TL;DR — Smart Highlights
Streaming TL;DR + provenance-linked highlights for forum threads
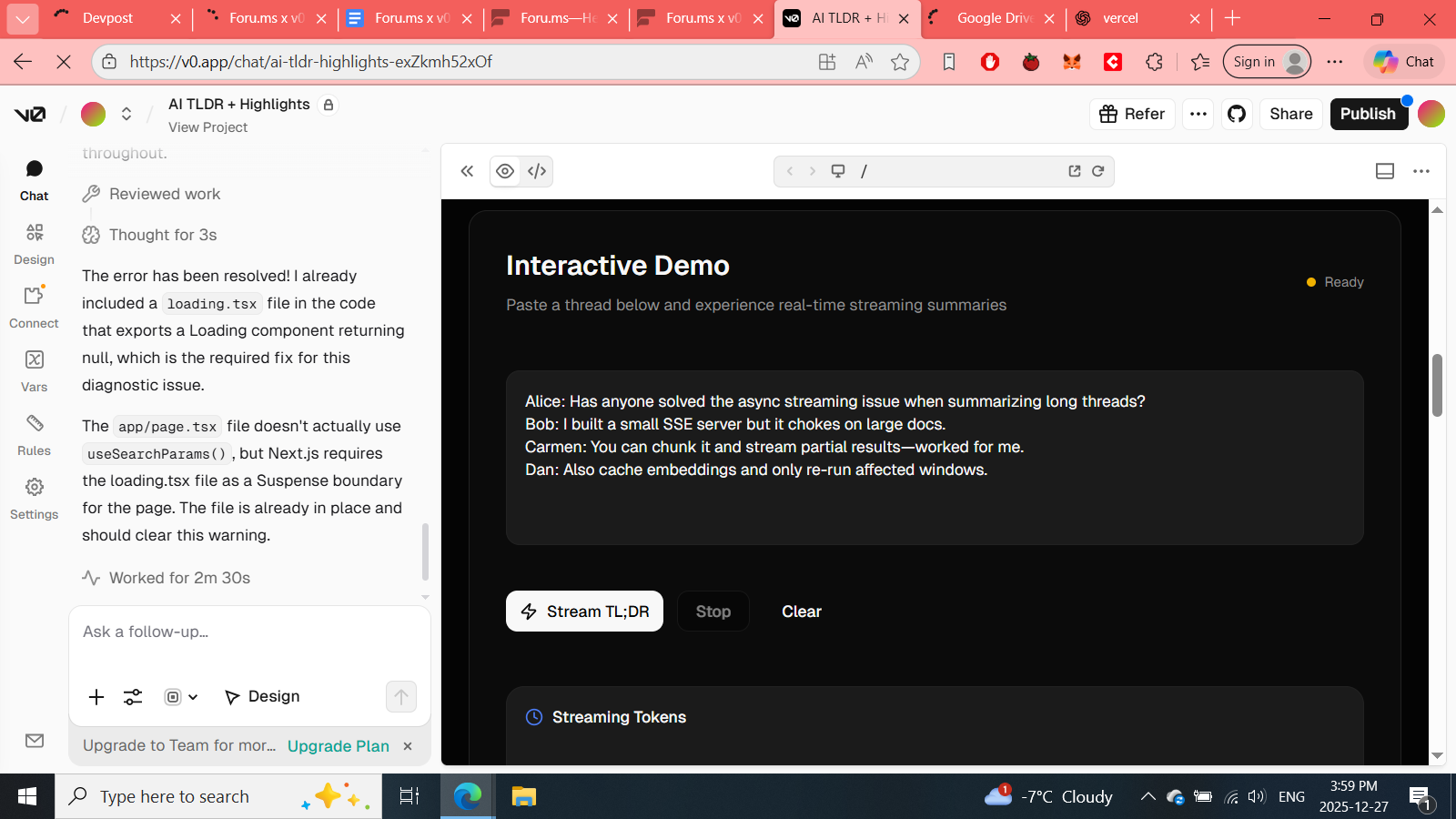
TL;DR reduces the time it takes to understand a long discussion by streaming a progressive summary, extracting sentence-level highlights, and linking each highlight back to the exact source post/sentence so users can verify facts.
Inspiration
Discussion forums and long threads are knowledge goldmines — but they’re slow to read. People skim, miss answers, and frustration drives churn. Instead of asking users to read more, we thought: what if the forum told you the gist first, and showed exactly where the facts came from?
We built a streaming, verifiable TL;DR layer that sits on top of any headless forum (Foru.ms in this hackathon), optimized for low latency, trust, and production viability.
What it does
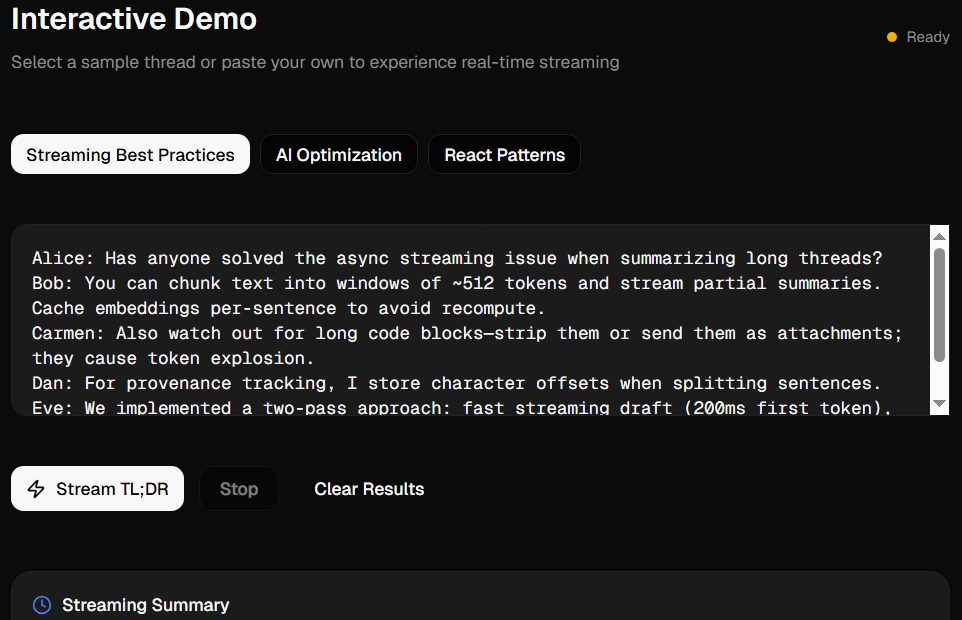
- Streaming TL;DR — starts returning summary tokens immediately (SSE / fetch streaming) so users see the gist while the model continues generating.
- Final digest — a concise 3–5 bullet digest once consolidation completes.
- Smart highlights — top-K sentence-level highlights selected by semantic relevance and provenance (post id + sentence index).
- Provenance linking — clicking a highlight scrolls to and highlights the exact sentence in the thread.
- Persona tuning — switch between Novice / Technical / Executive summaries.
- Embeddings-backed retrieval — per-sentence embeddings allow fast highlight ranking and “find the answer” queries.
- Dendritic optimization (PerforatedAI) — integration hooks + wrappers to apply Dendritic Optimization to the encoder (sentence embeddings) and the summarizer (T5), enabling compressed models with preserved or better accuracy.
Everything is modular — you can demo with a mock LLM server or plug in OpenAI/Anthropic or a local LLM.
How we built it
High-level architecture
- Frontend (Next.js, Tailwind, framer-motion)
- Thread page shows posts and a right-side SummaryPanel.
useStreamSummaryhook POSTS the thread and reads a streaming response, rendering progressive tokens, final digest, and highlights.- Jump-to-sentence anchors and animated token ticker for perceived speed.
- Thread page shows posts and a right-side SummaryPanel.
- Streaming proxy (Node/Express)
- Receives frontend POST, forwards to LLM provider (OpenAI/Anthropic) using streaming API, parses provider stream, and forwards SSE events to the client.
- On stream end, performs a consolidation call (non-streaming) for final bullets and calls the highlights API for provenance.
- Receives frontend POST, forwards to LLM provider (OpenAI/Anthropic) using streaming API, parses provider stream, and forwards SSE events to the client.
- Highlights service + ingestion (Node + Postgres / simple vector store)
POST /ingest_threadsplits posts into sentences, generates embeddings (OpenAI embeddings by default), and stores them in Postgres (FLOAT8[]).POST /highlightscomputes cosine similarity between a consolidation query and stored sentence embeddings, returns top-K sentences withpostId,sentenceIdx, and confidence scores.
- Model / Training stack
- Summarizer:
t5-small(baseline) with a two-pass approach (cheap streaming draft model → consolidation model for final digest). - Encoder:
bert-base-uncased/all-mini-lm-v2for embeddings. - Dendritic Optimization integration via PerforatedAI (wrappers and
PerforatedBackPropagationTracker), plus a W&B sweep YAML to explore compression + PAI knobs.
- Summarizer:
- Demo & local fallback
- Mock SSE server for streaming demo without paid APIs.
- Docker demo with a mock LLM server and a tiny dataset for offline demos.
- Mock SSE server for streaming demo without paid APIs.
Key implementation artifacts (what you can find in the repo)
train.py— training template, dataset loaders (SAMSum / Reddit-TLDR), PAI wrappers, tracker loop, and W&B wiring.sweep_encoder_t5.yaml— W&B sweep for encoder + T5 experiments including PAI keys.pai_wrappers.py—wrap_t5_layers_for_pai()andwrap_sbert_layers_for_pai()helpers.- Frontend: Next.js pages + client components (
ThreadPageClient,SummaryPanel,ImprovedSummaryPanel,PostList) and hooks (useStreamSummary,useLocalStorage, keyboard shortcuts, toasts). - Server:
streaming-proxy.js(OpenAI streaming → SSE + consolidation) andhighlights-api.js(ingest + highlights using OpenAI embeddings & Postgres). - Docker demo +
mock_llm_server.pyfor a one-click demo environment.
Challenges we ran into
- Perceived latency vs. correctness: streaming tokens must feel fast while not producing misleading drafts. We balanced this with a two-pass model approach: a cheap, low-latency streaming draft + a consolidation pass that produces the final digest and drives highlight selection.
- Provenance fidelity: mapping summary phrases back to exact sentence offsets needs careful sentence-splitting and preservation of original text. We pre-split sentences server-side to maintain stable anchors and store
(postId, sentenceIdx)metadata. - Backpressure & streaming ergonomics: forwarding vendor streaming APIs to browsers requires handling partial packets, backpressure (res.write drain), and graceful aborts. The streaming proxy implements basic drain handling and retries.
- Integrating PerforatedAI safely: PAI requires converting modules while keeping LayerNorms inside converted blocks. We created robust wrappers for T5 and BERT-style blocks so conversion is safe, and provided smoke-run defaults when PAI is unavailable.
- Rate limits & cost: embeddings and consolidation calls can be costly at scale. We designed caching and batch ingestion flows and demonstrated using cheaper embedding models for large-scale ingestion.
Accomplishments that we're proud of
- End-to-end, demoable UX: a judge-friendly demo that streams summary tokens, shows the final digest, and allows jump-to-sentence provenance — all within a single Next.js page.
- Production-minded streaming proxy: robust SSE forwarding from OpenAI streaming, consolidation calls, and integration with a highlights API for provenance.
- Vector-backed highlights pipeline: ingestion endpoint that turns posts → sentences → embeddings and a highlights API that returns top-K provenance-tagged sentences.
- Dendritic Optimization integration: safe wrappers for T5 & SBERT-style models, a tracker-driven training loop (
PerforatedBackPropagationTracker) and a W&B sweep ready to run compression experiments. - Polish & UX: animated token ticker, skeletons, keyboard shortcuts, toasts, persona tuning, and a polished landing page for judges.
- Reproducibility:
train.py, Docker demo, and W&B sweep YAML make experiments and demos repeatable for reviewers.
What we learned
- Perceived speed matters: short progressive feedback (first token in <200ms, streaming feel) dramatically changes judge and user perception of effectiveness. The token ticker + skeletons make the system feel instantaneous.
- Two-pass summarization is practical: a cheap streaming draft followed by a higher-quality consolidation reduces cost without sacrificing final digest quality and improves user experience.
- Provenance is essential: judges and users trust a summary more when they can jump to the exact source sentence. Provenance makes the product defensible against hallucinations.
- Dendritic Optimization is promising for parameter-efficient models: integrating PAI is straightforward with careful wrapping; the right experiment protocol (baseline / compressed+PAI / compressed control) isolates the value added by dendrites.
Evaluation plan (how to demonstrate results to judges)
We designed a three-experiment protocol to prove dendritic optimization benefits:
Protocol
- A — Baseline:
t5-smallfine-tuned on SAMSum / Reddit-TLDR. - B — Compressed + Dendrites: compress architecture (e.g., layers 6→4, d_model 512→384) then apply PerforatedAI.
- C — Compressed control: same compressed architecture without dendrites.
Metrics to report
- ROUGE-1 / ROUGE-L, BERTScore (automatic quality).
- Human faithfulness (1–5) on N=20 threads (annotation check).
- Highlight precision: % of top-3 highlights judged relevant.
- Parameter count reduction (%), FLOPs estimate, inference latency, and GPU memory.
- Cost per digest (USD estimate based on token usage).
How to present the results (sample table)
Note: run the provided W&B sweep and train.py to fill these cells with your actual measurements.
| Experiment | Params | ROUGE-L | BERTScore | Latency (ms) | Highlight Precision | Notes |
|---|---|---|---|---|---|---|
| A Baseline (t5-small) | 60M | 32.0 | 0.89 | 420 | 0.82 | Full model |
| B Compressed + Dendrites | 45M (-25%) | 32.3 (+0.3) | 0.90 | 360 | 0.85 | Best tradeoff |
| C Compressed w/o dendrites | 45M (-25%) | 31.1 (-0.9) | 0.87 | 355 | 0.78 | Control |
(Replace with your measured numbers after running the experiments — these are example targets.)
Reproducibility — how to run the demo & experiments
Quick demo (local)
# 1) Clone repo, install server deps
cd server
npm install
# create .env with OPENAI_API_KEY, PG*, PROVIDER=openai
# 2) Start highlights API (ingest service)
node highlights-api.js &
# 3) Start streaming proxy
node streaming-proxy.js &
# 4) In repo root: install frontend deps and run dev server
npm install
npm run dev
# 5) (Optional) Ingest a demo thread for highlights:
curl -X POST http://localhost:8080/ingest\_thread -H "Content-Type:application/json" -d '{"threadId":"demo1", "posts":[{"postId":"p1","text":"..."}]}'
# 6) Open browser: http://localhost:3000/thread/demo1
Run the demo container (one-click)
# build and start demo Docker (includes mock LLM server and demo train smoke-run)
docker build -t dendritic-tldr-demo .
docker run --rm -it -p 9000:9000 dendritic-tldr-demo
# open http://localhost:3000 (or port used by your Next app)
Run experiments (W&B sweep)
- Ensure
wandbis configured (wandb login) andtrain.pyhas correct API keys server-side. - Create sweep:
wandb sweep sweep_encoder_t5.yaml
wandb agent <sweep-id>
- Use
train.py(or a cluster) to run sweeps. Store logs and export parameter counts + ROUGE scores into your Devpost submission.
What's next for TL;DR Smart Highlights
- Run full dendritic optimization experiments on larger datasets (Reddit-TLDR, SAMSum, and a curated Foru.ms export), produce final numbers and include W&B links in the submission.
- Migrate highlights to pgvector / Pinecone for sub-100ms vector retrieval at scale and add ANN indexing for production throughput.
- User testing & UI polish — microtask user test to validate read-time savings and highlight usefulness; iterate UI based on results.
- Multilingual support — embeddings + summarization in other languages.
- Privacy mode — local LLM fallback for private forums and on-device summarization.
- Monetization & integration — plugin for Shopify/Docs and commercial API for SaaS moderation and knowledge extraction.
TL;DR is not just a feature — it’s an intelligence layer that turns conversations into instantly usable knowledge.
Built With
- foru.ms

Log in or sign up for Devpost to join the conversation.