-

MedTheia - A picture is worth a thousand words
-

Background Information on Electronic Medical Record - Time consuming and prone to misunderstandings
-
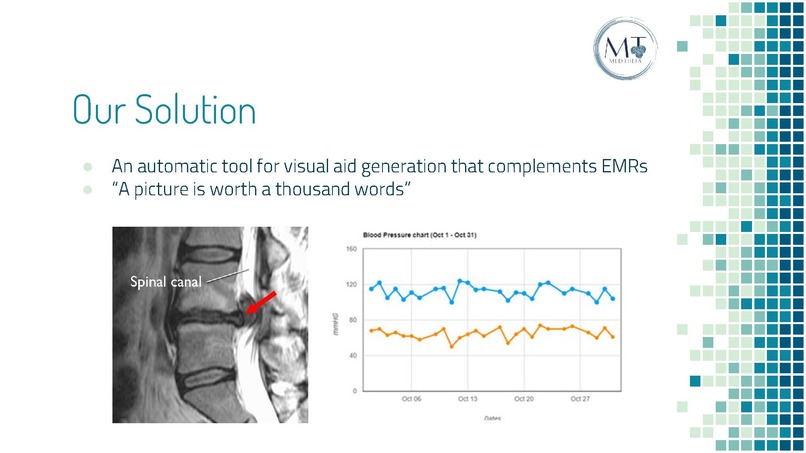
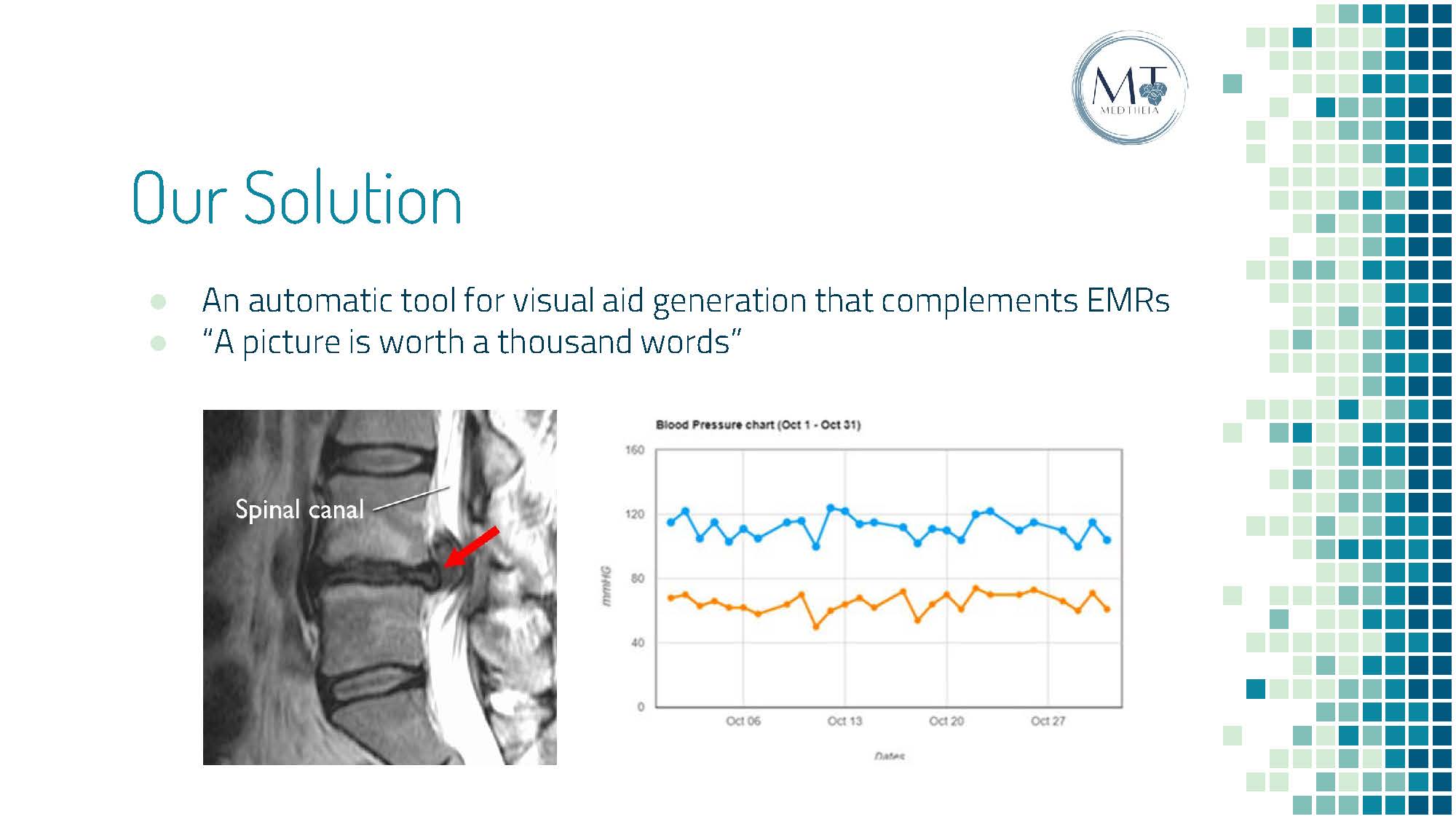
Our Proposed Solution
-
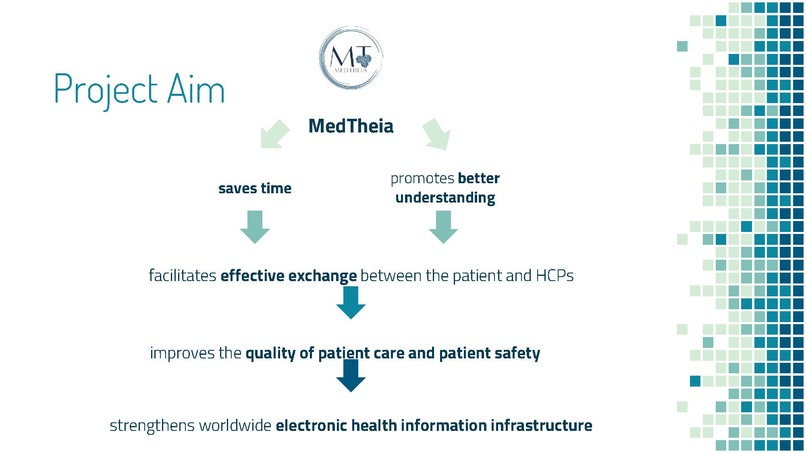
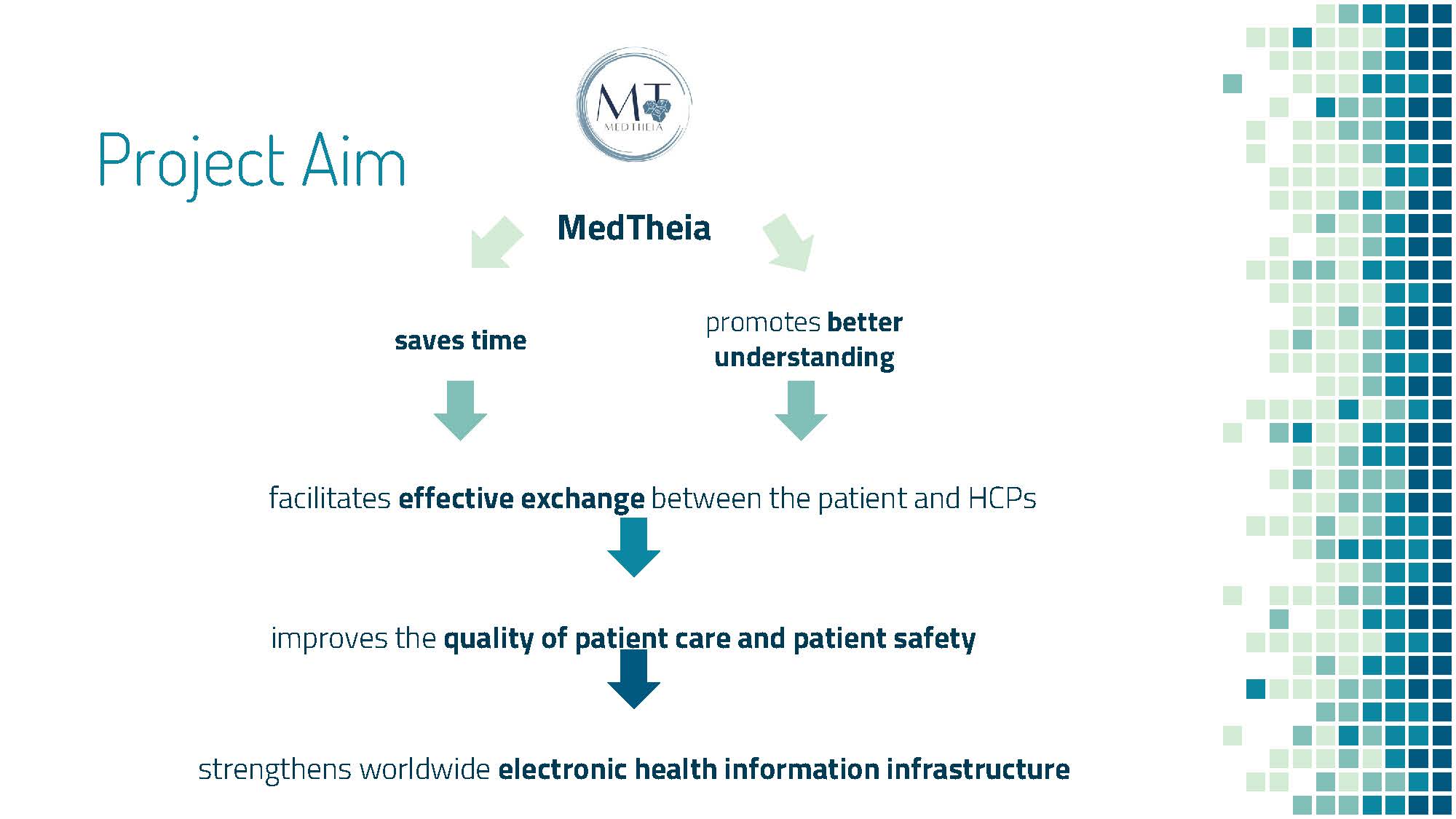
Project Impact and Relevance
-
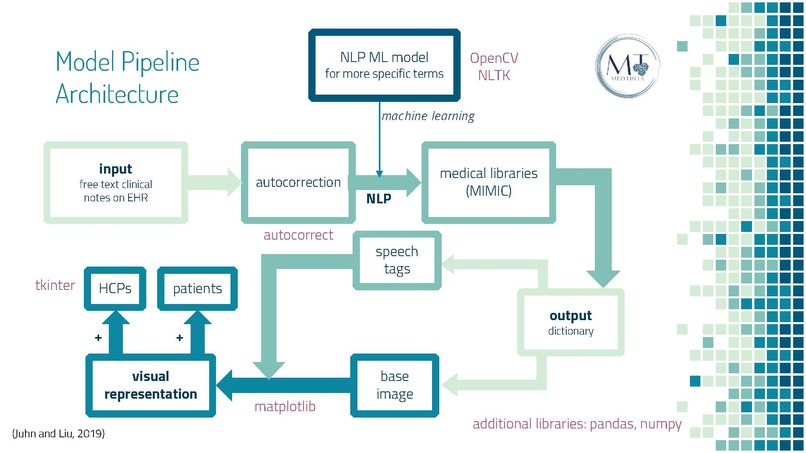
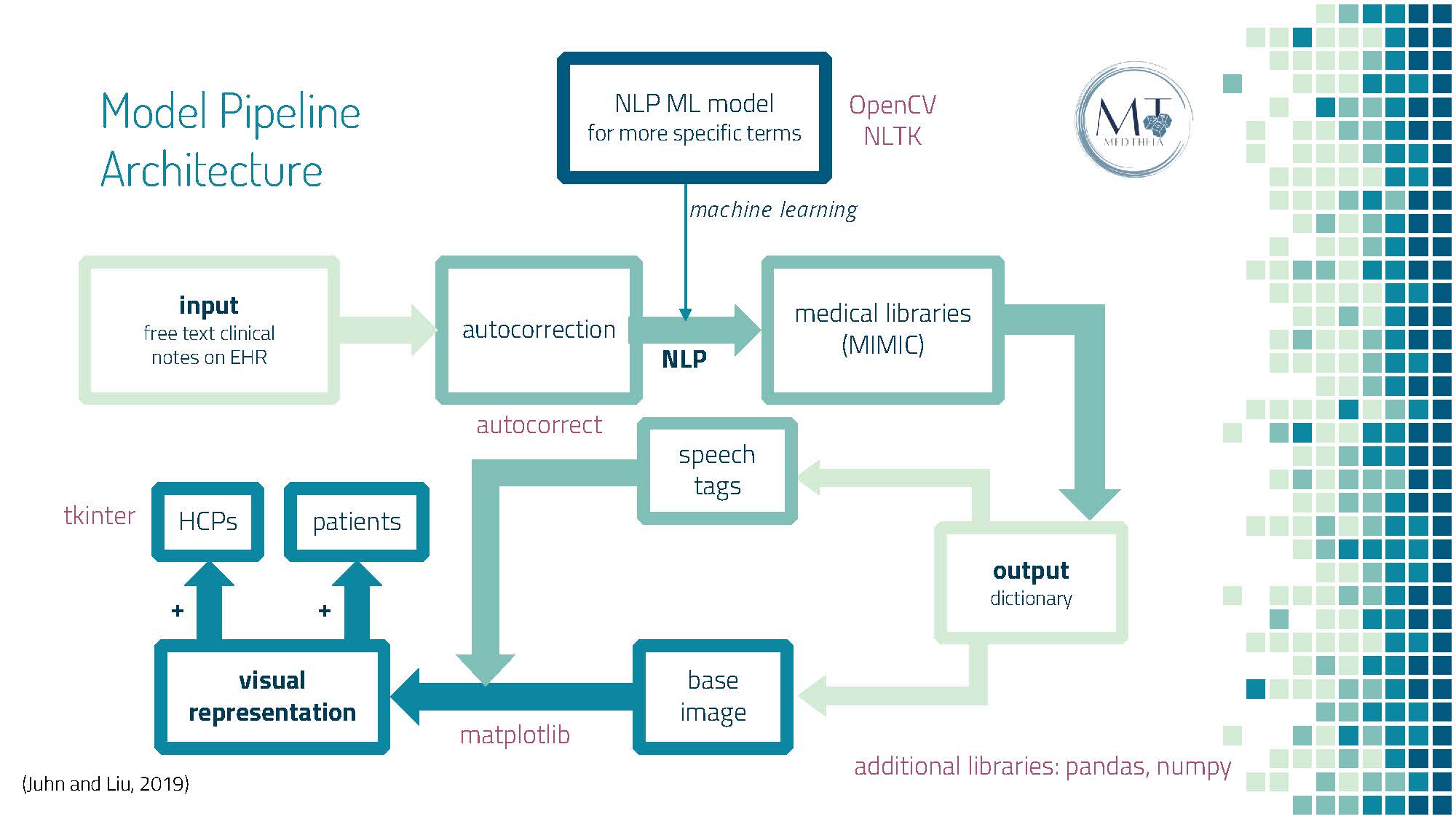
Model Pipeline Architecture
-
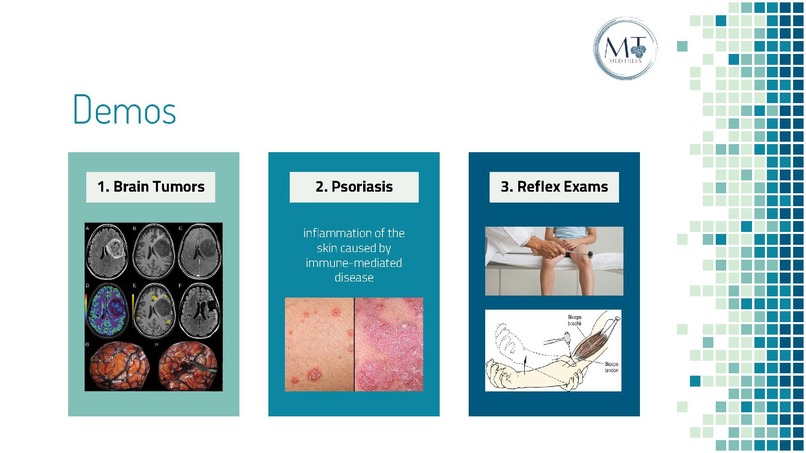
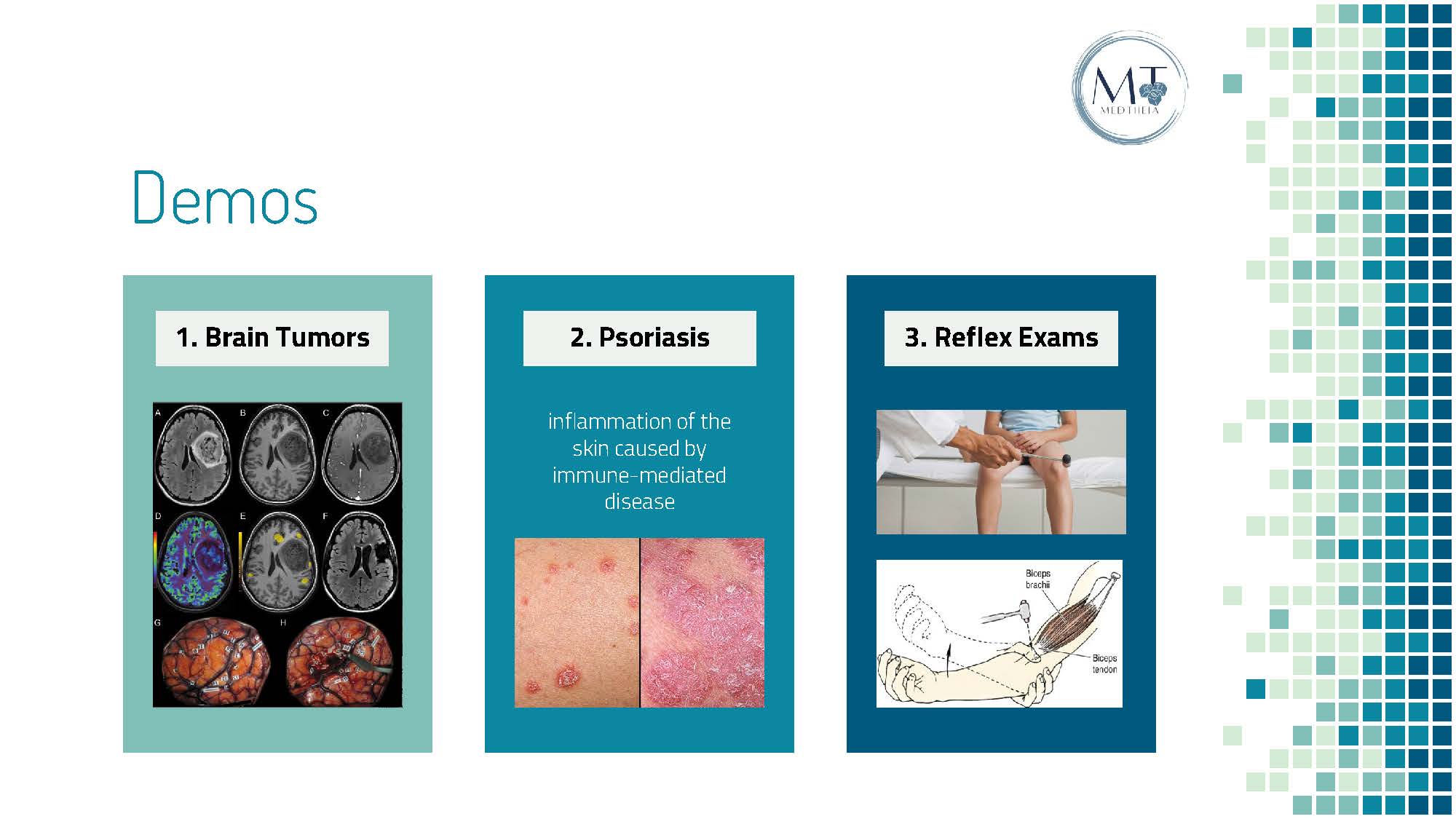
Proof of Concept Demos Overview - MedTheia can be very versatile in types of images generated
-
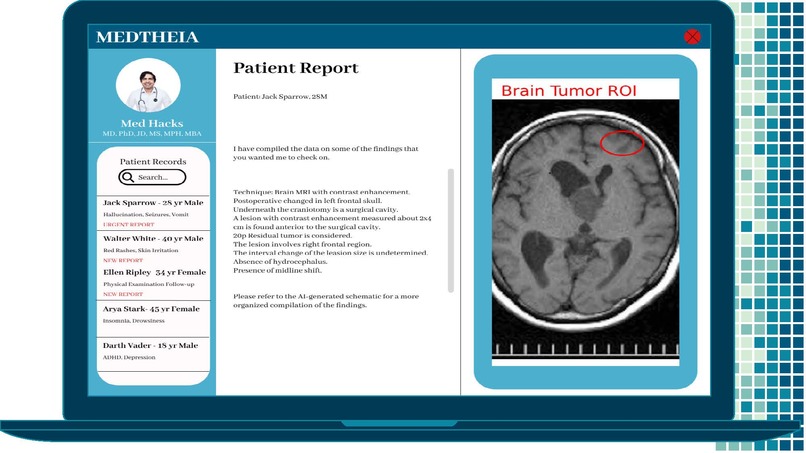
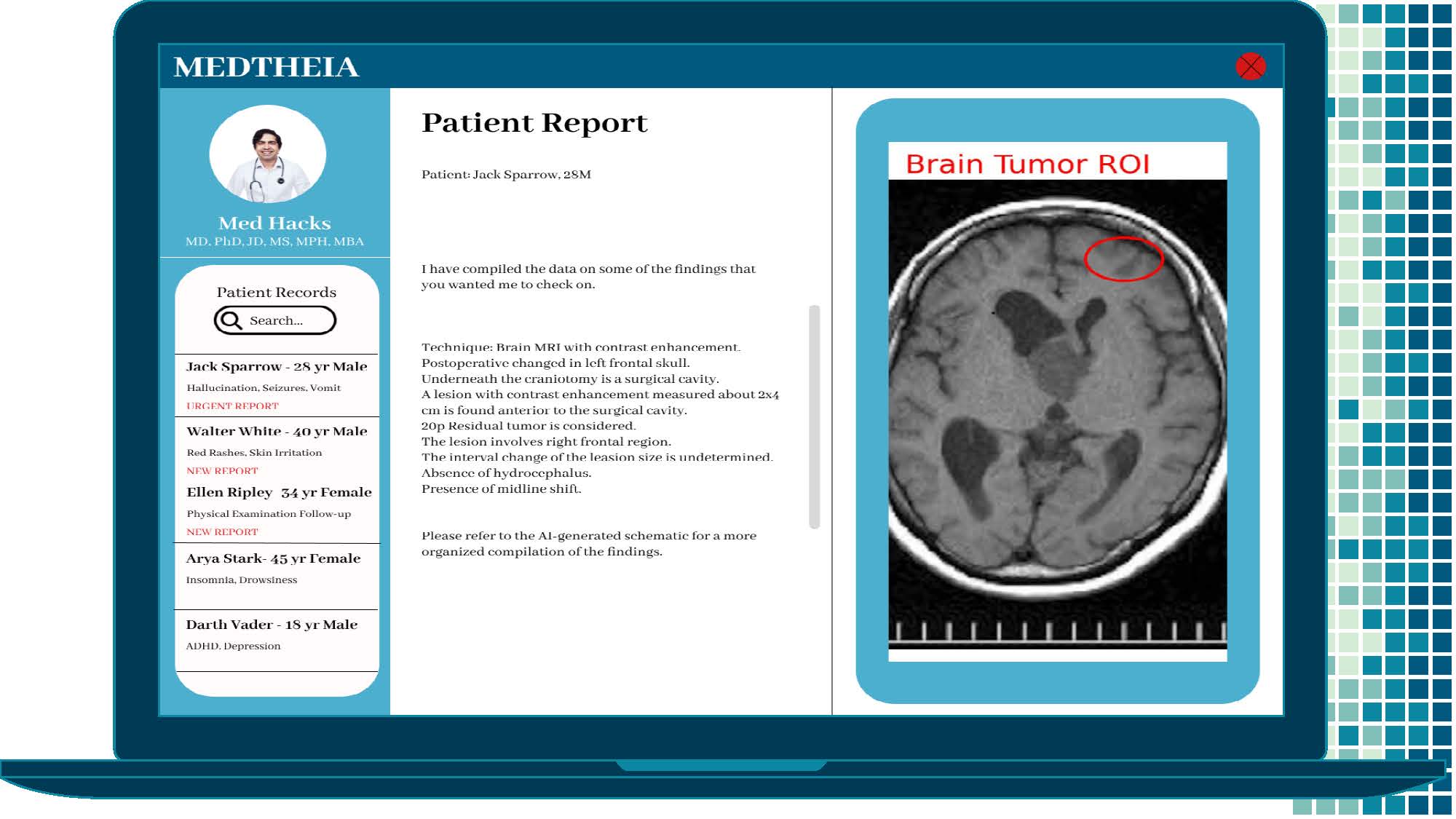
Mock UI Example 1 - Brain tumor region of interest and approximate size
-
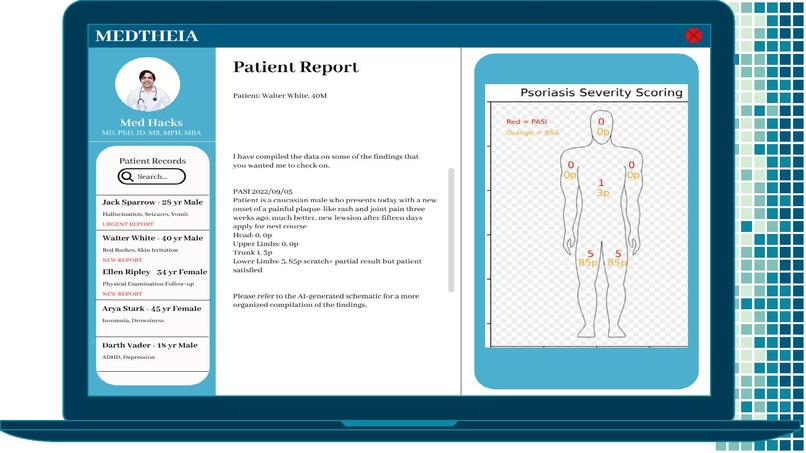
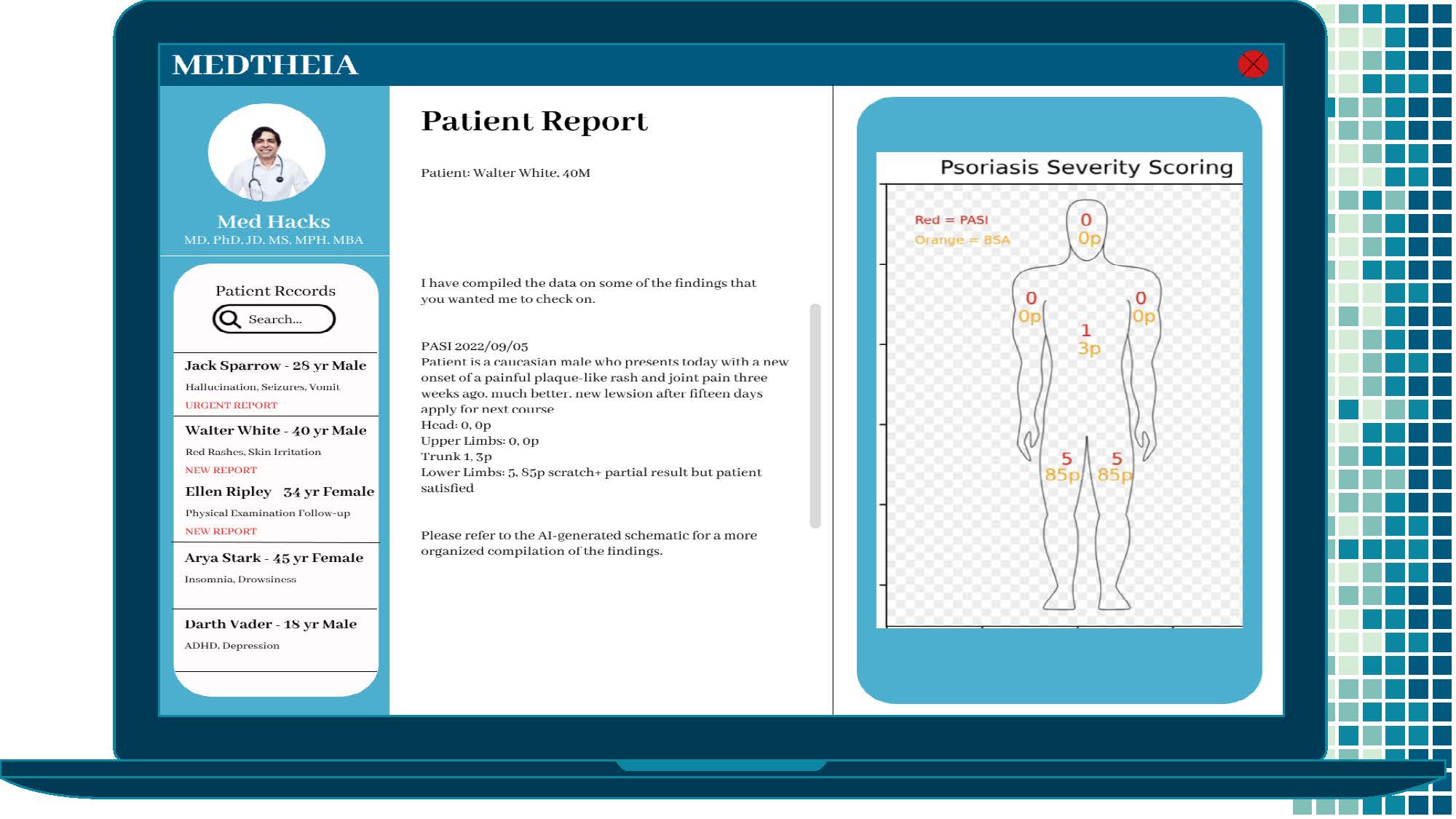
Mock UI Example 2 - Psoriasis Area and Severity Test
-
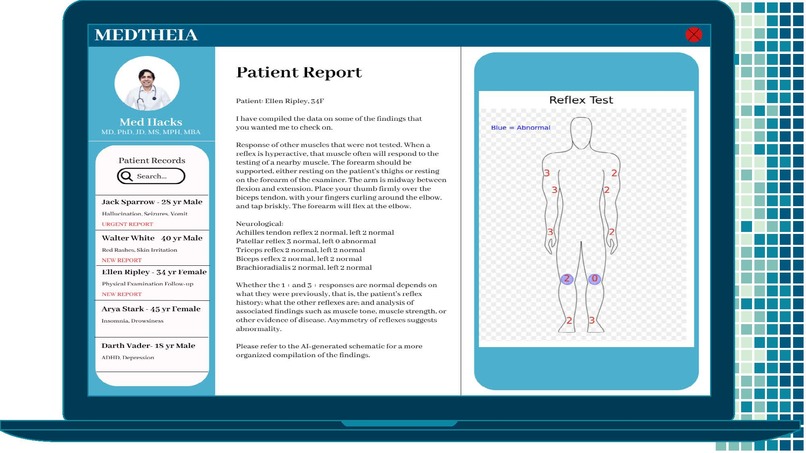
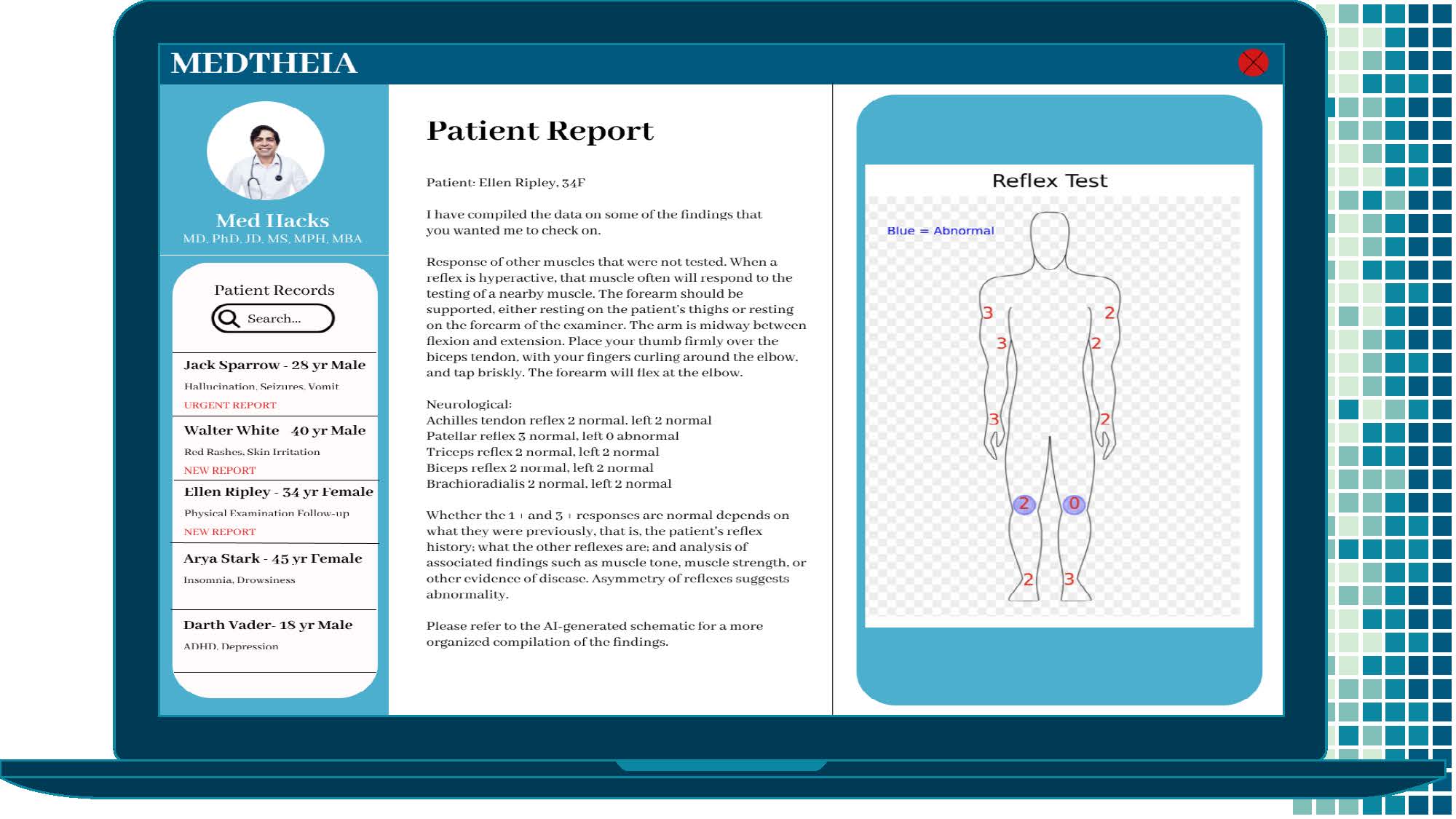
Mock UI Example 3 - Deep tendon reflex test results with abnormalities indicated
-
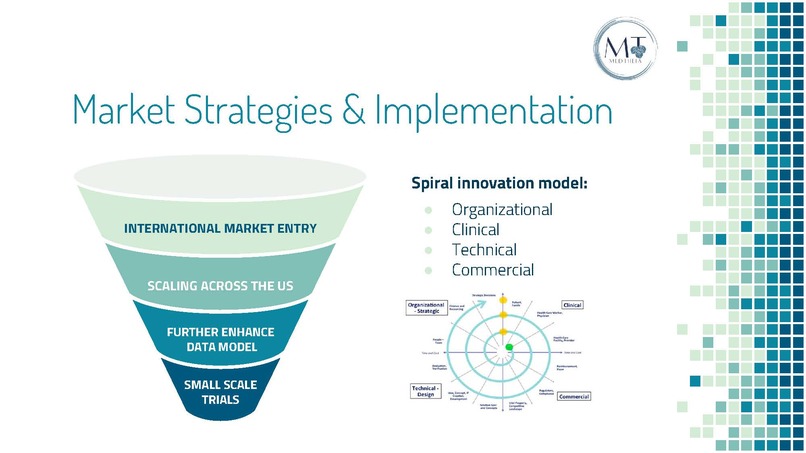
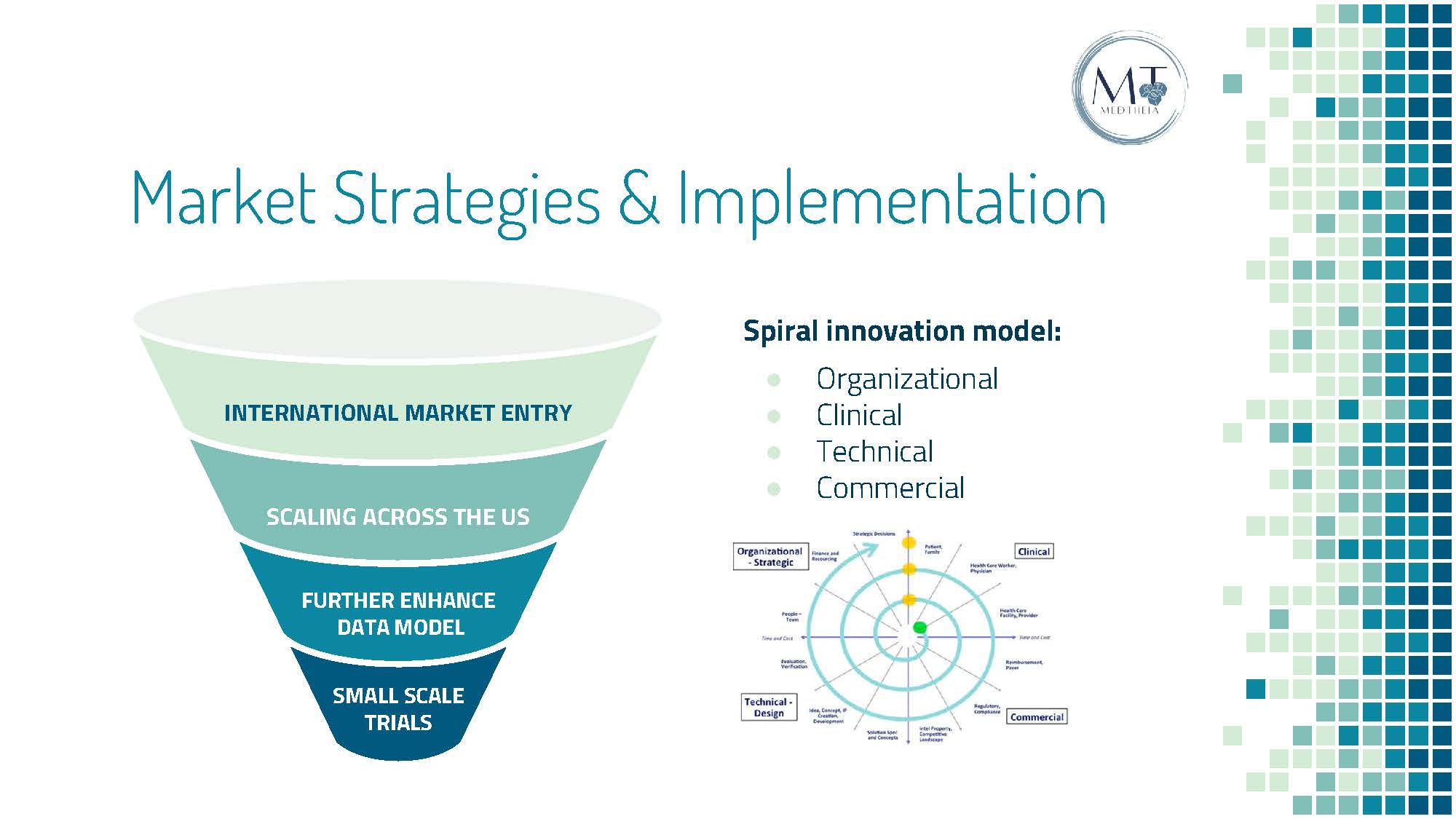
Marketization
-

Hard at work
-

Team Toefu!
-

Winners!





Github link: https://github.com/benchang323/MedHacks
Inspiration
Hospitals predominantly use electronic medical records (EMRs) to document information collected by healthcare providers (HCPs) for diagnosis and treatment. EMRs are more valuable than paper records because they enable HCPs to monitor patients over time, save and retrieve data efficiently, and identify patients for preventive visits and screenings, thus improving the quality of healthcare.
However, from literature review and consulting medical professionals, we learned that EMRs can be difficult to understand due to dense technical vocabulary, tedious length, and unfriendly user interface. This hinders individual understanding as well as communication between HCPs and patients. With ineffective communication, negative repercussions such as HCP burnout and lack of patient understanding can arise. Reading EMRs can also be very time-consuming: a recent study has suggested that physicians spend on average 4.5 hours per day interacting with EMRs, time that could be spent promoting better patient care and safety.
Inspired by this persisting yet overlooked problem, we began to brainstorm potential solutions to resolve this issue. So, what is better than words? Images! Through transforming tedious, but important, medical statements, into clear, engaging visuals, the efficiency of communication between different parties can be significantly improved.
What it does
Intelligent Text to Visual. The first part of our machine learning model is based on Natural Language Processing (NLP). Our model will first be trained with sufficient EMR free text to take, analyze, and extract essential information from medical statements. We then tokenize and tag these statements with NLP speech tags. Based on the information extracted, redundancies and stop-phrases are omitted. A lexical dispersion plot is employed to solidify the characteristics for visualization while the base layer image is mined from the medical imaging database. The model then stacks the appropriate characteristics based on trained results onto the base layer, generating the final image. All these processes are performed via a built-in extension and will allow for automatic and easy visualization of critical clinical information.
How we built it
Proof of Concept. We first ran an EMR dataset through the autocorrect library to authenticate data accuracy, thereby preventing medical transcribing errors through lexical correction. The nlkt library was used to tokenize and tag medical statements from three categories – brain tumor regions of interest, psoriasis severity tests, and tendon reflex exams – based on each word's part of speech. Redundant textual tokens and stop-phrases were then filtered before identifying medical terms of interest for imaging visualization. Using the normalized data, our image generation code, looped through our characteristic-identifying algorithm, was able to gather an appropriate base image for the matplotlib library to layer desired schematics based on processed EMR information. The final visualization product is transmitted to the user-end based on the tkinter toolkit.
Challenges we ran into
Identifying a problem in the healthcare industry that is of important need and conceptualizing a solution that is feasible: We spent our first night solely formulating our guiding question because we were constantly examining the originality and validity of our numerous proposals. In the end, we decided to focus on the communication and understanding of medical information. We believe our focus area is fundamental to reducing medical errors by allowing patients and physicians to better understand the interpretations of jargon-filled reports outside their specialty and thus improving the quality of care.
Addressing the possibility of transcribing errors: During our development process, several data cases derived transcribing errors interrupting the execution of the program. We imported the autocorrect library in python to prevent program-processing errors and the accuracy of our NLP code.
Troubleshooting: There were countless occasions when we had to debug the code, especially for layered lists, in order to identify errors. We also had to learn the implementation of many new programming libraries and concepts to achieve the desired advanced effects for our goal.
Limited access to datasets due to HIPAA and Privacy Concerns: The machine learning model and lexical dispersion plot were unable to be fully implemented due to our limited access to clinical databases that weren't de-identified. We aim to establish collaboration with physicians and medical institutes in the future to gain more access to EMR datasets and improve the accuracy of our programs.
Accomplishments that we're proud of
Firstly, we are proud of brainstorming and applying an innovative way of representing words by visuals to revolutionize communication between doctors, nurses, and patients. We're excited about the impact it would bring to help any medical entity to better understand fields outside their specialization, facilitating an effective communication channel that improves patient safety and medical outcomes. Lastly, we are proud of being able to create three working sample models (brain tumor, psoriasis, and tendon reflex exams) in short a short time to prove the viability of our idea.
P.S. And not to mention our project name, MedTheia, which is derived from Theia, the Greek goddess of sight and vision :)
What we learned
By researching and talking to professionals in the healthcare industry (consulted two well-respected doctors: a radiologist and a dermatologist), we have gained a better understanding of the mechanisms and problems within our current healthcare system, specifically on EMRs and their relation with patient safety. The program development cycle also deepened our understanding of natural language processing, lexical machine learning programs, and many data science python libraries to simplify clinical statements. Most importantly, we experienced the ins and outs of hackathons, broadened our understanding of the medical world, and learned to better collaborate and bond with each other as TOEFU members!
What's next for MedTheia
- Acquire (clinical) consent for accessing EMR datasets, which will be used to train our machine learning EMR visualization program.
- Integrate our code into the EMR system as an extension, allowing generated visuals to be presented with medical comments on top of plain text.
- Test the MedTheia program with a selective number of hospitals, observing the efficiency and impact of the program while troubleshooting any difficulties.
- Make improvements to our program until statistically significant and impactful promising results are yielded.
- Expand our program to all available hospitals that use the EMR system.
Built With
- figma
- github
- jupyter
- natural-language-processing
- python











Log in or sign up for Devpost to join the conversation.