


Our Inspiration
TLDR: Coronavirus was inspired by the mass hysteria and fear we feel at the rapid spread of COVID-19 in our daily lives. Whether it is the various news media sprouting unverified numbers, leading to a fear frenzy of rumors, or the numerous news sources we need to check to stay updated on the local and global level, staying updated is slowed down by the different levels of news sources we have to keep track of.
Keeping track of different reporting levels is important because information about updated coronavirus counts takes time to propagate up to state, national, and global levels. The CDC itself reported that it no longer claims to have the most up-to-date coronavirus numbers because states are doing individual testing and reporting. In the same vein, official state websites update their coronavirus counts by relying on individual county and city updates. It is crucial to keep track of local updates since they are the most fresh, but this creates more user overhead to search multiple websites.
Enter TLDR: Coronavirus, which allows users to track all of these customized locations from official verified sources, helping people keep track of the health security for themselves and their loved ones, all in one place. We especially honed in on local locations & college campuses since we ourselves have experienced how easily rumors can spread. Universities in particular may be the next outbreak hot spot, especially after travels during Spring Break. TLDR: Coronavirus can help keep everyone in our communities informed.
What it does
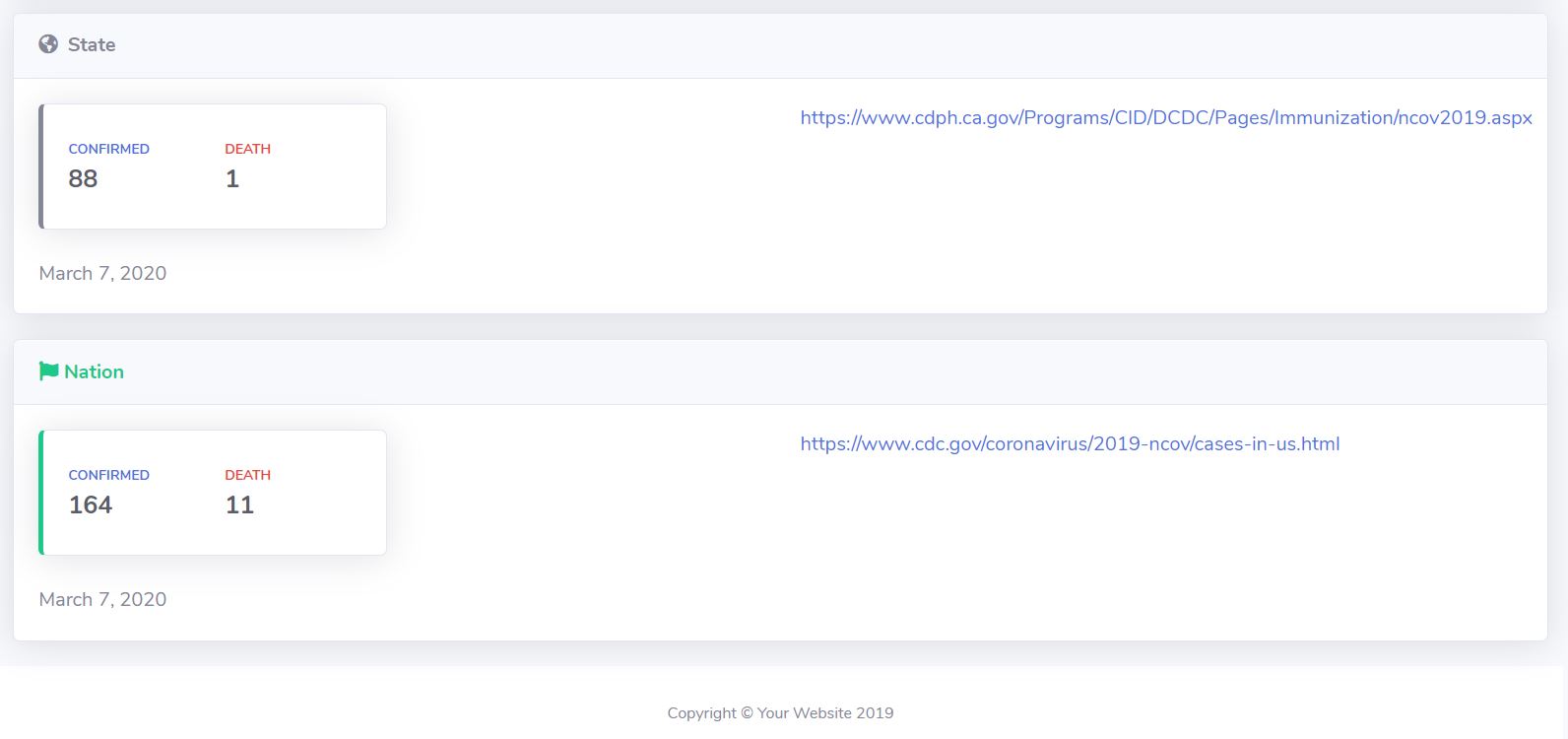
• On the website, users can highlight locations they want to generate and track by using our left filter bar (which breaks down to Institutions, Regional, National, and Global.)
• TLDR provides the bare essentials of what we are looking for from news updates in one spot: confirmed cases, deaths, as well as the latest status update. The site also provides a link to the latest article from which the data was scraped so you can read more.
How we built it
To create TLDR: Coronavirus, we used IDEs VScode/Sublime Text/Pycharm and customized HTML/CSS & Javascript to implement the app’s user interface (UI) and front end development. To collect our desired data from primary news sources, we scraped a set of official press release sources using Python’s library BeautifulSoup. We used natural language processing techniques with regex to parse desired data including the number of confirmed cases, deaths, and date for each site. To communicate between the front end and the back end, we used Flask and passed data through a json. Lastly, designed a logo using Adobe Illustrator.
Challenges we ran into
This was half of the team’s first hackathon and the whole team’s first dive into front end development (with Javascript and Flask) and web-scraping. We wanted to scrape Twitter’s API for bite-sized news but the authentication tokens and such proved more of a hassle than was worth the time we spent into it. Web scraping using text pattern matching also proved to be challenging, because of the variety of ways in which articles were written. Much of our time was spent trying to first understand how to proceed before we even started implementing. Making sure the communication of our front-end with our backend ran smoothly was especially hard! Mentors helped a lot!
Accomplishments that we're proud of
We are happy that we were able to design an application that can help everyone stay informed while also saving people’s time and data usage. We were very proud to be able to improve our knowledge about web application development (both front end & backend) and learning about APIs, web scraping with Python, and especially consolidating everyone’s work at the end. Getting over the front-end to backend communication hurdle and ensuring smooth flow of data is something we are very proud of. Ultimately working collaboratively with new people with different skill sets was both challenging and rewarding (and just goes to show rival schools can get along! [GO FIGHT ON TROJANS AND BRUINS] )
What we learned
We learned that website development takes a lot of time and a lot of collaboration. We had to learn to leverage each other’s different skill sets by dividing work efficiently and learn about all the many different components that result in a finished, workable product! It was a huge learning curve, but super rewarding!
What's next for TLDR: Coronavirus
Currently, our demo gives users a default landing page with customized locations checked for them (currently AthenaHack’s location, for convenience’s sake). We did not have time to implement more locations, but as we want to expand to help keep people as informed as possible we want to add much more.
We want to implement more visualization functionalities to our website. As we aim to be a source where you can find out all you need to know in one go, we think adding live heat maps or charts would be helpful to visitors. We'd like to have web scraping that can handle a larger diversity of websites and more generalized pattern matching. A “generate feed” button could update the page with all the new checked locations you want. Live notifications for our site could send text notifications for news update on user’s tracked locations.








Log in or sign up for Devpost to join the conversation.