-
-
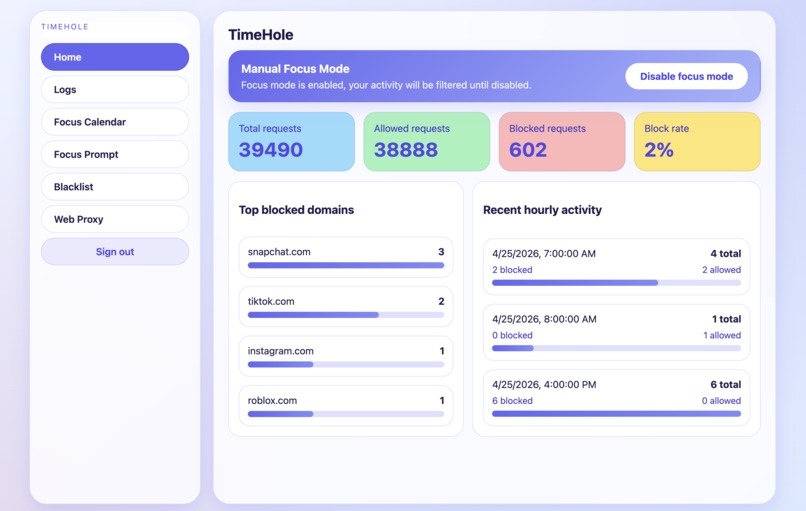
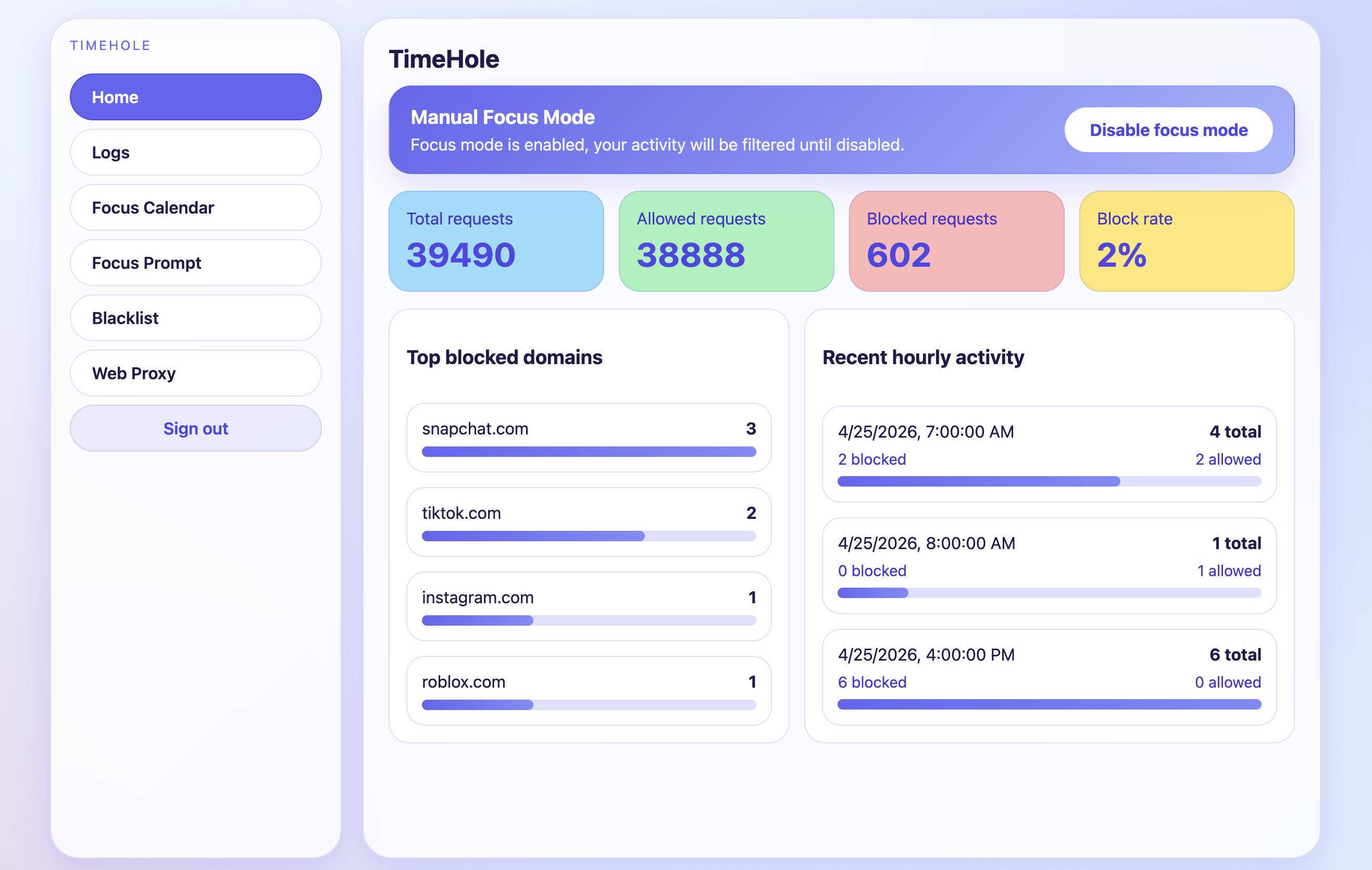
Home screen for TimeHole
-
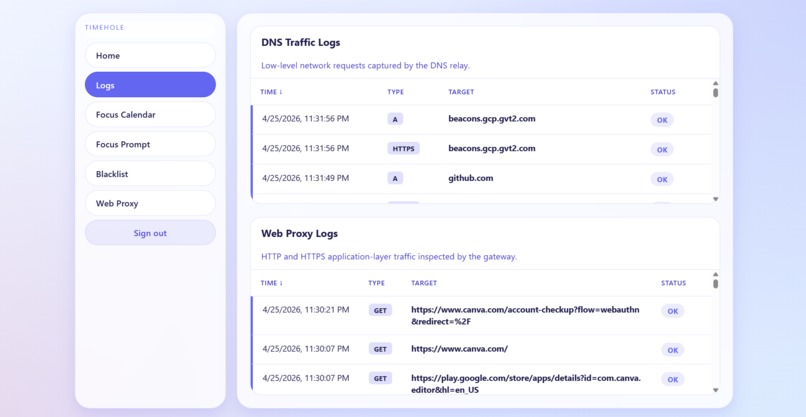
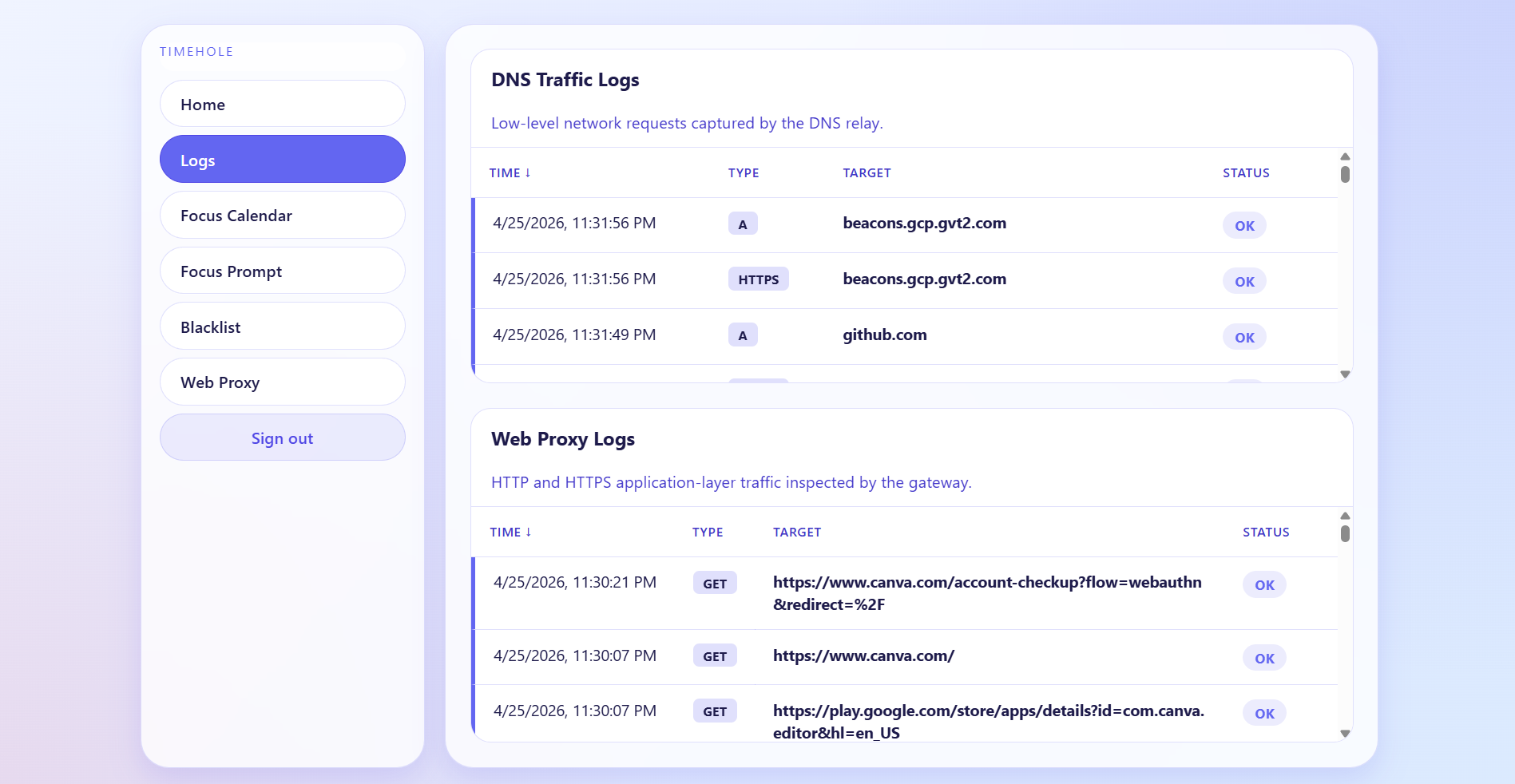
Logging screen
-
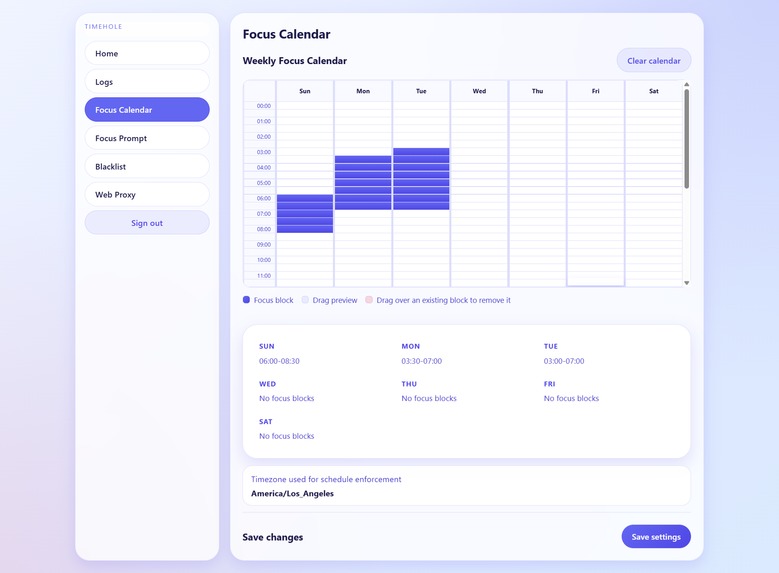
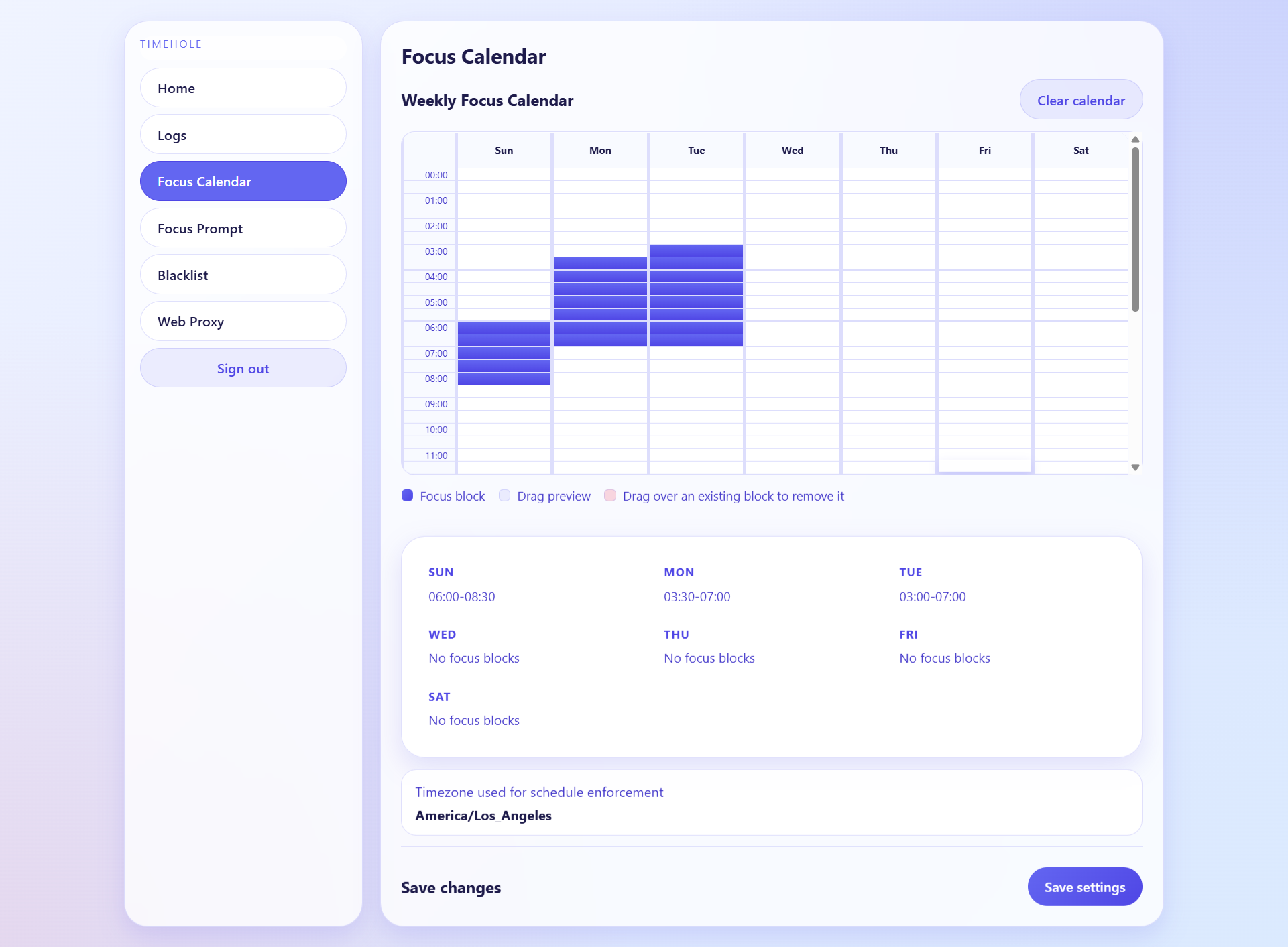
Focus Calendar screen
-

Focus Prompt screen
-
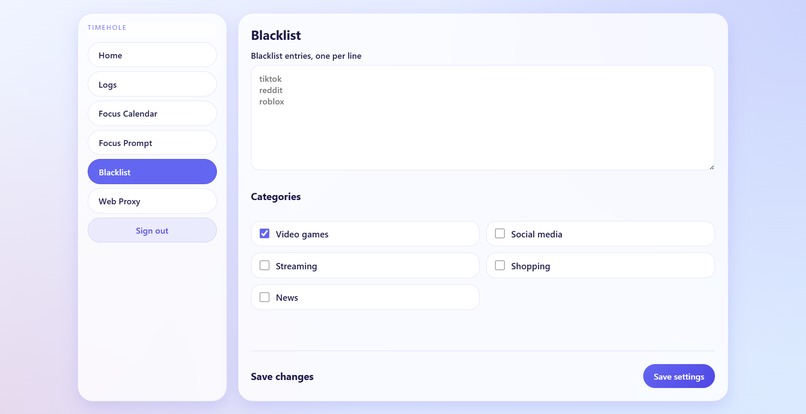
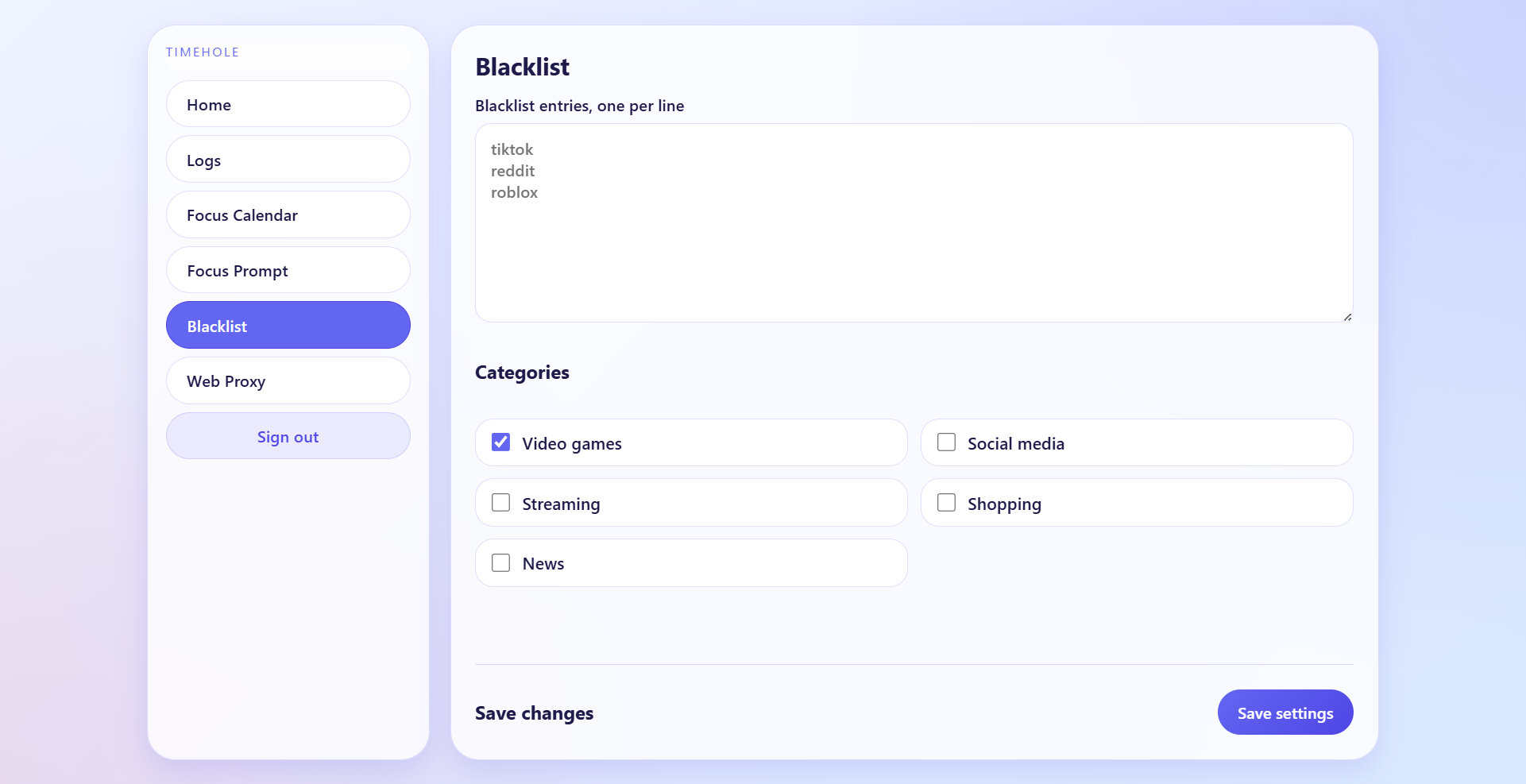
Blacklist screen
-
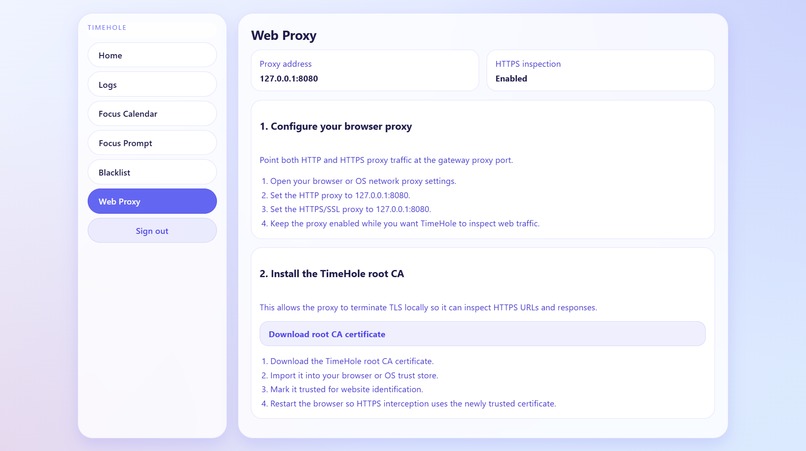
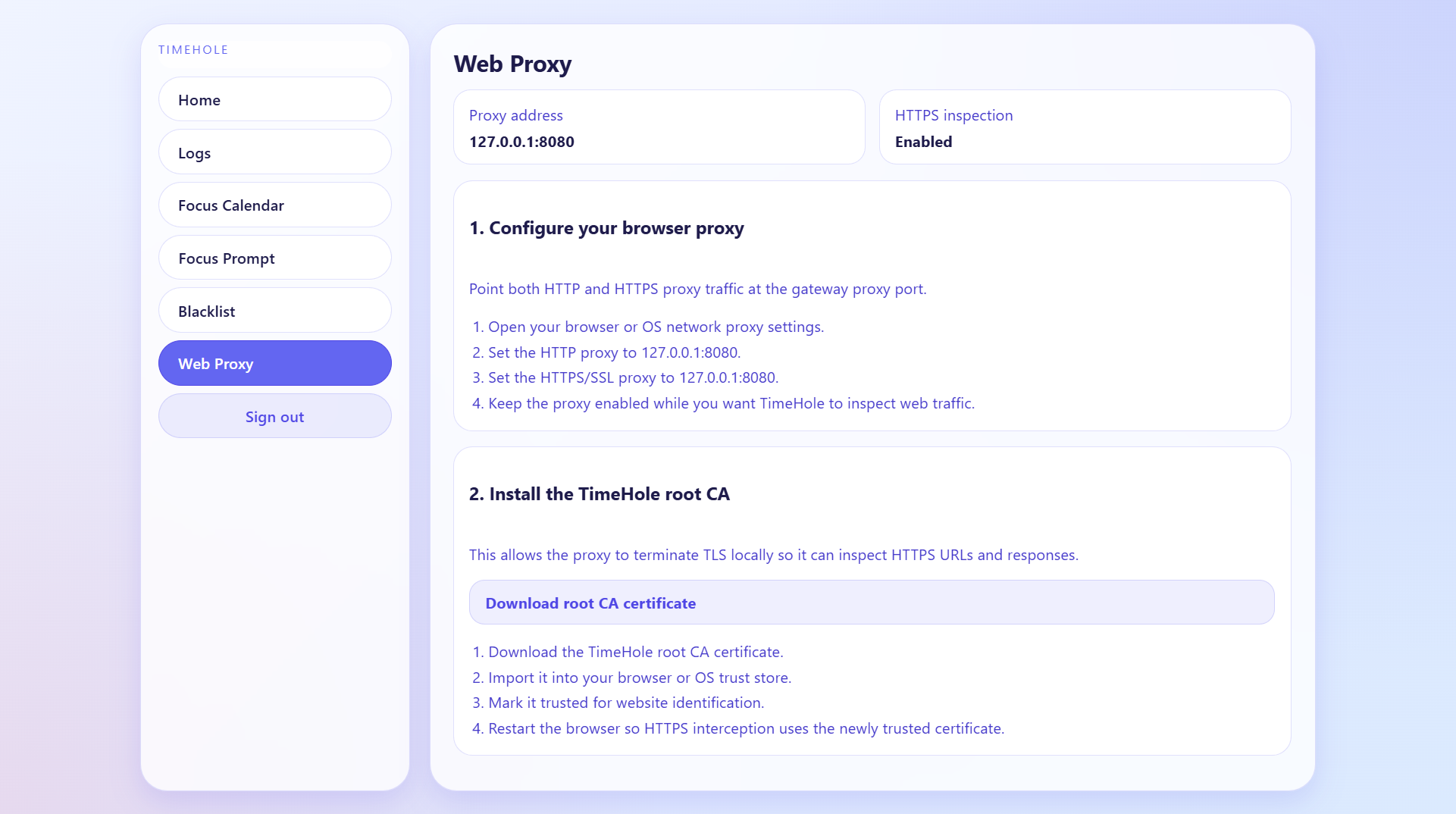
Web Proxy explanation screen
-
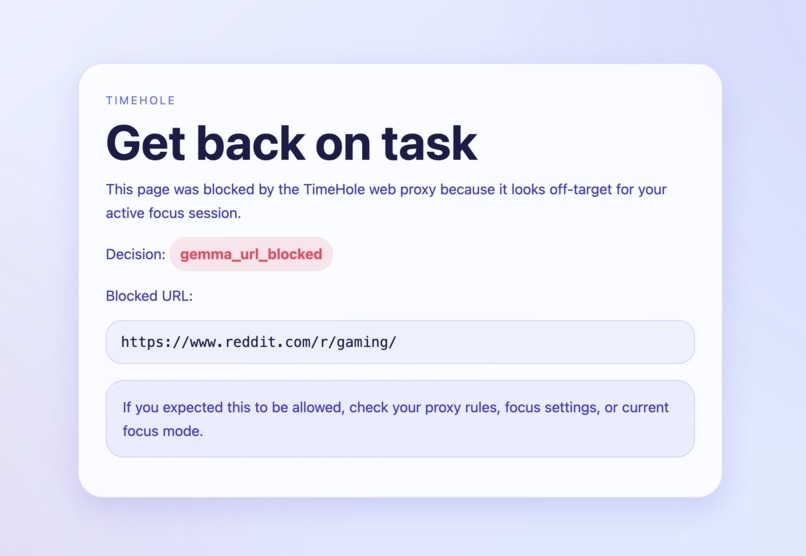
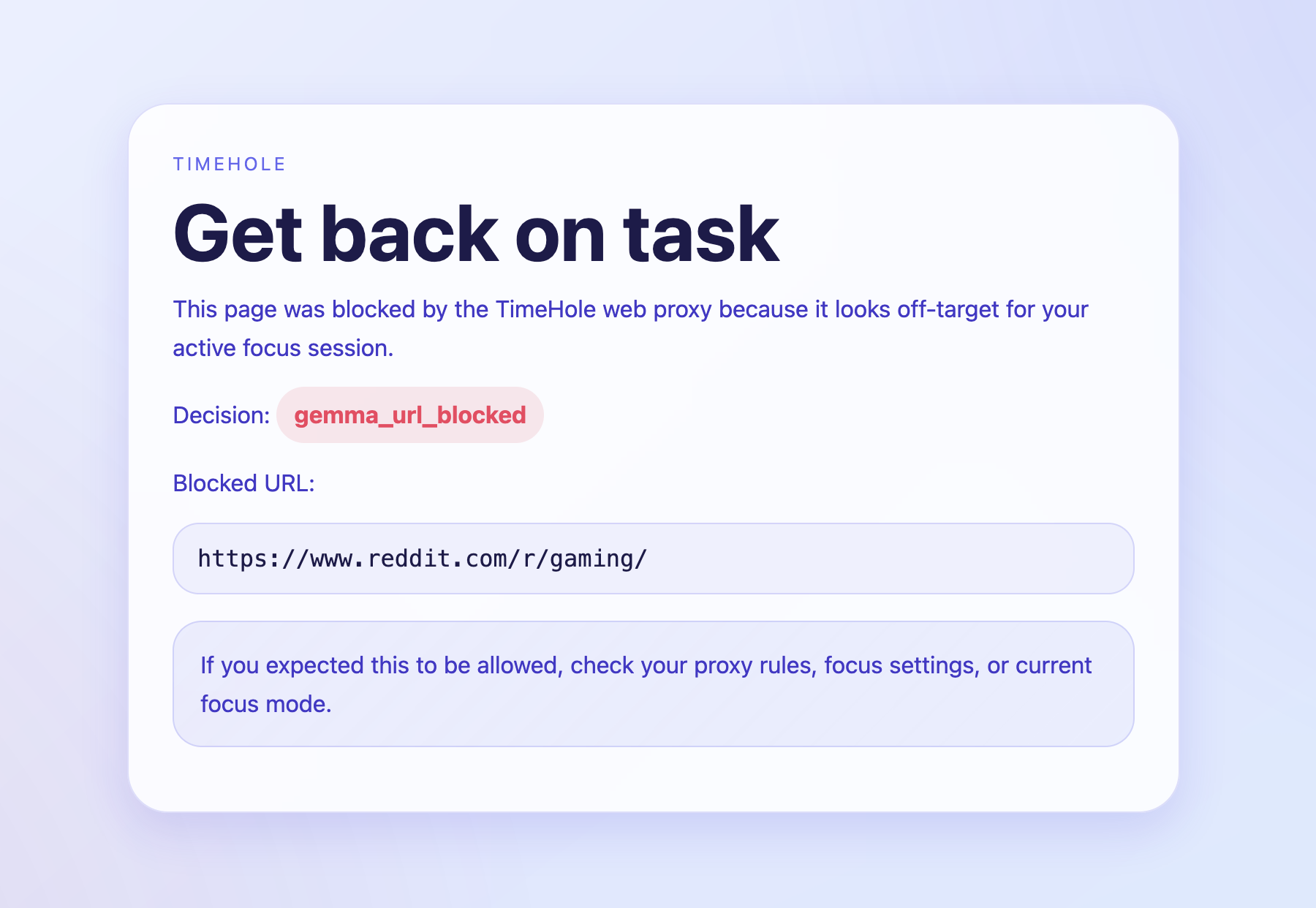
Intercepting block page

Track Fit
Flicker to Flow
Our tool is built to help people with their productivity to better compartmentalize their work-life balance, focusing on work when they need to without getting distracted.
Arista Networks
Networking sits at the core of our system. We built a customizable DNS server and an SSL-capable web proxy integrated with agentic tooling to perform traffic filtering and blackholing certain requests. On top of that, we generate and aggregate detailed log data through our backend API, enabling intuitive visualizations that clearly show the relevant data of traffic, and if they are blocked or allowed.
Use of Gemma
Our web proxy uses the Gemma 4 model to produce context-aware filtering, only blocking certain sections of websites based on their request and response data, not just blindly blocking entire applications. For example, with a website such as Reddit, it won't instantly block it, but will utilize extra heuristics such as the URL path, the response HTML data, and the user's request of what they want to focus on to determine if that specific section of Reddit is unproductive to the user or not.
Use of MongoDB Atlas
Our tooling uses MongoDB Atlas to store data and facilitate a shared memory between the web interface and the proxy server. The web interface will act as a front end to help visualize data from Atlas, and also update the user's configuration, which is stored in Atlas and is utilized by the proxy in real time to determine if they are in violation of their focus time.
About The Project
Inspiration
Distractions on the internet are not accidental. They are deliberately engineered to capture and hold attention. Platforms like social media are optimized to maximize engagement, making it difficult to stay focused even when users have clear goals. Existing solutions, such as browser extensions, can be easily bypassed by clients and lack the intelligence to understand context. We were inspired to build something more robust: a system-level solution that operates at the application network layer and enforces focus across all devices. Drawing inspiration from tools like Pi-hole and Opal, we asked ourselves: what if your internet connection itself could keep you on track to stay productive?
At the same time, we recognized that simply blocking domains or URLs is not enough, since much of today’s content requires a deeper understanding, such as platforms like YouTube, where the URL alone does not reveal whether a video is educational or distracting. This motivated us to incorporate response-based filtering directly into the project, where the proxy can analyze actual page content like video titles and descriptions instead of relying solely on URLs. By combining network-level control with contextual understanding, TimeHole aims to go beyond traditional blockers and create a smarter, more adaptive productivity system.
What it does
TimeHole is a network-level productivity filter that combines a DNS server and a web proxy to analyze and control internet traffic in real time. Users configure their experience through a web interface by setting focus schedules, selecting categories of content to block, adding custom blacklisted sites, and describing their goals in natural language. Once activated, all network traffic flows through TimeHole. The DNS layer performs fast, coarse filtering by blocking clearly distracting domains, while the proxy layer performs deeper analysis by examining URLs, request paths, and response content when applicable. A lightweight language model then evaluates whether a request aligns with the user’s goals, effectively acting as a personalized classifier that determines whether content should be allowed or blocked.
How we built it
We designed TimeHole as a modular system with shared logic across components. The core filtering engine combines a DNS relay and a web proxy, both implemented in Python, allowing us to balance speed and intelligence. A separate web interface handles user configuration, visualization, and control. All components share a centralized MongoDB Atlas database for storing user preferences, logs, and cached decisions. We integrated a lightweight LLM (Gemma) to perform contextual classification of requests, using user-provided goals as input. The entire system is containerized using Docker, with one container for the proxy and DNS server and another for the web interface. Key design decisions included prioritizing rule-based filtering for speed, caching frequent decisions to reduce latency, and structuring the system to support both URL-based and response-based content analysis.
Challenges we ran into
One of the main challenges was balancing speed and intelligence. DNS filtering must operate extremely quickly, while proxy-level and LLM-based analysis introduce latency. We addressed this by splitting the system into layers, where the DNS server handles only obvious cases and the proxy performs deeper inspection. Another challenge was defining what counts as “productive,” since this is highly subjective and context-dependent. Incorporating user-defined goals helped make the system more personalized and flexible. We also encountered technical difficulties with HTTPS inspection, as analyzing encrypted traffic requires TLS interception and certificate management, which adds complexity and potential security concerns. Additionally, handling edge cases in URL structures, such as distinguishing between productive and distracting content on the same platform, required careful parsing logic and heuristic design.
Accomplishments that we're proud of
We are proud of building a fully functional, system-level productivity tool that goes beyond traditional browser-based solutions. TimeHole demonstrates a hybrid architecture that effectively combines fast rule-based filtering with intelligent, context-aware decision-making using an LLM. We successfully integrated multiple components such as a DNS, proxy, web interface, database, and AI model, into a cohesive system. Additionally, we developed a user-friendly interface that allows for flexible configuration and provides meaningful insights through logs and analytics. The system is also designed with scalability and extensibility in mind, making it a strong foundation for future improvements.
What we learned
Through this project, we learned the importance of designing layered systems that separate concerns between speed and complexity. We saw firsthand that combining heuristic methods with machine learning produces more practical and efficient solutions than relying on either approach alone. We also gained experience working with real-time systems, where latency and performance constraints play a critical role. Another key takeaway was that user intent is difficult to formalize, but natural language input provides a powerful way to bridge that gap. Finally, we learned how to structure a distributed system with shared state and modular components, which made development and iteration much more manageable.
What's next for TimeHole
Looking ahead, we plan to further enhance TimeHole’s intelligence and usability. We want to optimize the system for on-device deployment using smaller, faster models that can run efficiently on hardware like a Raspberry Pi. We also aim to implement adaptive learning so the system can personalize filtering decisions over time based on user behavior. Furthermore, we could look into adding an administration panel to control focus configuration for other users, as this can be used in households and even enterprise companies. Additional improvements include more granular controls for different devices or applications, as well as richer analytics to provide deeper insights into productivity patterns. Ultimately, our goal is to make TimeHole a seamless, intelligent productivity system that integrates naturally into everyday workflows.

Log in or sign up for Devpost to join the conversation.