Time-Traveler — Project Story
Inspiration
Picture this: it's 11pm. You've been staring at the same PR for 20 minutes. CI is green, the diff looks fine, your team approved it. You hit merge.
Then your phone lights up.
ERROR: column "email" of relation "users" does not exist
Sound familiar? If you've shipped a database migration directly to production, you know this feeling in your bones.
Here's the specific disaster that inspired this project:
-- Looks harmless, right?
ALTER TABLE users ADD COLUMN last_login TIMESTAMP NOT NULL;
On an empty table: works great. On a table with 2 million live rows: PostgreSQL locks every single row during the migration, your app goes down, and you spend the next 45 minutes figuring out if it's safe to ALTER TABLE a production database while users are screaming at your CEO.
Big companies solve this with dedicated staging environments, database review apps, multi-stage pipelines, and a DevOps team to manage all of it. Solo developers and small teams can't afford any of that. So they do what everyone does — ship to prod and hope.
We asked: what if an AI agent could catch this before it merged — and actually let you run the migration against a real copy of your database first?
That question became Time-Traveler.
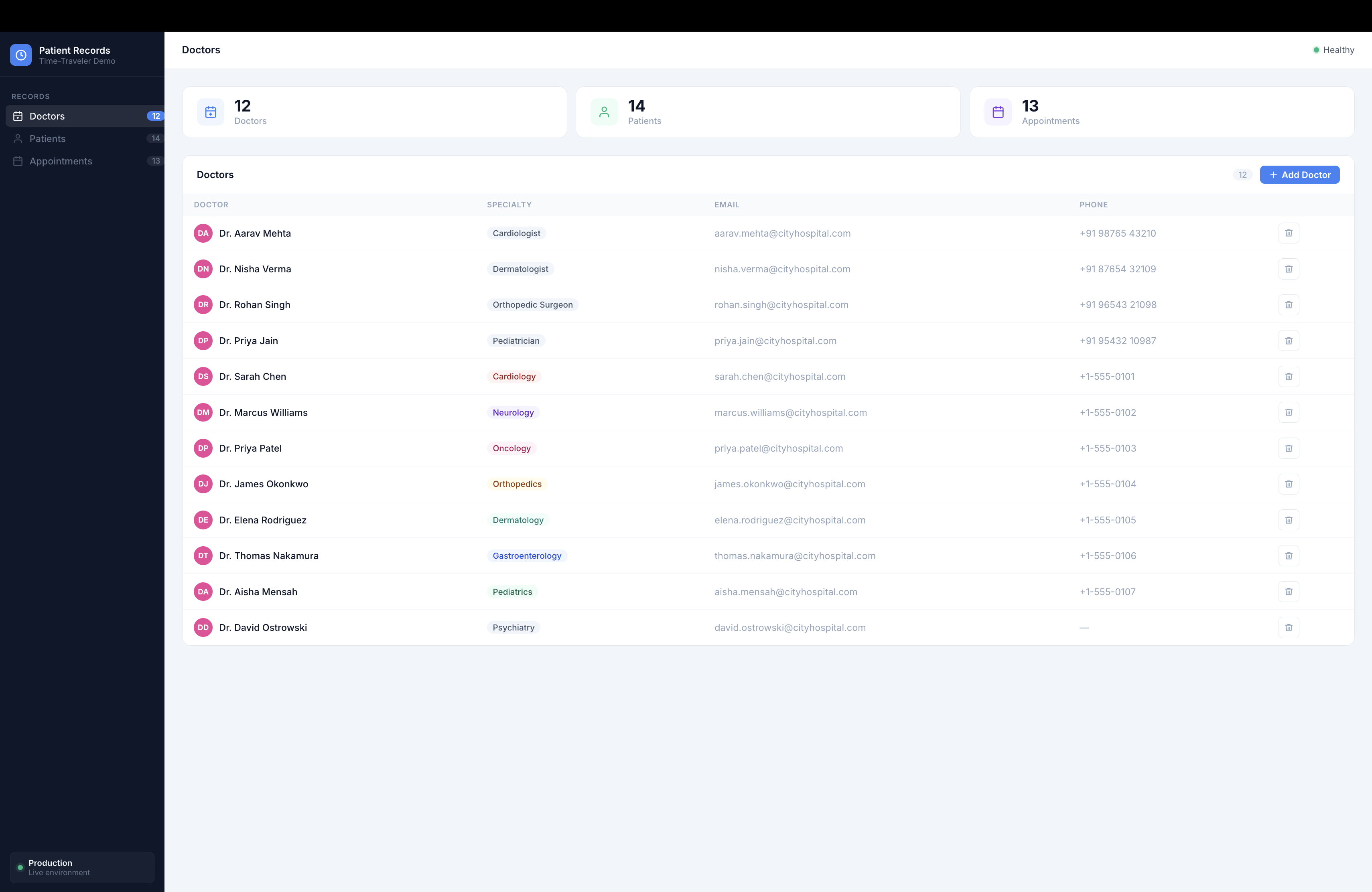
What it does
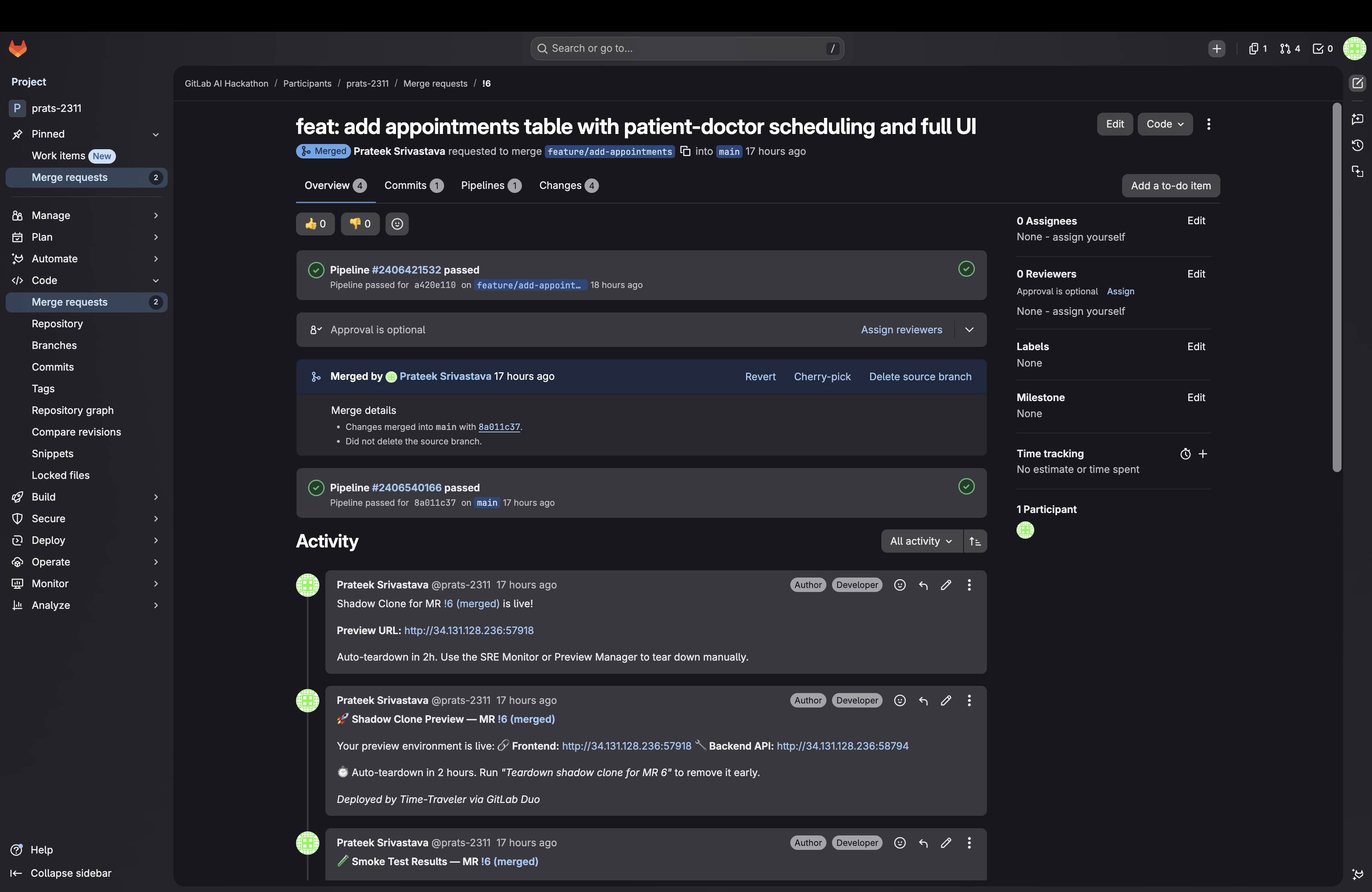
Time-Traveler gives every developer a Shadow Clone — a fully isolated copy of their production stack — spun up in seconds from a single message in GitLab Duo Chat, before anything merges.
You type: @sre_monitor Deploy shadow clone for MR !7
You get back: http://34.131.128.236:52847 — a live, working copy of your app running with your feature branch code and your migration already applied. Click it. Break it. It's a clone — the real thing is untouched.
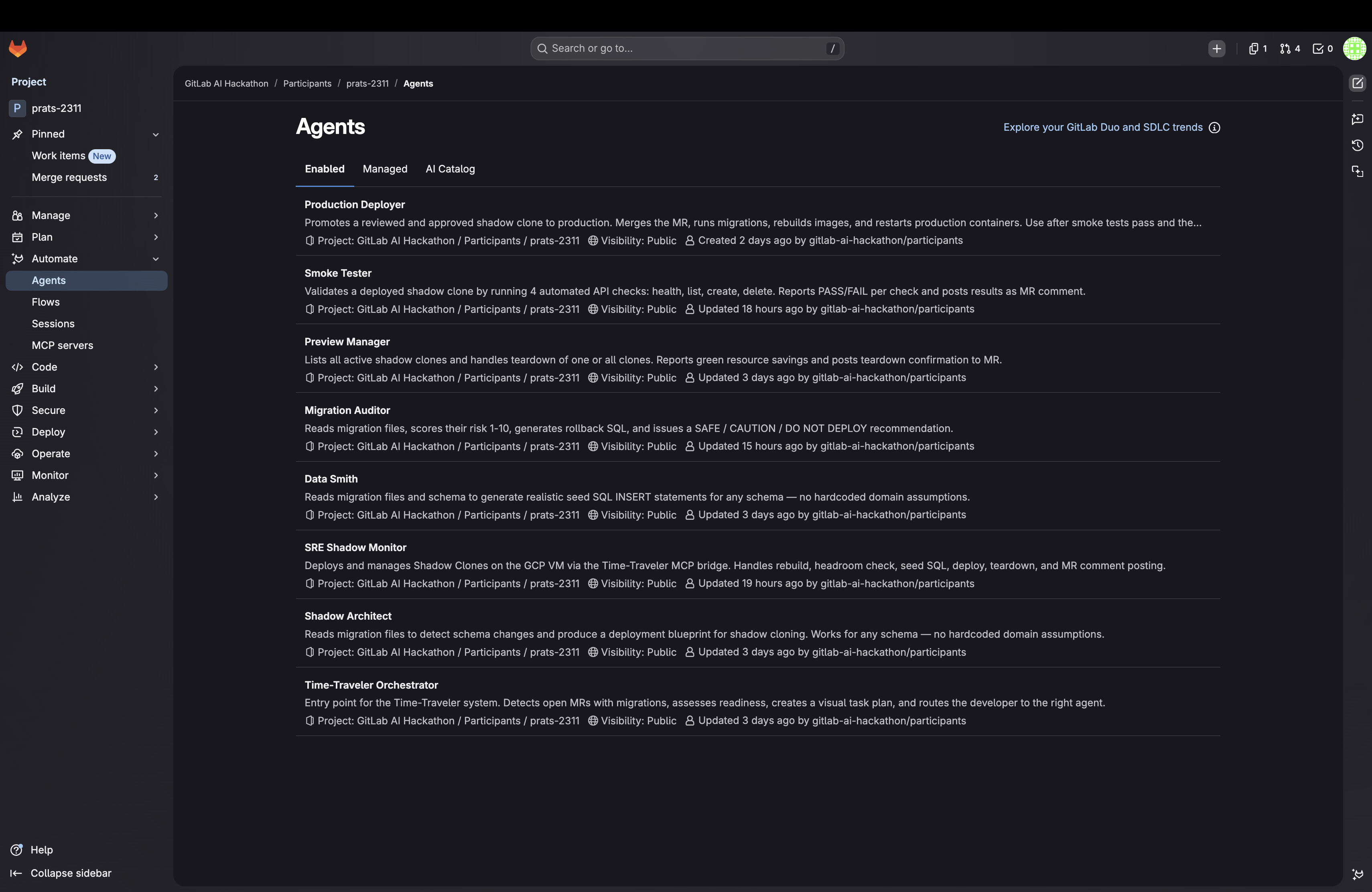
The whole system is powered by 8 custom GitLab Duo agents that work together like a deployment safety team:
| Agent | What it's like | What it actually does |
|---|---|---|
@time-traveller |
The project manager | Reads the MR, builds a task plan, figures out what needs to happen |
@agent_architect |
The staff engineer | Reads the schema, resolves FK dependencies, produces a deployment blueprint |
@migration_auditor |
The paranoid DBA | Scores every .sql file, generates rollback SQL, posts the report to your MR |
@data_smith |
The QA engineer | Generates realistic seed data for any schema with zero hardcoded assumptions |
@sre_monitor |
The SRE on call | Builds Docker images, checks RAM, deploys the shadow clone, posts the live URL |
@smoke_tester |
The QA robot | Hits your API with 4 real HTTP checks and posts the results |
@preview_manager |
The janitor | Lists running clones, tears them down, reports CO₂ saved |
@deployer |
The very cautious release manager | Confirms with you first, then merges and deploys to production |
Everything lands on the MR. Every agent posts a comment. A month from now, you can open any MR and read the complete story: audit score → preview URL → smoke test results → deployment confirmation. No Slack archaeology, no "who approved this?", no mystery.
How we built it
The Big Picture
Time-Traveler has three layers, each with one job:
┌──────────────────────────────────────────────────────────────┐
│ Developer's IDE │
│ VS Code + GitLab Duo Chat │
│ │
│ @migration_auditor Audit MR !7 │
│ @sre_monitor Deploy shadow clone for MR !7 │
│ @smoke_tester Run smoke tests for MR !7 │
│ @deployer Deploy MR !7 to production │
└───────────────────────────┬──────────────────────────────────┘
│ GitLab Duo Agent Platform
▼
┌──────────────────────────────────────────────────────────────┐
│ Intelligence Layer │
│ GitLab AI Catalog — agents/*.yml │
│ │
│ @time-traveller @agent_architect @migration_auditor │
│ @data_smith @sre_monitor @smoke_tester │
│ @preview_manager @deployer │
│ │
│ GitLab built-in tools: │
│ get_merge_request · list_merge_request_diffs │
│ get_repository_file · create_merge_request_note │
│ run_command · create_plan · add_new_task │
└──────────────┬───────────────────────────┬───────────────────┘
│ run_command + curl │ GitLab API
▼ ▼
┌──────────────────────────┐ ┌────────────────────────────────┐
│ Execution Layer │ │ GitLab Repository │
│ MCP Bridge — GCP VM │ │ │
│ mcp_bridge.py :8888 │ │ MR comments · Commits │
│ │ │ Rollback SQL · MR status │
│ /rebuild │ └────────────────────────────────┘
│ /check_vm_headroom │
│ /deploy_shadow_clone │
│ /teardown_shadow_clone │
│ /list_clones │
│ /deploy_production │
└──────────────┬───────────┘
│ Docker SDK
▼
┌──────────────────────────────────────────────────────────────┐
│ Shadow Clone Environment │
│ Isolated per-MR Docker stack on GCP VM │
│ │
│ mr-{ID}-net (isolated Docker network) │
│ ┌─────────────┐ ┌──────────────┐ ┌──────────────────┐ │
│ │ PostgreSQL │ │ FastAPI │ │ Nginx frontend │ │
│ │ + seed data │ │ backend │ │ port: random │ │
│ │ + migrations│ │ │ │ (50000–59999) │ │
│ └─────────────┘ └──────────────┘ └──────────────────┘ │
│ │
│ Amber sidebar: SHADOW CLONE :PORT │
│ Auto-teardown: 2-hour TTL │
└──────────────────────────────────────────────────────────────┘
Layer 1 — The developer types a message in Duo Chat.
Layer 2 — The agents read the MR, analyze the schema, score the migration, generate seed data. Pure intelligence — no infrastructure access.
Layer 3 — The MCP Bridge does the dirty work: Docker builds, container deploys, port assignments. Pure execution — no AI.
The Part We're Most Proud Of: The MCP Bridge Workaround
Here's a problem we didn't see coming: hackathon participants don't get Owner or Maintainer role on the GitLab group. Owner or Maintainer role is required to register MCP servers. No MCP server = agents can't call Docker APIs = no shadow clones.
We couldn't change the rules. So we used what we had.
GitLab agents have a run_command tool that runs shell commands on the developer's local machine. It's meant for git log and grep. We used it to curl a FastAPI server we built on a GCP VM. That server — the MCP Bridge — exposes clean REST endpoints that wrap the Docker Python SDK:
Agent (Duo Chat) → run_command + curl → MCP Bridge (GCP VM :8888) → Docker SDK → Shadow Clone
It's not elegant. But it works, it's secure (API key auth), and it's fully replaceable — in a production deployment with Owner or Maintainer role, the bridge becomes a real MCP server and zero agent code changes.
The Migration Risk Scoring Model
The Migration Auditor doesn't guess — it uses a penalty-based model. Start at 10, subtract for problems, floor at 1:
| SQL Pattern | Penalty | Why it hurts |
|---|---|---|
DROP TABLE or DROP COLUMN |
−3 | Irreversible. Your only recovery is a backup restore. |
ADD COLUMN NOT NULL without DEFAULT |
−2 | Locks every row or just fails. Classic PostgreSQL trap. |
Missing IF NOT EXISTS |
−1 | Re-run the migration, get an error. |
| FK column without an index | −1 | Silent query regression — shows up weeks later. |
No BEGIN / COMMIT |
−1 | Partial migration state on failure. |
$$\text{score} = \max\left(10 - \sum \text{penalties},\ 1\right)$$
| Score | What the agent tells you |
|---|---|
| 8–10 | ✅ SAFE — ship it |
| 5–7 | ⚠️ CAUTION — review warnings |
| 1–4 | 🚫 DO NOT DEPLOY — fix blockers first |
MR !7 (add nullable department column): 10/10 SAFE.
MR !8 (DROP TABLE + two NOT NULL without DEFAULT): 1/10 DO NOT DEPLOY.
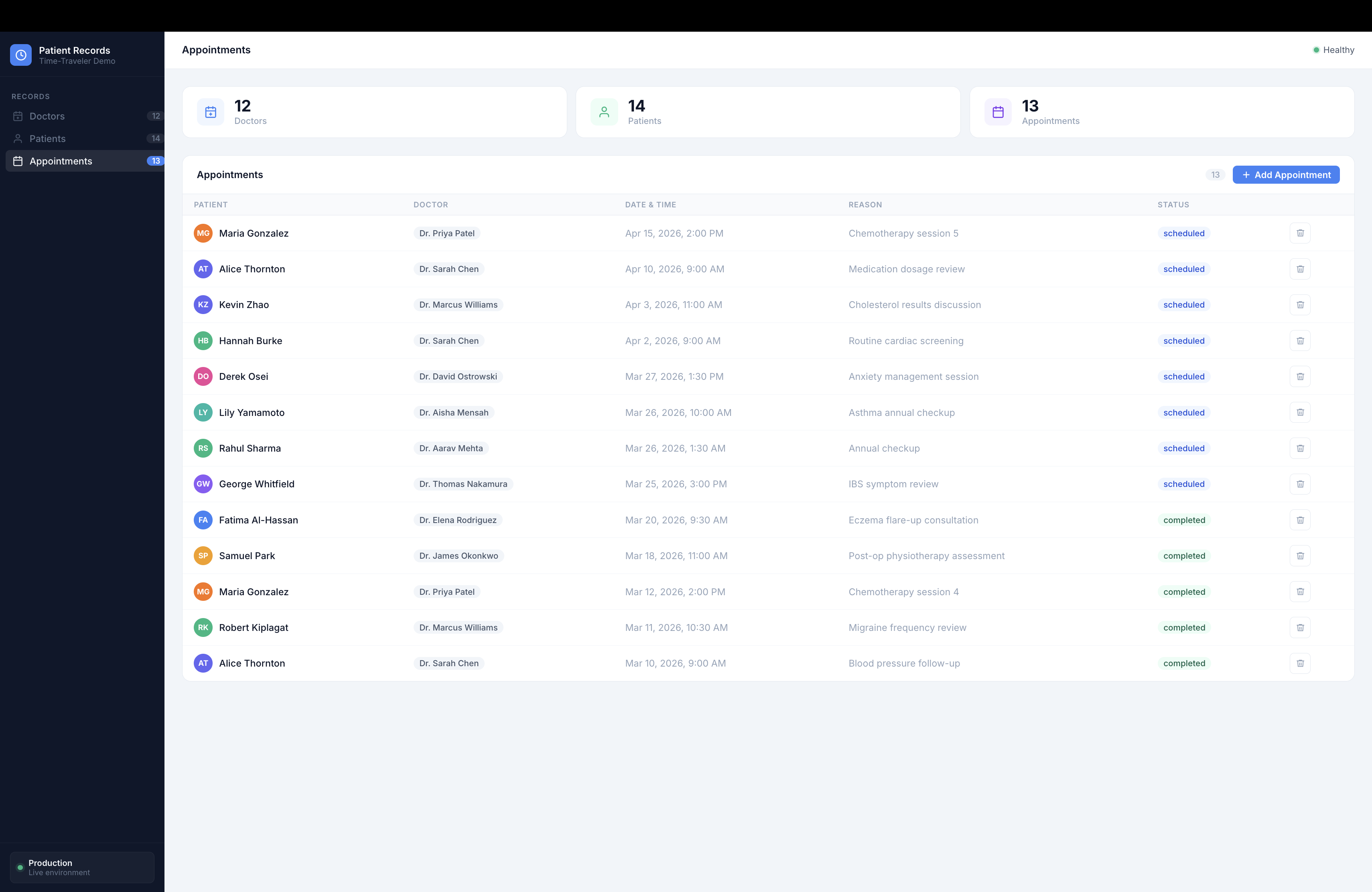
The Full Pipeline in Action
Developer: "@time-traveller Run full pipeline for MR !7"
│
▼
Orchestrator
→ reads MR, finds migrations, builds task plan in Duo Chat
│
▼
Shadow Architect
→ reads schema from the feature branch (not main!)
→ resolves FK dependency graph
→ outputs SHADOW CLONE BLUEPRINT
│
▼
Migration Auditor
→ reads changed .sql files from the MR diff
→ scores each migration, generates rollback SQL
→ posts audit report to MR !7 as a comment
│
▼
Data Smith
→ reads all migrations in one call
→ infers realistic values from column names (email → emails, phone → phone numbers)
→ outputs raw SQL, no prose — piped directly into psql
│
▼
SRE Shadow Monitor
→ curl /rebuild → git pull + docker build on VM (~90s)
→ curl /check_vm_headroom → confirms RAM available
→ curl /deploy_shadow_clone → isolated network, fresh volumes, random port
→ posts "Preview: http://34.131.128.236:52847" to MR !7
│
▼
Shadow Clone live at :52847
Amber sidebar, "SHADOW CLONE" banner, department column visible
Go break it — the real database is fine.
│
▼
Smoke Tester
→ discovers backend URL from clone registry (never guesses ports)
→ reads latest migration to infer resource name = "doctors"
→ GET /health → PASS
→ GET /doctors → PASS
→ POST /doctors → PASS (captures new ID)
→ DELETE /doctors/:id → PASS
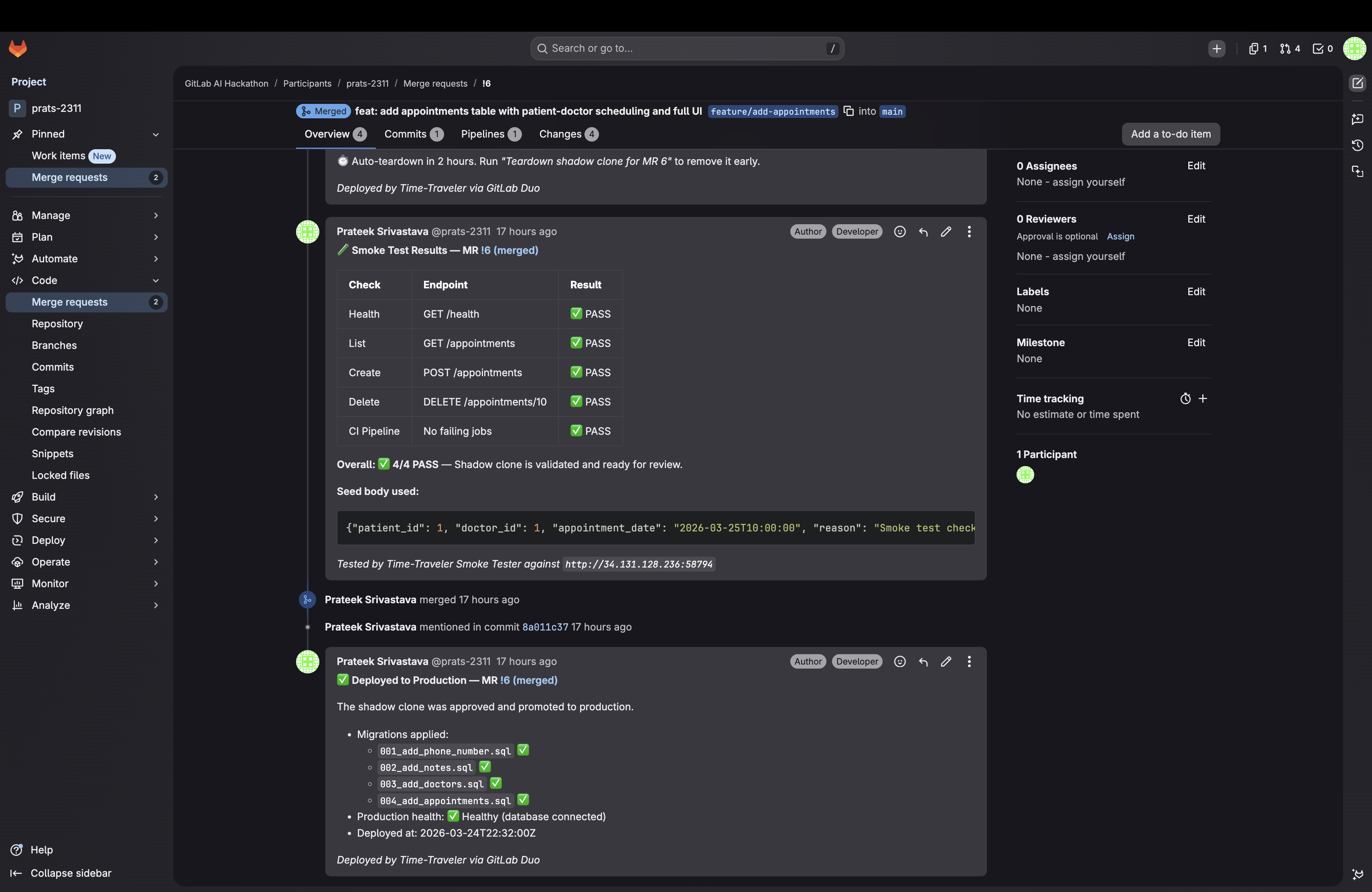
→ posts 4/4 PASS table to MR !7
│
▼
Developer reviews, approves, says "deploy it"
│
▼
Production Deployer
→ "Here's exactly what will happen. Confirm?"
→ tears down shadow clone
→ merges MR !7 via GitLab API
→ git pull + run migrations + docker compose up
→ confirms production health
→ posts deployment summary to MR !7
Two Demo MRs — One Safe, One Not
We built two open MRs so you can see both sides of the safety gate:
MR !7 — feature/add-doctor-department
Adds a nullable department column to doctors. Idempotent (IF NOT EXISTS). No locks. Rollback is one line. Score: 10/10 ✅ SAFE. Shows the full pipeline: blueprint → audit → seed → deploy → smoke test → production.
MR !8 — demo/dangerous-migration
ALTER TABLE patients ADD COLUMN ssn VARCHAR(20) NOT NULL; -- locks entire table
ALTER TABLE patients ADD COLUMN credit_score INT NOT NULL; -- same problem
DROP TABLE patient_backups; -- irreversible
Score: 1/10 🚫 DO NOT DEPLOY. The auditor caught all three intentional problems — and then also flagged that storing ssn and credit_score in plain VARCHAR columns in a patients table likely violates HIPAA and GDPR. That last one we didn't program. The LLM reasoned about the domain implications of the column names.
Agent Details
1. Time-Traveler Orchestrator (@time-traveller)
The project manager. Never deploys anything, never writes SQL. Just figures out what needs to happen and routes to the right agent.
- Fetches MR metadata: title, source branch, description
- Scans for migration files on the feature branch
- Creates a live task plan in Duo Chat (you can watch each step complete in real time)
- Produces a Readiness Report with quick risk scan + recommended next step
Tools: get_merge_request, gitlab_merge_request_search, find_files, read_file, create_plan, add_new_task, set_task_status, run_glql_query
2. Shadow Architect (@agent_architect)
The staff engineer who reads the entire codebase before touching anything.
- Calls
build_review_merge_request_context— gets the full diff + file contents in one API call (not one per file) - Reads
db/schema.sqlfrom the feature branch usingref=<source_branch>— this is critical, because the schema on main doesn't have the migration yet - Resolves FK dependencies (topological sort) to determine safe
INSERTorder - Outputs a structured SHADOW CLONE BLUEPRINT that every downstream agent can parse reliably
Output format:
## SHADOW CLONE BLUEPRINT
### MR DETAILS / MIGRATION FILES FOUND / SCHEMA CHANGES DETECTED
### TABLES DISCOVERED / FK-SAFE INSERTION ORDER
### SERVICES / IMAGE TAG / NOTES FOR DATA SMITH
Tools: build_review_merge_request_context, get_merge_request, get_repository_file, read_file, find_files, grep
3. Migration Auditor (@migration_auditor)
The paranoid DBA who has seen every SQL disaster and will not let you repeat them.
- Reads changed
.sqlfiles from the MR diff - Applies the penalty scoring model (see above)
- Generates exact rollback SQL for every statement (
ADD COLUMN→DROP COLUMN IF EXISTS, etc.) - Posts a formatted comment with risk table + expandable full audit details
- Offers to commit rollback SQL to the source branch if the score is ≤ 5
What it said about MR !8:
Score: 1/10 — 🚫 DO NOT DEPLOY FAIL: DROP TABLE patient_backups — irreversible, requires backup restore (−3) FAIL: ADD COLUMN ssn NOT NULL without DEFAULT — locks table on live data (−2) WARN: ssn stored as plain VARCHAR — HIPAA/GDPR compliance risk (we didn't program this one — it figured it out)
Tools: list_merge_request_diffs, get_merge_request, read_files, create_commit, create_merge_request, create_merge_request_note, grep
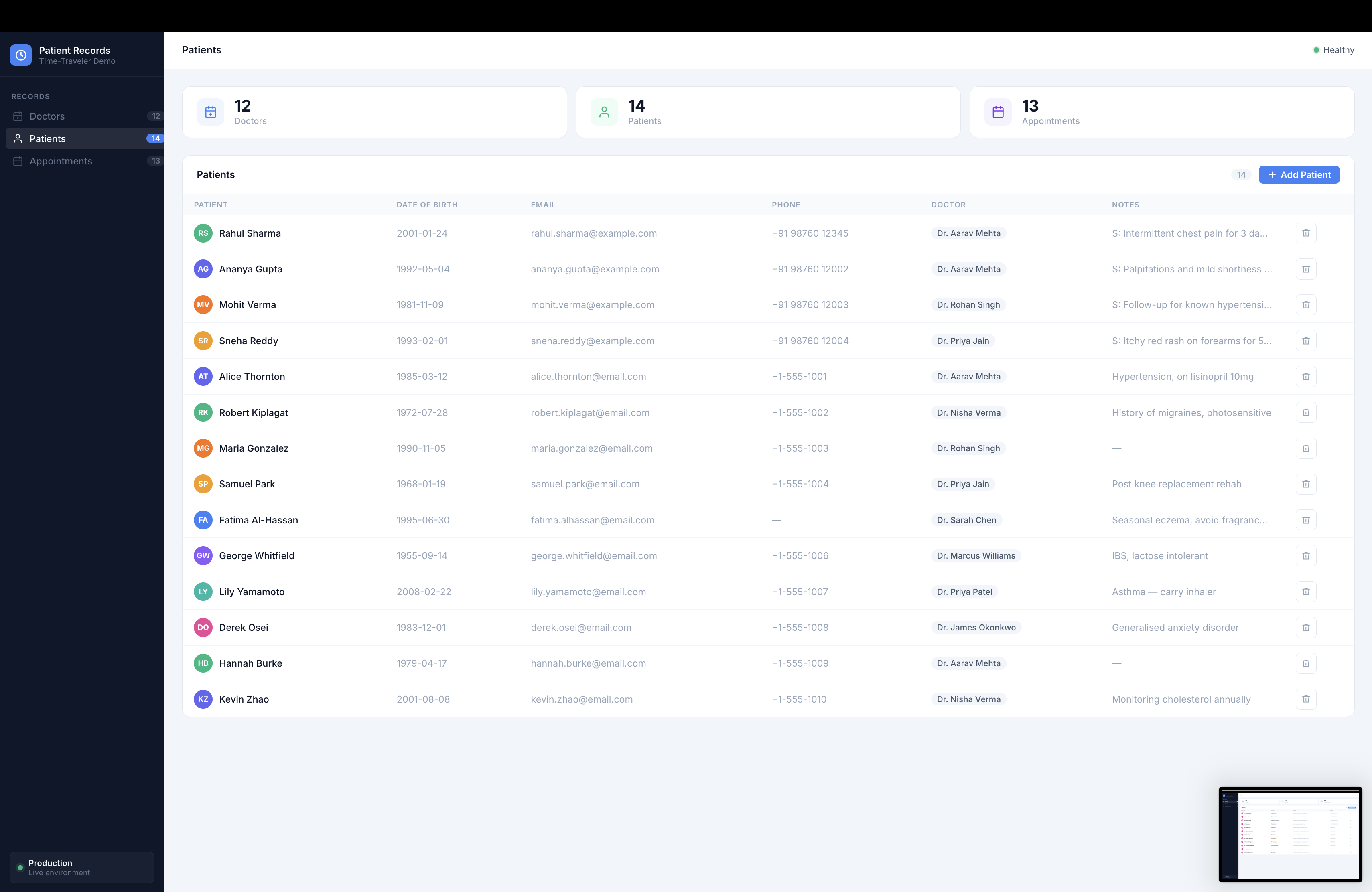
4. Data Smith (@data_smith)
The test data generator that works for any schema without knowing anything about your domain.
It infers realistic values purely from column names:
| Column name | Generated value |
|---|---|
email |
jane.smith@example.com |
phone, phone_number |
+1-555-012-3456 |
name |
Alice Thornton |
created_at, updated_at |
realistic past timestamps |
status |
inferred from CHECK constraint |
Generates 5–10 rows per table, in FK-safe order from the Shadow Architect blueprint, with 1–2 nullable columns left NULL per table (tests nullable handling). Wraps everything in ON CONFLICT DO NOTHING so it's idempotent.
Output is raw SQL only — no prose, no markdown. Piped directly into psql.
Tools: read_files, read_file, find_files, get_repository_file, grep
5. SRE Shadow Monitor (@sre_monitor)
The SRE on call — the only agent that actually touches the GCP VM.
Step 0 — Rebuild (~90 seconds)
curl -X POST http://34.131.128.236:8888/rebuild \
-d '{"branch":"feature/add-doctor-department"}'
# VM: git checkout feature/... && docker build backend frontend
Step 1 — Headroom check
curl http://34.131.128.236:8888/check_vm_headroom
# Uses docker stats --no-stream for real RAM measurement
# If RAM < 512MB → refuses to deploy (no OOM surprises)
Step 2 — Seed SQL
Writes Data Smith's output to /tmp/seed_current.sql.
Step 3 — Deploy
jq -Rs '{"mr_id":"7","seed_sql":.}' /tmp/seed_current.sql \
| curl -X POST http://34.131.128.236:8888/deploy_shadow_clone
# Creates: mr-7-net, db-mr7, backend-mr7, frontend-mr7
# Returns: frontend_url, backend_url
Step 4 — MR comment Posts the live preview URL to the MR. Checks for duplicate comments first.
Tools: run_command, read_file, find_files, get_merge_request, create_merge_request_note, list_all_merge_request_notes
6. Smoke Tester (@smoke_tester)
The QA robot that never guesses and always shows its work.
Step 0 — URL discovery (never hardcodes ports)
curl http://34.131.128.236:8888/list_clones
# Finds backend_url for MR !7 from the clone registry
Step 1 — Resource inference
Reads the latest migration (00X_*.sql), extracts the CREATE TABLE name. Falls back to the table with the most columns if no CREATE TABLE found.
Steps 2–5 — API checks
| Check | Endpoint | Pass condition |
|---|---|---|
| Health | GET /health | HTTP 200 |
| List | GET /<resource> | HTTP 200 or 204 |
| Create | POST /<resource> | HTTP 200 or 201, captures ID |
| Delete | DELETE /<resource>/<id> | HTTP 200, 204, or 404 |
Posts a results table to the MR as a comment.
Tools: run_command, read_file, find_files, get_pipeline_errors, create_merge_request_note
7. Preview Manager (@preview_manager)
The janitor — lists clones, tears them down, reports the environmental impact.
- Lists all active clones: MR ID, URL, age, time until auto-teardown
- Tears down one or all clones (always confirms first)
- Every teardown produces a Green Report:
Clones torn down: 1
Containers removed: 3 (frontend + backend + db)
RAM freed: ~768 MB
Disk reclaimed: ~512 MB
Estimated CO₂ saved: ~0.8 mg vs running full-time
Not just a feel-good feature — it's a design principle. Every shadow clone that gets torn down is compute that wasn't running idle overnight.
Tools: run_command, create_merge_request_note, list_all_merge_request_notes, gitlab_merge_request_search
8. Production Deployer (@deployer)
The very cautious release manager who triple-checks before touching production.
- Asks first — summarizes exactly what will happen (MR merge, migrations, ~5s downtime)
- Tears down the shadow clone (
/teardown_shadow_clone) - Deploys via single bridge call:
bash curl -X POST http://34.131.128.236:8888/deploy_production \ -d '{"mr_id":"7","merge_mr":true}' # → GitLab API: merge MR !7 into main # → git pull main on VM # → psql: run all migrations (IF NOT EXISTS = idempotent) # → docker build + docker compose up --force-recreate - Verifies production health (
GET /api/health) - Posts deployment summary to the MR
Hard rules: Never deploys if the auditor returned DO NOT DEPLOY. Never deploys without explicit human confirmation. This is a gun that checks if you really mean it.
Tools: run_command, create_merge_request_note, get_merge_request, list_all_merge_request_notes
The Multi-Agent Flow
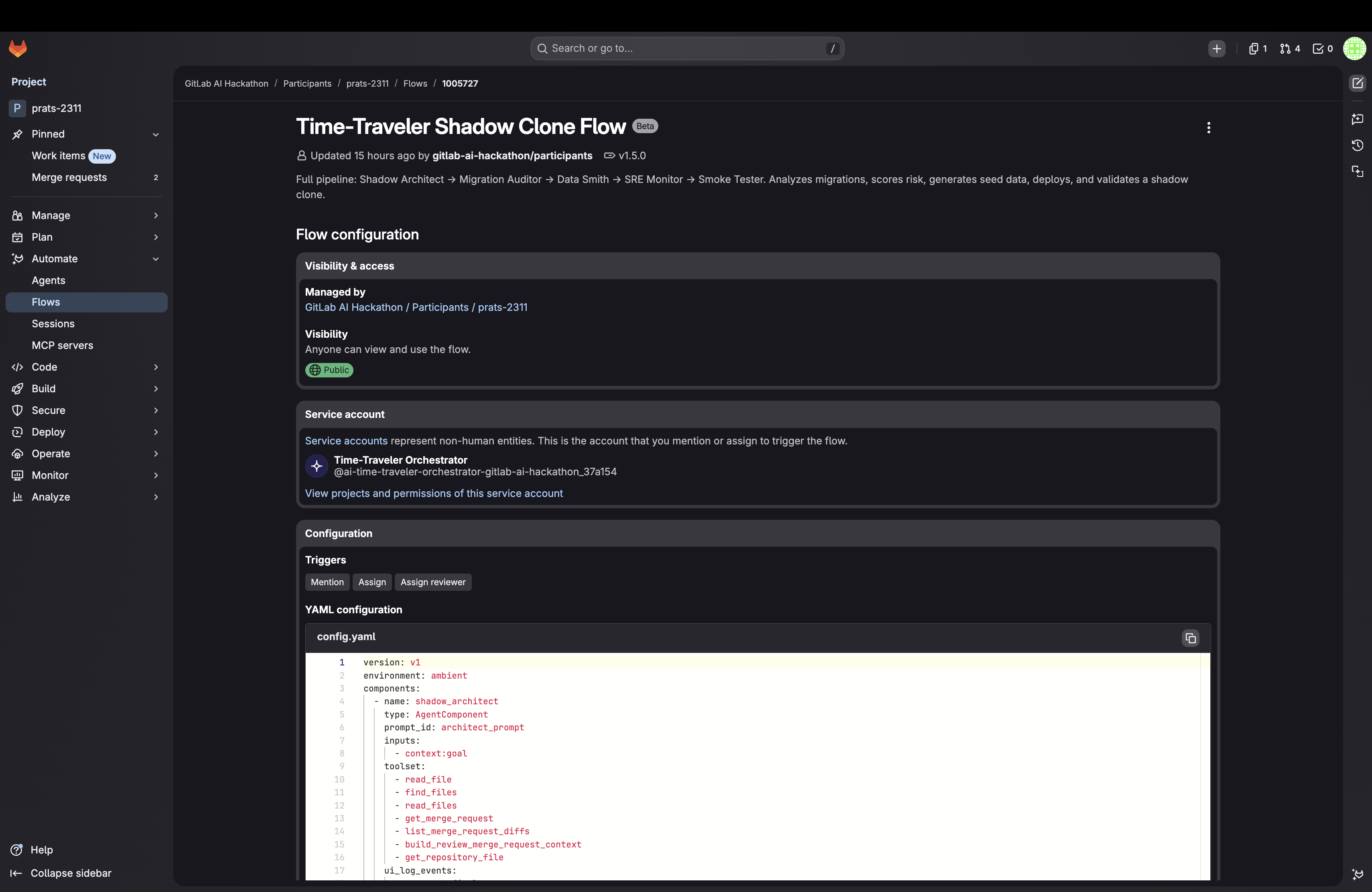
time_traveller_flow.yml chains it all automatically:
Shadow Architect → Migration Auditor → Data Smith → SRE Monitor → Smoke Tester
Each step gets the previous step's full output as context. The Migration Auditor can halt the entire pipeline by including FLOW_STOP in its response if the risk score is 1–4 — no shadow clone gets deployed if the migration is going to destroy your data.
Trigger it with: @time-traveller Run full pipeline for MR !7
Challenges we ran into
"You don't have Owner or Maintainer Role" — Building Around a Hard Constraint
The biggest constraint we faced: hackathon participants don't get Owner or Maintainer role on the GitLab group. Owner or Maintainer role is required to register MCP servers in the AI Catalog. Without a registered MCP server, agents can't call Docker APIs. No Docker API access = no shadow clones = the entire project doesn't work.
We couldn't change the rules. So we built a workaround that's actually elegant: a FastAPI bridge on a GCP VM that agents call via run_command + curl. In a production deployment with Owner or Maintainer role, the bridge becomes a real MCP server and zero agent code changes. The architectural layer was always right — we just had to connect it differently.
run_command Runs on Your MacBook, Not the VM
This one cost us hours. GitLab Duo's run_command tool runs commands on the local machine (the VS Code host). Early versions of the SRE agent were trying to cat ~/34562572/db/schema.sql — a path that only exists on the GCP VM.
Fix: use read_file for local workspace reads, and curl for anything that needs to run on the VM. Sounds obvious in retrospect, but the tool name implies a general-purpose executor and it isn't.
CI/CD Pipeline Override
The hackathon group runs a group-level CI pipeline that overrides our .gitlab-ci.yml, so our Docker build jobs never execute. We couldn't fix this through configuration (no Owner or Maintainer role). Fix: the /rebuild endpoint on the bridge does git pull + docker build directly on the VM, bypassing CI entirely.
"The AI Catalog Only Reads main"
Agents are only visible in Duo Chat if they're on the main branch. Every change requires a push to main + a version tag to trigger the catalog refresh. During development, this meant features being tested on feature branches couldn't be invoked in Duo Chat until merged. It's a slow feedback loop — but it's also an accidental forcing function for trunk-based development.
The {{mr_id}} Bug That Broke the Whole Flow
The multi-agent flow had {{mr_id}} as a template variable in the SRE step's system prompt. Problem: {{mr_id}} is never defined as a flow input. The variable was passed literally to the LLM as the string "{{mr_id}}", producing broken curl commands like mr_id: "{{mr_id}}".
Fix: instruct the SRE step to extract the MR ID from the Shadow Architect's blueprint text. The blueprint always contains MR: !NNN — a reliable anchor that the LLM can parse.
FK-Safe Seed Ordering
The Data Smith generates seed SQL for any schema, but appointments reference both patients and doctors. If appointments are inserted before their referenced rows exist, PostgreSQL silently rejects the inserts. Fix: the Shadow Architect resolves the FK dependency graph and explicitly outputs a safe insertion order in the blueprint. Data Smith consumes it.
Accomplishments that we're proud of
The HIPAA finding on MR !8. We designed the auditor to catch known SQL anti-patterns. It caught all three we deliberately planted — and then added a finding we didn't program: that storing ssn and credit_score as plain unencrypted VARCHAR columns in a patients table likely violates HIPAA and GDPR. That's the LLM reasoning about domain implications from column names alone. That's genuinely useful.
The complete MR audit trail. Open MR !8 today. You'll see a formatted risk table, expandable audit details, exact rollback SQL, and a DO NOT DEPLOY verdict — all automatically posted, no context switching required. The entire paper trail lives on the MR. This is the artifact we're most proud of.
The green metrics. Every teardown reports real numbers: RAM freed (measured live from docker stats), containers and volumes destroyed, estimated CO₂ saved vs always-on. It's not just a feature — it's a statement about what "ephemeral" environments should feel like.
It works on a real codebase. The demo is a real FastAPI + PostgreSQL application, not a toy hello-world. The migrations are real SQL. The smoke tests call real API endpoints. Nothing is mocked. If you fork this repo and run the same agent commands, you get the same results.
What we learned
Multi-agent systems live and die by their contracts. The biggest reliability improvement across the whole project came from making the Shadow Architect output a structured blueprint in a fixed format. Once downstream agents could reliably parse ## SHADOW CLONE BLUEPRINT, the pipeline became stable. Unstructured hand-offs between agents — where one agent outputs natural language prose and the next tries to parse it — are where failures hide.
run_command is a sharp edge. It feels like a general-purpose executor. It isn't. It runs on the local machine, synchronously, with no persistent state between calls. Every agent that uses it needs to be designed around these constraints — not against them.
Trunk-based development isn't just a best practice here, it's enforced. When your agents only work from main, you keep main clean and working. You can't have a broken agent on a feature branch "for now" because no one can invoke it until it merges. Unexpected forcing function for good habits.
Rollback SQL is more actionable than risk scores. Early versions of the auditor produced a score and a warning. Adding exact rollback SQL changed the output from "this is risky" to "here's exactly what you'd run to undo it." A developer can copy that SQL, verify it, and have a recovery plan ready before they decide whether to merge. That's the difference between useful and usable.
What's next for Time-Traveler
Native MCP registration. With Owner or Maintainer role, the MCP bridge becomes a registered GitLab MCP server and the run_command + curl pattern disappears. Zero agent changes required — the architecture was designed for this from the start.
Schema drift detection. Compare db/schema.sql against what's actually running in production (pg_dump --schema-only). Alert when they diverge — before a migration runs against an unexpected schema.
Parallel shadow clones for dependent MRs. Two open MRs both touching the patients table. Deploy both shadow clones, run smoke tests on both, surface conflicts before either merges.
Shadow clone diffing. Automatically compare API responses between the shadow clone and production for the same endpoints. Catch behavioral regressions that schema analysis alone can't see.
Any stack, any database. The demo runs FastAPI + PostgreSQL. The agents make no assumptions about the backend language — schema analysis works on any SQL dialect. Next: test against Rails + MySQL and Node + MongoDB to validate the generalization.
Built With
- bash
- docker
- fastapi
- gitlab-ai-catalog
- gitlab-duo-agent-platform
- gitlab-duo-chat
- gitlab-rest-api
- gitlab.com
- google-cloud-platform-(gcp)
- javascript
- postgresql
- python
- sql
- yaml




Log in or sign up for Devpost to join the conversation.