]. We believe that while there have been multiple approaches to treat this problem, there is still a great opportunity for its prevention and early detection; an area where machine learning can support.
We designed the app TogetherAlways to alert people when their friends and loved ones are showing signs of depression. The system automatically flags the messages that have a relation with depression and sends a "Depression Alert" to those that are friends with the person who sends them. Our intention is for friends and family to keep sight of these episodes and support those in need.
[1] Barrera, A. Z., Torres, L. D., & Muñoz, R. F. (2007). Prevention of depression: the state of the science at the beginning of the 21st century. International Review of Psychiatry, 19(6), 655-670. [2] Suicide data. (2020). World Health Organization. https://www.who.int/teams/mental-health-and-substance-use/suicide-data [3] Leis, A., Ronzano, F., Mayer, M. A., Furlong, L. I., & Sanz, F. (2019). Detecting signs of depression in tweets in Spanish: behavioral and linguistic analysis. Journal of medical Internet research, 21(6), e14199.
What it does
The model reads tweets from friends on a daily basis and classifies whether each of the messages they are sending is related to depression. Whenever the model determines the text has to do with depression, it sends a flag, which is shown in the TogetherAlways App. Through running our model and our UI, we are enabling folks stay in the loop about mental health of their loved ones. People registered on the app will be able to track the mental-health activity and let them know if their circle needs them!
How we built it
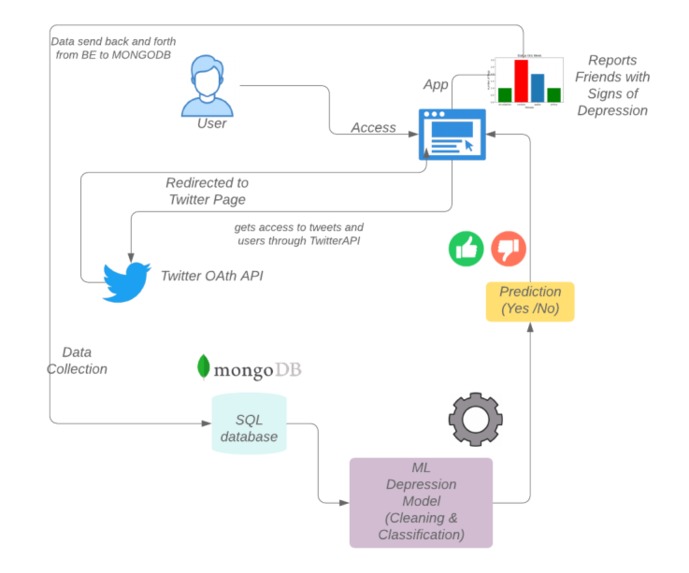
This app has 3 components: a _ frontend _ which the user interacts with, a _ backend _ which does all the authentication, fetching of data from Twitter and interaction with our third component -- _ NLP ML Model for classification of sentiment from a tweet. FE has a component a login screen, and a home page. When a user first accesses the app, they will be prompted to login. Login on this app is facilitated using OAuth1.1 to access entry into a user's Twitter profile. Currently, this app is allows login via Twitter only.
After loggin-in, client-side cookies are set up which gets sent to the server with every request, that is until the user logs out. Once the user is authenticated, they have the option to "Check-Up on their Friends". This is done through a button, and what this button does is use Twitter's APIs to extract information about a user's followers, and their most recent tweets. Once we have the tweets, we create a document on a MongoDB database.
A document looks like this: { follower_name: 'Shruti Chaturvedi', follower_screenname: 'shruti_tech', follower_location: '', follower_profile_image: 'http://pbs.twimg.com/profile_images/1328586762214584322/LmBAtdxx_normal.jpg', description: 'she/her/they/them; Woman in Tech; Co-creator of Resource Garage; Service App coming soon; DevOps is love, so is Cloud; Oracle Cloud Certified', tweet: "Just for the heck of a sentiment analysis problem, here's how I feel--anxious! Anxious to make the model work", flag: 1 } The one interesting field is flag. What is this field about? flag represents the mental health of a tweet; if the flag tag is 0, it means that a tweet by a person did not have signs of anxiety or depression. However, if the value of this field is 1, it means that some level of anxiety, sadness, or depression was detected. This classification is done by training an NLP model using ScikitLearn.
The model gets trained using a dateset which has labelled tweets as depressive or non-depressive using some common keywords. The classification is done using a RandomForestClassifier algo whcih provided the best result out of other algos used. Once the model is trained, it is built into a pipeline which goes through breaking the tweet apart, and feeding it into our classification model. The pipeline is then deployed using a Flask server.
After we have information about a user's friends, and classify their tweets using our pipeline, we parse through documents in our mongodb to search for any field which has a flag of 1.
Once we find this document from mongodb, we send it back to our front-end. The state of our FE gets populated with info about a user's friends. As the state gets updated, we render a component to display friends who have been feeling down lately. Any user can access it on their homepage, and can send them a heartwarming message! #TogetherAlways. (They also have the option to logout if they want!)
Challenges we ran into
The first challenged that we ran into during this project was collecting a great number of tweets so that our model could be well-trained and get a good accuracy when predicting. We approached this by researching various previous datasets and found a collection of tweets ( 1,600,000 tweets) that were obtained from the Tweeter API and stored in https://www.kaggle.com/kazanova/sentiment140.
Next, we had to label these tweets as whether this had a relation to depression or not. For this, we researched physiological papers and found that Ferran et al. [3] had already determined a list of negative words that are present in depression messages; some of the words are the following: overwhelmed, exhausted, distressed, anxiety, anxious, tired, low, sad, cry, nervous, empty, worried, insomnia, demotivated, lonely, desperate. These words were used to label the 1,600,000 tweets collected and found that 12,181 tweets had a link with depression.
Another challenge was the async communication between our front-end to our back-end to our model. Deploying the model was hard because we were getting a cursor back from our model, and we had to find a way for our model to send data back to our back-end.
Accomplishments that we're proud of
We are extremely proud of building a functional component which works end-to-end. There were so many parts which were tricky, however we did it. OAuth using Twitter, designing a NLP classification model, deploying our model, communication between front-end, back-end and our model. We did it all!
What we learned
We learned how OAuth1.1 can be setup with Twitter. After that, we had quite some work around sending data back to the user in form of cookies which would be sent to the server with every request.
We have learned the process of collecting, preprocessing, modeling, and deploying a complete machine learning project for social good, and we have done so by building a robust pipeline.
We learned a lot about communications between the front-end, taking the request back to the back-end and how it interacts with our model. How would data coming in from the database be sent to the pipeline on Flask and how would the pipeline send us the data back was something interesting we learned.
What's next for TogetherAlways
Connect other social-media platform.
Perfect the Model: We want to test other machine learning algorithms such as One-Class Classifiers to find anomalies from the messages and test Reinforcement Learning in an approach to obtain better results when classifying.
Other Products: We also want to make this app a parental control extension that can be downloaded to android and IOS and that can help parents monitor the mental health of their children by being flagged when depression messages are written by them.
Mental health is extremely precious, and we want to make sure that people who are having mental health crisis are able to stay connected with people. People often feel shy and powerless to reach out for help; through this we want people to have the ability to look for signs of depression and help their friends.




{kind=link}
Log in or sign up for Devpost to join the conversation.