-
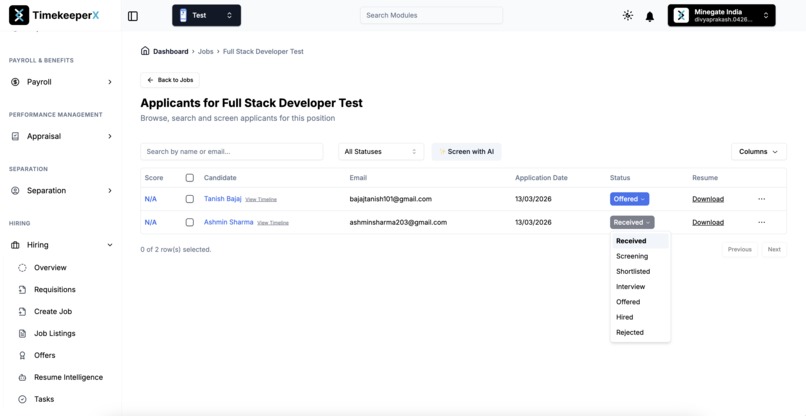
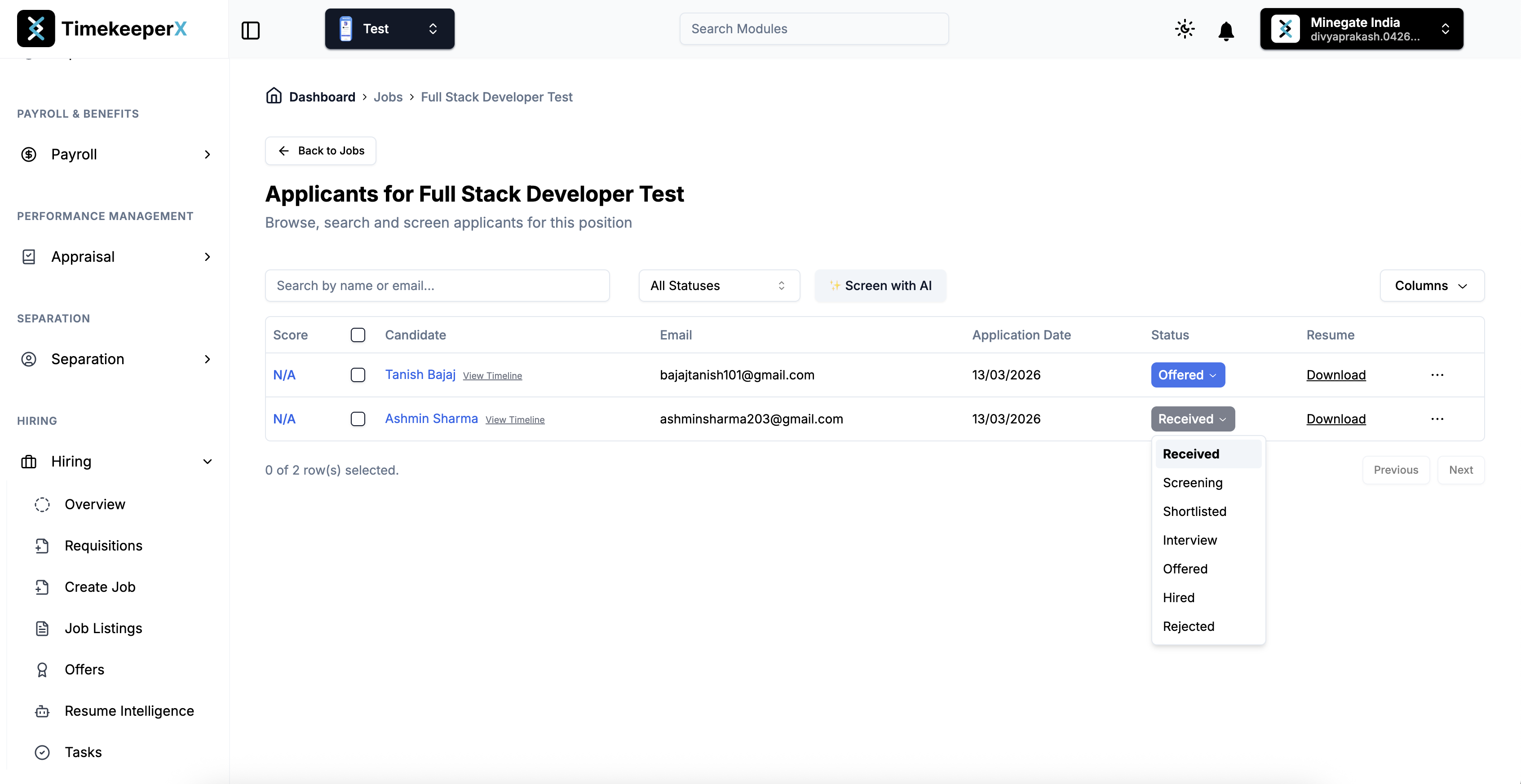
Candidate applied for the Full Stack Developer Test Job.
-
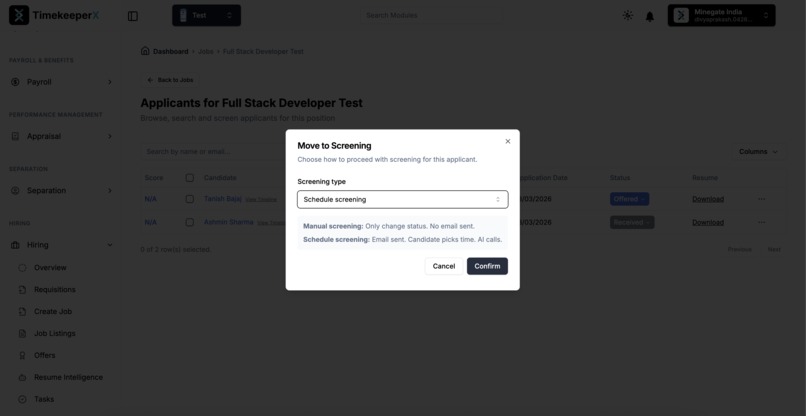
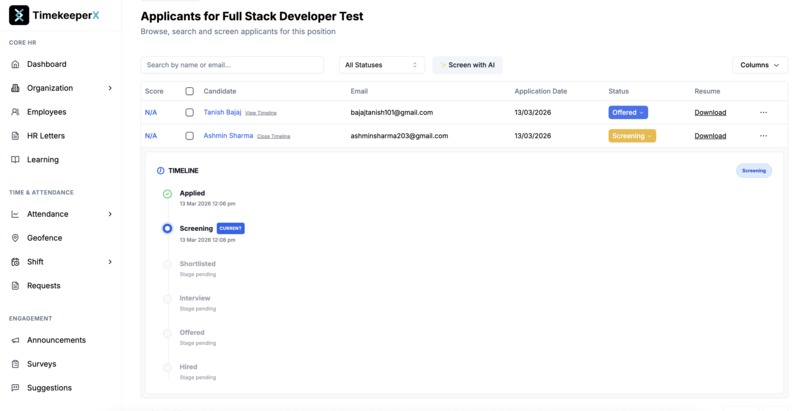
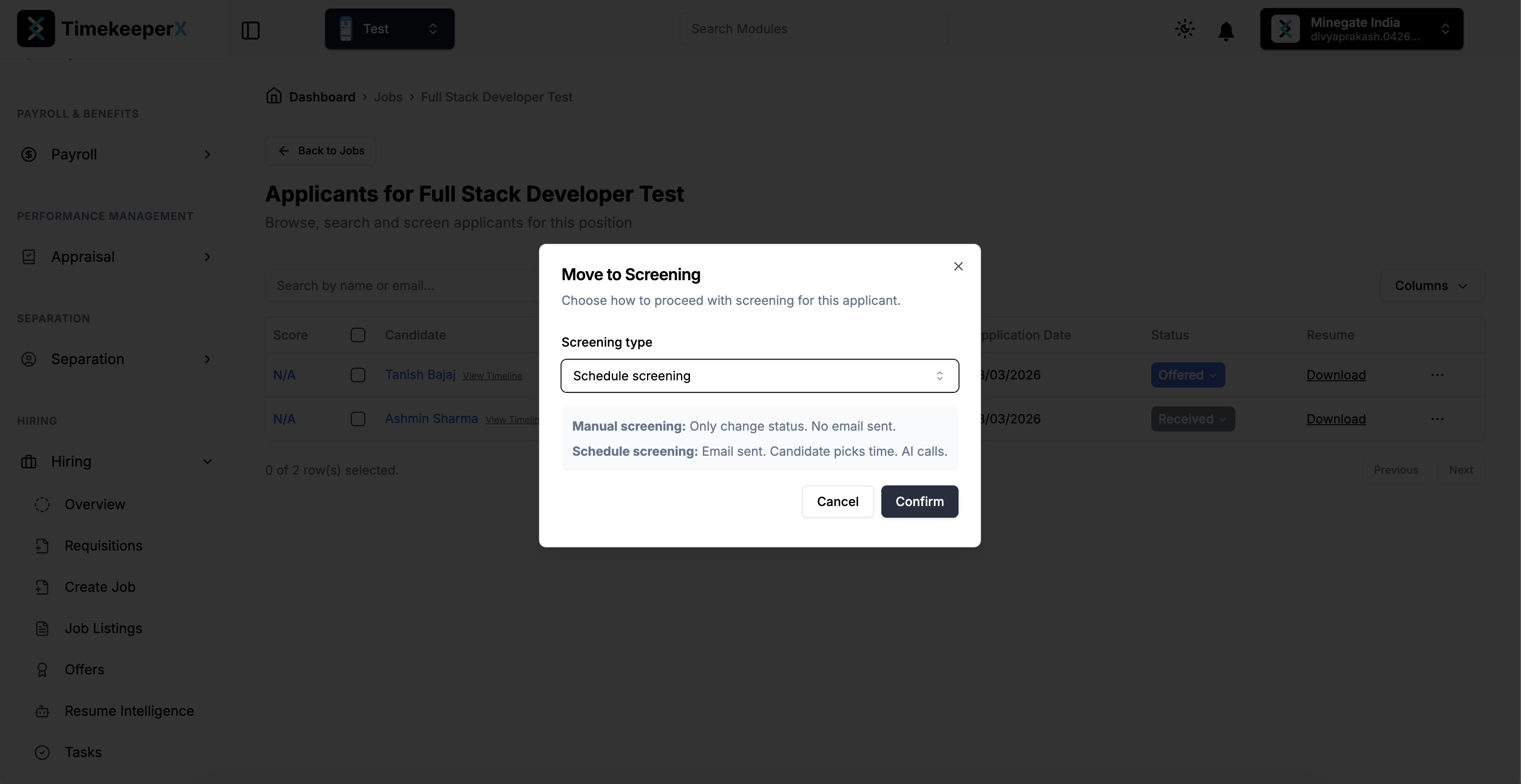
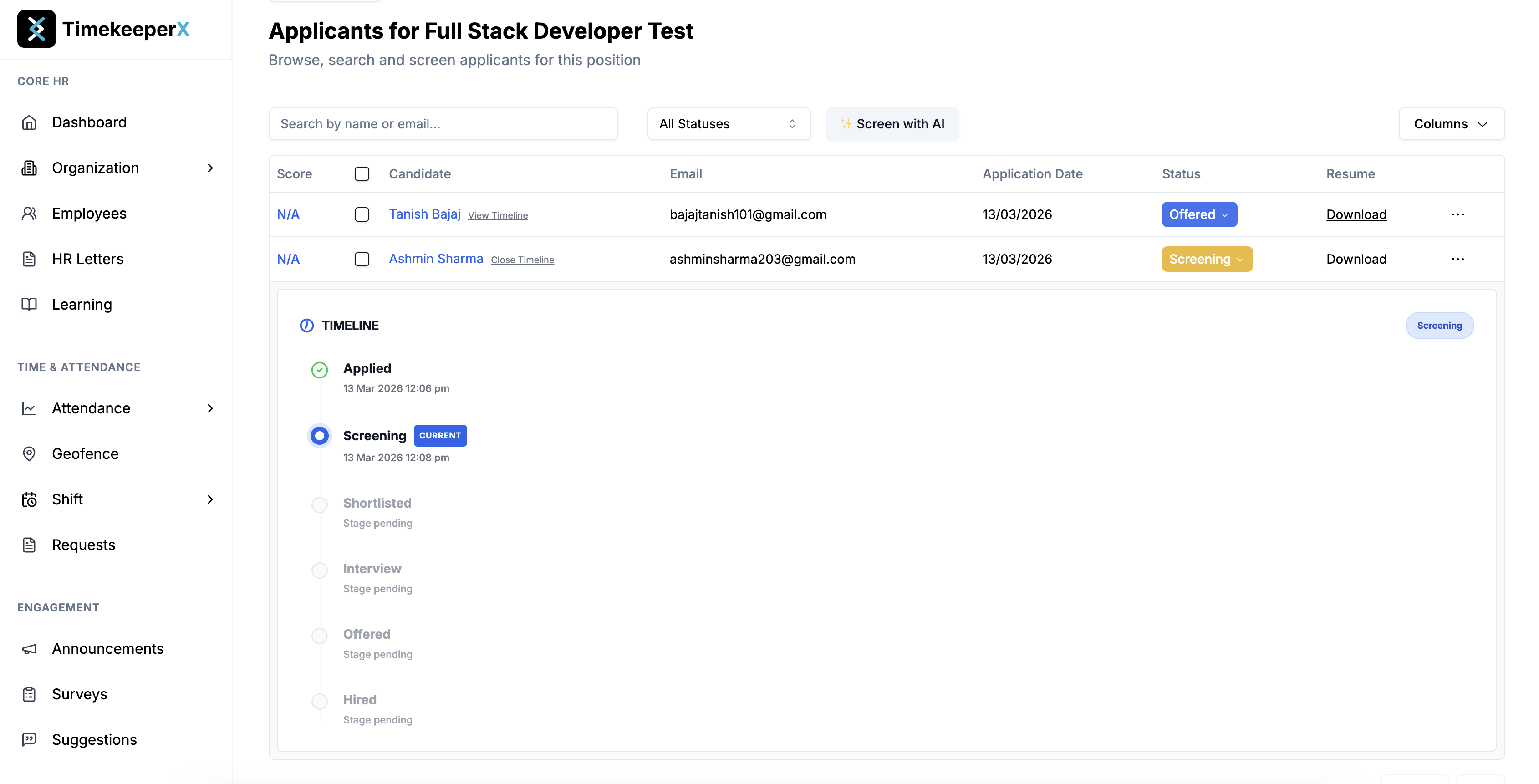
Screening process has been scheduled for the candidate.
-
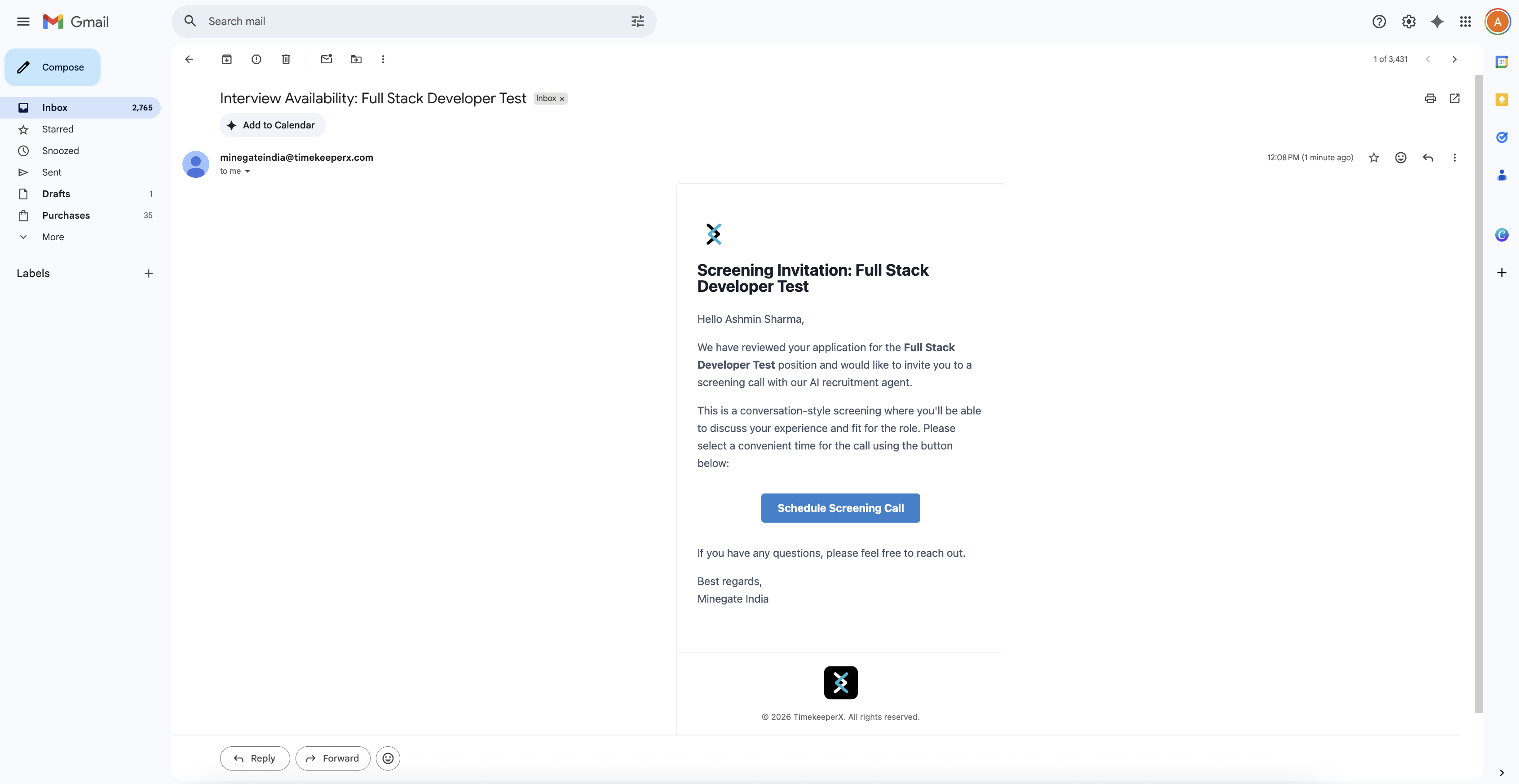
An email has been sent to the candidate to schedule the screening.
-
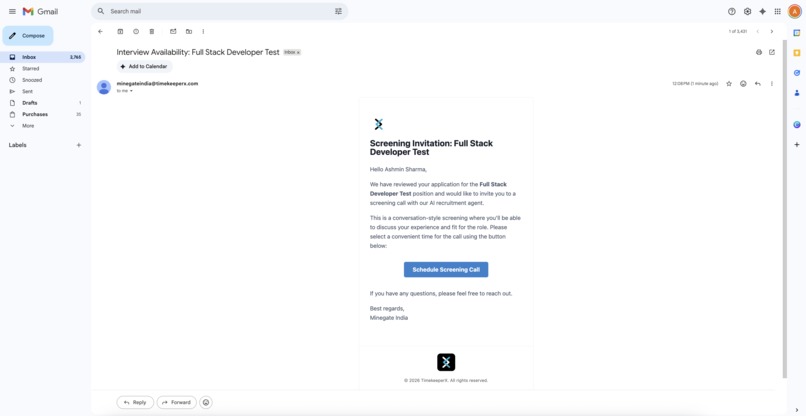
Candidate received the screening schedule email.
-
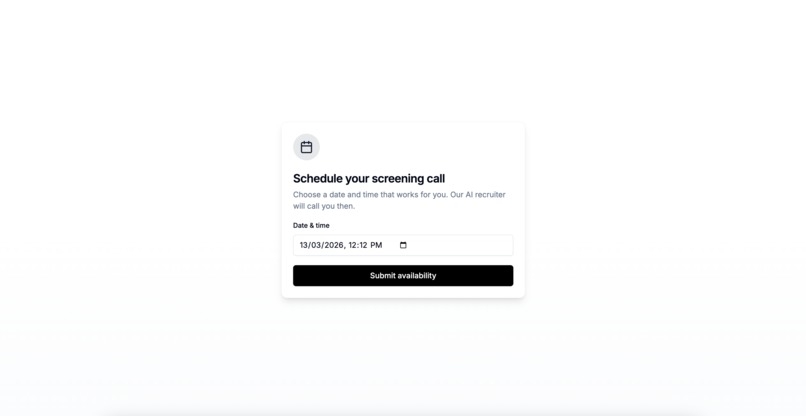
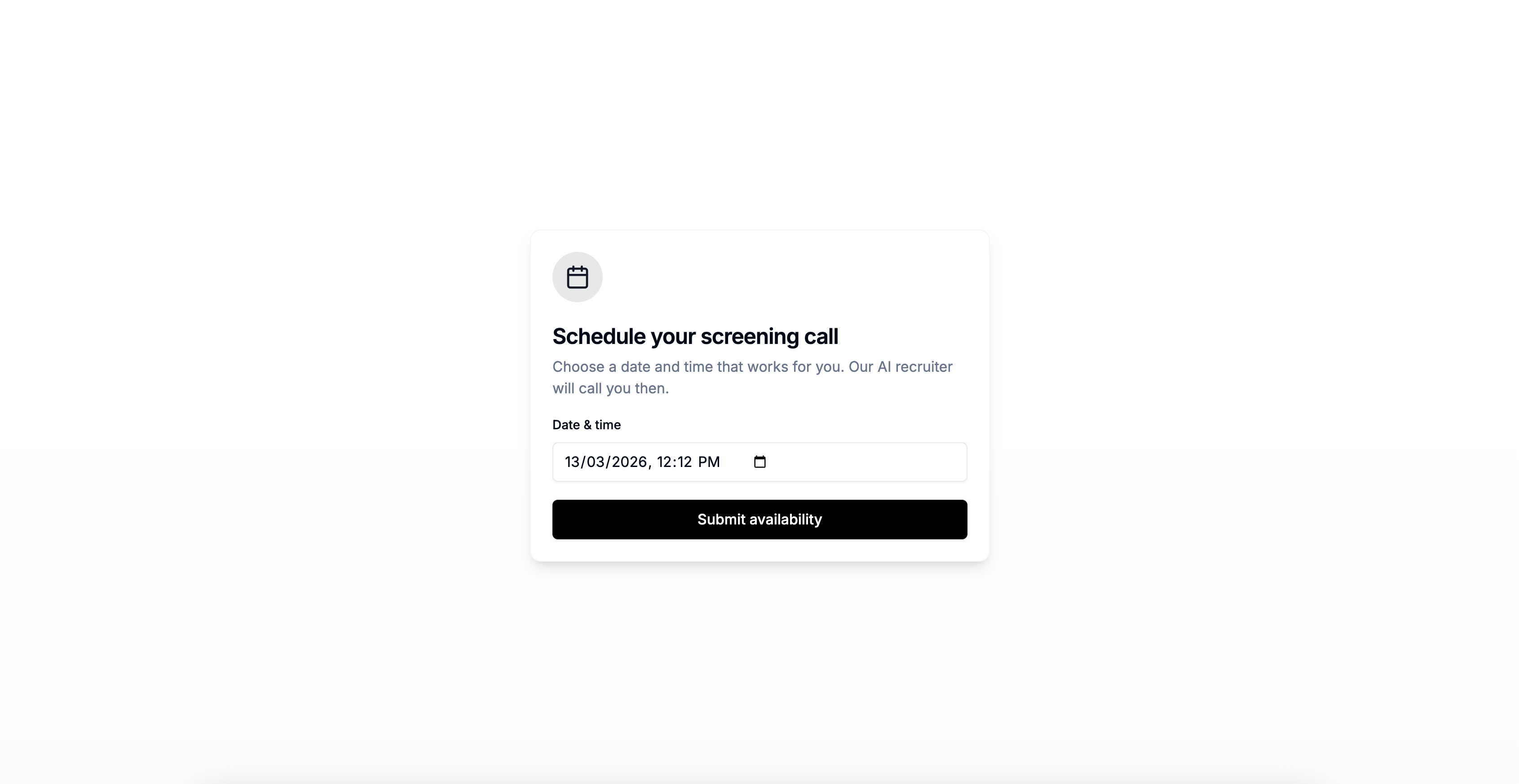
Candidate opened the screening scheduling page through the screening invitation email.
-
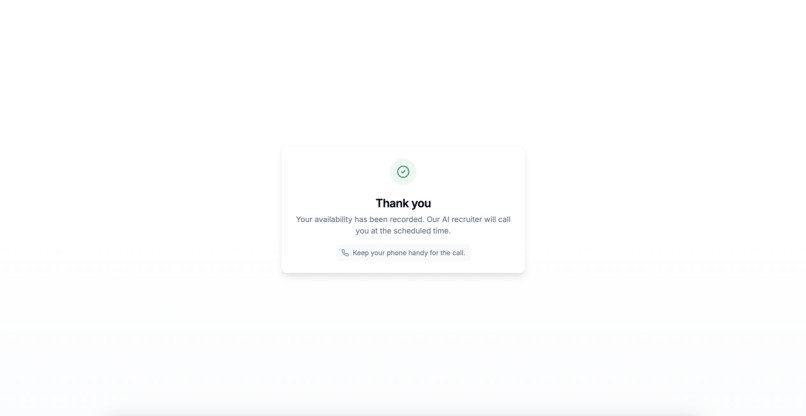
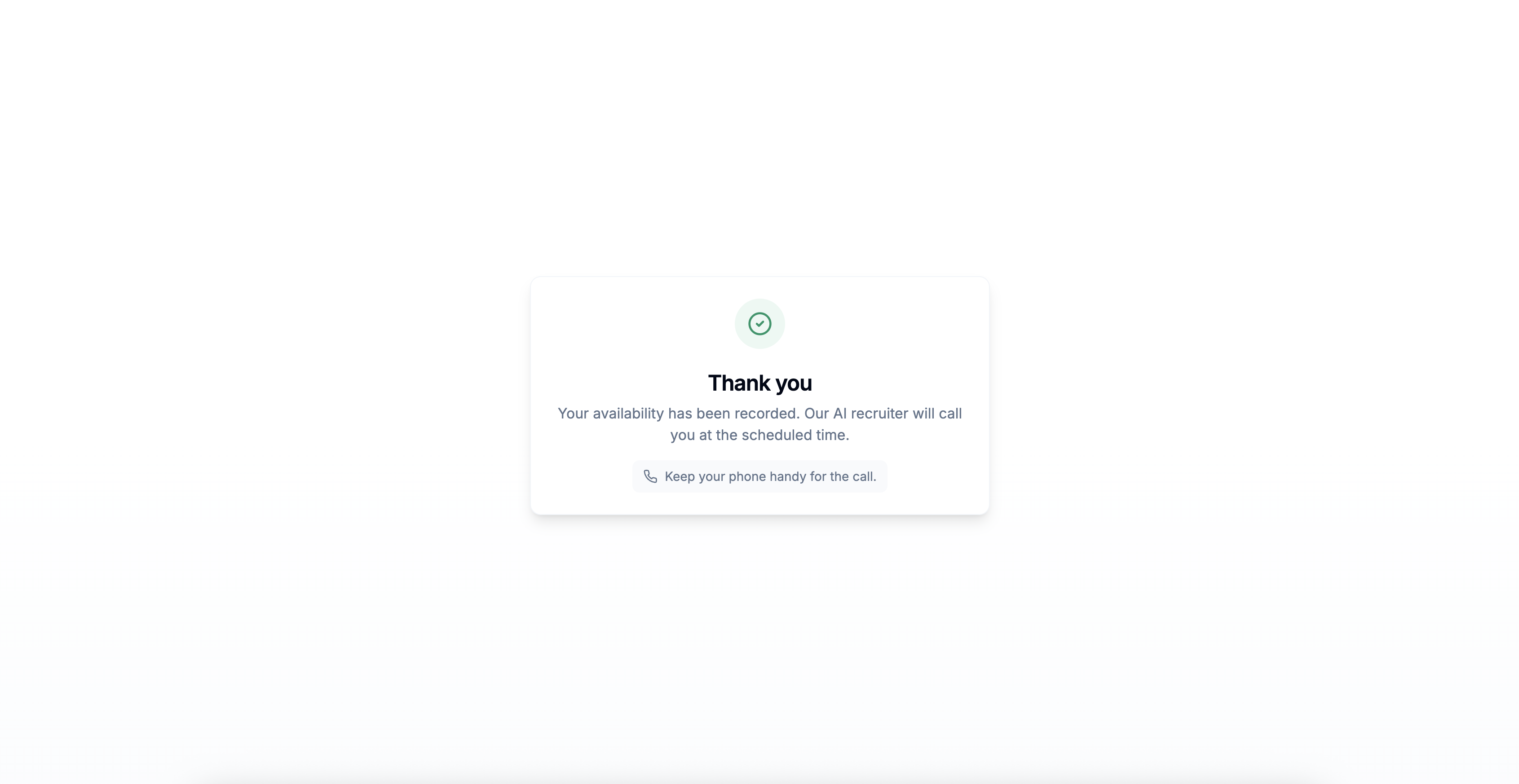
Screening call successfully scheduled by the candidate.
-
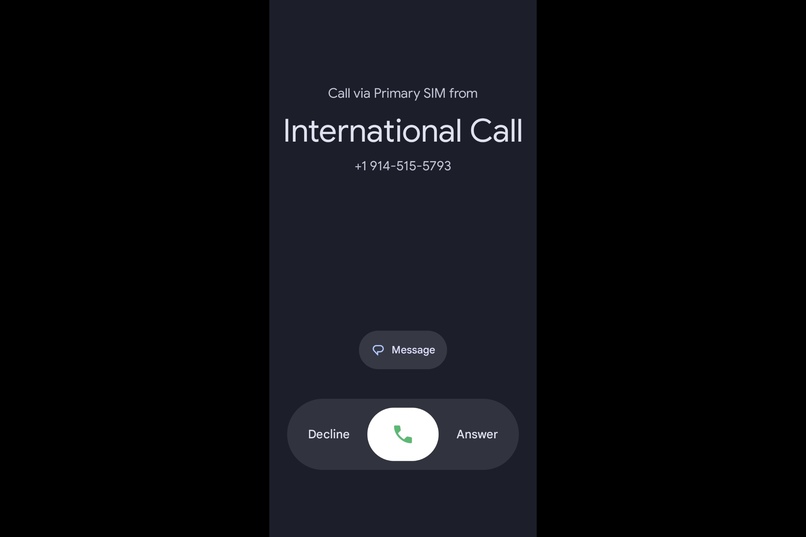
-
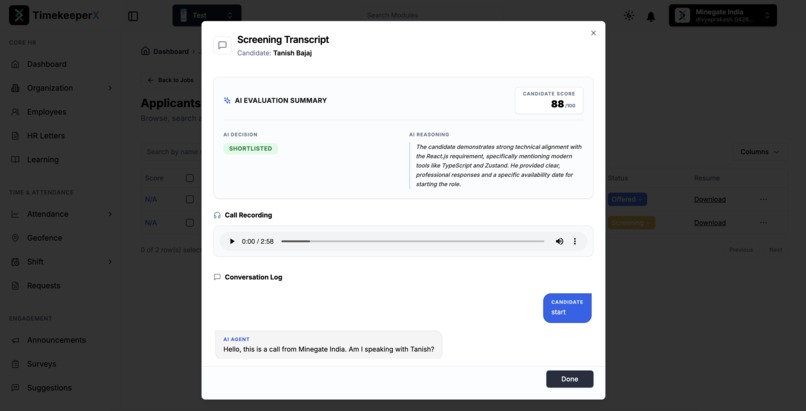
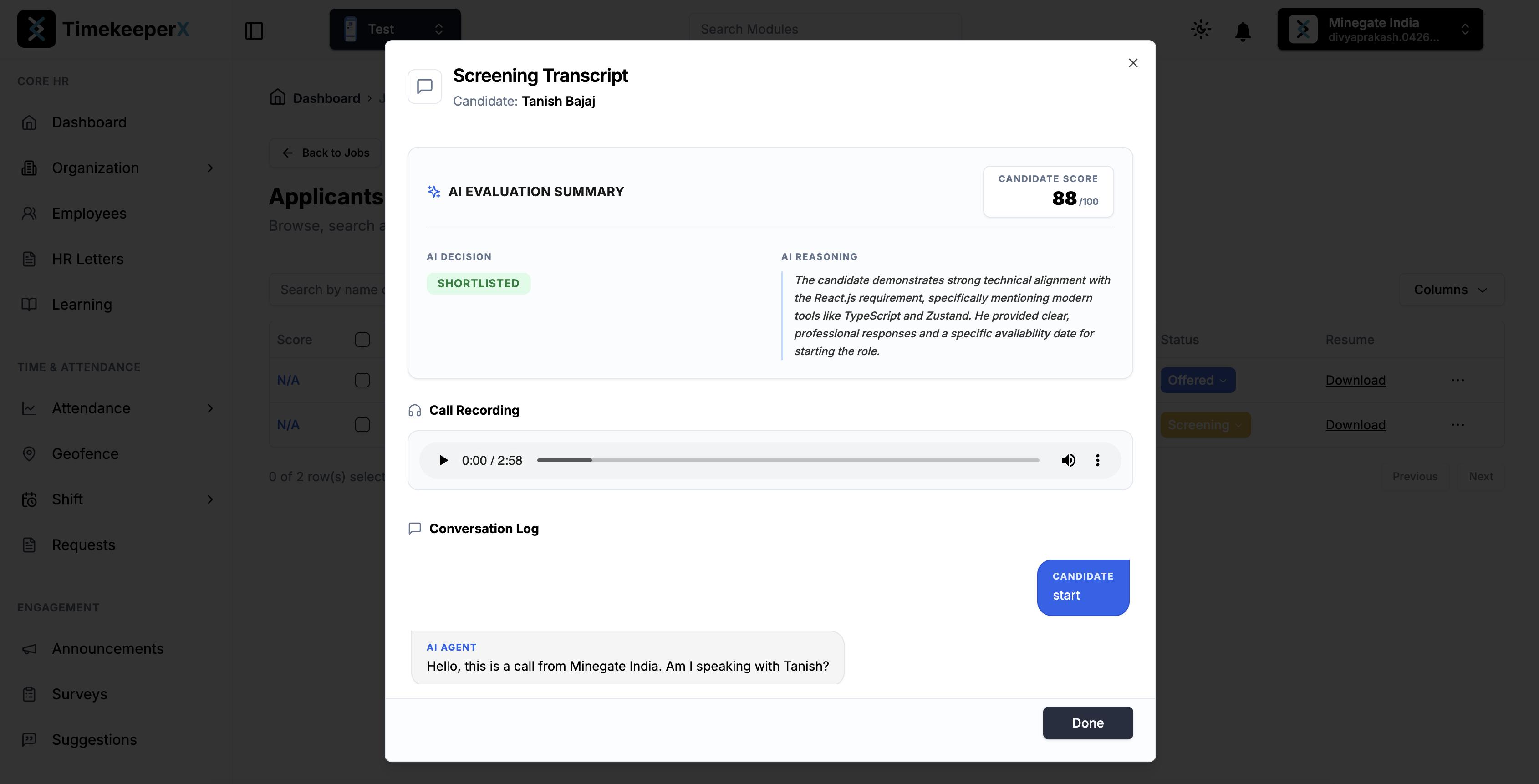
View the candidate–hiring agent transcript and listen to the call audio from the dashboard.
-
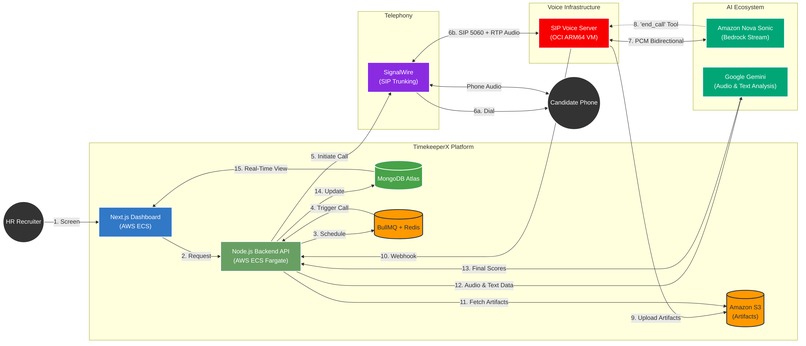
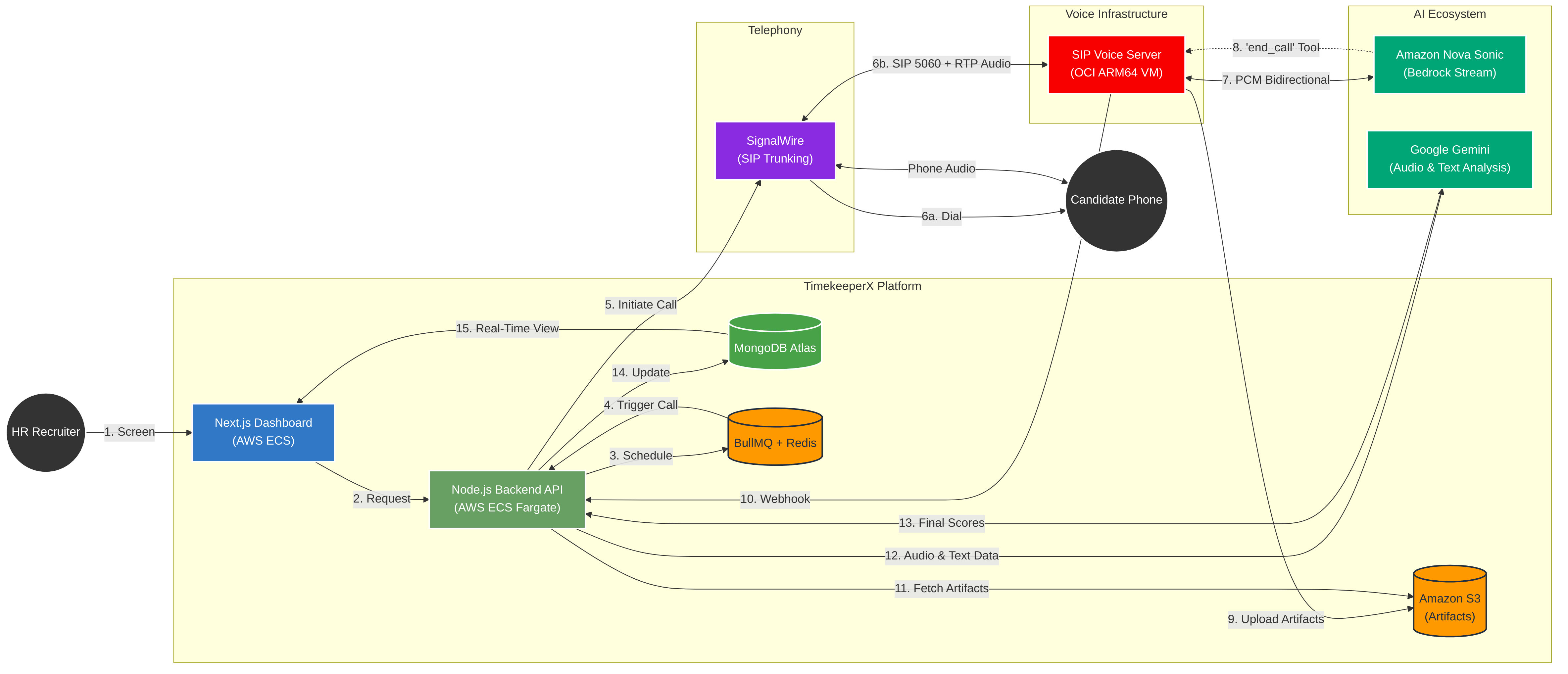
Architecture Diagram
Inspiration
Hiring is broken. A typical recruiter spends 60–70% of their time on the most repetitive part of the funnel: the initial phone screen. They make dozens of calls a day, asking the same questions, evaluating the same criteria, and still end up with inconsistent results. For candidates, it's equally painful — scheduling conflicts, no-shows, and ghosting plague the process on both sides.
We had already built TimekeeperX, a full-stack HR platform with an Applicant Tracking System. But the screening stage was a bottleneck we couldn't automate with chat or text. Phone screening is voice-native — tone, fluency, and conversational flow matter. When Amazon Nova Sonic launched with real-time speech-to-speech capabilities, we saw an opportunity: what if the recruiter who calls you is an AI that sounds human, adapts to your language, and knows your resume inside-out?
That question became this project.
What it does
TimekeeperX AI Hiring Agent is a production-grade, end-to-end voice AI pipeline that automates candidate phone screening. Here's what happens when a recruiter clicks "Screen" on a candidate's application:
- The candidate receives an email with a scheduling link (tenant-branded, timezone-aware).
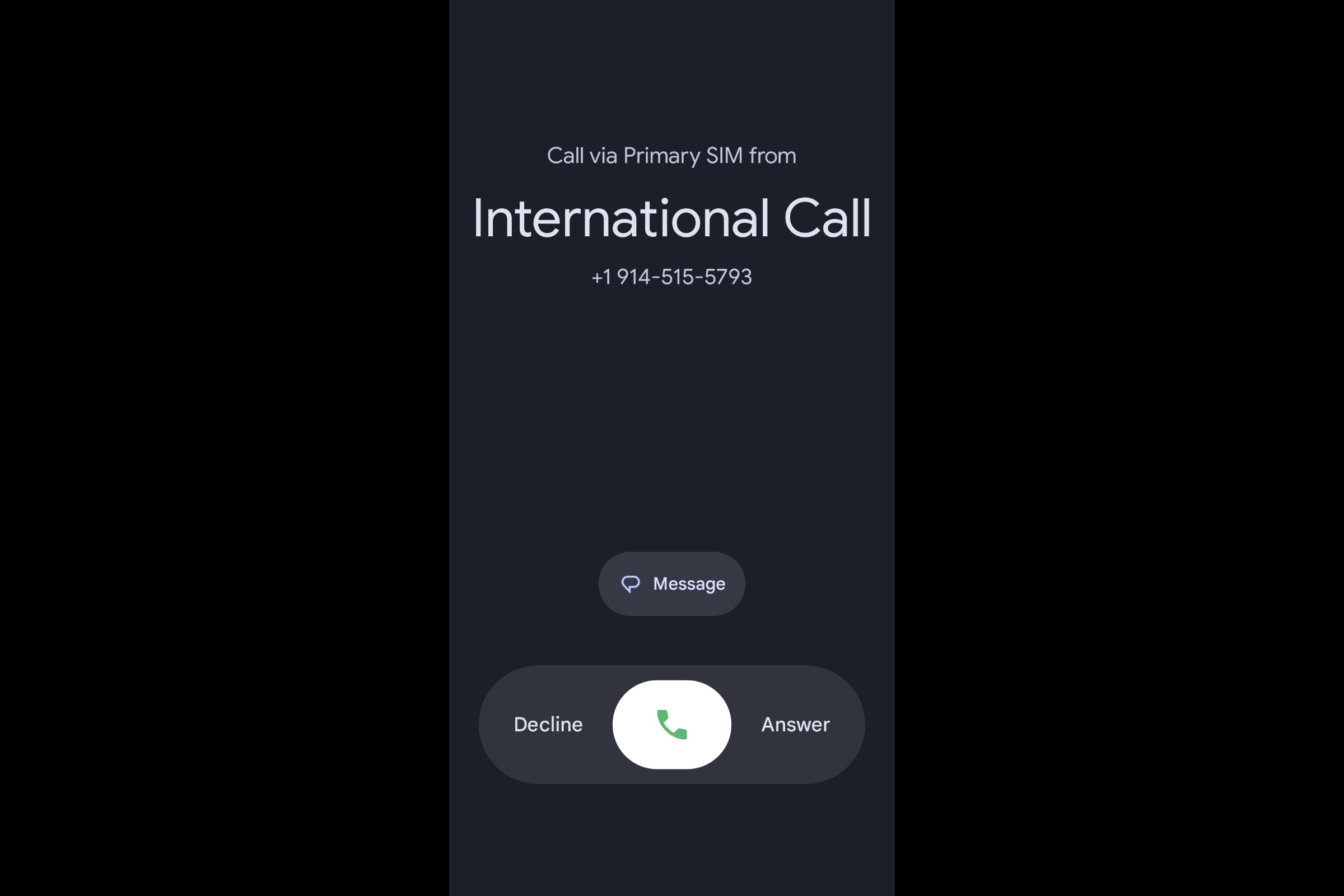
- At the scheduled time, the system places an outbound phone call to the candidate via SignalWire.
- The call connects over SIP to our custom voice server running Amazon Nova Sonic.
- Nova Sonic conducts the interview in real time — asking questions grounded in the candidate's resume and the job description, adapting language (English ↔ Hindi), and maintaining a natural conversational pace.
- When the interview is complete, the AI says a warm goodbye, then hangs up using Nova's tool-calling capability (
end_call). The recording and transcript are uploaded to S3, and a webhook fires back to the platform. - Hybrid AI analysis scores the candidate — the transcript is evaluated for technical knowledge against the job description, while the call recording is analyzed as audio using multimodal AI to score subjective qualities (communication skills, fluency, confidence, professionalism) that only voice can reveal.
- The ATS updates automatically — the recruiter sees a composite score (0–100), per-category breakdowns, the full transcript, and can play back the recording.
The entire flow — from click to scored candidate — happens without any human intervention.
How we built it
The Voice Engine: SIP + Nova Sonic
At the core is a custom SIP server built in Node.js that handles real-time voice calls using the SIP protocol (RFC 3261). When a call arrives, the server:
- Negotiates audio codecs via SDP (we use PCMU/G.711 at 8kHz)
- Allocates RTP ports from a managed pool for bidirectional media streaming
- Establishes a bidirectional streaming session with Amazon Nova Sonic via Bedrock's
InvokeModelWithBidirectionalStreamCommand
The audio pipeline handles real-time codec transcoding between the telephone network and Nova:
Caller (Phone) ──RTP/PCMU 8kHz──▶ SIP Server ──PCM 24kHz──▶ Nova Sonic
│
Caller (Phone) ◀──RTP/PCMU 8kHz── SIP Server ◀──PCM 24kHz───┘
Nova Sonic processes speech bidirectionally — it listens and speaks simultaneously, handling interruptions naturally. When the caller speaks over the AI, our interruption handler (NovaProvider.js) detects the overlap, halts outbound audio, and lets Nova re-engage contextually.
Tool Calling: Teaching the AI to Hang Up
One of the most interesting challenges was giving Nova the ability to end the call itself. We integrated Nova's tool-use capability with two tools:
// Tools registered with Nova Sonic
tools: [
{
name: 'end_call',
description: 'End the current call when the interview is complete'
},
{
name: 'query_knowledge_base',
description: 'Search company knowledge base for information'
}
]
When Nova decides the screening is complete, it invokes end_call, which triggers a HANGUP_REQUESTED event. Crucially, the hangup is delayed (configurable via NOVA_HANGUP_DELAY_MS, default 1.8s) to let Nova's final goodbye audio finish playing before the SIP BYE is sent — so the candidate hears "Thanks for your time, we'll get back to you soon" before the line disconnects, not a mid-sentence click.
If the AI stalls and stops producing audio, an idle-hangup monitor (configurable via AUTO_HANGUP_ON_IDLE_MS, default 30s) automatically disconnects the call — preventing zombie sessions that leave candidates listening to silence.
Dynamic Prompt Engineering: Resume-Grounded Conversations
Each call gets a unique system prompt built from the candidate's parsed resume and the job description:
const systemPrompt = `You are a friendly HR recruiter calling from ${companyName}
conducting a short phone screening for: ${jobTitle}.
Job description: ${jobDescription}
Required skills: ${skills}
Candidate name: ${candidateName}
Candidate resume context: ${resumeText.slice(0, 6000)}
Instructions:
- Ask one question at a time, wait for the answer
- Aim for 3-7 minutes
- If the candidate speaks Hindi, seamlessly switch to Hindi
- When done, use end_call to hang up`;
This prompt is cached on the SIP server via a REST endpoint (POST /api/prompt) and retrieved when the call arrives — keeping the voice server stateless while enabling per-call customization.
Multi-Cloud Production Deployment
The system runs across two cloud providers:
| Component | Cloud | Service | Why |
|---|---|---|---|
| SIP Voice Server | OCI (Oracle Cloud) | ARM64 VM, Docker, host networking | SIP requires direct UDP — no load balancer or NAT in the media path |
| Backend API | AWS | ECS Fargate (ARM64/Graviton) | Scalable container orchestration |
| Frontend | AWS | ECS Fargate + CloudFront | Next.js dashboard with global CDN |
| Realtime Voice AI | AWS | Bedrock (Amazon Nova 2 Sonic) | Low-latency speech-to-speech interviewing |
| Post-call Analysis | Google Cloud APIs | Gemini (multimodal) | Audio + transcript scoring for communication quality |
| Artifacts | AWS | S3 | Call recordings, transcripts, metadata |
| Job Queue | AWS | ElastiCache Redis + BullMQ | Delayed call scheduling |
The SIP server runs with host networking on OCI because SIP/RTP requires raw UDP socket access — no HTTP load balancer can proxy SIP signaling or RTP media streams. Our deployment pipeline automatically configures iptables rules for SIP (UDP 5060), RTP (UDP 10000–10400), and fragmented UDP packets.
Concurrency at Scale
We designed for production traffic from day one:
- RTP port pooling: 400 ports (10000–10400) supporting up to 200 concurrent calls
- Admission control: Returns SIP
503 Service Unavailablewhen capacity is reached - Session lifecycle guards: Setup timeout (30s), max duration backstop (15min), stale-session cleanup
- Call-ID based session tracking: Prevents session collisions from repeated caller identities
// Capacity check on every incoming INVITE
if (this.activeSessions.size >= this.maxConcurrentSessions) {
this.sendResponse(rinfo, this.sipHandler.build503ServiceUnavailable(headers));
return;
}
Security & Toll Fraud Prevention
Exposing a SIP server connected to a generative voice AI model creates a massive vector for toll fraud and resource exhaustion. To protect the deployment:
- Pre-Flight Prompt Authentication (
REQUIRE_PROMPT_CACHE_FOR_INVITE): The SIP server strictly rejects any incomingINVITEwith a403 Forbiddenif a prompt cache entry does not already exist for that specificmeetingId. This ensures only candidates with a pre-authorized, scheduled meeting can interact with the AI, fully mitigating unauthorized dial-in scanning attempts. - HMAC SHA-256 API & Webhook Signing: All server-to-server communications (prompt caching, end-of-call webhooks) are cryptographically signed using a shared secret. We use timestamped, nonce-backed payloads combined with timing-safe equality checks (
crypto.timingSafeEqual) to prevent replay and timing attacks. Callback URLs are strictly time-bound (cb_exp). - Network-Level Service Isolation: Because the SIP server requires host networking for pure UDP RTP paths, we implemented zero-trust
iptablesrules. Internal API ports are dropped on public interfaces and proxied entirely via Caddy with HTTPS, exposing only SIP (5060) and the allocated RTP pool (10000–10400) to the public web.
Post-Call Analysis Pipeline: Hybrid Text + Audio Scoring
After each call, artifacts flow through a structured pipeline:
- Recording (multi-channel WAV) → uploaded to S3
- Transcript (timestamped conversation log) → uploaded to S3
- Metadata (call duration, participants, provider info) → uploaded to S3
- Webhook fires to backend with conversation data + S3 references
- Text Analysis — the transcript is evaluated against the job description and resume for technical knowledge and overall fit, producing a recommendation and 0–100 score
- Audio Analysis (Multimodal) — the WAV recording is downloaded from S3 and sent as inline audio to a multimodal model that listens to the actual call and scores subjective qualities that text alone cannot capture:
// Audio analysis evaluates the candidate's vocal qualities from the recording
const audioScores = await interviewAnalyzerService.analyzeAudio(audioBuffer, 'audio/wav');
// Returns: { communicationSkills, fluency, confidence, professionalism }
// Subjective scores from audio override the text-only estimates
analysis.categoryScores.communicationSkills = audioScores.communicationSkills;
analysis.categoryScores.fluency = audioScores.fluency;
analysis.categoryScores.confidence = audioScores.confidence;
analysis.categoryScores.professionalism = audioScores.professionalism;
This hybrid approach means technical knowledge is scored from what the candidate said (transcript), while how they said it — clarity, vocal confidence, conversational flow, professional tone — is scored from the actual audio. The result is a richer, fairer evaluation than either modality alone.
- ATS Update moves the candidate to
ShortlistedorRejectedwith per-category score breakdowns
All artifacts are stored with tenant-scoped S3 prefixes (screening-calls/{tenantId}/{meetingId}/), enabling multi-tenant data isolation.
Challenges we ran into
SIP over cloud infrastructure is hard. We had a crucial head start: AWS's own open-source sample server (aws-samples/sample-sonic-sip-server-js) gave us a working foundation for connecting Nova Sonic to SIP calls. Without it, building the SIP signaling, RTP handling, and Bedrock streaming integration from scratch would have been weeks of work before we could even attempt the hiring use case. From that baseline, we built all the production enhancements that made this project real — concurrency controls, session hardening, artifact pipelines, prompt caching, multi-tenant isolation, and the full outbound hiring flow. Even with the head start, SIP's use of UDP for signaling and RTP for media — protocols that don't play well with load balancers, NAT gateways, or container networking — was a constant battle. Early deployments had silent audio (RTP packets dropped by NAT) and one-way calls. The solution was host networking on a dedicated VM with carefully configured firewall rules.
Nova Sonic's streaming startup is sensitive. We discovered that including toolConfiguration in the promptStart event caused parse failures (Unable to parse input chunk) on certain streams. The fix was gating tool configuration behind an ENABLE_NOVA_TOOLS flag and ensuring the event payload format was consistent across the queueing pipeline.
Codec transcoding in real-time is unforgiving. The telephone network speaks PCMU at 8kHz; Nova Sonic speaks PCM at 24kHz. Any misalignment in sample rates, buffer sizes, or timing causes audio glitches. We built a priority-based audio queue that ensures codec conversion happens without blocking the stream, and added RTP keepalive packets (silence frames every 15s) to prevent NAT timeouts.
Session cleanup under adversarial conditions. In production, callers drop without sending BYE, SIP retransmissions create duplicate sessions, and network partitions leave zombie connections holding RTP ports. We added setup timeouts, max-duration backstops, and centralized timer cleanup to prevent resource exhaustion.
Accomplishments that we're proud of
- It actually calls people and sounds human. The Nova Sonic integration produces natural, conversational interviews that candidates often don't realize are AI-powered until told.
- Zero-intervention hiring funnel. From application to scored candidate, the entire flow is automated — recruiter clicks once, gets a scored transcript back.
- Production-ready at 200 concurrent calls. Not a demo — this runs on real infrastructure with real phone numbers, handling real SIP traffic.
- Multilingual adaptation. The AI seamlessly switches between English and Hindi mid-conversation based on the candidate's language preference.
- Tool-calling for call control. Nova doesn't just talk — it decides when the interview is done, speaks a closing line, and hangs up the call with a graceful delay so the goodbye isn't clipped. An idle-timeout backstop auto-disconnects if the AI ever stalls.
- Hybrid text + audio analysis. Technical knowledge is scored from the transcript; communication, fluency, confidence, and professionalism are scored from the actual audio recording — capturing nuances that text analysis misses entirely.
- Multi-tenant SaaS architecture. Each company gets isolated artifacts, branded emails, and subdomain-scoped callback URLs — this isn't a single-tenant demo.
- Live in production with real clients. We are a startup and this isn't sitting on a shelf — the AI Hiring Agent is actively running for our first client, screening real candidates for real roles. We also use it internally for our own hiring. Every improvement in this submission was battle-tested against real calls, real candidates, and real recruiter feedback.
What we learned
- Voice AI needs production infrastructure, not just a model. The gap between "Nova Sonic works in a demo" and "Nova Sonic handles 200 concurrent SIP calls with artifact storage" is enormous. SIP, RTP, codec negotiation, port management, and session lifecycle are all critical infrastructure that doesn't exist in sample code.
- Speech-to-speech changes the UX equation. Text-based screening loses nuance. Voice captures communication skills, confidence, and cultural fit in ways that text never can. Nova Sonic's real-time capabilities make this practical for the first time.
- Multimodal analysis unlocks richer evaluation. Scoring a transcript tells you what a candidate said. Scoring the audio tells you how they said it — vocal confidence, speech clarity, conversational flow. Combining both produces evaluations that neither modality achieves alone.
- Tool calling in voice is powerful. Giving the AI the ability to take actions (hang up, query a knowledge base) during a live call opens up patterns that weren't possible with text-only agents.
- Multi-cloud is sometimes necessary. SIP's UDP requirements pushed us to OCI for the voice server while keeping everything else on AWS. The architectural complexity was worth the reliability gain.
What's next for TimekeeperX AI Hiring Agent
- Real-time transcription to the recruiter dashboard — live-stream the conversation as it happens so recruiters can monitor active calls.
- Multi-round screening — chain multiple AI interviews (technical round, cultural fit round) with different prompts and scoring criteria.
- Video screening via WebRTC — extend the pipeline to video interviews for roles that require visual assessment.
- Candidate feedback loop — let candidates rate their screening experience and use that signal to improve prompt engineering.
- Expanded language support — beyond English and Hindi, add support for regional languages using Nova's multilingual capabilities.
- Custom screening templates — let recruiters design their own question flows per job, with the AI adapting in real-time.
Built With
- amazon-acm
- amazon-bedrock
- amazon-cloudfront
- amazon-cloudwatch
- amazon-ecr
- amazon-ecs-(fargate)
- amazon-elasticache-(redis)
- amazon-nova-lite
- amazon-nova-sonic
- amazon-route-53
- amazon-ses
- amazon-waf
- amazon-web-services
- aws-textract
- bullmq
- docker
- github-actions
- mongodb
- next.js-14
- node.js
- oracle-cloud-infrastructure-(oci)
- rtp
- shadcn
- signalwire
- sip-protocol
- terraform
Log in or sign up for Devpost to join the conversation.